
CS229|Ch8-9|泛化、正则化、模型选择
关键词:
泛化性、过拟合、欠拟合;误差、偏差、方差 及其关系;模型复杂度&偏差&方差&过拟合&欠拟合&误差之间关系
正则化、范数、稀疏;交叉验证
泛化性generalization: performances on unseen data
training data——seen
test data——unseen
过拟合overfit: predict accurately on training data(small training loss=error=cost) but not generalize well on test data(large test error)
*在训练数据上表现很好,但在测试数据上表现很差。往往是把模型搞得很复杂去fit每一个训练数据点,但其实并不能真正代表整个数据的分布(比如考虑了unrelated features&noise),捕捉了虚假的输入和输出之间的关系
【large variance】
欠拟合underfit: relatively large training error (typically relatively large test error)
*在训练数据上表现得就很差,在测试数据上也相应不会好。往往是模型太简单,并不能代表ground truth function,没啥预测能力。此时你堆再多训练数据也没用。。。
【large bias】
bias-variance trade-off
看到这里,你肯定有很多问题:
1、bias=偏差和variance=方差到底是什么?
首先,两者都是针对测试集的
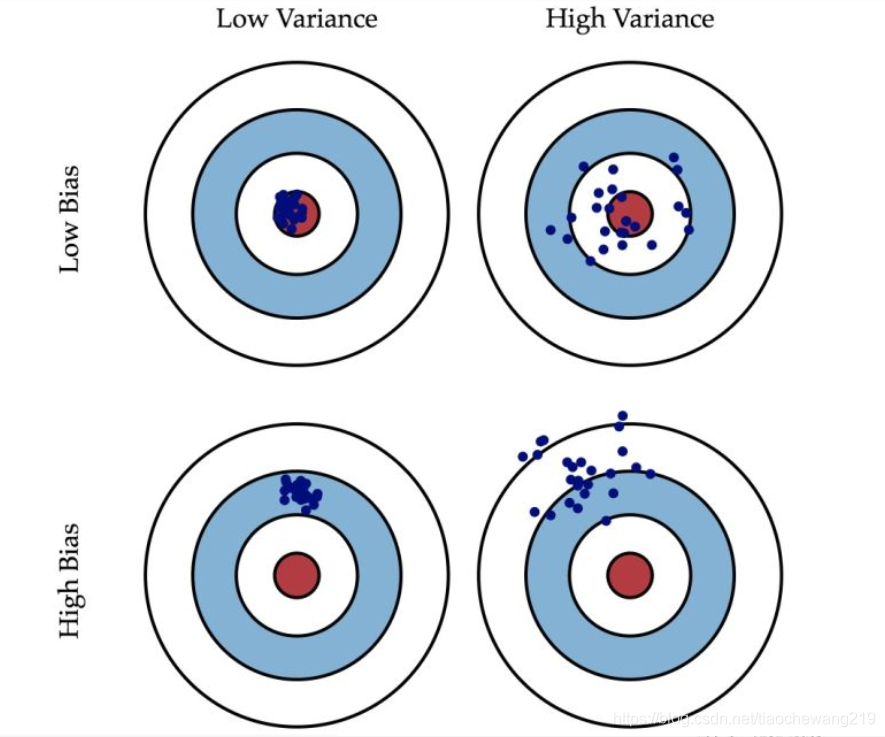
bias偏差:在测试集上,预测值和真实值之间的差距
variance方差:在测试集上,预测值的离散程度
这里先要理解,各个预测点来自哪里?所有预测点的输入x(来自测试集中的某个样本)是同一个,但是输出的预测值不同,这是因为模型的参数不同,即使用了不同的训练集(理解为训练数据的不同子集)进行模型训练。
因此,
偏差:对于同一个测试样本,N次预测值的平均值 与 真实值 之间的距离
方差:对于同一个测试样本,N次预测值之间的方差
然后看这张图帮助理解,对于同一个测试样本的输入x,红色代表真实输出值,蓝点代表各次预测点
2、generalization error=test error泛化误差、bias偏差、variance方差 之间的关系?
先上结论:泛化误差=数据本身噪声+偏差+方差
其中,数据噪声不可避免也无法处理。这个式子里比较反直觉的是方差这一项的存在
(1)理解:
我们前面提到,N次预测是针对同一个测试样本的输入x,但是每次的模型参数不同,这些参数来自于不同的训练集。因此,N次预测值的离散程度,反映在不同训练集下的模型表现的离散程度。即,方差衡量模型对训练数据集中微小波动的敏感度。如果一个模型本身复杂度很高,对于训练集很敏感,能够细微捕捉到数据中的微小差异,那么用不同训练集得到的模型参数,在同一个测试数据上,预测结果的方差很较大。so模型复杂——高variance
另一方面,bias衡量不同训练集下平均预测表现的好坏,即平均预测值和真实值的差距。如果模型太简单,根本不能预测准,那么bias自然会很大。so模型简单——高bias
(2)数学推导
右侧第一项:unavoidable noise
右侧第二项:bias的平方
右侧第三型:variance
具体推导过程见P120 of https://cs229.stanford.edu/main_notes.pdf
*注意,这是回归问题的数学式子,分类问题相对not clear,暂无统一数学式子
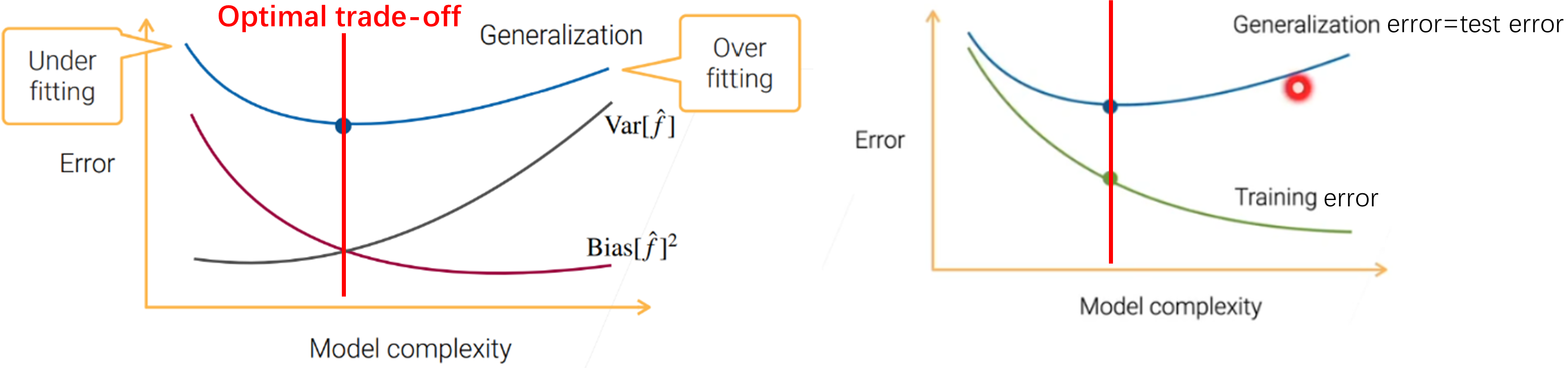
3、总结bias、variance、model complexity、underfit、overfit、generalization error、training error之间的关系:
Find best bias-variance trade-off according to the model complexity, otherwise leading to overfitting/underfitting, thus high generalization error:
模型简单——高bias—欠拟合(高test error、高training error)。增加训练数据无济于事
模型复杂——高variance——过拟合(高test error、低training error)。增加训练数据往往可以降低variance
关系图如下:
——————————————————————————————————————
test error的double descent现象
见于:线性模型、深度神经网络
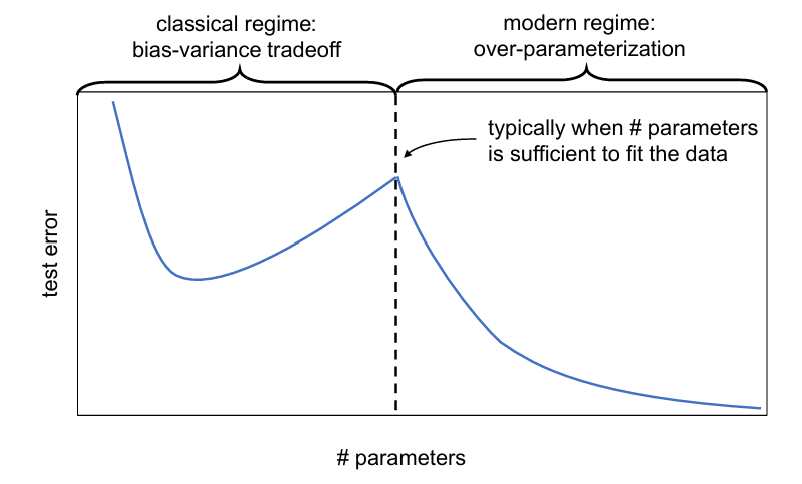
(1)model-wise double descent
模型复杂度(参数数量)↑,test error降-升-降
*在经典bias-variance trade-off中,test error随模型复杂度先降后升,但这里注意可能有第二个降,即继续增加模型参数,test error会降低
(2)sample-wise double descent
样本数量↑,test error降-升-降
*不是随着样本数量↑,test error一直降,中间会有个升降的过程
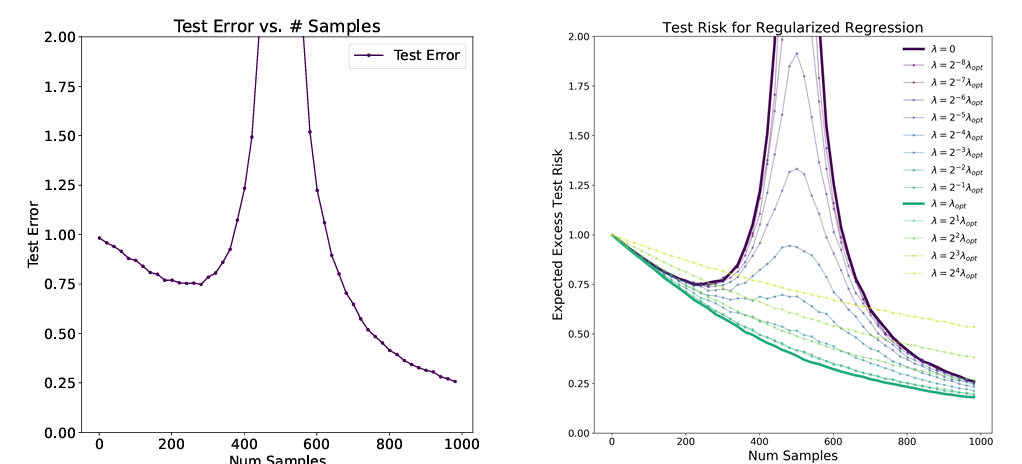
两种现象的test error极大值点均为n=d,样本数量=参数数量
这个点是我们不想要的,研究发现,通过正则化,可以降低此处的test error(上图的右图)
另外,为什么overparameterized model能够降低test error(泛化好)?可能解释为有隐式的正则化作用(implicit regularization)
—————————————————————————————————————
正则化Regularization
正则化的目的为防止过拟合,增强模型泛化能力
几个问题
1、什么是正则化
2、正则化为什么能防止过拟合
(1)直觉理解
regulate是规则化,对参数施加某种规则(impose structures on parameters)。
为什么正则化的对象是参数?正则化的目的为降低模型复杂度(让模型变简单,变“傻”),防止过拟合;而模型复杂度就是和参数相关的
可以提前想想,对参数施加何种规则有利于降低模型复杂度?稀疏sparse——非0参数少,大部分参数都是0(L1-norm)!这样模型不会因为有很多参数(模型很复杂)就去考虑所有的特征(包括noise和unrelated features)导致过拟合,而是利用少量的非0参数,只留下/只考虑真正有用的特征,这样得到一个具有代表性的模型,泛化能力强
(2)实施正则化
正则化其实就是在training loss function中加一项
到时候训练目标是最小化regularized loss function
使得正则项尽可能小:可以理解为正则项是一个关于参数
正则化参数
常用的Regularizers
线性模型:L1-norm、L2-norm(常用于kernal methods)
深度学习:L2-norm=weight-decay、dropout、data augmentation、regulating the Lipschitzness
—————————————————————————————————————
知识补充:范数norm
向量中非0元素的个数
绝对值之和。0范数和1范数均可实现稀疏,但1范数具有更好的优化求解特性,从而被广泛使用
平方和开根号=模。让其很小,可以使每个元素都很小,接近0但不等于0;这与 1范数让更多的等于0 不同
—————————————————————————————————————
(3)详解逻辑链:加入正则项&使其尽可能小 —— 参数的稀疏解 —— 防止过拟合,增加泛化能力
如果跳过“参数的稀疏解”,可以直觉理解为:正则项是一个关于参数
但是,如果一步一步看,该如何理解?
“参数的稀疏解 —— 防止过拟合,增加泛化能力”这一步,可以直觉理解为:稀疏sparse——比如非0参数少,大部分参数都是0(L1-norm)!这样模型不会因为有很多参数(模型很复杂)就去考虑所有的特征(包括noise和unrelated features)导致过拟合,而是利用少量的非0参数,只留下/只考虑真正有用的特征,这样得到一个具有代表性的模型,泛化能力强
“加入正则项&使其尽可能小 —— 参数的稀疏解”这一步,如何理解?
先看一下,各个范数的形状(x-y为参数平面,z为norm值的大小)

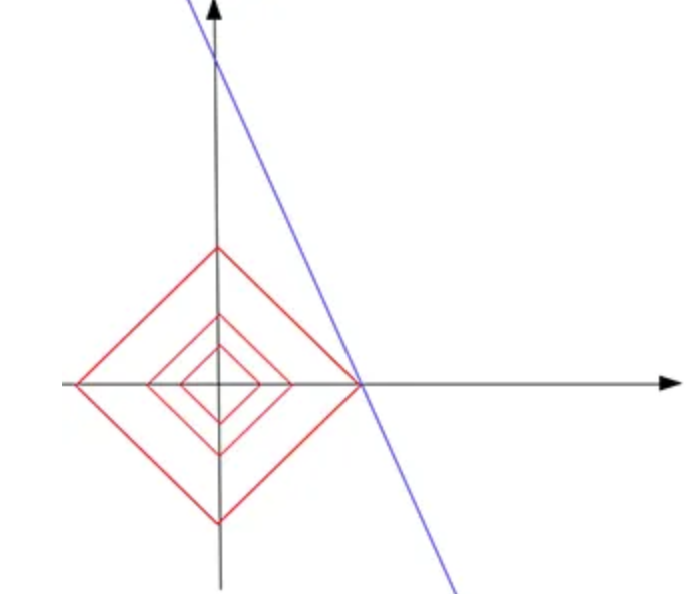
接下来都以L1-norm为例,注意看这是一个八棱锥,角/刺很多!
假设为线性回归模型
如果给了我们一个训练样本(a,b),但是因为有两个参数,则可得无数组参数解,形成一条直线
这时候,我们要(1)fit训练样本,即在那条直线上找参数解;(2)满足L1-norm的限制,即在上图八棱锥的形状内找参数解;(3)让L1-norm的值尽可能小(z小)
想实现上述目标,可以想象为,L1-norm的形状从原点开始长大,直到与此直线相“触碰”到(下图)。不难想象,有很大的概率,最先触碰到的点是八棱锥的刺!而这些刺,都会让两个参数中的其中一个为0,即为稀疏解!
有人会问,0<p<1不是刺更多,为什么不用这个?因为计算难度
—————————————————————————————————————
交叉验证cross validation(CV):hold-out CV、k-fold CV、leave-one-out CV
用于模型选择(传统机器学习数据量不大时常用)
1、hold-out CV
数据集中分70%训练、30%验证,对于每个待选模型,在训练集上训练,然后在验证集上验证,最后选择validation error最小的模型
缺点:浪费30%的数据
2、k-fold CV
数据集分为k份,对于每个待选模型,每次取k-1份训练,剩下1份验证,这样进行k次训练和验证,得到k次的平均validation error,最后选平均validation error最小的模型
优点:损失数据相对少,损失1/k的数据
缺点:计算量增加,每个模型都需要训练k次
3、leave-one-out CV
每次只留1个样本验证
适用于特别小的数据集(损失不起)
CV除了可以进行模型选择,还可以进行模型表现的评估。k折CV可以体现模型的稳定性。具体来说,训练集进行k折CV,然后测试集在每个模型上都进行测试,取均值作为最终表现
参考文献:
[1]https://cs229.stanford.edu/main_notes.pdf
[2]https://blog.mlreview.com/l1-norm-regularization-and-sparsity-explained-for-dummies-5b0e4be3938a
([2]这篇强推,正则化解释得太好了)
[3]https://www.cnblogs.com/nxf-rabbit75/p/10592583.html
[4]https://www.zhihu.com/tardis/bd/art/26884695
[5]https://zhuanlan.zhihu.com/p/25707761
[6]https://blog.csdn.net/kdongyi/article/details/83932945
[7]https://blog.csdn.net/weixin_42327752/article/details/121428875
[8]https://blog.csdn.net/tiaochewang219/article/details/107631221
本文来自博客园,作者:xjl-ultrasound,转载请注明原文链接:https://www.cnblogs.com/xjl-ultrasound/p/18316368


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端