爬虫---提取关键字生成词云图
提出问题
如何爬取新闻的关键字,并生成词云图或者饼图展示?
比如一则新闻:https://new.qq.com/rain/a/20230315A08LAK00。如下图所示:
解决思路
1、先爬取新闻中的所有文字
2、再把所有的文字分割,使之成为一个个的字
3、将出现的字进行统计,统计出次数靠前的10位
4、再生成词云图或饼图
请看以下代码:
一起看一下运行效果:

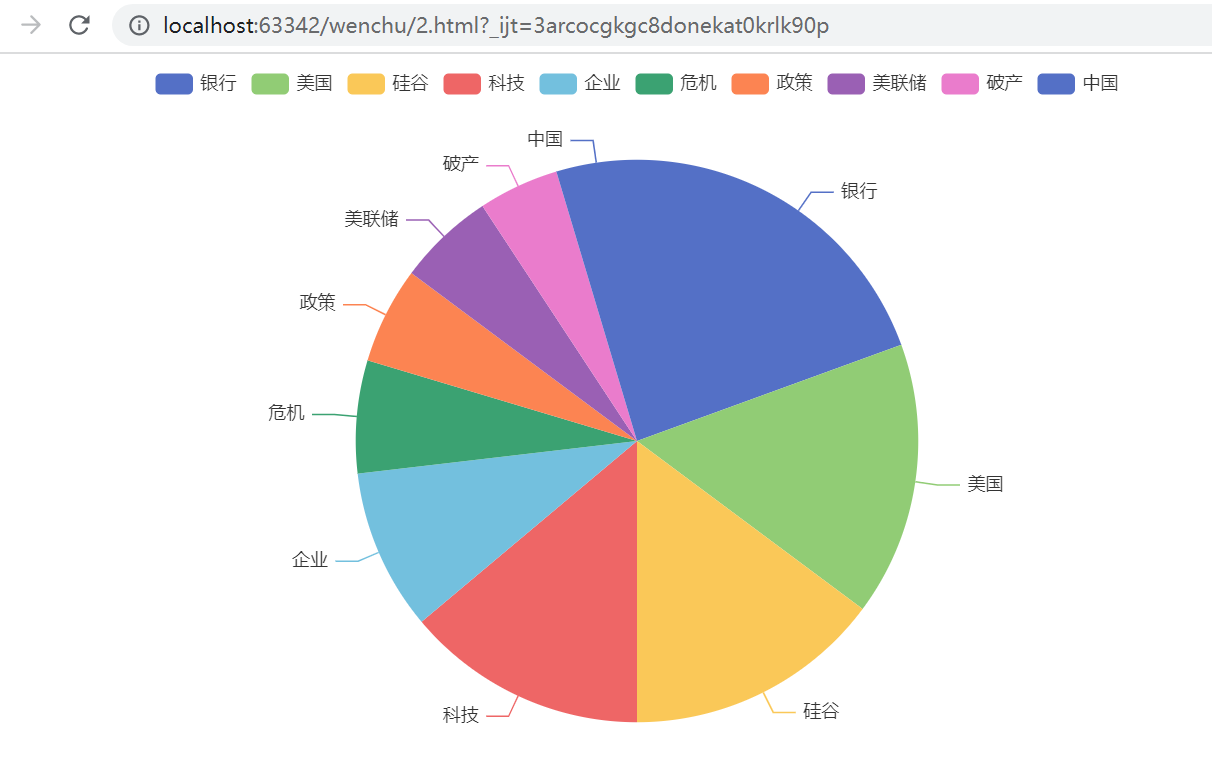
饼图:
__EOF__

本文作者:excellent_1
本文链接:https://www.cnblogs.com/xj-excellent/p/17237373.html
关于博主:互联网小萌新一名,希望从今天开始慢慢提高,一步步走向技术的高峰!
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/xj-excellent/p/17237373.html
关于博主:互联网小萌新一名,希望从今天开始慢慢提高,一步步走向技术的高峰!
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)