
DDPM生成人脸代码
github: https://github.com/shixiaojia/ddpm.git
基于DDPM介绍的理论,简单实现DDPM生成人脸,代码如下:
utils.py
import os from torch.utils.data import Dataset from torchvision.transforms import transforms import glob import cv2 class MyDataset(Dataset): def __init__(self, img_path, device): super(MyDataset, self).__init__() self.device = device self.fnames = glob.glob(os.path.join(img_path+"*.jpg")) self.transforms = transforms.Compose([ transforms.ToTensor(), transforms.Resize((32, 32)), # transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) def __getitem__(self, idx): fname = self.fnames[idx] img = cv2.imread(fname, cv2.IMREAD_COLOR) img = self.transforms(img) img = img.to(self.device) return img def __len__(self): return len(self.fnames)
model.py
import math import torch import torch.nn as nn from torch.nn import init class Swish(nn.Module): def forward(self, x): return x * torch.sigmoid(x) class TimeEmbedding(nn.Module): def __init__(self, T, d_model, dim): assert d_model % 2 == 0, "error d_model!" super(TimeEmbedding, self).__init__() emb = torch.arange(0, d_model, step=2) / d_model * math.log(10000) emb = torch.exp(-emb) pos = torch.arange(T).float() X = pos[:, None] * emb[None, :] emb = torch.zeros(T, d_model) emb[:, 0::2] = torch.sin(X) emb[:, 1::2] = torch.cos(X) self.time_embedding = nn.Sequential(nn.Embedding.from_pretrained(emb), nn.Linear(d_model, dim), Swish(), nn.Linear(dim, dim)) self.initialize() def initialize(self): for module in self.modules(): if isinstance(module, nn.Linear): init.xavier_uniform_(module.weight) init.zeros_(module.bias) def forward(self, t): emb = self.time_embedding(t) return emb class DownSample(nn.Module): def __init__(self, in_ch): super(DownSample, self).__init__() self.down = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=3, stride=2, padding=1) self.initialize() def initialize(self): init.xavier_uniform_(self.down.weight) init.zeros_(self.down.bias) def forward(self, x, temb): x = self.down(x) return x class UpSample(nn.Module): def __init__(self, in_ch): super(UpSample, self).__init__() self.up = nn.ConvTranspose2d(in_channels=in_ch, out_channels=in_ch, kernel_size=2, stride=2, padding=0) self.conv = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=3, stride=1, padding=1) self.initialize() def initialize(self): init.xavier_uniform_(self.conv.weight) init.zeros_(self.conv.bias) init.xavier_uniform_(self.up.weight) init.zeros_(self.up.bias) def forward(self, x, temb): x = self.up(x) x = self.conv(x) return x class AttnBlock(nn.Module): def __init__(self, in_ch): super(AttnBlock, self).__init__() self.group_norm = nn.GroupNorm(32, in_ch) self.proj_q = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=1, stride=1, padding=0) self.proj_k = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=1, stride=1, padding=0) self.proj_v = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=1, stride=1, padding=0) self.proj = nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=1, stride=1, padding=0) self.initialize() def initialize(self): for module in [self.proj_q, self.proj_k, self.proj_v]: init.xavier_uniform_(module.weight) init.zeros_(module.bias) init.xavier_uniform_(self.proj.weight, gain=1e-5) def forward(self, x): N, C, H, W = x.shape h = self.group_norm(x) q = self.proj_q(h) k = self.proj_k(h) v = self.proj_v(h) q = q.permute(0, 2, 3, 1).view(N, H * W, C) k = k.view(N, C, H * W) score = q @ k * (C**-0.5) # N, H*W, H*W score = score.softmax(dim=-1) v = v.permute(0, 2, 3, 1).view(N, H*W, C) h = score @ v h = h.view(N, H, W, C).permute(0, 3, 1, 2) h = self.proj(h) return x + h # DownBlock = ResBlock + AttnBlock class ResBlock(nn.Module): def __init__(self, in_ch, out_ch, t_dim, dropout, attn=False): super(ResBlock, self).__init__() self.block1 = nn.Sequential(nn.GroupNorm(32, in_ch), Swish(), nn.Conv2d(in_channels=in_ch, out_channels=out_ch, kernel_size=3, stride=1, padding=1)) self.temb_proj = nn.Sequential( Swish(), nn.Linear(t_dim, out_ch) ) self.block2 = nn.Sequential( nn.GroupNorm(32, out_ch), Swish(), nn.Dropout(dropout), nn.Conv2d(in_channels=out_ch, out_channels=out_ch, kernel_size=3, stride=1, padding=1) ) if in_ch != out_ch: self.short_cut = nn.Conv2d(in_channels=in_ch, out_channels=out_ch, kernel_size=1, stride=1, padding=0) else: self.short_cut = nn.Identity() if attn: self.attn = AttnBlock(out_ch) else: self.attn = nn.Identity() self.initialize() def initialize(self): for module in self.modules(): if isinstance(module, (nn.Conv2d, nn.Linear)): init.xavier_uniform_(module.weight) init.zeros_(module.bias) init.xavier_uniform_(self.block2[-1].weight, gain=1e-5) def forward(self, x, temb): h = self.block1(x) h += self.temb_proj(temb)[..., None, None] h = self.block2(h) h += self.short_cut(x) h = self.attn(h) return h class UNet(nn.Module): def __init__(self, T, ch, ch_ratio, num_res_block, dropout): super(UNet, self).__init__() tdim = ch * 4 self.time_embedding = TimeEmbedding(T, ch, tdim) self.head = nn.Conv2d(in_channels=3, out_channels=ch, kernel_size=3, stride=1, padding=1) self.down_blocks = nn.ModuleList() chs = [ch] in_ch = ch for i, ratio in enumerate(ch_ratio): out_ch = ch * ratio for _ in range(num_res_block): self.down_blocks.append(ResBlock(in_ch=in_ch, out_ch=out_ch, t_dim=tdim, dropout=dropout, attn=True)) in_ch = out_ch chs.append(in_ch) if i != len(ch_ratio) - 1: self.down_blocks.append(DownSample(in_ch=in_ch)) chs.append(in_ch) self.middle_blocks = nn.ModuleList([ResBlock(in_ch=in_ch, out_ch=in_ch, t_dim=tdim, dropout=dropout, attn=True), ResBlock(in_ch=in_ch, out_ch=in_ch, t_dim=tdim, dropout=dropout, attn=False)]) self.up_blocks = nn.ModuleList() for i, ratio in reversed(list(enumerate(ch_ratio))): out_ch = ch * ratio for _ in range(num_res_block+1): self.up_blocks.append(ResBlock(in_ch=chs.pop()+in_ch, out_ch=out_ch, t_dim=tdim, dropout=dropout, attn=True)) in_ch = out_ch if i != 0: self.up_blocks.append(UpSample(in_ch=in_ch)) self.tail = nn.Sequential(nn.GroupNorm(32, in_ch), Swish(), nn.Conv2d(in_channels=in_ch, out_channels=3, kernel_size=3, stride=1, padding=1)) self.initialize() def initialize(self): init.xavier_uniform_(self.head.weight) init.zeros_(self.head.bias) init.xavier_uniform_(self.tail[-1].weight) init.zeros_(self.tail[-1].bias) def forward(self, x, t): temb = self.time_embedding(t) h = self.head(x) # down hs = [h] for layer in self.down_blocks: h = layer(h, temb) hs.append(h) # middle for layer in self.middle_blocks: h = layer(h, temb) # up for layer in self.up_blocks: if isinstance(layer, ResBlock): h = torch.cat([h, hs.pop()], dim=1) h = layer(h, temb) h = self.tail(h) return h if __name__ == '__main__': batch_size = 8 net = UNet(T=1000, ch=128, ch_ratio=[1, 2, 2, 2], num_res_block=3, dropout=0.1) x = torch.rand(batch_size, 1, 32, 32) y = torch.randint(1000, (batch_size, )) y = net(x, y) torch.save(net.state_dict(), "model_______.pth")
diffusion.py
import torch import torch.nn as nn import torch.nn.functional as F def extract(v, t, x_shape): """ Extract some coefficients at specified timesteps, then reshape to [batch_size, 1, 1, 1, 1, ...] for broadcasting purposes. """ out = torch.gather(v, index=t, dim=0).float() return out.view([t.shape[0]] + [1] * (len(x_shape) - 1)) class GaussionDiffusion(nn.Module): def __init__(self, model, image_size, image_channel, beta_1, beta_T, T): super(GaussionDiffusion, self).__init__() self.model = model self.image_size = image_size self.image_channel = image_channel self.T = T betas = torch.linspace(beta_1, beta_T, T).double() alphas = 1. - betas alphas_bar = torch.cumprod(alphas, dim=0) self.register_buffer("betas", betas) self.register_buffer("sqrt_alphas_bar", torch.sqrt(alphas_bar)) self.register_buffer("sqrt_one_minus_alphas_bar", torch.sqrt(1. - alphas_bar)) self.register_buffer("remove_noise_coef", betas/torch.sqrt(1-alphas_bar)) self.register_buffer("reciprocal_sqrt_alphas", 1./torch.sqrt(alphas)) self.register_buffer("sigma", torch.sqrt(betas)) def forward(self, x_0): """ Algorithm 1. """ t = torch.randint(self.T, size=(x_0.shape[0], ), device=x_0.device) noise = torch.randn_like(x_0) x_t = ( extract(self.sqrt_alphas_bar, t, x_0.shape) * x_0 + extract(self.sqrt_one_minus_alphas_bar, t, x_0.shape) * noise) loss = F.mse_loss(self.model(x_t, t), noise, reduction='mean') return loss def sample(self, batch_size, device): x = torch.randn(batch_size, self.image_channel, self.image_size, self.image_size, device=device) for t in reversed(range(self.T)): # t = x_t.new_ones([x_t.shape[0], ], dtype=torch.long) * time_step t_batch = torch.tensor([t], device=device).repeat(batch_size) x = (x - extract(self.remove_noise_coef, t_batch, x.shape) * self.model(x, t_batch)) * \ extract(self.reciprocal_sqrt_alphas, t_batch, x.shape) if t > 0: x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x) return x
train.py
import torch
import argparse
from torch.utils.data import DataLoader
from torch.optim import Adam
from utils import MyDataset
from torchvision.utils import save_image
from tqdm import tqdm
# from unet import UNet
from model import UNet
from diffusion import GaussionDiffusion
def args_parser():
parser = argparse.ArgumentParser(description="Parameters of training vae model")
parser.add_argument("-b", "--batch_size", type=int, default=64)
parser.add_argument("-i", "--in_channels", type=int, default=3)
parser.add_argument("-d", "--latent_dim", type=int, default=64)
parser.add_argument("-l", "--lr", type=float, default=1e-4)
parser.add_argument("-w", "--weight_decay", type=float, default=1e-5)
parser.add_argument("-e", "--epoch", type=int, default=500)
parser.add_argument("-v", "--snap_epoch", type=int, default=1)
parser.add_argument("-n", "--num_samples", type=int, default=64)
parser.add_argument("-p", "--path", type=str, default="./results_linear")
parser.add_argument("--T", type=int, default=1000)
parser.add_argument("--ch", type=int, default=64)
parser.add_argument("--ch_ratio", type=list, default=[1, 2, 2, 2])
parser.add_argument("--num_res_block", type=int, default=2)
parser.add_argument("--dropout", type=float, default=0.1)
parser.add_argument('--beta_1', type=float, default=1e-4, help='start beta value')
parser.add_argument('--beta_T', type=float, default=0.02, help='end beta value')
parser.add_argument('--mean_type', type=str, choices=['xprev', 'xstart', 'epsilon'], default='epsilon', help='predict variable')
parser.add_argument('--var_type', choices=['fixedlarge', 'fixedsmall'], default='fixedlarge', help='variance type')
parser.add_argument("--image_size", type=int, default=32)
parser.add_argument("--image_channels", type=int, default=3)
return parser.parse_args()
if __name__ == '__main__':
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
opt = args_parser()
dataset = MyDataset(img_path="../faces/", device=DEVICE)
# trans = transforms.Compose([transforms.ToTensor(),transforms.Resize((32, 32))])
# dataset = MNIST("./mnist_data", download=True, transform=trans)
train_loader = DataLoader(dataset=dataset, batch_size=opt.batch_size, shuffle=True, num_workers=4)
model = UNet(T=opt.T, ch=opt.ch, ch_ratio=opt.ch_ratio, num_res_block=opt.num_res_block, dropout=opt.dropout)
# model = UNet(opt.in_channels, opt.latent_dim)
diffusion = GaussionDiffusion(model, opt.image_size, opt.image_channels, opt.beta_1, opt.beta_T, opt.T).to(DEVICE)
optimizer = Adam(diffusion.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
for epoch in range(opt.epoch):
diffusion.train()
# data_bar = tqdm(train_loader)
for step, x_0 in enumerate(train_loader):
pbar = tqdm(total=len(train_loader), desc=f"Epoch {step + 1}/{len(train_loader)}")
optimizer.zero_grad()
loss = diffusion(x_0.to(DEVICE))
loss.backward()
optimizer.step()
if epoch % opt.snap_epoch == 0 or epoch == opt.epoch - 1:
diffusion.eval()
with torch.no_grad():
images = diffusion.sample(opt.num_samples, device=DEVICE)
imgs = images.detach().cpu().numpy()
fname = './my_generated-images-epoch_{0:0=4d}.png'.format(epoch)
save_image(images, fname, nrow=8)
torch.save(diffusion.state_dict(), f"./model_step_{epoch}.pth")
没有调参,模型生成的结果如下:
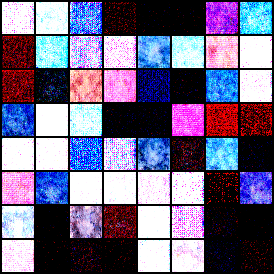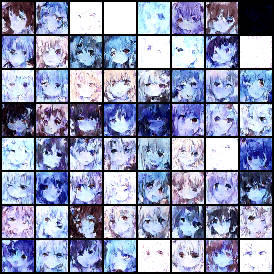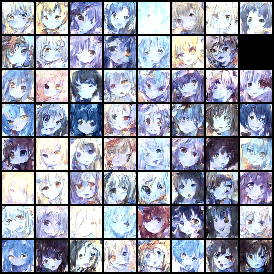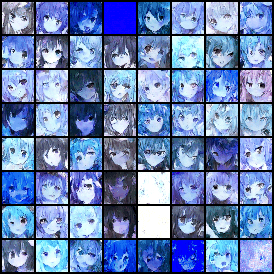

 浙公网安备 33010602011771号
浙公网安备 33010602011771号