物体检测项目
1、项目介绍
1.1 项目架构设计
实现基于tensorflow的物体检测。项目框架主要分为三部分:数据采集层、深度模型层、用户层。其中,数据采集层用于对数据进行标记以及转换成TFRecords格式数据文件。深度模型层的功能是读取数据采集层输出的TFRecords数据进行数据的预处理以及对深度模型的训练,其中深度模型可以使用不同的框架(例如SSD、YOLO等),通过模型工厂进行选择,本项目中使用SSD物体检测框架。训练得到的模型通过tensorflow serving进行部署,提供给后台。用户层通过前端和后台业务交互得到想要的结果。项目结构如下:
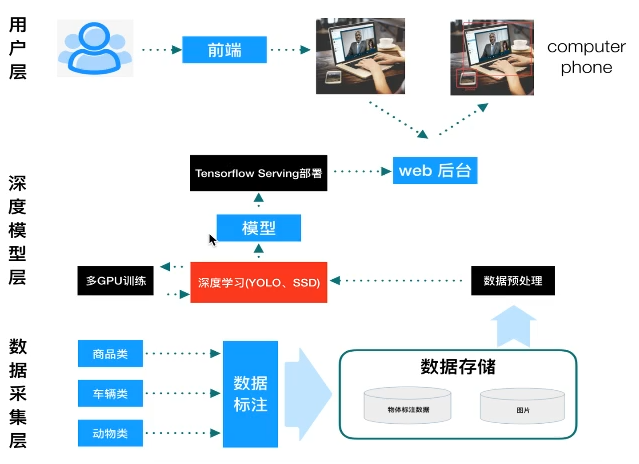
图1 物体检测项目框架
使用TensorflowServing进行模型部署有以下几个好处:
1、可以进行模型的热更新:只要上传模型文件到服务器上即可,TensorFlow会自动识别模型并使用,不需要重启serving 服务。
2、导出模型和使用模型进行解耦合
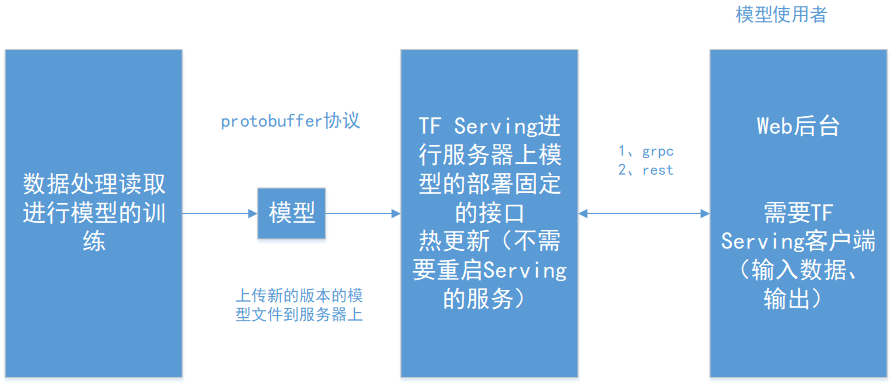
图2 TensorflowServing模型部署逻辑
整个项目开发流程主要分为两大部分:
1.模型的训练与测试
训练
数据集处理(将数据转换成TFRecords格式文件)
数据读取
preprocess(数据预处理)
网络构建预测结果
损失计算并训练
模型保存
测试
测试数据
preprocess(数据预处理)
模型加载
postprocess(预测结果后期处理)
预测结果显示(matplotlib)
2、模型部署与小程序
模型导出
TensorFlow Serving部署模型
Serving客户端+Flask Web
小程序前端
1.2 项目代码训练架构设计
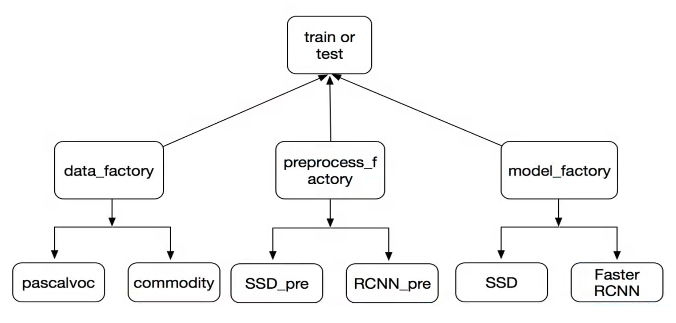
图2 项目代码训练架构设计
其中:
1.数据集工厂(data factory)
为了使项目能够读取不同的数据集
2.预处理工厂(preprocess factory)
为了处理不同模型要求的处理需求
3.模型工厂(model factory)
为了项目训练数据能够使用不同的模型
1.3 训练代码架构设计意义
1.网络模型和网络模型之间不交叉,模型和数据之间解耦合,数据集与预处理逻辑之间解耦合;
2.训练代码可以调用不同的模型与不同的数据集训练不同的模型结果。
2. 数据模块接口
获取到的图片数据集,保存在IMAGE/commodity/JPEGImages文件下。使用图片标记工具(本项目使用labelimg)将图片进行标记,输出XML格式文件,保存在 IMAGE/commodity/Annotatons文件下。这样的数据集类似PASCAL VOC数据集,数据集的图片和标记文件分布在不同的文件中,并且图片和标签没有一一对应,后续项目中不方便处理,也不方便项目的解耦合。tensorflow提供了TFRecord个数来统一存储数据,TFRecord格式是一种将图像数据和标签数据存放在一起的二进制文件,在tensorflow中能够快速处理。因此项目中需要将数据集转换成TFRecords文件。TFRecord文件中的数据是通过tf.train.Example Protocol Buffer格式存储的。每个我想ample对应一张图片,其中包括图片的各种信息。特点是:
1)体积小,消息大小只需要xml文件的1/10~1/3;
2)解析速度快:解析速度比xml块20~100倍。
其中,tf.train.Example的定义见本博客的《TFRecord数据处理》一节。
2.1 数据转换成TFRecord格式文件
2.1.1 转换步骤:
1)设定每个tfrecord文件中保存多的样本个数
2)读取每张图片内容以及xml文件
3)将每次去读内容写入tfrecord文件
2.1.2 数据转换成TFRecord文件
代码结构如图所示:
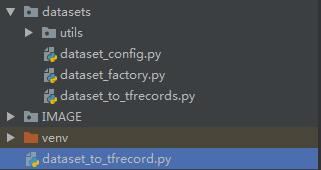
图3 图片转换成tfrecord文件
其中,datasets文件夹下的utils存放读取数据的公用组件;dataset_config.py存放数据读取的配置;dataset_to_tfrecords.py为主要的数据转换逻辑。dataset_to_tfrecord.py文件执行dataset_to_tfrecords.py中的run()函数完成数据转换。具体代码如下:
2.1.2.1 配置文件dataset_config.py如下:
""" 数据集转换配置文件 """ # 指定原始图片的XML和图片的文件夹名字 DIRECTORY_ANNOTATIONS = "Annotations/" DIRECTORY_IMAGES = "JPEGImages/" # 指定每个TFRecord文件存储example的数量 SAMPLER_PER_FILES = 200 # 定义字典,保存数据集的类别 # 字典的key是类别,字典的value是一个元组 # 元组的元素不能修改,元组中是类别代表的数字和类别 VOC_LABELS = { 'none': (0, 'Background'), 'clothes': (1, 'clothes'), 'pants': (2, 'pants'), 'shoes': (3, 'shoes'), 'watch': (4, 'watch'), 'phone': (5, 'phone'), 'audio': (6, 'audio'), 'computer': (7, 'computer'), 'books': (8, 'books') }
2.1.2.2 utils文件下的dataset_utils.py文件中,编写定义tf Example需要的feature转换公式,代码如下:
import tensorflow as tf # 生成整数型的属性 def int64_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(int64_list=tf.train.Int64List(value=value)) # 生成浮点型的属性 def float_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(float_list=tf.train.FloatList(value=value)) # 生成字符串类型的属性 def bytes_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
2.1.2.3 dataset_to_tfrecords.py文件下主要编写编写转换逻辑,代码如下:
import tensorflow as tf import os import xml.etree.ElementTree as ET from datasets.dataset_config import DIRECTORY_ANNOTATIONS, DIRECTORY_IMAGES, SAMPLER_PER_FILES, VOC_LABELS from datasets.utils.dataset_utils import int64_feature, float_feature, bytes_feature # 获取输出的TFRecord文件名字,格式如下:commodity_2018_train_xxx.tfrecord # xxx代表序号,从000开始 def _get_output_filename(outputdir, dataset_name, fdx): """ 获取输出的TFRecord文件的名字 :param outputdir: 输出路径 :param dataset_name: 数据集名字 :param fdx: 文件id :return: """ return "%s/%s_%03d.tfrecord" % (outputdir, dataset_name, fdx) def _process_image(dataset_dir, image_name): """ 处理一张图片的数据:获取图片数据以及xml文件中的内容。根据需要获取 :param dataset_dir: 数据集路径 :param img_name: 图片名字 :return: """ # 图片路径 + 图片名字 filename = dataset_dir + DIRECTORY_IMAGES + image_name + '.jpg' # 读取图片数据 image_data = tf.gfile.FastGFile(filename, 'rb').read() # 读取xml数据,使用ET工具 # 构造xml文件名字 filename_xml = dataset_dir + DIRECTORY_ANNOTATIONS + image_name + '.xml' # 将文件内容转换成树状结构tree tree = ET.parse(filename_xml) # 获取root节点 root = tree.getroot() # 获取root节点下面的子节点 # 1、获取size信息 size = root.find('size') # 把height、width、depth存放在一个shape里面 shape = [int(size.find('height').text), int(size.find('width').text), int(size.find('depth').text)] # 用于存储object对应的label的编号 labels = [] labels_text = [] difficults = [] truncated = [] bboxes = [] # 2、获取 object信息 for obj in root.findall('object'): # 解析每一个object,包含name、difficult、truncated、bndbox[xmin, ymin, xmax, ymax] # 取出label和与之对应的数字 label = obj.find('name').text labels.append(int(VOC_LABELS[label][0])) labels_text.append(label.encode('ascii')) # 取出difficult if obj.find('difficult'): difficults.append(int(obj.find('difficult').text)) else: # 不存在,默认difficult为0 difficults.append(0) # 取出truncated if obj.find('truncated'): truncated.append(int(obj.find('truncated').text)) else: # 不存在,默认truncated为0 truncated.append(0) # 取出bndbox bbox = obj.find('bndbox') bboxes.append([float(bbox.find('ymin').text)/shape[0], float(bbox.find('xmin').text) / shape[1], float(bbox.find('ymax').text) / shape[0], float(bbox.find('xmax').text) / shape[1]]) return image_data, shape, labels, labels_text, difficults, truncated, bboxes def _convert_to_example(image_data, shape, labels, labels_text, difficults, truncated, bboxes): """ 将图片数据转换成example protocol buffer格式 :param image_data: :param shape: :param labels: :param difficults: :param truncated: :param bboxes: :return: """ # bboxes存储格式如下:[[a0, b0, c0, d0], [a1, b1, c1, d1]]转换成 # ymin[a0, a1], xmin[b0, b1], ymax[c0, c1], xmax[d0, d1] ymin = [] xmin = [] ymax = [] xmax = [] for b in bboxes: ymin.append(b[0]) xmin.append(b[1]) ymax.append(b[2]) xmax.append(b[3]) # 将所有信息封装成example image_format = b'JPEG' example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': int64_feature(shape[0]), 'image/width': int64_feature(shape[1]), 'image/channels': int64_feature(shape[2]), 'image/shape': int64_feature(shape), 'image/object/bbox/ymin': float_feature(ymin), 'image/object/bbox/xmin': float_feature(xmin), 'image/object/bbox/ymax': float_feature(ymax), 'image/object/bbox/xmax': float_feature(xmax), 'image/object/bbox/label': int64_feature(labels), 'image/object/bbox/difficult': int64_feature(difficults), 'image/object/bbox/truncated': int64_feature(truncated), 'image/object/bbox/label_text': bytes_feature(labels_text), 'image/format': bytes_feature(image_format), 'image/encoded': bytes_feature(image_data)})) return example def _add_to_tfrecord(dataset_dir, image_name, tfrecord_writer): """ 添加一个图片文件和xml内容写入文件中 :param dataset_dir: 数据集目录 :param img_name: 图片名 :param tfrecord_writer: 文件写入实例 :return: """ # 1、读取每张图片内容及其对应的xml文件的内容 image_data, shape, labels, labels_text, difficults, truncated, bboxes = _process_image(dataset_dir, image_name) # 2、将每张图片的数据封装成一个example example = _convert_to_example(image_data, shape, labels, labels_text, difficults, truncated, bboxes) # 3、使用tfrecord_writer将example序列化结果写入TFRecord文件 tfrecord_writer.write(example.SerializeToString()) return None def run(dataset_dir, output_dir, dataset_name="data"): """ 运行转换代码逻辑:存入tfrecord文件,每个文件固定N个样本 :param dataset_dir: 数据集目录 :param output_dir: TFRecord存储目录 :param dataset_name: 数据集名字,指定名字以及train_or_test :return: """ # 1、判断数据集目录是否存在,不存在则创建一个目录 if not tf.gfile.Exists(dataset_dir): tf.gfile.MakeDirs(dataset_dir) # 2、读取某个文件夹下的所有文件名字列表 path = os.path.join(dataset_dir, DIRECTORY_ANNOTATIONS) # 读取所有文件,返回所有文件名字列表。但是会打乱顺序,需要使用sorted函数进行排序 filenames = sorted(os.listdir(path)) # 3、循环遍历列表,每N张图片和XML信息存储到一个tfrecord文件中 i = 0 fdx = 0 while i < len(filenames): # 1、创建TFRecord文件 tf_filename = _get_output_filename(output_dir, dataset_name, fdx) # 每N个文件存储一次 # 新建tfrecord的存储器 with tf.python_io.TFRecordWriter(tf_filename) as tfrecord_writer: j = 0 while i < len(filenames) and j < SAMPLER_PER_FILES: print("转换图片进度%d/%d" % (i+1, len(filenames))) # 取出图片以及xml的名字 single_filename = filenames[i] image_name = single_filename[:-4] # 读取图片和xml内容,存入图片,每次构造一个图片文件存储指定文件 _add_to_tfrecord(dataset_dir, image_name, tfrecord_writer) i += 1 j += 1 # 每N个数据,文件id增加计数 fdx += 1 print("数据集 %s 转换成功" % dataset_name)
2.1.2.4 dataset_to_tfrecords.py文件代码
from datasets import dataset_to_tfrecords if __name__ == '__main__': dataset_to_tfrecords.run('./IMAGE/commodity/', './IMAGE/tfrecords/commodity_tfrecords/', 'commodity_2018_train')
为了实现数据格式的转换,需要在图3的IMAGE文件夹下分别放置如下目录:
commodity/Annotations/
commodity/JPEGImages/
tfrecords/commodity_tfrecords/
其中,commodity/Annotations/路径下存放标记过的xml格式文件;commodity/JPEGImages/路径下存放于xml格式对应的图片数据;tfrecords/commodity_tfrecords/路径用于存放转换好的tfrecord格式数据。
2.2 TFRecord格式文件读取
TFRecord文件读取有两种方法:
1)使用tensorflow进行实现
2)使用tensorflow.slim库进行实现
本项目使用tensorflow.slim进行实现,具体步骤如下:
1、定义解码器decoder
decoder = tf.slim.tfexample_decoder.TFExampleDecoder()
其中,定义解码器时,需要制定两个参数:keys_to_features,和items_to_handlers两个字典参数。key_to_features这个字典需要和TFrecord文件中定义的字典项匹配。items_to_handlers中的关键字可以是任意值,但是它的handler的初始化参数必须要来自于keys_to_features中的关键字。
2、定义dataset
dataset= tf.slim.dataset.Dataset()
其中,定义dataset时需要将datasetsource、reader、decoder、num_samples等参数
3、定义provider
provider = slim.dataset_data_provider.DatasetDataProvider
其中,需要的参数为:dataset, num_readers, reader_kwargs, shuffle, num_epochs,common_queue_capacity,common_queue_min, record_key=',seed, scope等。
4、调用provider的get方法
获取items_to_handlers中定义的关键字
5、利用分好的batch建立一个prefetch_queue
6、prefetch_queue中有一个dequeue的op,每执行一次dequeue则返回一个batch的数据。
具体代码如下(这里先只介绍到通过provider的get函数获取数据,后面步骤5和步骤6的队列处理先不介绍,在实际项目代码中会使用到):
import os import tensorflow as tf slim = tf.contrib.slim def get_dataset(dataset_dir): """ 获取commodity2018数据集 :param dataset_dir: 数据集目录 :return: Dataset """ # 1.准备 tf.slim.dataset.Dataset()的参数 # 1.1第一个参数:dataset file_pattern = os.path.join(dataset_dir, "commodity_2018_train_*.tfrecord") # 1.2第二个参数:reader reader = tf.TFRecordReader # 1.3第三个参数:decoder # 创建decoder需要两个参数:keys_to_features和items_to_handlers # 1.3.1 定义keys_to_features,反序列化的格式 keys_to_features = { 'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''), 'image/format': tf.FixedLenFeature((), tf.string, default_value='jpeg'), 'image/height': tf.FixedLenFeature([1], tf.int64), 'image/width': tf.FixedLenFeature([1], tf.int64), 'image/channels': tf.FixedLenFeature([1], tf.int64), 'image/shape': tf.FixedLenFeature([3], tf.int64), 'image/object/bbox/xmin': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/ymin': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/xmax': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/ymax': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/label': tf.VarLenFeature(dtype=tf.int64), 'image/object/bbox/difficult': tf.VarLenFeature(dtype=tf.int64), 'image/object/bbox/truncated': tf.VarLenFeature(dtype=tf.int64), } # 1.3.2 items_to_handlers,反序列化成高级的格式 items_to_handlers = { 'image': slim.tfexample_decoder.Image('image/encoded', 'image/format'), 'shape': slim.tfexample_decoder.Tensor('image/shape'), 'object/bbox': slim.tfexample_decoder.BoundingBox( ['ymin', 'xmin', 'ymax', 'xmax'], 'image/object/bbox/'), 'object/label': slim.tfexample_decoder.Tensor('image/object/bbox/label'), 'object/difficult': slim.tfexample_decoder.Tensor('image/object/bbox/difficult'), 'object/truncated': slim.tfexample_decoder.Tensor('image/object/bbox/truncated'), } # 1.3.3构造decoder decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers) # 2.tf.slim.dataset.Dataset()并返回 return slim.dataset.Dataset(data_sources=file_pattern, reader=reader, decoder=decoder, num_samples=88, items_to_descriptions={ 'image': 'A color image of varying height and width.', 'shape': 'Shape of the image', 'object/bbox': 'A list of bounding boxes, one per each object.', 'object/label': 'A list of labels, one per each object.' }, # 数据集返回的格式描述字典 num_classes=8)
from datasets.dataset_init import commodity_2018 import tensorflow as tf slim = tf.contrib.slim if __name__ == '__main__': # 获取dataset dataset = commodity_2018.get_dataset("./IMAGE/tfrecords/commodity_tfrecords/") # 通过provider取出数据 provider = slim.dataset_data_provider.DatasetDataProvider(dataset=dataset, num_readers=3) # 通过get方法获取指定名称的数据(名称在准备规范数据dataset时高级格式的名称,即items_to_handlers中定义的名称) [image, shape, bbox, label, difficult, truncated] = provider.get( ['image', 'shape', 'object/bbox', 'object/label', 'object/difficult', 'object/truncated']) print(image, shape, bbox, label, difficult, truncated)
最后得到如下输出结果:

图4 输出tfrecord文件
2.3 数据模块接口——数据工厂的实现
功能需求:
1)原始数据集(图片+XML)转换成TFRecords文件格式
2)读取TFRecords数据
数据模块设计的目录如下:
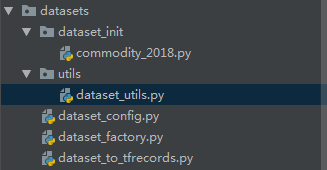
图5 数据模块接口
其中:
dataset_factory:数据模块工厂,找到不同的数据集读取逻辑;
dataset_init:保存不同数据集的TFRecords格式读取功能;
utils:数据模块的共用组件
dataset_config‘:数据模块的一些数据集配置文件
dataset_to_tfrecords:原始数据集格式转换逻辑
2.3.1 格式转换
上一节以及介绍了将数据集转换成TFRecord格式文件,这里就不再赘述。
2.3.2 读取TFRecord文件数据
2.3.2.1 读取代码框架设计
数据模块需要实现对不同数据集类型进行读取操作,因此可以定义一个基类,同时不同数据集继承这个基类。类的设计如下:
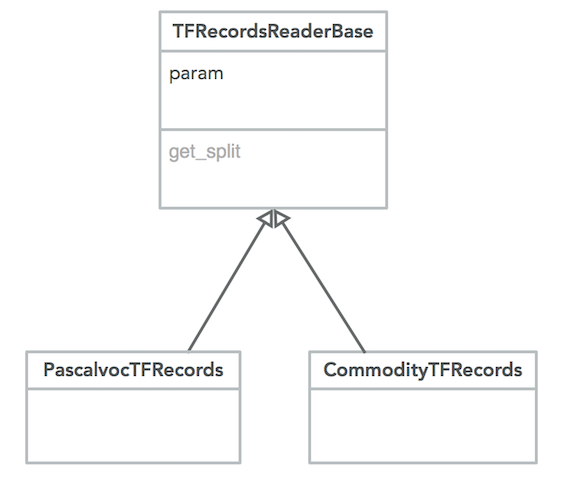
图6 数据读取基类设计
2.3.2.2 数据读取代码
1.在dataset_utils.py中新建一个基类,该文件下的代码如下:
import tensorflow as tf # 定义数据集TFRecord文件读取基类 class TFRecordsReaderBase(object): """ 数据集读取基类 """ def __init__(self, param): # param是给不同数据集使用的属性配置 self.param = param def get_dataset(self, train_or_test, dataset_dir): """ 获取数据 :param train_or_test: 训练还是测试 :param dataset_dir: 数据集目录 :return: """ return None
2. 因为在读取TFRecord数据时,不同的数据集,都会有自己特有的参数(比如:文件名、样本数、类别数等)。因此在dataset_config.py文件中定义不同数据集的参数,作为继承类的参数。这里使用命名字典:
""" 数据集读取 """ from collections import namedtuple # 创建命名字典,用于存放读取数据类中的param参数 DataSetParams = namedtuple("DataSetParamters", ['FILE_PATTERN', 'NUM_CLASSES', 'SPLITS_TO_SIZES', 'ITEMS_TO_DESCRIPTIONS' ]) # 定义commodity_2018属性配置 Cmd2018 = DataSetParams( FILE_PATTERN='commodity_2018_%s_*.tfrecord', NUM_CLASSES=8, SPLITS_TO_SIZES={ 'train': 88, 'test': 0 }, ITEMS_TO_DESCRIPTIONS={ 'image': '图片数据', 'shape': '图片形状', 'object/bbox': '若干物体对象的bbox框组成的列表', 'object/label': '若干物体对应的label编号' } )
3. 继承基类来定义派生类用于处理不同数据集
继承的基类存放在dataset/dataset_init/目录下。对于不同数据集,定义不同的文件继承基类,本项目值处理commodity数据集,因此仅创建commodity_2018.py继承基类,代码如下:
import os import tensorflow as tf from datasets.utils import dataset_utils slim = tf.contrib.slim class CommodityTFRecords(dataset_utils.TFRecordsReaderBase): """ 商品数据集读取类 """ def __init__(self, param): self.param = param def get_dataset(self, train_or_test, dataset_dir): """ 获取commodity2018数据集 :param train_or_test: train or test :param dataset_dir: 数据集目录 :return: """ # 参数检查,异常抛出 if train_or_test not in ['train', 'test']: raise ValueError("训练/测试的名字 %s 错误" % train_or_test) if not tf.gfile.Exists(dataset_dir): raise ValueError("数据集目录 %s 不存在" % dataset_dir) # 1.准备 tf.slim.dataset.Dataset()的参数 # 1.1第一个参数:dataset file_pattern = os.path.join(dataset_dir, self.param.FILE_PATTERN % train_or_test) # 1.2第二个参数:reader reader = tf.TFRecordReader # 1.3第三个参数:decoder # 创建decoder需要两个参数:keys_to_features和items_to_handlers # 1.3.1 定义keys_to_features,反序列化的格式 keys_to_features = { 'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''), 'image/format': tf.FixedLenFeature((), tf.string, default_value='jpeg'), 'image/height': tf.FixedLenFeature([1], tf.int64), 'image/width': tf.FixedLenFeature([1], tf.int64), 'image/channels': tf.FixedLenFeature([1], tf.int64), 'image/shape': tf.FixedLenFeature([3], tf.int64), 'image/object/bbox/xmin': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/ymin': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/xmax': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/ymax': tf.VarLenFeature(dtype=tf.float32), 'image/object/bbox/label': tf.VarLenFeature(dtype=tf.int64), 'image/object/bbox/difficult': tf.VarLenFeature(dtype=tf.int64), 'image/object/bbox/truncated': tf.VarLenFeature(dtype=tf.int64), } # 1.3.2 items_to_handlers,反序列化成高级的格式 items_to_handlers = { 'image': slim.tfexample_decoder.Image('image/encoded', 'image/format'), 'shape': slim.tfexample_decoder.Tensor('image/shape'), 'object/bbox': slim.tfexample_decoder.BoundingBox( ['ymin', 'xmin', 'ymax', 'xmax'], 'image/object/bbox/'), 'object/label': slim.tfexample_decoder.Tensor('image/object/bbox/label'), 'object/difficult': slim.tfexample_decoder.Tensor('image/object/bbox/difficult'), 'object/truncated': slim.tfexample_decoder.Tensor('image/object/bbox/truncated'), } # 1.3.3构造decoder decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers) # 2.tf.slim.dataset.Dataset()并返回 return slim.dataset.Dataset(data_sources=file_pattern, reader=reader, decoder=decoder, num_samples=self.param.SPLITS_TO_SIZES[train_or_test], items_to_descriptions=self.param.ITEMS_TO_DESCRIPTIONS, # 数据集返回的格式描述字典 num_classes=self.param.NUM_CLASSES)
2.3.3 定义数据工厂
在datasets根目录下创建dataset_factory.py文件,定义数据工厂获取数据,代码如下:
from datasets.dataset_init import commodity_2018 from datasets.dataset_config import Cmd2018 # 定义dataset种类的字典,目前只是有commodity数据集,后续可以添加 datasets_maps = { 'commodity_2018': commodity_2018.CommodityTFRecords } # 定义参数种类的字典,不同数据集,param参数不一样,目前只是有commodity的参数,后续可以添加 param_map = { 'commodity_2018': Cmd2018 } def get_dataset(dataset_name, train_or_test, dataset_dir): """ 获取指定数据名称的数据文件 :param dataset_name: 数据集名称(数据当中要存在 :param train_or_test: train or test数据集 :param dataset_dir: 数据集目录 :return: Dataset 数据规范 """ if dataset_name not in datasets_maps: raise ValueError("数据集名称 %s 不存在" % dataset_name) param = param_map[dataset_name] return datasets_maps[dataset_name](param).get_dataset(train_or_test, dataset_dir)
最终对外只提供dataset_factory.py文件用于读取TFRecord文件。
3. 模型接口
本项目使用SSD模型。
项目文件结构如下:
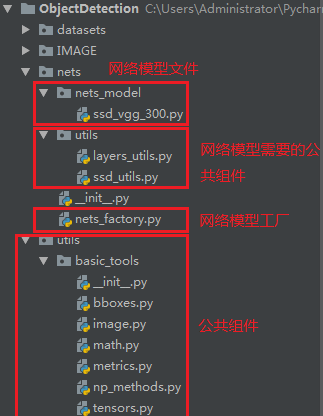
图7 网络模型接口文件格式
其中的公共组件的源码都是已知的,本项目使用的ssd网络模型实现文件ssd_vgg_300.py相关代码都是现有代码。对于SSD模型以及其代码实现,将在另外章节介绍。
3.1 网络工厂nets_factory实现
类似数据工厂,我们定义模型工厂nets_factory.py文件,代码如下:
from nets.nets_model import ssd_vgg_300 nets_maps = { 'ssd_vgg_300': ssd_vgg_300.SSDNet } def get_network(network_name): """ 获取不同网络模型 :param network_name: 网络模型名称 :return: 网络 """ if network_name not in nets_maps: raise ValueError("网络名称 %s 不存在" % network_name) return nets_maps[network_name]
4.预处理模块
目的:
1)在图像的深度学习中,对输入数据进行数据增强(Data Augmentation),为了丰富图像的训练集,更好地提取图像特征,泛化模型(防止过拟合)。
通过一系列图像的操作(比如:剪切、翻转、偏移、缩放等图像变换),增加数据集的大小,防止过拟合。
2)还有一个根本目的就是把图片变成符合大小要求的格式:
RCNN网络对于输入图片没有要求,但是网络当中卷积之前需要的大小为227×227;
YOLO算法:输入图片大小为448×448;
SSD算法:输入图片大小为300×300;
4.1 预处理模块代码实现
首先,预处理模块的结构如图所示:

图8 预处理模块结构
其中,需要创建一个preprocessing目录,该目录下的文件用于数据预处理。该目录下的processing目录中的ssd_vgg_preprocessing.py是对于SSD模型的预处理的。如果后续需要增加网络模型,需要在这个文件夹下增加预处理的文件。utils中是预处理需要用到的公共组件。这些相关代码都是公开的代码,这里不做介绍。有了上面的基础文件,下面就来完成数据预处理工厂代码的编写,在preprocessing_factory.py文件中实现:
from preprocessing.processing import ssd_vgg_preprocessing # 目前只有sdd_vgg_300,后续可以增加 preprocessing_maps = { 'ssd_vgg_300': ssd_vgg_preprocessing } def get_preprocessing(name, is_trainning=True): """ 预处理工厂获取不同的数据增强方法 :param name: 预处理名称 :param is_trainning: 是否是训练 :return: 返回预处理的函数,后续再调用函数 """ if name not in preprocessing_maps: raise ValueError("数据预处理名称 %s 不存在" % name) # 定义一个预处理函数,用于函数返回,后续再调用该预处理函数 def preprocessing_fn(image, labels, bboxes, out_shape, data_format, **kwargs): return preprocessing_maps[name].preprocess_image(image, labels, bboxes, out_shape, data_format=data_format, is_training=is_trainning, **kwargs) return preprocessing_fn
5.训练不同模块接口参数
对于2、3、4章节,只是分别单独介绍了数据模块接口、模型接口以及数据预处理接口。现在需要统一每一个模块接口提供给训练的参数,整理成文档。这样以后就直接查看文档即可调用相关模块。总结如图9所示:
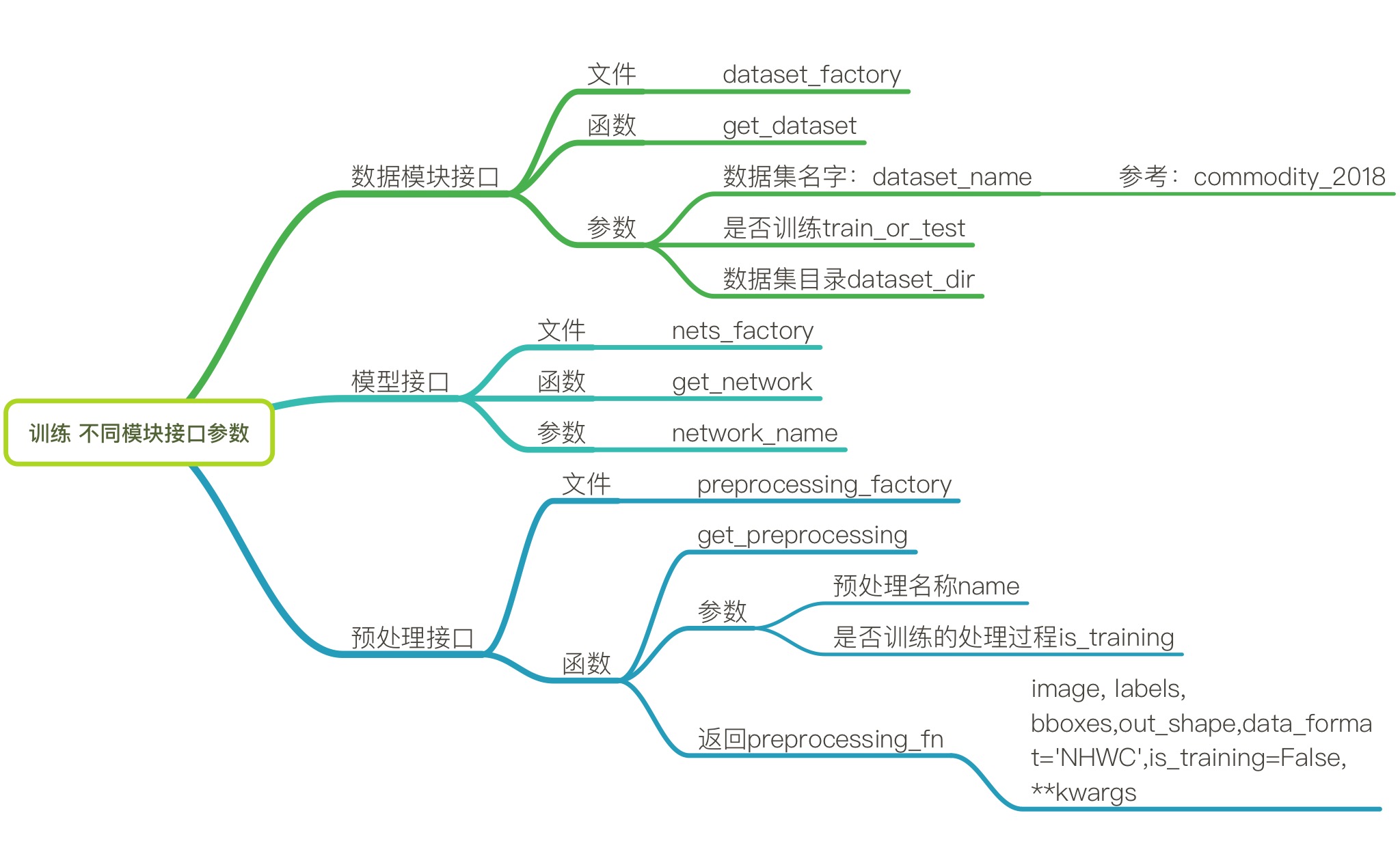
图9 训练不同模型参数
6. 多GPU训练
终于到了模型训练这一步了。这里介绍多GPU训练。
对于深度学习来说,大量的计算量导致CPU会显得十分乏力耗时。所以需要GPU来进行提供帮助计算,那么他们的主要任务就是计算得出结果,与CPU之间会进行分工,CPU会做一些基本工作,变量存储,更新参数,输入数据变量等等。如图10所示。在TensorFlow当中会通过标号来区别不同的GPU和CPU,如 ,''/device:CPU:0", "/device:CPU:1","/device:GPU:0","/device:GPU:1","/device:GPU:2",那么这些标号都是程序自动给的编号,指的具体哪块计算设备。

图10 CPU与GPU之间的分工合作
6.1 训练步骤
- 步骤
- 数据读取
- preprocess(数据预处理)
- 网络构建预测结果
- 损失计算
- 添加变量到TensorBoard
- 模型训练、保存
- 部署需求:训练整个模型需要在多GPU、多计算机的环境下进行
那么接下来首先我们要讲模型训练的设备逻辑原理弄清楚,如图11所示:

图11 模型训练的设备逻辑原理
训练主要是在设备(GPU/CPU)上训练,但是如果我们利用目前简单的TensorFlow提供的API去进行指定设备训练会比较繁琐。所以在这里需要介绍一个TensorFlow提供的最新的专门用于多GPU,多计算机的设备部署模块——model_deploy。
6.2 model_deploy介绍
model_deploy位于TensorFlow slim模块的deployment目录下,可以使得用多个 GPU / CPU在同一台机器或多台机器上执行同步或异步训练变得更简单。可以从如下官方地址下载:
https://github.com/tensorflow/models/blob/master/research/slim/deployment/model_deploy.py
首先我们要介绍:
replica:使用多机训练时,一台机器对应一个replica(复本);
clone:由于tensorflow里多GPU训练一般都是每个GPU上都有完整的模型,各自进行前向传播计算,得到的梯度交给CPU平均后统一反向计算,每个GPU上的模型叫做一个clone;
parameter server:多机训练时,计算梯度平均值并执行反向传播操作的参数,功能类似于单机多GPU的CPU;
worker server:一般指单机多卡中的GPU,用于训练。
6.2.1 DeploymentConfig
1. DeploymentConfig为文件中的一个类,主要用于给变量配置选择的设备。
- class DeploymentConfig(object):
- 配置参数
- num_clones=1:每一个计算设备上的模型克隆数(每台计算机的GPU/CPU总数)
- clone_on_cpu=False:如果为True,将只在CPU上训练
- replica_id=0:指定某个计算机去部署,默认第0台计算机(TensorFlow会给个默认编号)
- num_replicas=1:多少台可用计算机
- num_ps_tasks=0:用于参数服务器的计算机数量,0为不适用计算机作为参数服务器
- worker_job_name='worker':工作服务器名称
- ps_job_name='ps':参数服务器名称
- config.variables_device()
- 作为tf.device(func)的参数,返回默认创建变量的设备
- 一般用于指定全局步数变量的设备,默认运行计算机的"/device:CPU:0"
- config.inputs_device()
- 作为tf.device(func)的参数,返回用于构建数据输入变量所在的设备。
- 默认运行计算机的"/device:CPU:0"
- config.optimizer_device()
- 作为tf.device(func)的参数,返回学习率、优化器所在的设备。
- 默认运行计算机的"/device:CPU:0"
- config.clone_scope(self, clone_index):
- 返回指定编号的设备命名空间
- 按照这样编号,clone_0,clone_1...
6.2.2 model_deploy定义的相关函数,主要用于为每一个clone创建一个复制的模型(在GPU)
- model_deploy.create_clones(config, model_fn, args=None, kwargs=None):
- 作用:每个clone创建一个复制的模型,给GPU进行clone模型
- config:一个DeploymentConfig的配置对象
- model_fn:用于回调的函数model_fn,
- args=None, kwargs=None:回调函数model_fn的参数
- 返回元组组成的列表,列表个数大小为指定的num_clones数量
- Clone(outputs, scope, device)
- outputs:网络模型的每一层节点
- scope: 第i个GPU设备的命名空间,config.clone_scope(i)
- clone_device:第i个GPU设备
- Clone(outputs, scope, device)
- model_deploy.optimize_clones(clones, optimizer,regularization_losses=None, **kwargs)
- 作用:计算所有给定的clones的总损失以及每个需要优化的变量的总梯度
- clones: 元组列表,每个元素Clone(outputs, scope, device)
- optimizer:选择的优化器
- **kwargs:可选参数,优化器优化的变量
- 返回:
- total_loss:总损失
- grads_and_vars:每个需要优化变量的总梯度组成的列表
源码介绍使用:
# Set up DeploymentConfig config = model_deploy.DeploymentConfig(num_clones=2, clone_on_cpu=True) # Create the global step on the device storing the variables. with tf.device(config.variables_device()): global_step = slim.create_global_step() # Define the inputs with tf.device(config.inputs_device()): images, labels = LoadData(...) inputs_queue = slim.data.prefetch_queue((images, labels)) # Define the optimizer. with tf.device(config.optimizer_device()): optimizer = tf.train.MomentumOptimizer(FLAGS.learning_rate, FLAGS.momentum) # Define the model including the loss. def model_fn(inputs_queue): images, labels = inputs_queue.dequeue() predictions = CreateNetwork(images) slim.losses.log_loss(predictions, labels) model_dp = model_deploy.deploy(config, model_fn, [inputs_queue], optimizer=optimizer) # Run training. slim.learning.train(model_dp.train_op, my_log_dir, summary_op=model_dp.summary_op)
6.3 训练逻辑
1)DeploymentConfig
需要在训练之前配置所有的设备信息
定义全局步数
2)获取图片队列
在config.inputs_device()指定
3)数据输入、网络计算结果、定义损失并复制模型到clones,添加变量到tensorboard
model_deploy.create_clones
4)定义学习率、优化器
config.optimizer_device()指定
5)计算所有GPU/CPU设备的平均损失和每个变量的梯度总和、定义训练OP、summaries OP
model_deploy.optimize_clones
6)配置训练的config,进行训练
slim.learning.train
代码框架如下:
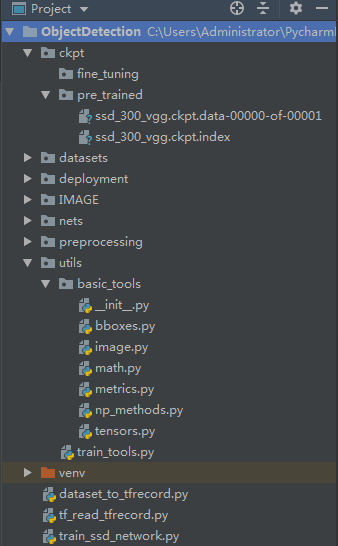
图中,pre_trained文件下存放的是预训练好的ssd_vgg_300网络的预训练模型,fine_tuning是训练存放模型的路径。
根目录下的utils是公共组件,最后训练的文件是train_ssd_network.py。
训练代码如下:
""" 训练初始化参数 PRE_TRAINED_PATH=./ckpt/pre_trained/ssd_vgg_300.ckpt TRAIN_MODEL_PDIR=./ckpt/fine_tuning/ DATASET_DIR=./IMAGE/tfrecords/commodity_tfrecords/ 每批次训练样本数:32或者更小 惩罚项:0.005 学习率:0.001 优化器选择:adam 模型名称:ssd_vgg_300 """ import tensorflow as tf from datasets import dataset_factory from preprocessing import preprocessing_factory from nets import nets_factory from utils import train_tools from deployment import model_deploy slim = tf.contrib.slim DATA_FORMAT = 'NHWC' # 命令行参数 # 设备相关的命令行参数 tf.app.flags.DEFINE_integer('num_clones', 1, "可用GPU数量") tf.app.flags.DEFINE_boolean('clone_on_cpu', False, "是否只在CPU上运行") tf.app.flags.DEFINE_integer('replica_id', 0, "复本id") # 数据集相关命令行参数 tf.app.flags.DEFINE_string('dataset_dir', ' ', "训练数据集目录") tf.app.flags.DEFINE_string('dataset_name', 'commodity_2018', "数据集名称") tf.app.flags.DEFINE_string('train_or_test', 'train', "训练还是测试") # 网络相关命令行参数 tf.app.flags.DEFINE_string('network_name', 'ssd_vgg_300', "网络名称") tf.app.flags.DEFINE_integer('batch_size', 32, "每批次获取样本换数量") tf.app.flags.DEFINE_float('weight_decay', 0.0001, "网络误差惩罚项") # 训练相关参数 tf.app.flags.DEFINE_string( 'optimizer', 'rmsprop', '优化器种类 可选"adadelta", "adagrad", "adam","ftrl", "momentum", "sgd" or "rmsprop".') tf.app.flags.DEFINE_string( 'learning_rate_decay_type', 'exponential', '学习率种类 "fixed", "exponential", "polynomial".') tf.app.flags.DEFINE_float('learning_rate', 0.01, '模型初始学习率') tf.app.flags.DEFINE_float('end_learning_rate', 0.0001, '模型终止学习率') tf.app.flags.DEFINE_integer('max_number_of_steps', None, '训练的最大步数') tf.app.flags.DEFINE_string('train_model_dir', ' ', '训练输出的模型目录') tf.app.flags.DEFINE_string('pre_trained_model', None, '预训练模型目录') FLAGS = tf.app.flags.FLAGS def main(_): if not FLAGS.dataset_dir: raise ValueError("必须指定一个TFRecord的数据集目录") # 设置打印级别 tf.logging.set_verbosity(tf.logging.DEBUG) # 在默认图中进行训练 with tf.Graph().as_default(): # 1.DeploymentConfig配置 deploy_config = model_deploy.DeploymentConfig(num_clones=FLAGS.num_clones, clone_on_cpu=FLAGS.clone_on_cpu, replica_id=0, num_replicas=1, num_ps_tasks=0) # 在variables_device定义全局步长(网络训练一般都这么配置) with tf.device(deploy_config.variables_device()): global_step = tf.train.create_global_step() # 2.获取图片数据,做一些预处理 # image, shape, bbox, label # 不是直接进行训练,而是需要进行正负样本标记(输出的anchor和GT进行IOU计算选择) # 2.1步骤如下: # (1)通过数据工厂获取DataSet规范,不是真正的数据,需要通过后续操作去获取数 dataset = dataset_factory.get_dataset(dataset_name=FLAGS.dataset_name, train_or_test=FLAGS.train_or_test, dataset_dir=FLAGS.dataset_dir) # (2)通过网络计算获取的anchors结果 # 通过网络工厂获取网络 ssd_class = nets_factory.get_network(FLAGS.network_name) # 获取默认网络参数 ssd_params = ssd_class.default_params._replace(num_classes=9) # 初始化网络init函数 ssd_net = ssd_class(ssd_params) # 获取shape ssd_shape = ssd_net.params.img_shape # 获取anchors, SSD网络中6层的所有计算出来的默认候选框default boxes ssd_anchors = ssd_net.anchors(ssd_shape) # (3)获取预处理函数 image_preprocessing_fn = preprocessing_factory.get_preprocessing(name=FLAGS.network_name, is_training=True) # 打印网络相关参数 train_tools.print_configuration(ssd_params, dataset.data_sources) # 2.2 # (1)通过slim.dataset_data_provider.DatasetDataProvider获取图像数据 # (2)进行数据预处理 # (3)对获取出来的GT标签和bbox进行编码 # (4)获取的单个样本数据,要进行批处理以及返回队列 with tf.device(deploy_config.inputs_device()): with tf.name_scope(FLAGS.network_name + "_data_provider"): provider = slim.dataset_data_provider.DatasetDataProvider( dataset, num_readers=4, common_queue_capacity=20 * FLAGS.batch_size, common_queue_min=10 * FLAGS.batch_size, shuffle=True) # get获取数据(真正获取参数) [image, shape, glabels, gbboxes] = provider.get(['image', 'shape', 'object/label', 'object/bbox']) # 数据预处理 [?, ?, 3]-->[300, 300, 3] image, glabels, gbboxes = image_preprocessing_fn(image, glabels, gbboxes, ssd_shape, DATA_FORMAT) # 原始anchor boxes进行正负样本标记 # gclasses: 目标类别 # glocalizations: 目标类别的真实位置 # gscores: 目标结果(概率值) gclasses, glocalizations, gscores = ssd_net.bboxes_encode(glabels, gbboxes, ssd_anchors) # 批处理、队列处理 # tensor_list:tensor组成的类别 [tensor, tensor, tensor, ...] # r是1个tensor组成的列表 r = tf.train.batch(tensors=train_tools.reshape_list([image, gclasses, glocalizations, gscores]), batch_size=FLAGS.batch_size, num_threads=4, capacity=5 * FLAGS.batch_size) batch_queue = slim.prefetch_queue.prefetch_queue(r, capacity=deploy_config.num_clones) # 3.数据输入、网络计算结果、定义损失并复制模型到clones,添加变量到tensorboard summaries = set(tf.get_collection(tf.GraphKeys.SUMMARIES)) # batch_shape:获取的默认队列大小,即上面r的大小 batch_shape = [1] + 3 * [len(ssd_anchors)] update_ops, first_clone_scope, clones = train_tools.deploy_loss_summary(deploy_config, batch_queue, ssd_net, summaries, batch_shape, FLAGS) # 4.定义学习率、优化器 # 初始学习率:0.001 # 终止学习率:0.0001 # 优化器选择:adam with tf.device(deploy_config.optimizer_device()): # 定义学习率和优化器 learning_rate = train_tools.configure_learning_rate(FLAGS, dataset.num_samples, global_step) # 定义优化器 optimizer = train_tools.configure_optimizer(FLAGS, learning_rate) # 观察学习的变化情况添加到summaries中 summaries.add(tf.summary.scalar('learning_rate', learning_rate)) # 5.计算所有GPU/CPU设备的平均损失和每个变量的梯度总和、定义训练OP、summaries OP train_op, summaries_op = train_tools.get_trainop(optimizer, summaries, clones, global_step, first_clone_scope, update_ops) # 6.配置训练的config,进行训练 # 6.1 配置config和saver gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8) config = tf.ConfigProto(log_device_placement=False, # 若果打印会有许多变量的设备信息出现 gpu_options=gpu_options) saver = tf.train.Saver(max_to_keep=5, # 默认保留最近几个模型文件 keep_checkpoint_every_n_hours=1.0, write_version=2, pad_step_number=False) # 6.2 训练 slim.learning.train( train_op, # 训练优化器tensor logdir=FLAGS.train_model_dir, # 模型存储目录 master='', is_chief=True, init_fn=train_tools.get_init_fn(FLAGS), # 初始化参数的逻辑,预训练模型的读取和微调模型判断 summary_op=summaries_op, # 摘要 number_of_steps=FLAGS.max_number_of_steps, # 最大步数 log_every_n_steps=10, # 打印频率 save_summaries_secs=60, # 保存摘要频率 saver=saver, # 保存模型参数 save_interval_secs=600, # 保存模型间隔 session_config=config, # 会话参数配置 sync_optimizer=None) if __name__ == '__main__': tf.app.run()
训练模型:
训练的过程使用技嘉RTX2070Super显卡。
切换到ObjectDetection目录,执行如下命令(参数可以自己设定):
PRE_TRAINED_PATH=./ckpt/pre_trained/ssd_300_vgg.ckpt TRAIN_MODEL_DIR=./ckpt/fine_tuning/ DATASET_DIR=./IMAGE/tfrecords/commodity_tfrecords/ python train_ssd_network.py --train_model_dir=${TRAIN_MODEL_DIR} --dataset_dir=${DATASET_DIR} --dataset_name="commodity_2018" --train_or_test=train --model_name=ssd_vgg_300 --pre_trained_path=${PRE_TRAINED_PATH} --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --batch_size=16
此时可以学习。
同时在ckpt/fine_tuning文件夹下,执行如下命令,可以使用tensorboard查看已经添加到tensorboard中的相关参数。
tensorboard --logdir=./
训练过程如下图所示:

7.测试过程
7.1测试流程
1)测试数据准备
2)preprocessing数据预处理--测试过程的数据预处理就是需要图片的resize
3)模型加载
4)postprocess(预测结果后期处理)--训练过程中是不需要后期处理的
通过scores筛选bbox
使用NMS筛选box
注意bbox边界与原始图片的bbox,按需修改bbox
5)预测结果显示(使用matplotlib)
7.1 测试框架:
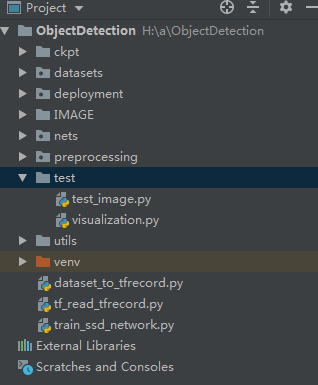
其中,test文件夹用于测试使用,visualization.py文件里面是显示结果的代码,test_image.py文件中文最终存放的测试代码。
7.2 测试代码
7.2.1显示图片代码
visualization.py中的显示结果的代码如下:
import cv2 import random import matplotlib.pyplot as plt import matplotlib.image as mpimg import matplotlib.cm as mpcm VOC_LABELS = { '0': 'Background', '1': 'clothes', '2': 'pants', '3': 'shoes', '4': 'watch', '5': 'phone', '6': 'audio', '7': 'computer', '8': 'books' } # =========================================================================== # # Matplotlib 显示图 # =========================================================================== # def plt_bboxes(img, classes, scores, bboxes, figsize=(10,10), linewidth=1.5): """显示bounding boxes. """ fig = plt.figure(figsize=figsize) plt.imshow(img) height = img.shape[0] width = img.shape[1] colors = dict() for i in range(classes.shape[0]): cls_id = int(classes[i]) if cls_id >= 0: score = scores[i] if cls_id not in colors: colors[cls_id] = (random.random(), random.random(), random.random()) ymin = int(bboxes[i, 0] * height) xmin = int(bboxes[i, 1] * width) ymax = int(bboxes[i, 2] * height) xmax = int(bboxes[i, 3] * width) rect = plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin, fill=False, edgecolor=colors[cls_id], linewidth=linewidth) plt.gca().add_patch(rect) class_name = str(cls_id) plt.gca().text(xmin, ymin - 2, '{:s} | {:.3f}'.format(VOC_LABELS[class_name], score), bbox=dict(facecolor=colors[cls_id], alpha=0.5), fontsize=12, color='white') plt.show()
7.2.1测试过程代码
测试过程test_image.py代码如下:
import numpy as np import tensorflow as tf from PIL import Image import sys sys.path.append('../') import matplotlib.pyplot as plt import matplotlib.image as mping import visualization from utils.basic_tools import np_methods slim = tf.contrib.slim from nets import nets_factory from preprocessing import preprocessing_factory # 1.定义输入图片数据的占位符 image_input = tf.placeholder(tf.uint8, shape=[None, None, 3]) # 定义输出形状,元组表示 net_shape = (300, 300) data_format = 'NHWC' # 2.数据输入预处理工厂,进行预处理 preprocessing_fn = preprocessing_factory.get_preprocessing('ssd_vgg_300', is_training=False) image_Pre, _, _, bbox_img = preprocessing_fn(image_input, None, None, net_shape, data_format) # image_Pre是三维形状--->(300, 300, 3) # 卷积神经网络要求都是四维的数据计算 # 维度的扩充--->(1, 300, 300, 3) image_4d = tf.expand_dims(image_Pre, 0) # 3.定义SSD模型,并输出预测结果 # 网络工厂获取 ssd_class = nets_factory.get_network('ssd_vgg_300') ssd_params = ssd_class.default_params._replace(num_classes=9) reuse = True if 'ssd_net' in locals() else False # 初始化网络 ssd_net = ssd_class(ssd_params) ssd_anchors = ssd_net.anchors(net_shape) # 通过网络的方法获取结果 # 使用slim指定公有参数 with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)): predictions, localizations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse) config = tf.ConfigProto(log_device_placement=False) sess = tf.InteractiveSession(config=config) sess.run(tf.global_variables_initializer()) ckpt_filepath = '../ckpt/fine_tuning/model.ckpt-103480' saver = tf.train.Saver() saver.restore(sess, ckpt_filepath) # 会话运行图片,输出结束 # 读取一张图片 img = Image.open('../IMAGE/commodity/JPEGImages/000080.jpg').convert('RGB') img = np.array(img) i, p, l, box_img = sess.run([image_4d, predictions, localizations, bbox_img], feed_dict={image_input:img}) # 进行结果筛选 classes, scores, bboxes = np_methods.ssd_bboxes_select( p, l, ssd_anchors, select_threshold=0.5, img_shape=(300, 300), num_classes=9, decode=True ) # bbox边框不能超过原图片,默认原图的相对于bbox大小比例 [0, 0, 1, 1] bboxes = np_methods.bboxes_clip(box_img, bboxes) # 根据 scores 从大到小排序,并改变classes rbboxes的顺序 classes, scores, bboxes = np_methods.bboxes_sort(classes, scores, bboxes, top_k=400) # 使用nms算法筛选bbox classes, scores, bboxes = np_methods.bboxes_nms(classes, scores, bboxes, nms_threshold=.45) # 根据原始图片的bbox,修改所有bbox的范围[.0, .0, .1, .1] bboxes = np_methods.bboxes_resize(box_img, bboxes) visualization.plt_bboxes(img, classes, scores, bboxes)
测试中使用训练得到的ckpt/fine_tuning/model.ckpt-103480文件中的参数进行。测试结果如下图所示:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号