
生成式AI之GAN
1. GAN原理
1.1 从比较直观的角度理解
如图1、2所示,GAN包括一个生成器Generator和一个判别器Discriminator。其中,Generator是根据输入的一个vector生成一个图片,而判别器是将生成的图片输入网络,输出该图片为真实图片的概率。

图1 Generator

图2 Discriminator
如图3所示,训练GAN,首先需要有真实图像的数据集。一开始Generator参数是随机的,只能产生的图片类似噪声的图片。然后,Discriminator是去判别是生成的图片(fake images)还是真实的图片(true images);
然后,Generator需要做的是想办法骗过第一代(上一次)的Discriminator。(第一代的Discriminator可以分辨第一代的Generator生成的图片还是真实的图片;第二代的Generator进化了,想要骗过第一代的Discriminator。)
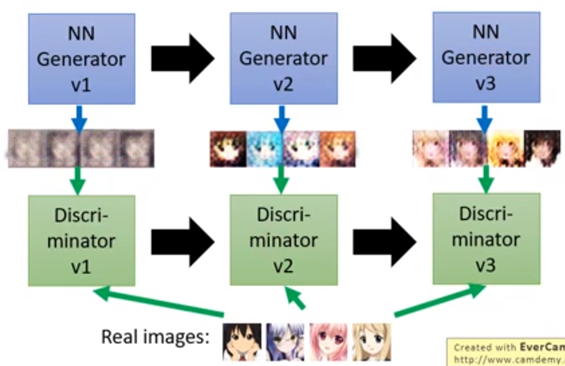
图3 GAN训练过程
其中,GAN可以理解为:Generator是一个学生,Discriminator是一个老师。
Algorithm算法:
Initialize generator and discriminator : G, D;
In each training iteration:
Step1: Fix generator G, and update discriminator D;
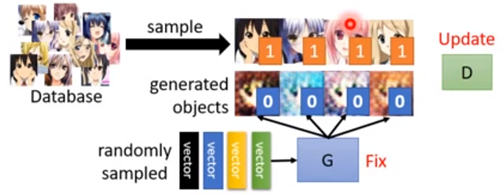
图4 训练Discriminator过程
(Discriminator learns to assign high scores to real objects and low scores to generated objects.)
Step2: Fix Discriminator D, and update Generator G;
Generator learns to “fool“ the discriminator
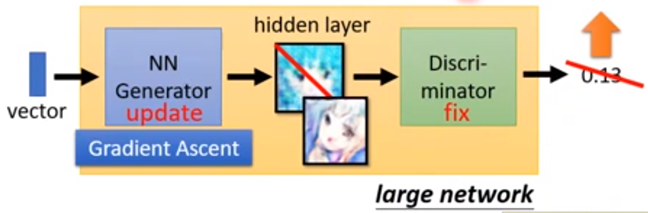
图5 训练Generator过程
Algorithm
Initialize $\theta _{d}$ for D and $\theta _{g}$ for G
Learning D:
In each training iteration:
Sample N examples ${x^{1},x^{2}, ..., x^{N}}$ from database
Sample N noise samples ${z^{1},z^{2}, ..., z^{N}}$ from a distribution
Obtaining generated data ${\tilde{x} ^{1}, \tilde{x} ^{2}, ..., \tilde{x} ^{N}}$,
Update Discriminator parameters $\theta _{d}$ to maximize:
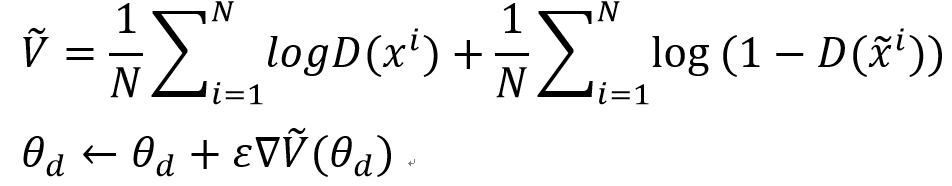
Learning G:
Sample N noise samples ${z^{1},z^{2}, ..., z^{N}}$ from a distribution
Update Generator parameters $\theta _{g}$ to maximize:
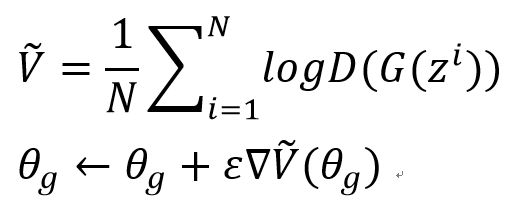
1.2 从数学角度理解
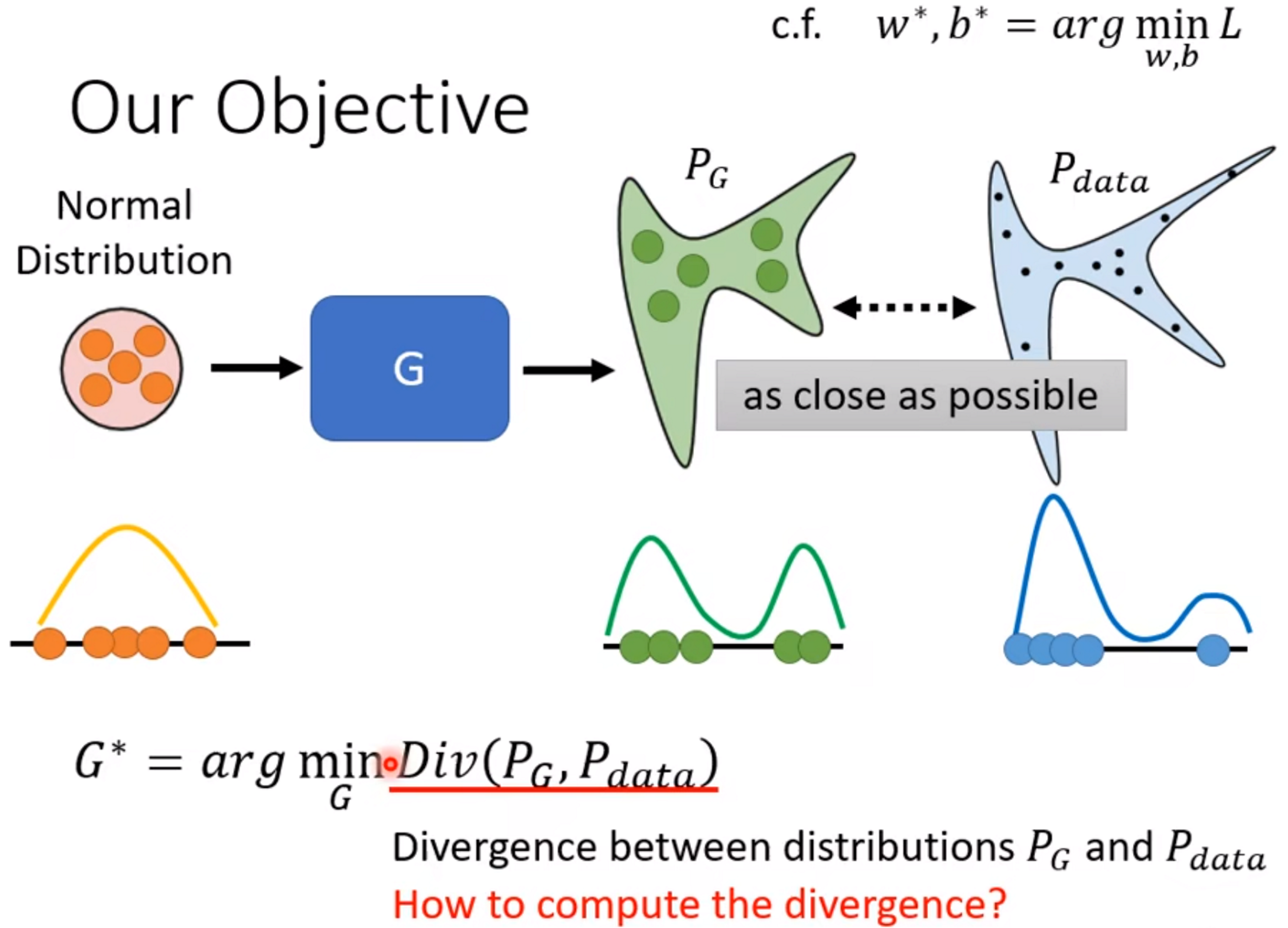
对于生成器Generator,学习的目标objective是使得生成的数据的distribution和真实数据的distribution之间的divergence越小越好(两个数据分布越接近越好)。
但是P_G 和P_data 的formulation不知道,怎么样计算divergence?这就是GAN的神奇之处,通过Discriminator,GAN可以突破计算divergence的限制。
如图所示,虽然我们不知道P_G 的distribution和P_data 的distribution,但是我们可以从这个分布中进行采样。
从$P_{data}$中sample出real data,从$P_{G}$中sample出Generated data,然后通过这些数据训练一个Discriminator。训练的目标是对于real data,给它一个高的分数;而对于generated data,给它一个低的分数。其过程如下:
Training: $D^{*}=arg\underset{D}{max}V(D,G)$
Objective function: $V(D,G)=E_{x\sim P_{data}}[logD(y)]+ E_{x\sim P_{G}}[log(1-D(y))]$
其中,$\underset{D}{max}V(D,G)$跟JS divergence相关。(注意在train Discriminator时,Generator是固定住的)。

因此,maximize的value就是$P_{G}$和$P_{data}$ 的JS Divergence,而GAN的Generator的objective function是找一个G,去minimize$P_{G}$ 和$P_{data}$的JS Divergence,但是因为不知道其真实分布,divergence无法计算。
但是可以通过Discriminator的objective function计算,maximize Discriminator的objective function就是$P_{G}$和$P_{data}$的JS Divergence。因此,GAN的Generator的objective function可以做如下转换:
$G^{*}=arg\underset{G}{min}Div(P_{G},P_{data}) ->G^{*}=arg\underset{G}{min}\underset{D}{max}V(D,G)$。
训练顺序如下,就是在求解min max的问题:

上述是原始的GAN paper的objective function,所以跟JS Divergence相关。如果修改objective function,则可以是不同的divergence(查看f-GAN的paper)。
Original GAN的缺陷以及WGAN
由于GAN的objective function和JS Divergence,而JS Divergence不适合训练GAN。原因如下:
大多数情况下,$P_{G}$ 和$P_{data}$ 往往重叠很少。
JS Divergence有一个特性,就是两个没有重叠的分布,JS Divergence的值永远是log2。
如下图所示,后面的情况比前面的情况要好,但是JS Divergence都是log2,看不出好坏,在training的时候loss一样,无法训练。

为了解决上述问题,可以设置不同的损失objective function,使得优化的不再是JS Divergence,下面介绍基于
Wasserstein distance的优化方法。
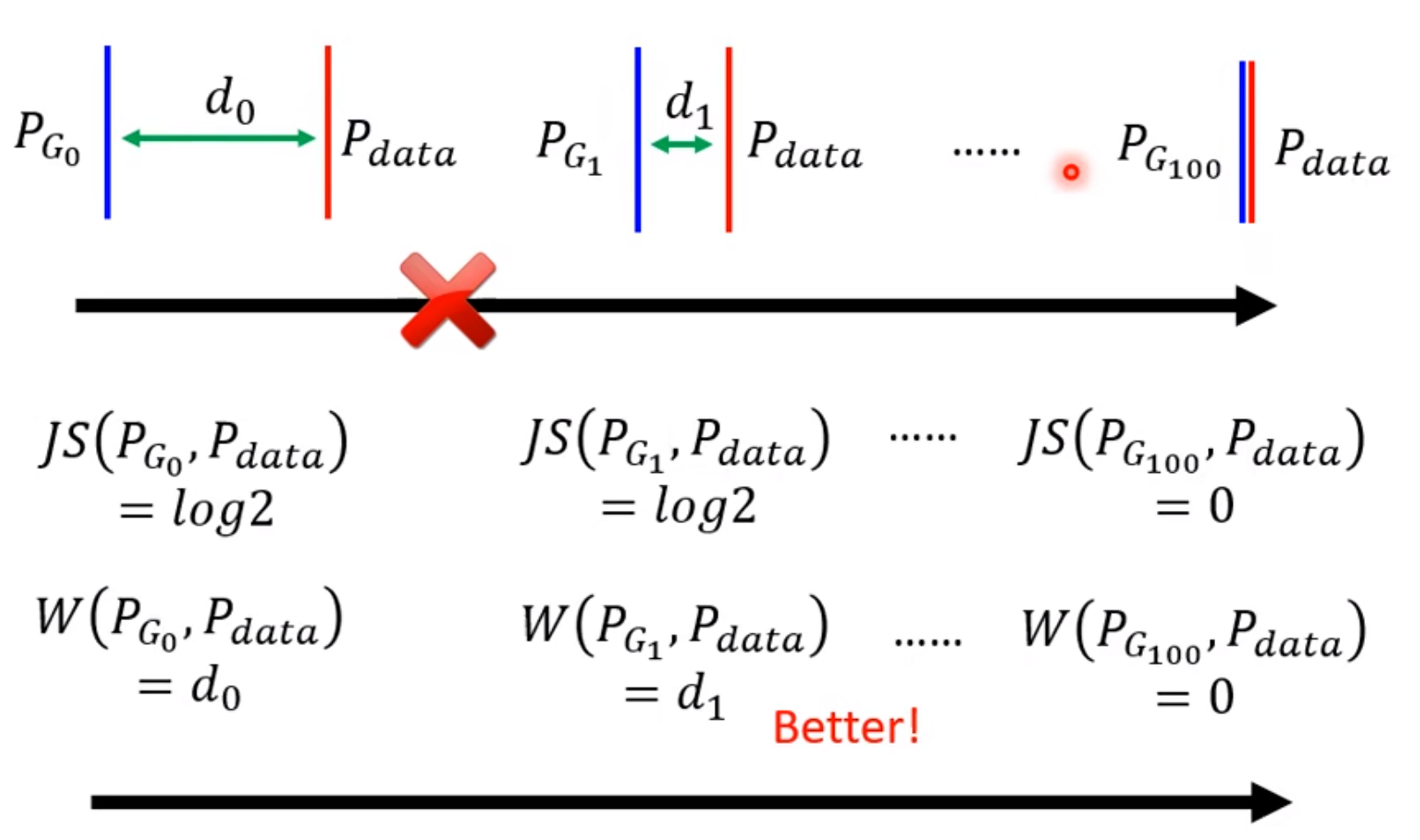
换一个计算divergence的方法,就可以解决JS Divergence带来的问题。Wasserstein distance可以看出从左往右越来越好。
其实,求解如下公式,就可以求出Wasserstein distance:
$\underset{D\in 1-Lipschitz}{max}\left \{E_{y\sim data}[D(x)]-E_{y\sim P_{G}}[D(x)]\right \} $,其中,其实,D∈1−Lipschitz的目的是使得D最够平滑。无法收敛。

如果real data和generated data距离很接近,需要限制无法让Discriminator判断real data的值很大,让Discriminator判断generated data的值很小。
如果real data和generated data距离比较远,则Discriminaror的值就可以相差很多。
实现WGAN可以通过weight clip、Spectral Normalizationh或者gradient penalty等。
GAN训练技巧
PGGAN
Minibatch discriminator
由这种思想指导出来最有用的方法就是 Minibatch discrimination。我们将生成的图像和真实的图像划入到一个一个的batch中。对于同一batch下的不同sample(图像),我们会计算它和其他图像的似然度,并将这类信息添加到 discriminator 的 cost function 中。当mode collapse 发生时,图片的相似度上升,于是cost 也就增加了,从而惩罚generator。
Minibatch discrimination 这种方法较为复杂,而且可学习的参数较多,因此本文作者 Tero Karras 对其进行优化,创造了现在的 Minibatch standard deviation,非常简洁,而且代码很是方便书写。
不过论文中的叙述,倒是非常的绕,我是结合代码才看懂他在说什么。
Minibatch std 既没有可学习的参数也没有需要人为调控的超参数,而且计算方法也较为简单。首先,我们对 N, C, H, W 的张量,沿着 BatchSize(N) 计算standard deviation,产生 1, C, H, W 的张量,然后对其平均 avg 得到一个常数 scaler,然后将常量复制多次 reshape 成为 N, 1, H, W 的形状,作为一个特征层 concat 到我们原本 N, C, H, W 的张量中,得到 N, C+1, H, W 形状的张量。(是不是比 Minibatch Discriminator 简单多了)。但是中心思想还是没变,衡量多个样本之间的距离,不过 minibatch std 将其浓缩成了一个 scaler,然后 expand 形成一个 特征层。
def minibatch_std(self, x):
batch_statistics = (
torch.std(x, dim=0).mean().repeat(x.shape[0], 1, x.shape[2], x.shape[3])
)
# we take the std for each example (across all channels, and pixels) then we repeat it
# for a single channel and concatenate it with the image. In this way the discriminator
# will get information about the variation in the batch/image
return torch.cat([x, batch_statistics], dim=1)
One-sided label smoothing
特征匹配
GAN代码在GAN生成人脸代码一节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号