Halcon深度学习——奇异值检测
该方法属于无监督式的深度学习方法,优点:
1 无需标注
2 只训练正样本
3 可以在CPU下进行训练
4 具有较快的推断速度
适用场景:适合缺陷较为明显的项目
注意:设置的ImageWidth、ImageHeight ,以及自己采的图,尽量是32的倍数
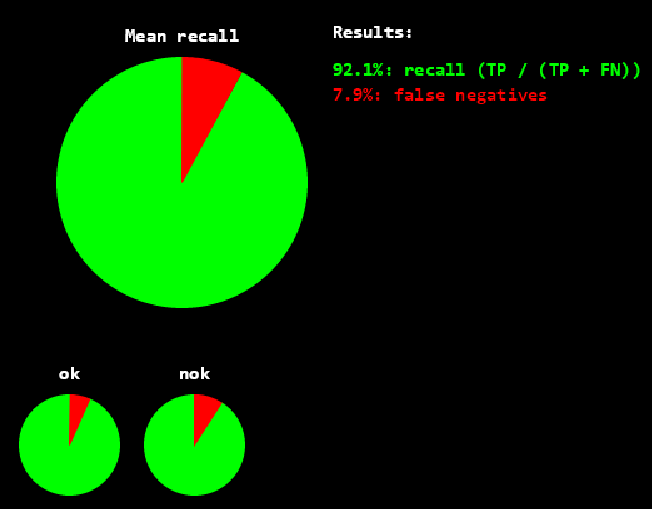
召回率(recall) == 92.1%,意味着ok图中7.9%被预测为ng
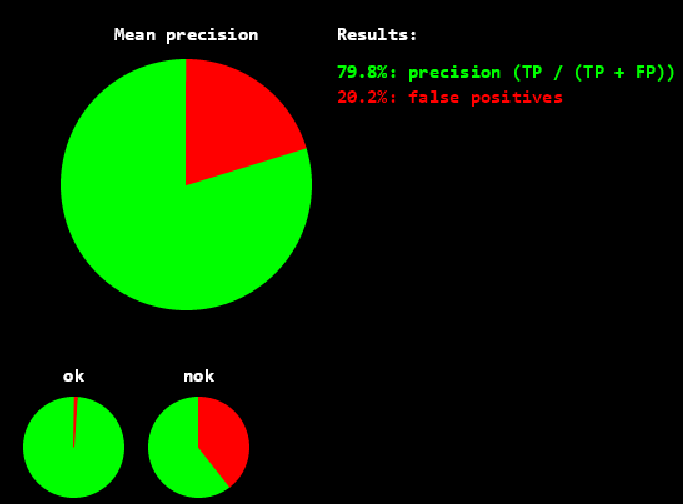
精确率(precision) =79.8%,意味着被认为是ok的图中有20.2%的ng图,即ng容易被检测成ok

主对角线数值越大越好,副对角线数值越小越好。47个OK被误判为ng,3个ng被误判为OK
dev_update_off () dev_close_window () set_system ('seed_rand', 25) * * *----------------------------- 0.) 样本、保存模型路径 -----------------------* * * 训练只需ok文件夹,其他文件夹用于之后的评估 * * 路径及子文件夹名 ImageDir := 'E:/整条' ImageSubDirs := ['ok','ng'] * * 缺陷区域的二值图路径(无) AnomalyDir := [] * * 所有样本预处理后的保存路径 OutputDir := ImageDir+'/anomaly_output_data' * 模型的保存路径+模型名 ModelFileFullName := ImageDir+'/model_final.hdl' * ********************** 自己需要设定的值 ****************** * * 数据集特定的预处理 ExampleSpecificPreprocessing := true * 缩放后的大小(32的倍数) ImageWidth := 320 ImageHeight := 320 * 复杂度,越大准确率越高,训练越耗时 Complexity := 15 * Complexity := 30 * *----------------------------- 1.) 读取、拆分样本集 DLDataset -----------------------* create_dict (GenParamDataset) set_dict_tuple (GenParamDataset, 'image_sub_dirs', ImageSubDirs) read_dl_dataset_anomaly (ImageDir, AnomalyDir, [], [], GenParamDataset, DLDataset) * 拆分样本集为训练集(60%)、验证集(20%)、测试集(剩余的20%) split_dl_dataset (DLDataset, 60, 20, []) * * 加载预训练模型、设置参数 read_dl_model ('initial_dl_anomaly_medium.hdl', DLModelHandle) *read_dl_model ('initial_dl_anomaly_large.hdl', DLModelHandle) set_dl_model_param (DLModelHandle, 'image_width', ImageWidth) set_dl_model_param (DLModelHandle, 'image_height', ImageHeight) set_dl_model_param (DLModelHandle, 'complexity', Complexity) *set_dl_model_param (DLModelHandle, 'runtime', 'cpu') set_dl_model_param (DLModelHandle, 'runtime', 'gpu') set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately') * 设置预处理参数,并进行预处理 create_dict (PreprocessSettings) set_dict_tuple (PreprocessSettings, 'overwrite_files', true) create_dl_preprocess_param ('anomaly_detection', ImageWidth, ImageHeight, 3, [], [], 'constant_values', 'full_domain', [], [], [], [], DLPreprocessParam) preprocess_dl_dataset (DLDataset, OutputDir, DLPreprocessParam, PreprocessSettings, DLDatasetFileName) * * 获取样本集DLDataset中的样本 get_dict_tuple (DLDataset, 'samples', DatasetSamples) if (ExampleSpecificPreprocessing) read_dl_samples (DLDataset, [0:|DatasetSamples| - 1], DLSampleBatch) preprocess_dl_samples_bottle(DLSampleBatch) write_dl_samples (DLDataset, [0:|DatasetSamples| - 1], DLSampleBatch, [], []) endif * * 展示10个随机预处理后的 DLSamples create_dict (WindowDict) for Index := 0 to 9 by 1 SampleIndex := int(rand(1) * |DatasetSamples|) read_dl_samples (DLDataset, SampleIndex, DLSample) dev_display_dl_data (DLSample, [], DLDataset, 'anomaly_ground_truth', [], WindowDict) dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) * get_dict_tuple (WindowDict, 'anomaly_ground_truth', WindowHandles) dev_set_window (WindowHandles[0]) dev_disp_text ('Preprocessed image', 'window', 'top', 'left', 'black', [], []) * *stop () endfor dev_close_window_dict (WindowDict) * *stop () * *----------------------------- 2.) 训练 DLDataset -----------------------* *--- 设置训练参数 * 是否展示训练过程 EnableDisplay := true * 设置训练终止条件,错误率、次数,满足其一则终止 ErrorThreshold := 0.001 MaxNumEpochs := 15 * 训练集中用于训练的样本比 *DomainRatio := 0.25 DomainRatio := 0.75 * 正则化噪声,使得训练更健壮。为防止训练失败,可以设置大些 RegularizationNoise := 0.01 * 创建字典,并存储键-值对 create_dict (TrainParamAnomaly) set_dict_tuple (TrainParamAnomaly, 'regularization_noise', RegularizationNoise) set_dict_tuple (TrainParamAnomaly, 'error_threshold', ErrorThreshold) set_dict_tuple (TrainParamAnomaly, 'domain_ratio', DomainRatio) *--- 创建训练参数 create_dl_train_param (DLModelHandle, MaxNumEpochs, [], EnableDisplay, 73, 'anomaly', TrainParamAnomaly, TrainParam) *--- 开始训练 train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos) dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) stop () * dev_close_window () * * 保存模型 write_dl_model (DLModelHandle, ModelFileFullName) * * *----------------------------- 3.) 评估模型(计算得到分类、分割的阈值) -----------------------* * 标准差因子(如果缺陷很小,推荐较大值) StandardDeviationFactor := 1.0 * 往字典DLModelHandle里存储键-值对 set_dl_model_param (DLModelHandle, 'standard_deviation_factor', StandardDeviationFactor) * 计算阈值 create_dict (GenParamThreshold) set_dict_tuple (GenParamThreshold, 'enable_display', 'true') compute_dl_anomaly_thresholds (DLModelHandle, DLDataset, GenParamThreshold, AnomalySegmentationThreshold, AnomalyClassificationThresholds) dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) stop () * dev_close_window () * * 设置评估参数,在test集上进行评估 create_dict (GenParamEvaluation) set_dict_tuple (GenParamEvaluation, 'measures', 'all') set_dict_tuple (GenParamEvaluation, 'anomaly_classification_thresholds', AnomalyClassificationThresholds) evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEvaluation, EvaluationResult, EvalParams) * * 要展示的参数 create_dict (GenParamDisplay) * 直方图、图例 set_dict_tuple (GenParamDisplay, 'display_mode', ['score_histogram','score_legend']) create_dict (WindowDict) dev_display_anomaly_detection_evaluation (EvaluationResult, EvalParams, GenParamDisplay, WindowDict) dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', 'box', 'true') stop () * dev_close_window_dict (WindowDict) * * 可视化precision精确率, recall召回率, and confusion matrix set_dict_tuple (GenParamDisplay, 'display_mode', ['pie_charts_precision','pie_charts_recall','absolute_confusion_matrix']) * 展示 AnomalyClassificationThresholds 中的一个阈值(第三个) set_dict_tuple (GenParamDisplay, 'classification_threshold_index', 2) create_dict (WindowDict) dev_display_anomaly_detection_evaluation (EvaluationResult, EvalParams, GenParamDisplay, WindowDict) dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) stop () * dev_close_window_dict (WindowDict) * * *----------------------------- 4.) 测试 -----------------------* *** read_dl_model(ModelFullName, DLModelHandle) ************************ 测试的样本,随机的10个ng图(低于10以实际为准) *list_image_files (ImageDir + '/' + ImageSubDirs, 'default', 'recursive', ImageFiles) list_image_files (ImageDir + '/' + 'ng', 'default', 'recursive', ImageFiles) * 打乱数据集 tuple_shuffle (ImageFiles, ImageFilesShuffled) * 设置阈值(模型训练后得到) InferenceClassificationThreshold := AnomalyClassificationThresholds[2] InferenceSegmentationThreshold := AnomalySegmentationThreshold * * 创建类别标签字典(不起作用,但是必须有) create_dict (DLDatasetInfo) set_dict_tuple (DLDatasetInfo, 'class_names', ['ok','ng']) set_dict_tuple (DLDatasetInfo, 'class_ids', [0,1]) * 创建字典,承载窗体信息 create_dict (WindowDict) for IndexInference := 0 to min2(|ImageFilesShuffled|,10) - 1 by 1 * 读图 read_image (Image, ImageFilesShuffled[IndexInference]) gen_dl_samples_from_images (Image, DLSample) preprocess_dl_samples(DLSample, DLPreprocessParam) * 与训练时相同的特定处理 if (ExampleSpecificPreprocessing) preprocess_dl_samples_bottle (DLSample) endif * apply_dl_model (DLModelHandle, DLSample, [], DLResult) threshold_dl_anomaly_results (InferenceSegmentationThreshold, InferenceClassificationThreshold, DLResult) * 展示结果 dev_display_dl_data (DLSample, DLResult, DLDatasetInfo, ['anomaly_result','anomaly_image'], [], WindowDict) dev_disp_text ('Press F5 (continue)', 'window', 'bottom', 'center', 'black', [], []) stop () endfor * ************************ 测试的样本,随机的10个ok图(低于10以实际为准) list_image_files (ImageDir + '/' + 'ok', 'default', 'recursive', ImageFiles) tuple_shuffle (ImageFiles, ImageFilesShuffled) for IndexInference := 0 to min2(|ImageFilesShuffled|,10) - 1 by 1 read_image (Image, ImageFilesShuffled[IndexInference]) gen_dl_samples_from_images (Image, DLSample) preprocess_dl_samples(DLSample, DLPreprocessParam) if (ExampleSpecificPreprocessing) preprocess_dl_samples_bottle (DLSample) endif apply_dl_model (DLModelHandle, DLSample, [], DLResult) threshold_dl_anomaly_results (InferenceSegmentationThreshold, InferenceClassificationThreshold, DLResult) dev_display_dl_data (DLSample, DLResult, DLDatasetInfo, ['anomaly_result','anomaly_image'], [], WindowDict) dev_disp_text ('Press F5 (continue)', 'window', 'bottom', 'center', 'black', [], []) stop () endfor dev_close_window_dict (WindowDict)
如果已有模型 *.hdl,可以直接测试
* 读取模型 read_dl_model ('E:/整条/model_final.hdl', DLModelHandle) * 设置阈值(模型训练后得到) InferenceClassificationThreshold := 0.183618 InferenceSegmentationThreshold := 0.236205 * 用模型中已设定的尺寸缩放 get_dl_model_param (DLModelHandle, 'image_width', ImageWidth) get_dl_model_param (DLModelHandle, 'image_height', ImageHeight) create_dl_preprocess_param ('anomaly_detection', ImageWidth, ImageHeight, 3, [], [], 'constant_values', 'full_domain', [], [], [], [], DLPreprocessParam) * 创建类别标签字典(不起作用,但是必须有) create_dict (DLDatasetInfo) set_dict_tuple (DLDatasetInfo, 'class_names', ['ok','ng']) set_dict_tuple (DLDatasetInfo, 'class_ids', ['0','1']) * 创建字典,承载窗体信息 create_dict (WindowDict) * 读图 list_files ('E:/整条/ng', ['files','follow_links','recursive'], ImageFiles) tuple_regexp_select (ImageFiles, ['\\.(tif|tiff|gif|bmp|jpg|jpeg|jp2|png|pcx|pgm|ppm|pbm|xwd|ima|hobj)$','ignore_case'], ImageFiles) for Index := 0 to |ImageFiles| - 1 by 1 read_image (Image, ImageFiles[Index]) * Image Acquisition 01: Do something gen_dl_samples_from_images (Image, DLSample) preprocess_dl_samples(DLSample, DLPreprocessParam) preprocess_dl_samples_bottle (DLSample) apply_dl_model (DLModelHandle, DLSample, [], DLResult) threshold_dl_anomaly_results (InferenceSegmentationThreshold, InferenceClassificationThreshold, DLResult) * 展示结果 dev_display_dl_data (DLSample, DLResult, DLDatasetInfo, ['anomaly_result','anomaly_image'], [], WindowDict) dev_disp_text ('Press F5 (continue)', 'window', 'bottom', 'center', 'black', [], []) stop () endfor dev_close_window_dict (WindowDict)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号