爬 “某车之家” 网站 实践
零、写在前面
本文涉及的反爬技术,仅供个人技术学习,禁止并做到:
- 干扰被访问网站的正常运行
- 抓取受到法律保护的特定类型的数据或信息
- 搜集到的数据禁止传播、交给第三方使用、或者牟利
- 如有可能,在爬到数据后24小时候内删除
具体可参考 2019年5月28号 颁布的 《数据安全管理办法(征求意见稿)》
一、写在前面
1、背景
最近有个爬“某车之家”网站里论坛帖子的 spike,遇到一系列的问题,遂这里整理下。
这里以爬此网站的“奔腾T99论坛” 为例。
2、技术选型
用我最近在捣鼓也最熟悉的框架+库:scrapy + splash
3、实现
(1)建表
-
帖子表 - carPostList
-
帖子的评论表 - carPost
carPost 里的第一条数据是发帖人的内容
(2)取舍爬取方法
carPostList 有 api 接口,直接调用获取 json 数据即可
carPost 无 api 接口,纯服务器端渲染,直接抓取 page source 再用 css selector。
(3)入库
这里选择存入 mongodb。
-
carPostList - 共 612 条数据
-
carPost - 共 10569 条数据
耗时:约 1 hour(设置了每个请求间隔 3s)
二、遇到的问题
这章是本文的重点,会列举我遇到的一系列问题,和解决的思路、方法。
1、splash 加载页面不出来
虽然爬 carPostList 直接调 api 就好,但是我最初是用 splash 来抓的 (参考我之前的 blog: Splash 学习笔记),且遇到个棘手的问题,就是帖子那一块总是加载不出来,一直显示 loading,如下图:

(1)尝试
1、一开始以为是网速慢,或者网站本身需要加载更久,于是加大 wait 时间,发现无用。
2、以为是 request header 的问题,于是加了 User-Agent 、Cookie 等都无用。用 selenuim 做了对比实验,发现相同的 header 配置 selenuim 却可以加载成功,遂排除此条。
注:在用 selenuim 爬的时候,需加上 User-Agent,如
Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.23 Mobile Safari/537.36,否则爬取失败。
3、以为是 splash 功能配置的问题,所以我把 splash 的几乎所有有嫌疑的属性都打开了:
splash.plugins_enabled = true
splash.indexeddb_enabled = true
splash.webgl_enabled = true
splash.html5_media_enabled = true
splash.media_source_enabled = true
splash.request_body_enabled = true
splash.response_body_enabled = true
# 下面都是默认为true,我还是覆写了一遍。
splash.js_enabled = true
splash.images_enabled = true
事实证明还是无用。
(2)解决办法
关闭浏览器的私有模式 (匿名模式) 即可。(默认是打开的)
做法:splash.private_mode_enabled = false 或者启动 splash 时指定个参数docker run -p 8050:8050 scrapinghub/splash --disable-private-mode,结果如下图:
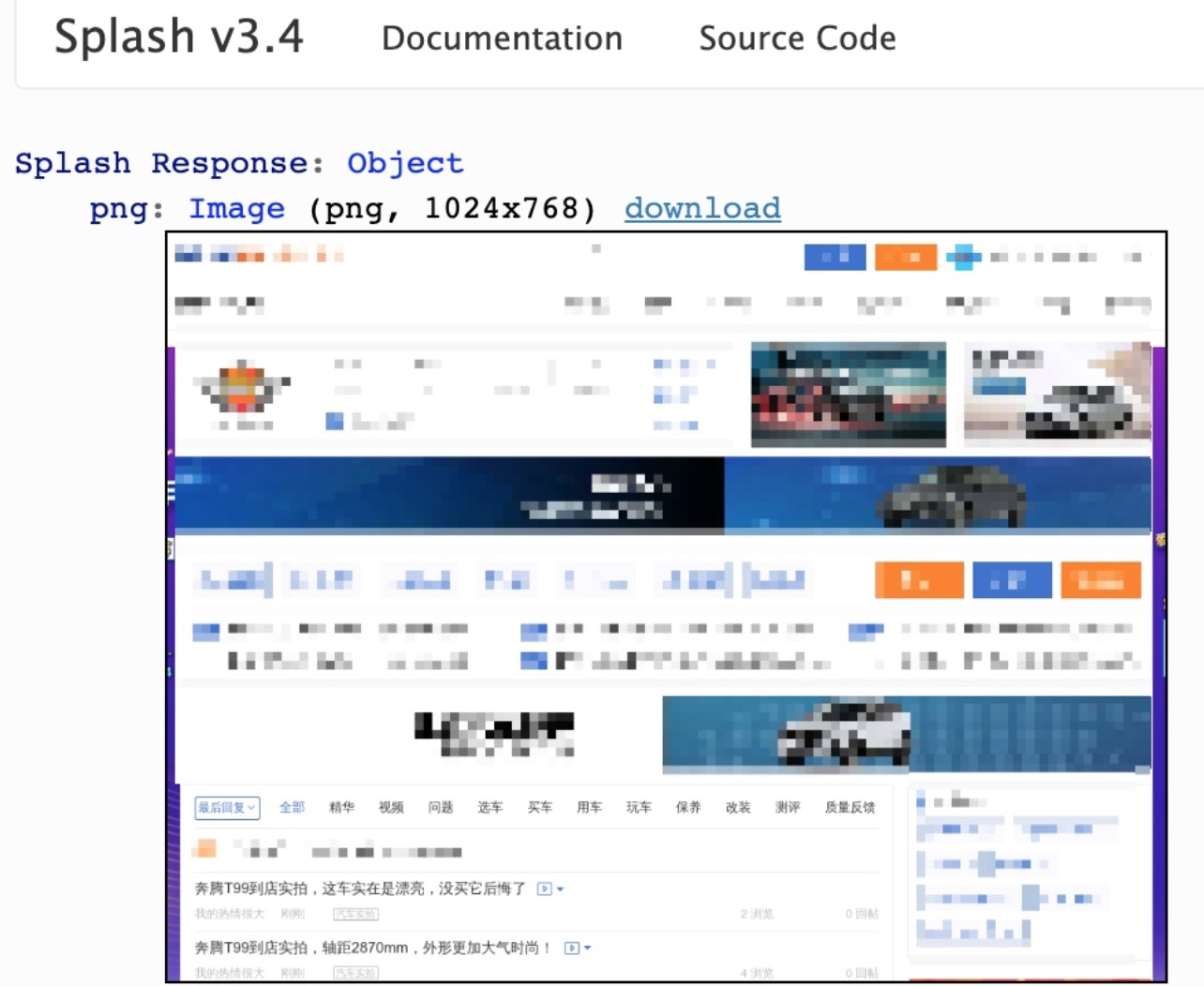
(3)原因
查阅官方文档(https://splash-cn-doc.readthedocs.io/zh_CN/latest/faq.html#how-do-i-disable-private-mode)可知:
“有时您仍然需要关闭私有模式,WebKit的本地存储在开启私有模式时不能正常工作。并且可能无法为本地缓存提供JavaScript填充程序。 因此对于某些站点(某些基于AngularJS站)您需要关闭私有模式。”
看来 splash 的私有模式影响了此网站的 DOM Storage。
官方文档还说了:
“如果您关闭了私有模式,那么不同请求之间可能会使用同样的浏览器信息(cookie 不受影响)。如果 您下共享环境下使用Splash,您发送请求中的相关信息可能会影响其他用户发送的请求。”
所以在一般情况下,还是建议打开私有模式。
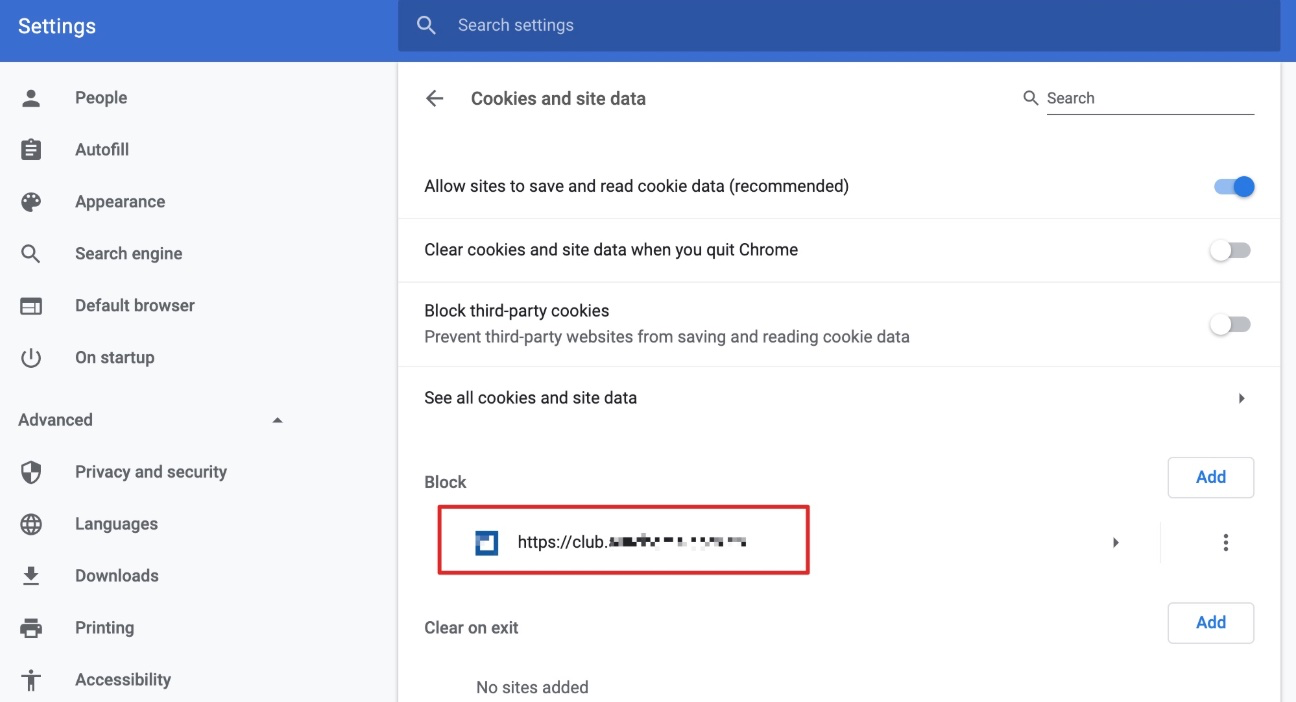
可以做一个实验来证实这一点,即打开 chrome,在 settings -> Cookies and site data -> Block 里添加此网站,然后再访问,发现网站确实出现了跟之前一样加载不出的情况。
2、帖子内容加密了,需要做字体反爬
在爬取帖子内容时,经常会出现一句话不全的情况,即少个别字,而这些字在浏览器打开则显示为粗体样式,复制粘贴出来则变成了。
看来此网站做了反爬措施。

目前已知的几个字体反爬的网站还有:猫眼,天眼查,起点中文网等。
(1)尝试
我用浏览器调试工具,发现这些口有两个特点:
1、这些口 ,虽然看上去一样,但是是不一样的。用上面”是“这个粗体字来当例子,复制它,粘贴到 站长工具 - unicode 编码转化 里,点 ”中文转 unicode“ ,发现他的 unicode 值为 \ued19。
2、这些口都被一个<span>包裹着,且用了 CSS3 的 @font-face,即:
<span style="font-family: myfont;"></span>
于是下载网站的字体文件(.ttf),用在线的 百度字体编辑器 打开,如下:
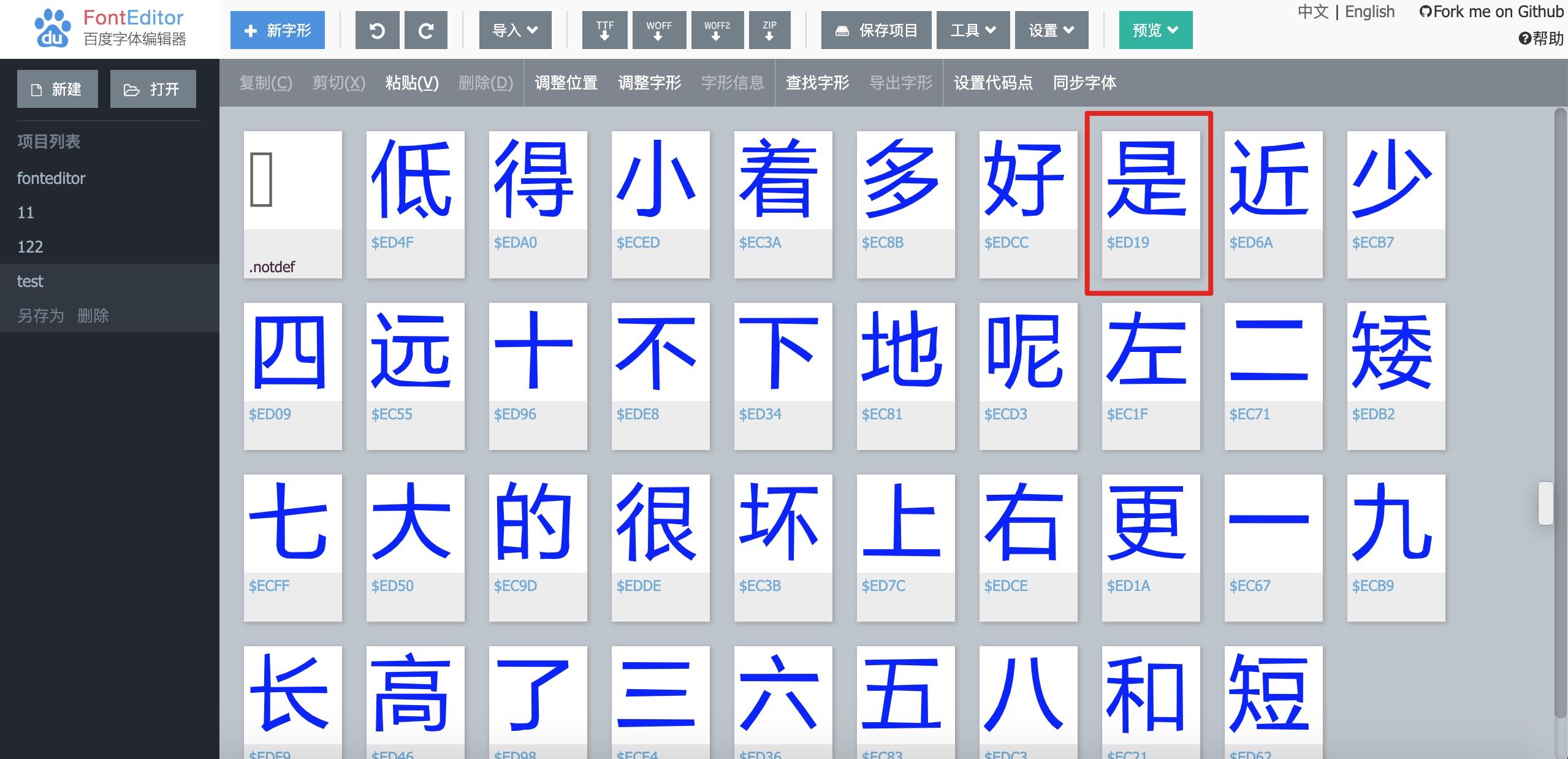
发现 "是" 这个字确实对应的是"$ED19"。
3、虽然上面我们找到了字体库里包含的口与实际汉字的对应关系,但是每次打开新的评论页面或者页面刷新,这个字体库都在实时的变化,即 口与实际汉字的对应关系也在不停的变化。
(2)解决办法
我尝试在 github 上搜索有没有过来人的经验,真的找到了:https://github.com/StuPeter/AutoHome_spider,利用这个第三方代码,我:
1、先抓取评论页的 page source,里面的口都显示为形如 
2、调用第三方代码,替换口为正常汉字
from AutoHomeFont import get_new_font_dict
# 第三方代码提供的标准.ttf,只管引用就好
standardFontPath = 'standardFont.ttf'
# 你当前评论页对应的.ttf(因为每次评论页.ttf都在变,所以需时刻保持最新)
newFontPath = 'car.ttf'
font_dict = get_new_font_dict(standardFontPath, newFontPath)
## 替换文字
# responseStr 为抓取评论页的 page source
responseStr = "……<span style='font-family: myfont;'></span>……"
for key, value in font_dict.items():
new_key = '&#x'+key[3:].lower()+';'
new_value = eval(repr(value).replace('\\\\', '\\'))
responseStr = responseStr.replace(new_key, new_value)
3、替换完成后,就可以顺利的进行接下来的 css selector 解析、入库了。
eval(repr(value).replace('\\', '\'))的作用是,第三方代码里对 unicode 的定义多了一个\,如\\u4f4e,所以需要在替换前减去一个\。

