

第一章 Scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
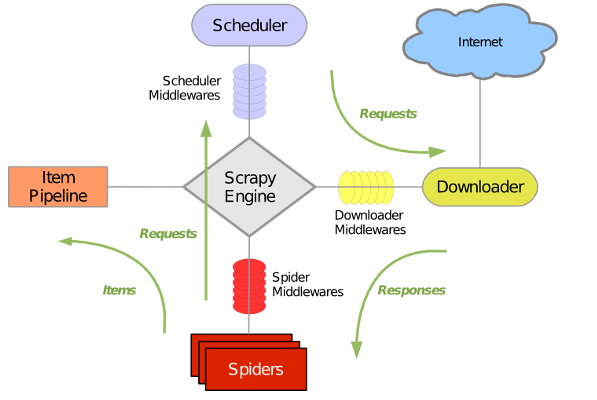
实例 :爬取163新闻
1 、创建scrapy项目
在项目文件目录下输入:
scrapy startproject news_163 # 项目名称自己设置
2、创建爬虫程序
cd news_163
# 创建包含名字,网站
scrapy genspider news_spider https://news.163.com/
3、scrapy项目文件说明
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的 配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
- middleware 中间件文件
注意:一般创建爬虫文件时,以网站域名命名
4、设置数据存储模板
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class News163Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
author =scrapy.Field()
5、编写爬虫
spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import News163Item
class NewsSpiderSpider(CrawlSpider):
name = 'news_spider'
# allowed_domains = ['dddd']
start_urls = ['https://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*news\.163\.com/19/0118/.*\d\.html'), callback='parse_item', follow=True),
Rule(LinkExtractor(allow=r'.*\.163\.com/19/0118/.*\d\.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
items = News163Item()
title = response.xpath('//h1/text()').extract()[0]
time = response.xpath('//div[@class="post_time_source"]/text()').re(r'.*?(20.*\d)')[0]
author = response.xpath('//a[@id="ne_article_source"]/text()').extract()[0]
if title:
items['title'] = title
if time:
items['time'] = time
if author:
items['author'] = author
return items
6、设置配置文件
settings.py修改
ROBOTSTXT_OBEY = True # robot协议
7、编写数据处理脚本
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class News163Pipeline(object):
def open_spider(self, spider):
print('开始程序=======================')
self.file = open("spider.json", "w")
self.n = 0
def process_item(self, item, spider):
self.file.write(str(self.n + 1) + ' : ' + str(item) + '\n')
self.n += 1
return item
def close_spider(self, spider):
self.file.close()
print('结束程序========================')
print(self.n)
8、执行爬虫
方法一:命令执行
# 进入项目目录
scrapy crawl news_spider
方法二:
# 进入项目目录
touch main.py # 创建一个py文件
vim main.py # 进入文件
# 运行该文件即可启动爬虫
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'news_spider'])
