Redis删除策略
## 1. 过期数据
通过前面的学习, 我们知道Redis中的数据可以设置有效期,到期自动删除
可以通过TTL指令获取其状态 ,不同的类型的数据,返回不同的数字
- (具体剩余时间):具有时效性的数据
- -1 :永久有效的数据
- -2 :已经过期的数据 或 被删除的数据 或 未定义的数据
但是,生命周期到达的数据,真的有被立即删除嘛,若同一批数据,在同一时间同时过期,如果需要Redis立即删除,将瞬间对CPU产生较高的压力,可能导致重要的普通指令延迟执行,
这是得不偿失的,所以对于过期数据的清理, Redis提供了三种策略进行删除,防止对CPU产生过高的压力
- 定时删除
- 惰性删除
- 定期删除
数据有效期的实现原理
向Redis中存放数据,默认都是永久保存的, 可以手动执行数据的有效期
如下命令:
expire key seconds // 单位秒(setex指令用的也是这个)
pexpire key milliseconds //单位毫秒
expireat key timestamp //设置到某个时间戳(秒)
pexpireat key milliseconds-timestamp //毫秒
那么Redis对于数据的有效期又是如何维护的呢
示意图:
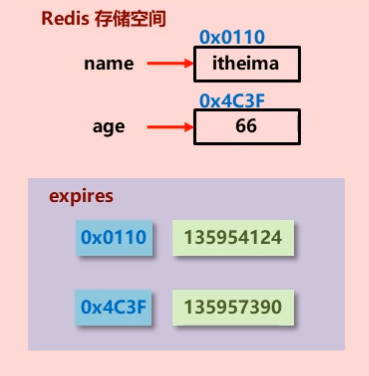
对于每个有对应有效期时间的数据,Redis在底层维护了一个 expires 哈希结构的区域, 对应每个数据的地址值,都记录其失效时间, 而Redis的删除策略,操作的也就是这块数据区域
数据删除策略的目标 :
在内存占用与CPU占用之间寻找一种平衡,顾此失彼都会造成整体redis性能的下降,甚至引发服务器宕机或 内存泄露
2. 定时删除策略
对于每一个有有效期的数据会对应创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
优点: 节约内存,到时就删除,快速释放掉不必要的内存占用
缺点: 实时删除,若一次性大量的数据失效,CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
总结:用处理器性能换取存储空间(拿时间换空间)
3. 惰性删除策略
数据到达过期时间,不做处理。等下次访问该数据时
- 如果未过期,返回数据
- 发现已过期,删除,返回不存在
原理:
对于每个对Redis数据进行读写的指令,其在执行时,都会执行expireIfNeeded函数,此函数就像一个拦截器, 对该指令操作的key进行检查,若发现此键已经过期,将进行删除,否则什么都不做
优点:节约CPU性能,发现必须删除的时候才删除
缺点:有可能出现长期占用内存的数据,内存压力很大
总结:用存储空间换取处理器性能(拿时间换空间)
4. 定期删除策略
上面两种方案都走极端,有没有折中方案? ,就是定期删除
对于Redis的每一个 database, 都对应着自己的 expires区域, 如下图
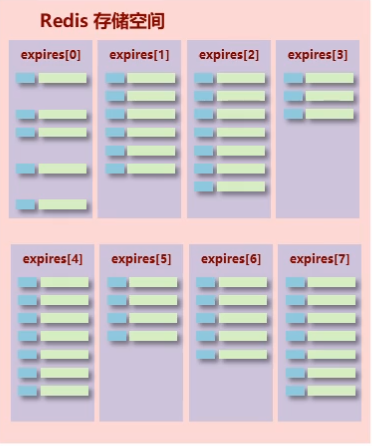
而定期删除,就是在Redis启动服务器初始化时,会读取配置server.hz的值,默认为10
并每秒钟执行server.hz次serverCron() 函数, 并以此执行 databasesCron() , activeExpireCycle() 函数
而每个activeExpireCycle() 将对 expires[*] 进行轮询依次检查, 每次执行时间为 250ms/server.hz
对某个expires[*]检测时,随机挑选W个key检测 ,例如第一次检查 expires[0] 区域
- 如果随机检查的key超时,删除key
- 如果一轮中删除的key的数量>W*25%,循环该过程,再在此expires[0]区域随机抽查,但是总时间不会超过设定时间 (删除的数量大于检查的 25%)
- 直到一轮中删除的key的数量≤W*25%,检查下一个expires[1], 0-15循环 (同样总时间不会超过设定时间)
- W取值=ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP属性值 ,可以在config文件中设置
问题:
这时有一个问题,如果在一次activeExpireCycle(),执行的周期里面,检查到第三个database 区域,则下次如何从此局域开始轮询
对于本次执行的位置,有参数current_db用于记录activeExpireCycle() 进入哪个expires[*] 执行
如果activeExpireCycle()执行时间到期,下次从current_db继续向下执行
总结:
- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
- 周期性抽查存储空间(随机抽查,重点抽查)
5. 删除策略比对
| 策略名称 | 内存占用情况 | CPU占用情况 | 特性 |
|---|---|---|---|
| 定时删除 | 节约内存,无占用 | 不分时段占用CPU资源,频度高 | 拿时间换空间 |
| 惰性删除 | 内存占用严重 | 延时执行,CPU利用率高 | 拿空间换时间 |
| 定期删除 | 内存定期随机清理 | 每秒花费固定的CPU资源维护内存 | 随机抽查,重点抽查 |
对于Redis,采用: 惰性删除 + 定期删除 的方式 作为默认的删除策略
6. 逐出策略
当新数据进入redis时,如果内存不足怎么办?,所有数据都是永久的,或是还没有到失效期的,此时怎么办
解决:
Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如 果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据 的策略称为逐出算法。
注意:
逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息。
(error) OOM command not allowed when used memory >'maxmemory'
相关配置:
-
最大可使用内存 ,占用物理内存的比例,默认值为0,表示不限制。生产环境中根据需求设定,通常设置在50%以上。
maxmemory value -
每次选取待删除数据的个数 , 选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据
maxmemory-samples value -
删除策略 , 达到最大内存后的,对被挑选出来的数据进行删除的策略
maxmemory-policy value
八种逐出策略:
- 检测易失数据,有失效期的数据(可能会过期的数据集server.db[i].expires )
- volatile-lru:挑选最长时间没用过的数据(推荐)
- volatile-lfu:挑选使用次数最少的数据淘汰
- volatile-ttl:挑选将要过期的数据淘汰 ,失效期最近的数据
- volatile-random:任意选择数据淘汰
- 检测全库数据(所有数据集server.db[i].dict )
- allkeys-lru:挑选最长时间没用过的数据
- allkeys-lfu:挑选使用次数最少的数据淘汰
- allkeys-random:任意选择数据淘汰
- 放弃数据驱逐
- no-enviction(驱逐):禁止驱逐数据(redis4.0中默认策略),会直接引发错误OOM(Out Of Memory)
示例(config文件中):
maxmemory-policy volatile-lru
数据逐出策略配置依据
- 使用INFO命令输出监控信息,查询缓存 hit 和 miss() 的次数,根据业务需求调优Redis配置
