
Vision Transformer(VIT)
1.ViT 介绍
Vision Transformer是在最少改动Transformer结构的情况下,将Transformer应用到图像上。因此,将图片划分成patch,并将这些patch的线性嵌入序列作为输入,具体在下面详细介绍。这里的图像patch和NLP中的token相同。
但是在中等大小的数据集上(例如:ImageNet)训练的到的模型没有很好的效果,和同等规模的ResNet相比,Transformer结构低了几个百分点的精度。然而这种看似令人沮丧的结果可能是意料之中的。因为Transformer缺乏
像CNN那样的归纳偏置,例如平移不变性和空间局部性。因此,在数据量不足的情况下进行训练时,不能很好地进行泛化。然而,如果模型在更大的数据集上(14M-300M images)训练,情况就会发生变化,大规模训练胜过
归纳偏置。当然,当有足够的数据上进行预训练,并迁移到数据较少的任务时,Vision Transformer也取得了很好的效果。当模型在公开的ImageNet-21k或者JFT-300M数据集上进行预训练,ViT在多个图像识别benchmark上接
近或者击败了SOTA。
Transformer一般需要在大的数据集上进行预训练,然后针对手头的任务进行微调。将self-attention应用于图像最naive的方法,需要将在pixel level上实现,但是这会引起像素数量的平方的成本,因此这种方式无法扩展到现实中。
所以ViT是对patch进行self-attention。
2. ViT模型结构
一、VIT,即纯transformer模型
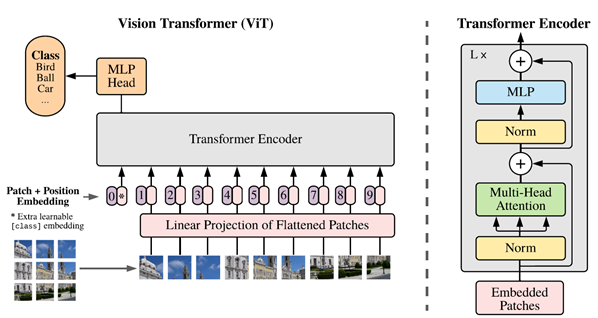
图1 VIT 架构
VIT模型的架构如图1所示。主要分为三个步骤:
1. 首先将输入的图片分成patches(如16*16的patch),然后将每个patch输入到Embedding层(即Linear Projection of Flattened Patches)得到一系列的向量(即token)。然后在这些token的最前面加上一个新的token,也就是用于分类的class token(图1中的*)(这里参考了BERT的[class] token),这个class token的dimension和之前的每一个token一致。然后还需要加上位置的信息(即Position Embedding);
2. 得到上述token之后,输入到Transformer Encoder中。Transformer Encoder的结构如图1右侧所示;
3. 最后将class token所对应的输出,通过MLP Head得到最终分类的结果;其中,MLP包含两个具有GELU非线性的层。
具体细节如下:
1. Embedding层
对于标准的Transformer模块,要求输入的是token(即向量序列),即二位矩阵[num_token, token_dim]
在代码中,直接通过一个卷积来实现。假设patch size为16,使用卷积核大小为16*16,stride为16,卷积核个数为768(16*16*3),即:
[224, 224, 3] -> [14, 14, 768] -> [196, 768]
在输入Transformer Encoder之前需要加上class token以及Position Embedding,都是可训练的参数。
然后拼接class token:concat([1,768], [196, 768]) -> [197, 768]
最后叠加Position Embedding:[197, 768] -> [197, 768]
2. Transformer Encoder层
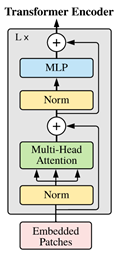
图2 Transformer Encoder结构
如图2所示,Transformer Encoder其实就是将Transformer Block重复堆叠L次。
3. MLP Head层
即Linear层。
二、Hybrid,即传统的CNN和Transformer混合模型
混合模型就是先使用传统的卷积神经网络(比如resnet网络)提取特征,然后再通过VIT模型进一步得到最终的结果。
使用ResNet50网络提取特征。但是在ResNet50网络上进行了修改:
1. 卷积层使用stdConv2d而不是传统的Conv2d;
2. 将所有的BatchNorm层替换成GroupNorm层;
3. 把stage4中的3个Block移至stage3中;
上述是使用class toke进行分类,但是是否可以使用image-patch embeddings然后使用GAP,最后是线性分类器呢?答案是可以的。如下图所示,但是学习率需要调节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号