
【关系抽取-R-BERT】模型结构
模型的整体结构
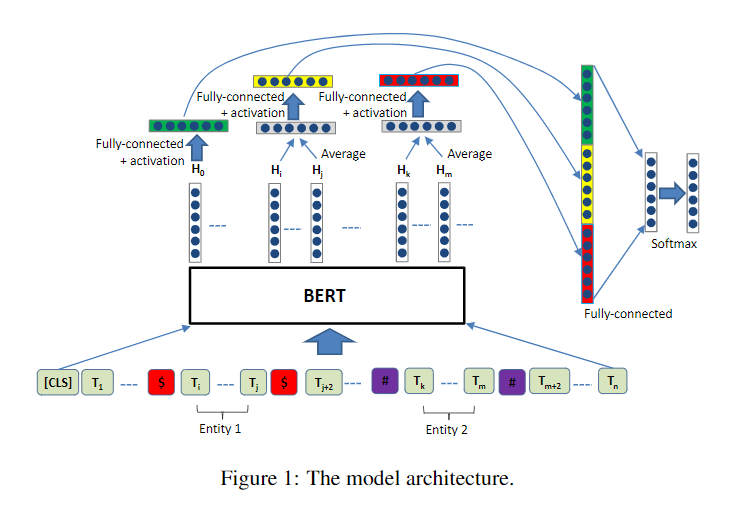
相关代码
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
class FCLayer(nn.Module):
def __init__(self, input_dim, output_dim, dropout_rate=0.0, use_activation=True):
super(FCLayer, self).__init__()
self.use_activation = use_activation
self.dropout = nn.Dropout(dropout_rate)
self.linear = nn.Linear(input_dim, output_dim)
self.tanh = nn.Tanh()
def forward(self, x):
x = self.dropout(x)
if self.use_activation:
x = self.tanh(x)
return self.linear(x)
class RBERT(BertPreTrainedModel):
def __init__(self, config, args):
super(RBERT, self).__init__(config)
self.bert = BertModel(config=config) # Load pretrained bert
self.num_labels = config.num_labels
self.cls_fc_layer = FCLayer(config.hidden_size, config.hidden_size, args.dropout_rate)
self.entity_fc_layer = FCLayer(config.hidden_size, config.hidden_size, args.dropout_rate)
self.label_classifier = FCLayer(
config.hidden_size * 3,
config.num_labels,
args.dropout_rate,
use_activation=False,
)
@staticmethod
def entity_average(hidden_output, e_mask):
"""
Average the entity hidden state vectors (H_i ~ H_j)
:param hidden_output: [batch_size, j-i+1, dim]
:param e_mask: [batch_size, max_seq_len]
e.g. e_mask[0] == [0, 0, 0, 1, 1, 1, 0, 0, ... 0]
:return: [batch_size, dim]
"""
e_mask_unsqueeze = e_mask.unsqueeze(1) # [b, 1, j-i+1]
length_tensor = (e_mask != 0).sum(dim=1).unsqueeze(1) # [batch_size, 1]
# [b, 1, j-i+1] * [b, j-i+1, dim] = [b, 1, dim] -> [b, dim]
sum_vector = torch.bmm(e_mask_unsqueeze.float(), hidden_output).squeeze(1)
avg_vector = sum_vector.float() / length_tensor.float() # broadcasting
return avg_vector
def forward(self, input_ids, attention_mask, token_type_ids, labels, e1_mask, e2_mask):
outputs = self.bert(
input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
sequence_output = outputs[0]
pooled_output = outputs[1] # [CLS]
# Average
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
# Dropout -> tanh -> fc_layer (Share FC layer for e1 and e2)
pooled_output = self.cls_fc_layer(pooled_output)
e1_h = self.entity_fc_layer(e1_h)
e2_h = self.entity_fc_layer(e2_h)
# Concat -> fc_layer
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=-1)
logits = self.label_classifier(concat_h)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
# Softmax
if labels is not None:
if self.num_labels == 1:
loss_fct = nn.MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)
代码解析
- 首先我们来看RBERT类,它继承了BertPreTrainedModel类,在类初始化的时候要传入两个参数:config和args,config是模型相关的,args是其它的一些配置。
- 假设输入的input_ids, attention_mask, token_type_ids, labels, e1_mask, e2_mask的维度分别是:(16表示的是batchsize的大小,384表示的是设置的句子的最大长度)
input_ids.shape= torch.Size([16, 384])
attention_mask.shape= torch.Size([16, 384])
token_type_ids.shape= torch.Size([16, 384])
labels.shape= torch.Size([16])
e1_mask.shape= torch.Size([16, 384])
e2_mask.shape= torch.Size([16, 384])
经过原始的bert之后得到output,其中outputs[0]的维度是[16,384,768],也就是每一个句子的表示,outputs[1]表示的是经过池化之后的句子表示,维度是[16,768],意思是将384个字的每个维度的特征通过池化将信息聚合在一起。 - 对于sequence_output, e1_mask或者sequence_output, e2_mask,我们将他们分别传入到entity_averag函数中,针对于e1_mask或者e2_mask,他们的维度都是[16,384],然后进行变换为[16,1,384],通过将[16,1,384]和[16,384,768]进行矩阵相乘,就得到了实体的特征表示,维度是[16,1,768],去除掉第1维再除以实体的长度进行归一化,最终得到一个[16,768]的表示。
- 我们将cls,也就是outputs[1],和实体1以及实体2的特征表示进行拼接,得到一个维度为[16,2304]的张量,再经过一个全连接层映射成[16,19],这里的19是类别的数目,最后使用相关的损失函数计算损失即可。
使用
最后是这么使用的:
定义相关参数以及设置
self.args = args
self.train_dataset = train_dataset
self.dev_dataset = dev_dataset
self.test_dataset = test_dataset
self.label_lst = get_label(args)
self.num_labels = len(self.label_lst)
self.config = BertConfig.from_pretrained(
args.model_name_or_path,
num_labels=self.num_labels,
finetuning_task=args.task,
id2label={str(i): label for i, label in enumerate(self.label_lst)},
label2id={label: i for i, label in enumerate(self.label_lst)},
)
self.model = RBERT.from_pretrained(args.model_name_or_path, config=self.config, args=args)
# GPU or CPU
self.device = "cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu"
self.model.to(self.device)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号