python的正则表达式(常用详解)
今天抽时间给大家整理一下正则表达式,有的同学可能还是不太懂这个东西,这次你看我的帖子,你就明白了,我写的博客真的通俗易懂,真的一点都不难,希望您耐心看完,保管有用。
正则表达式,主要是做什么用的?这个概念得先理解,明白这个,你就能看懂正则一半了,就是用来匹配数据的,好的,接下来给大家上一些代码和截图:
1.单字符
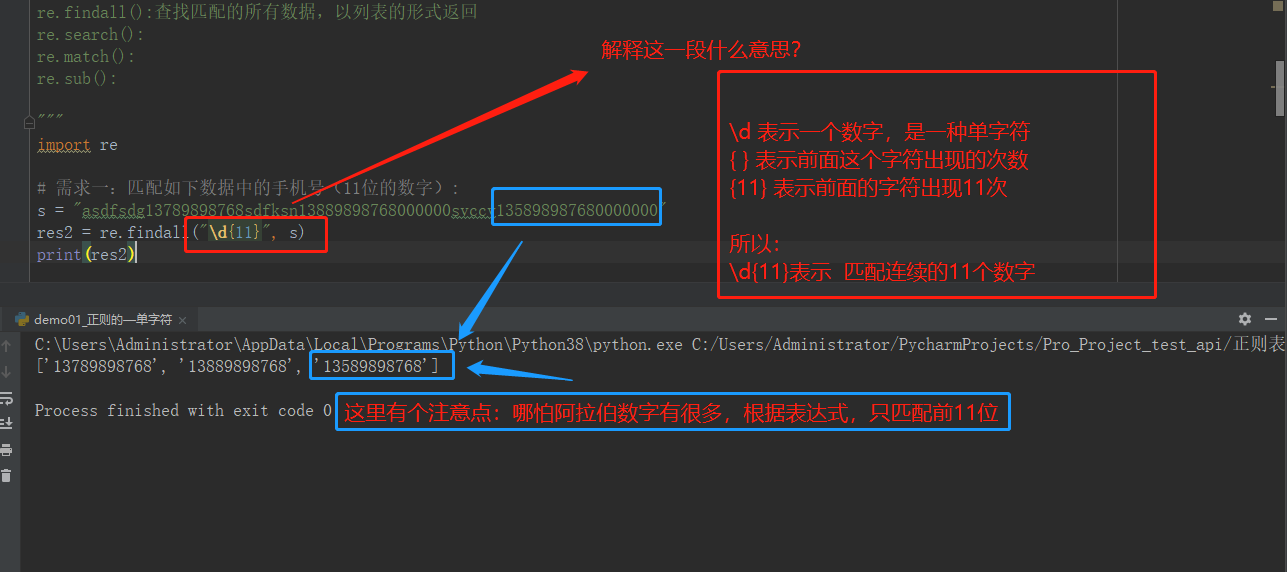
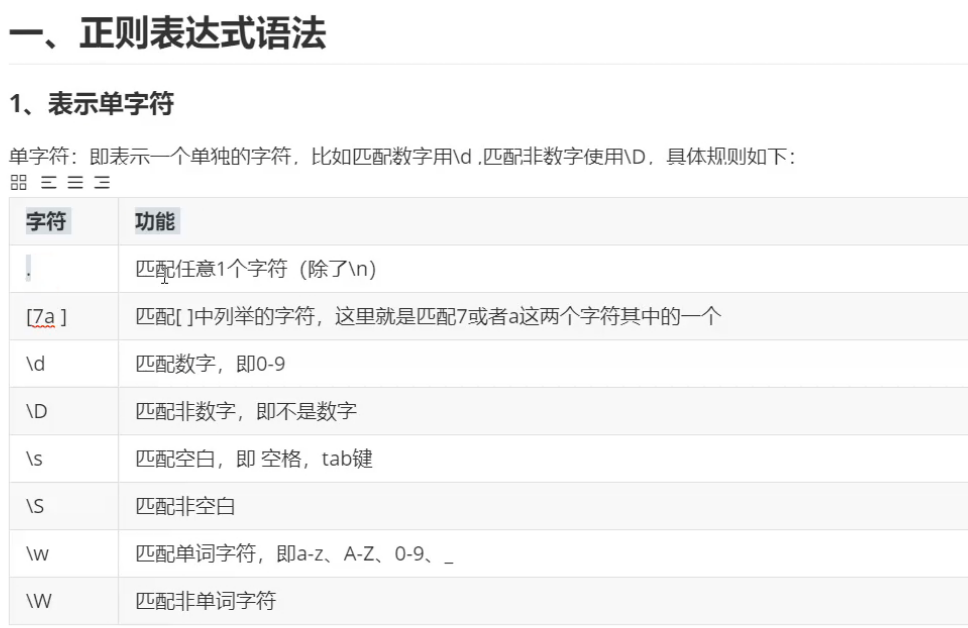
import re # 需求一:匹配如下数据中的手机号(11位的数字): # s = "asdfsdg13789898768sdfksn13889898768000000svccv135898987680000000" # res2 = re.findall("\d{11}", s) # print(res2) # --------------------单字符(元字符)--------------- # 1、. :匹配任意一个字符(除\n外) # res = re.findall(".", 'abcd1234?_!&\n') # print(res) #打印结果为 ['a', 'b', 'c', 'd', '1', '2', '3', '4', '?', '_', '!', '&'] # 2、[] :列举可以匹配的字符 # res = re.findall("[1-3]", 'ab243gzyw53cd1234?_!&\n') # 从后面的字符串中,匹配数字1,2,3 # print(res) #打印结果为 ['2', '3', '3', '1', '2', '3'] # # res1 = re.findall("[a-c]", 'ab243gzyw53cd1234?_!&\n') # 从后面的字符串中,匹配字母a到c # print(res1) #打印结果为 ['a', 'b', 'c'] # # res1 = re.findall("[a-c0-9A-Z]", 'ab243gzGDRyw53cd1234?_!&\n') # 从后面的字符串中,匹配所有的数字和字母 # print(res1) #打印结果为 ['a', 'b', '2', '4', '3', 'G', 'D', 'R', '5', '3', 'c', '1', '2', '3', '4'] # 3、\d:匹配任意一个数字 # res = re.findall("\d", 'ab243gzyw53cd1234?_!&\n') # print(res) #打印结果为 ['2', '4', '3', '5', '3', '1', '2', '3', '4'] # 4、\D:匹配任意一个非数字 # res = re.findall("\D",' ab243gzyw53cd1234?_!&\n') # 除数字之外的都能匹配 # print(res) # 打印结果为 [' ', 'a', 'b', 'g', 'z', 'y', 'w', 'c', 'd', '?', '_', '!', '&', '\n'] # 5、\s:匹配任意一个空白字符(空格键、tab键、\n符) # res = re.findall("\s", 'ab243gzyw5 3cd1 23 4?_!&\n') # print(res) # 打印结果为 [' ', ' ', ' ', ' ', ' ', ' ', ' ', '\n'] # 6、\S:匹配任意一个非空白字符 # res = re.findall("\S", 'ab2 43gzyw5') # print(res) # 打印结果为 ['a', 'b', '2', '4', '3', 'g', 'z', 'y', 'w', '5'] # 7、\w:匹配任意一个单字符(数字、字母、下划线) # res = re.findall("\w", 'ab243gzyw5 3cd1 23 4?_!&\n') # print(res) # 打印结果为 ['a', 'b', '2', '4', '3', 'g', 'z', 'y', 'w', '5', '3', 'c', 'd', '1', '2', '3', '4', '_'] # # 8、\W:匹配任意一个非单词字符(数字字母下划线) # res = re.findall("\W", 'ab243gzyw53cd1234?_!&\n') # print(res) # 打印结果为 ['?', '!', '&', '\n']
看代码,可能您有点烦,看不下去,好,我给您上图:
2.字符数量
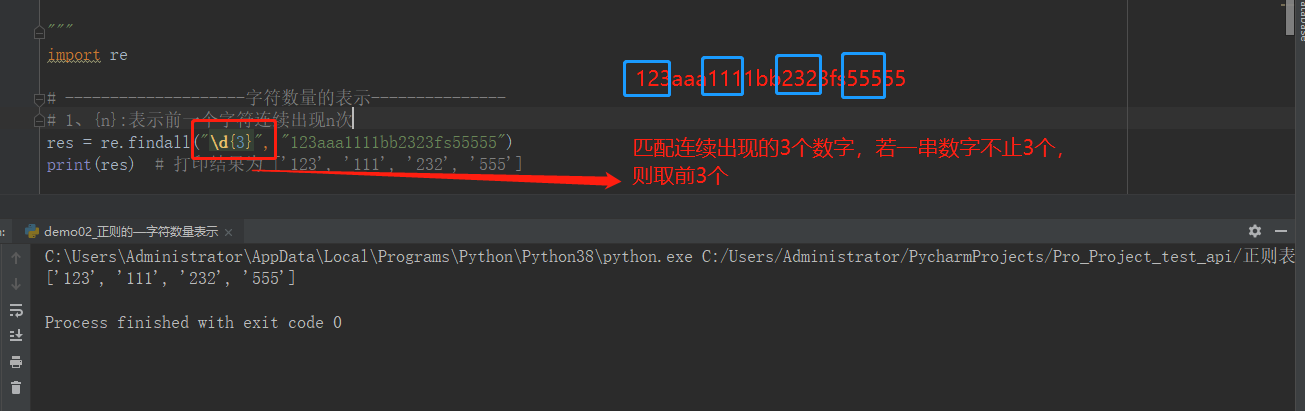
一般表示范围的:如下图所示

先给大家附上代码,后面才有截图解析
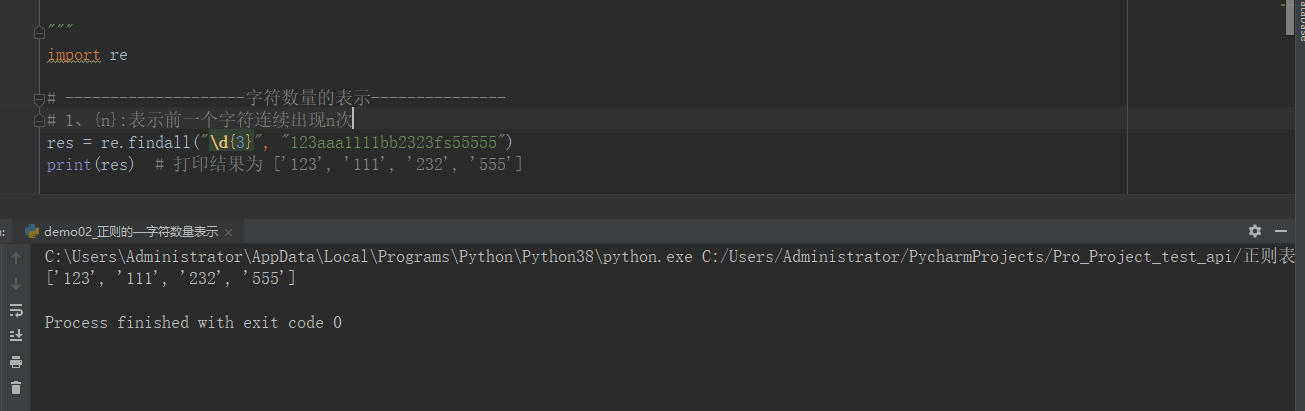
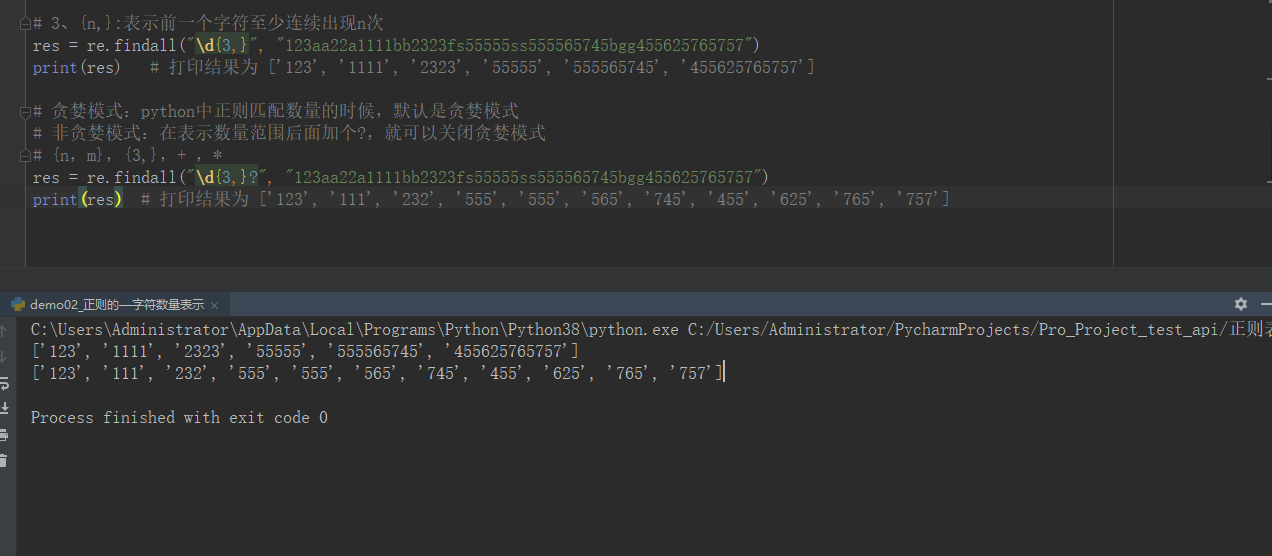
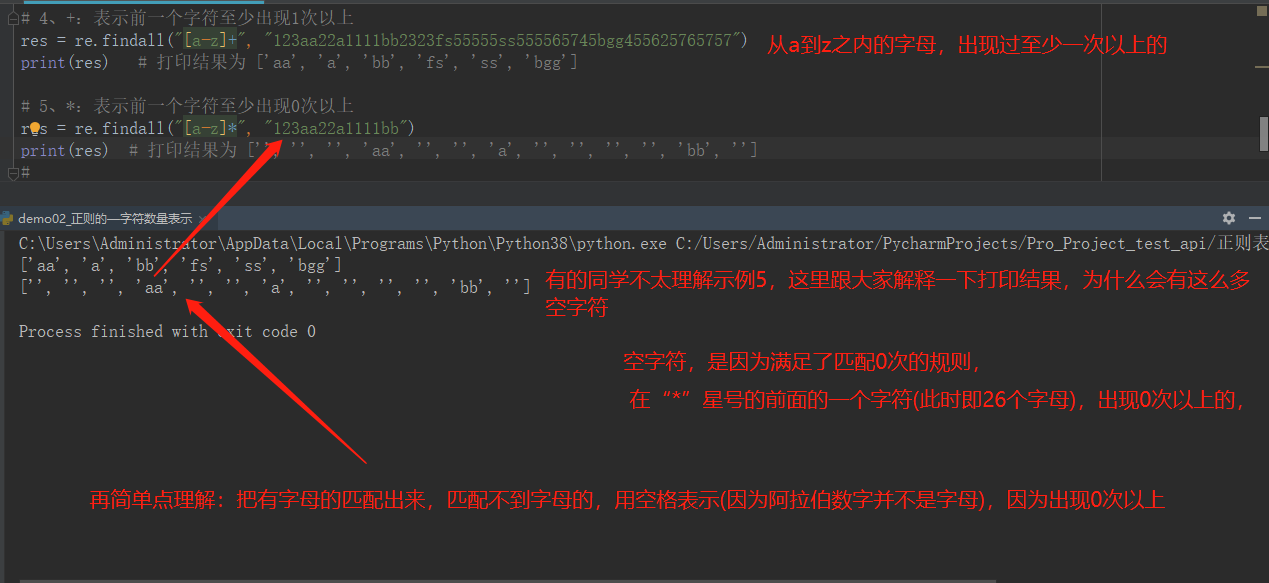
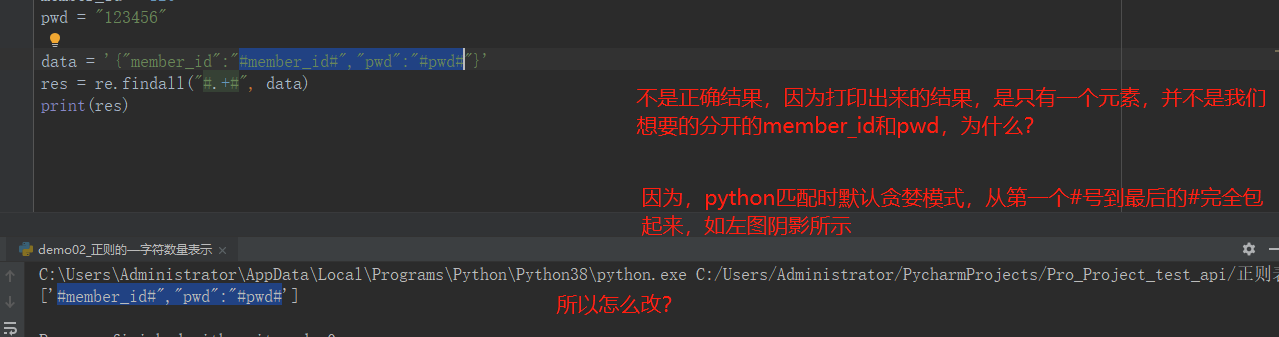
import re # --------------------字符数量的表示--------------- # 1、{n}:表示前一个字符连续出现n次 # res = re.findall("\d{3}", "123aaa1111bb2323fs55555") # print(res) # 打印结果为 ['123', '111', '232', '555'] # 2、{n,m}:表示前一个字符连续出现n-m次 # res = re.findall("\d{3,5}", "123aaa1111bb2323fs55555") # print(res) # 打印结果为 ['123', '1111', '2323', '55555'] # 3、{n,}:表示前一个字符至少连续出现n次 # res = re.findall("\d{3,}", "123aa22a1111bb2323fs55555ss555565745bgg455625765757") # print(res) # 打印结果为 ['123', '1111', '2323', '55555', '555565745', '455625765757'] # 贪婪模式:python中正则匹配数量的时候,默认是贪婪模式 # 非贪婪模式:在表示数量范围后面加个?,就可以关闭贪婪模式 # {n,m},{3,},+ ,* # res = re.findall("\d{3,}?", "123aa22a1111bb2323fs55555ss555565745bgg455625765757") # print(res) # 打印结果为 ['123', '111', '232', '555', '555', '565', '745', '455', '625', '765', '757'] # 4、+:表示前一个字符至少出现1次以上 # res = re.findall("[a-z]+", "123aa22a1111bb2323fs55555ss555565745bgg455625765757") # print(res) # 打印结果为 ['aa', 'a', 'bb', 'fs', 'ss', 'bgg'] # # # 5、*:表示前一个字符至少出现0次以上 # res = re.findall("[a-z]*", "123aa22a1111bb") # print(res) # 打印结果为 ['', '', '', 'aa', '', '', 'a', '', '', '', '', 'bb', ''] # member_id = 120 pwd = "123456" data = '{"member_id":"#member_id#","pwd":"#pwd#"}' res = re.findall("#.+?#", data) print(res) data2 = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#aaa#"}' res2 = re.findall("#.+?#", data2) print(res2)
截图解析,一张一张来,傻逼也能看得懂,更何况是聪明机智的正在阅读的你呢
另外,这里再给将一个很重要的知识点:贪婪模式与非贪婪模式
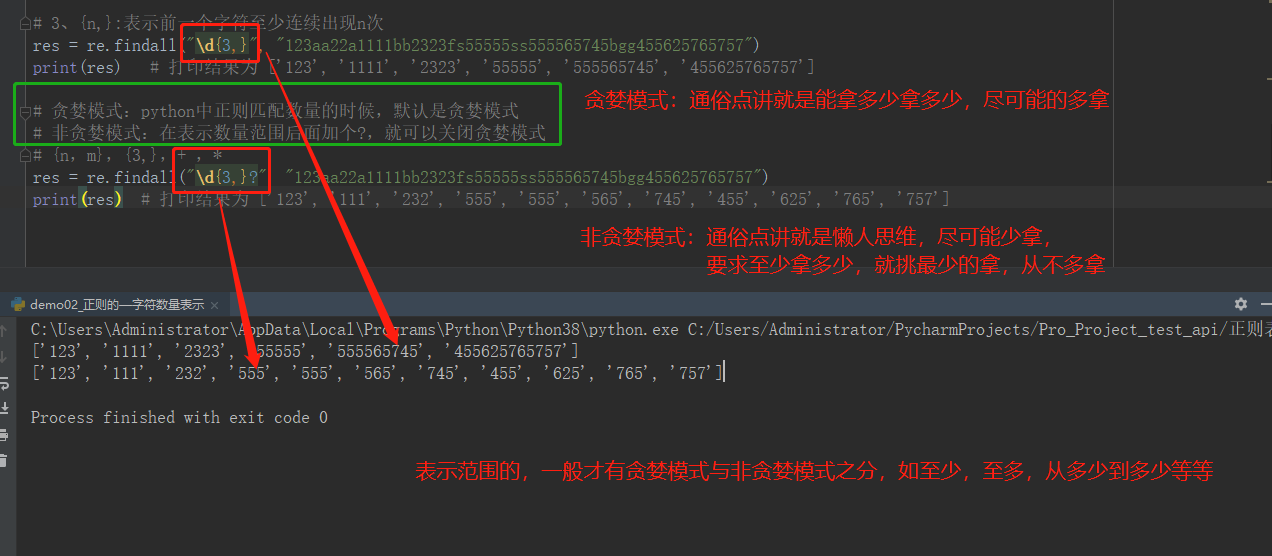
因为,涉及到这种模式的,还有 + * 等等,现在拿这两种举例,看下图
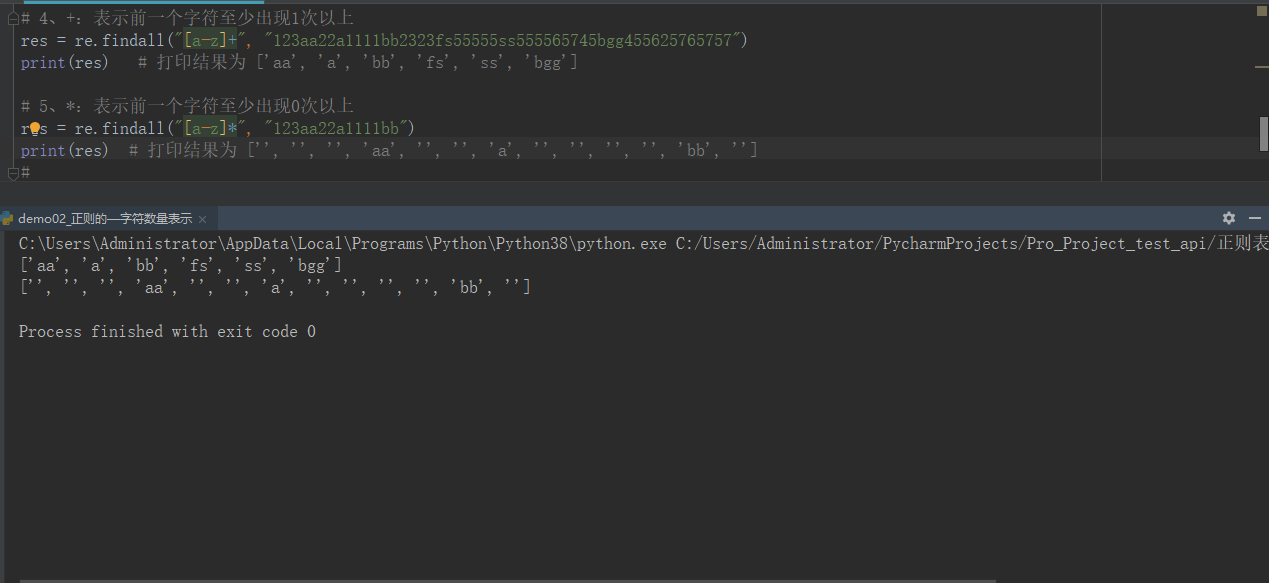
有的同学会问,这有什么实际应用呢?举个例子如何,好,继续往下看,


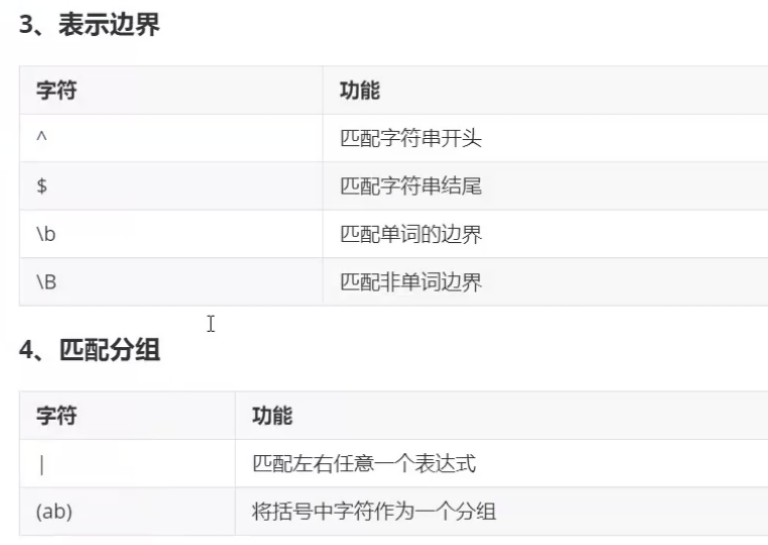
3.字符边界和匹配分组
import re # --------------------字符边界的表示--------------- # 1、^:表示字符串开头 # res = re.findall("^python", "python-00-java-00-php-python") # print(res) # 打印结果为 ['python'] # 2、$:表示字符串结尾 # res = re.findall("python$", "python-00-java-00-php-python") # print(res) # 打印结果为 ['python'] # # 3、\b:表示单词边界 # res = re.findall(r"\bpython\b", "python? java-00-java-00-php,python") # print(res) # 打印结果为 ['python', 'python'] # 4、\B:表示非单词边界 res = re.findall(r"\Bpython\B", "qqpythonqq? java-00-java-00-php,python") print(res) # 打印结果为 ['python']
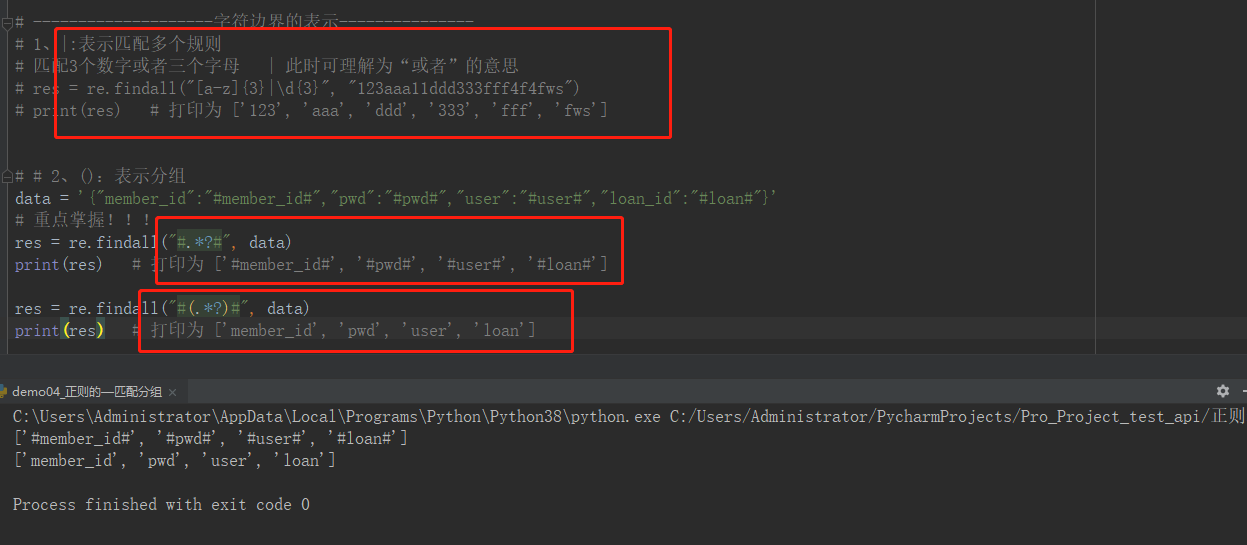
# --------------------匹配分组的表示--------------- # 1、|:表示匹配多个规则 # 匹配3个数字或者三个字母 | 此时可理解为“或者”的意思 # res = re.findall("[a-z]{3}|\d{3}", "123aaa11ddd333fff4f4fws") # print(res) # 打印为 ['123', 'aaa', 'ddd', '333', 'fff', 'fws'] # # 2、():表示分组 data = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#user#","loan_id":"#loan#"}' # 重点掌握!!! res = re.findall("#.*?#", data) print(res) # 打印为 ['#member_id#', '#pwd#', '#user#', '#loan#'] res = re.findall("#(.*?)#", data) print(res) # 打印为 ['member_id', 'pwd', 'user', 'loan']
4.正则参数替换
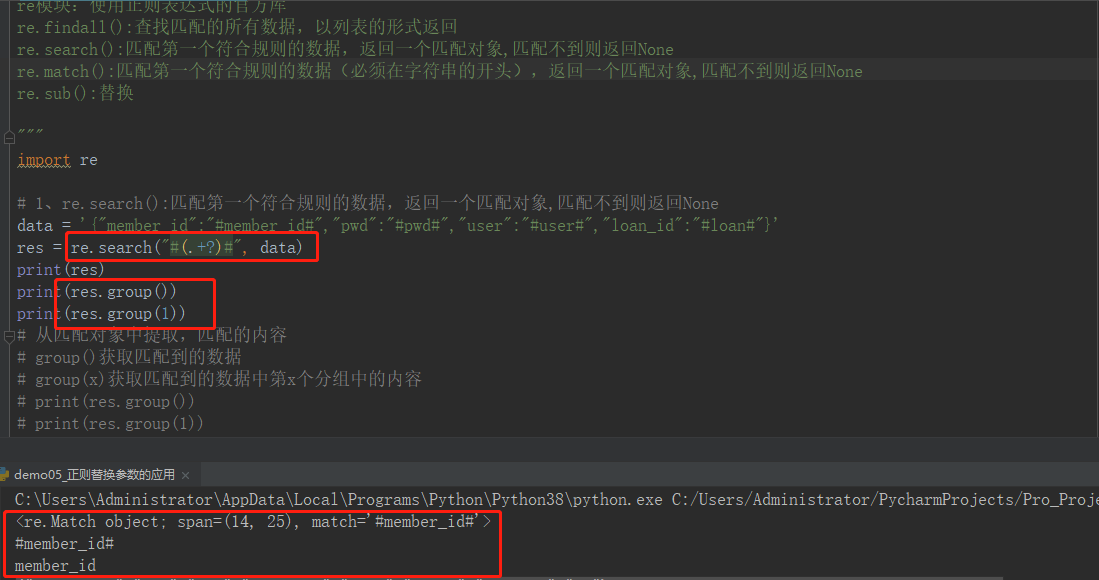
re模块:使用正则表达式的官方库
re.findall():查找匹配的所有数据,以列表的形式返回
re.search():匹配第一个符合规则的数据,返回一个匹配对象,匹配不到则返回None,此方法常用
re.match():匹配第一个符合规则的数据(必须在字符串的开头),返回一个匹配对象,匹配不到则返回None
re.sub():替换
import re # 1、re.search():匹配第一个符合规则的数据,返回一个匹配对象,匹配不到则返回None data = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#user#","loan_id":"#loan#"}' res = re.search("#(.+?)#", data) print(res) print(res.group()) print(res.group(1)) # 从匹配对象中提取,匹配的内容 # group()获取匹配到的数据 # group(x)获取匹配到的数据中第x个分组中的内容 # print(res.group()) # print(res.group(1)) # 了解即可 # 2、re.match():匹配第一个符合规则的数据(必须在字符串的开头),返回一个匹配对象 # 匹配不到则返回None data = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#user#","loan_id":"#loan#"}' res = re.match(r"{", data) print(res) class EnvDate: member_id = 123 user = "musen" pwd = "lemonban" loan = 31 # 3,sub # data = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#user#","loan_id":"#loan#"}' # data = re.sub("#.+?#",str(EnvDate.member_id),data) # print(data)