
图卷积网络(GCN)python实现
数据集为cora数据集,cora数据集由机器学习论文组成,共以下7类:
- 基于案例
- 遗传算法
- 神经网络
- 概率方法
- 强化学习
- 规则学习
- 理论
由cora.content和cora.cities文件构成。共2708个样本,每个样本的特征维度是1433。
下载地址:https://linqs.soe.ucsc.edu/data
cora.content:
每一行由论文id+特征向量+标签构成。
31336 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 Neural_Networks 1061127 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 Rule_Learning 1106406 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 Reinforcement_Learning 13195 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Reinforcement_Learning ......
cora.cities:
引用关系:被引论文编号以及引论文编号
35 1033 35 103482 35 103515 35 1050679 35 1103960 35 1103985 35 1109199 35 1112911 ......
读取数据集:
import numpy as np import scipy.sparse as sp import torch from sklearn.preprocessing import LabelBinarizer def normalize_adj(adjacency): adjacency += sp.eye(adjacency.shape[0]) degree = np.array(adjacency.sum(1)) d_hat = sp.diags(np.power(degree, -0.5).flatten()) return d_hat.dot(adjacency).dot(d_hat).tocoo() def normalize_features(features): return features / features.sum(1) def load_data(path="/content/drive/My Drive/nlpdata/cora/", dataset="cora"): """Load citation network dataset (cora only for now)""" print('Loading {} dataset...'.format(dataset)) idx_features_labels = np.genfromtxt("{}{}.content".format(path,dataset), dtype=np.dtype(str)) features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) encode_onehot = LabelBinarizer() labels = encode_onehot.fit_transform(idx_features_labels[:, -1]) # build graph idx = np.array(idx_features_labels[:, 0], dtype=np.int32) idx_map = {j: i for i, j in enumerate(idx)} edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset), dtype=np.int32) edges = np.array(list(map(idx_map.get, edges_unordered.flatten())), dtype=np.int32).reshape(edges_unordered.shape) adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), shape=(labels.shape[0], labels.shape[0]), dtype=np.float32) features = normalize_features(features) adj = normalize_adj(adj) idx_train = range(140) idx_val = range(200, 500) idx_test = range(500, 1500) features = torch.FloatTensor(np.array(features)) labels = torch.LongTensor(np.where(labels)[1]) num_nodes = features.shape[0] train_mask = np.zeros(num_nodes, dtype=np.bool) val_mask = np.zeros(num_nodes, dtype=np.bool) test_mask = np.zeros(num_nodes, dtype=np.bool) train_mask[idx_train] = True val_mask[idx_val] = True test_mask[idx_test] = True return adj, features, labels, train_mask, val_mask, test_mask
构建网络:
import numpy as np import scipy.sparse as sp import torch import torch.nn as nn import torch.nn.functional as F import torch.nn.init as init import torch.optim as optim import matplotlib.pyplot as plt from load_cora import * import sys sys.path.append("/content/drive/My Drive/nlpdata/cora/") class GraphConvolution(nn.Module): def __init__(self, input_dim, output_dim, use_bias=True): """图卷积:L*X*\theta Args: ---------- input_dim: int 节点输入特征的维度 output_dim: int 输出特征维度 use_bias : bool, optional 是否使用偏置 """ super(GraphConvolution, self).__init__() self.input_dim = input_dim self.output_dim = output_dim self.use_bias = use_bias self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim)) if self.use_bias: self.bias = nn.Parameter(torch.Tensor(output_dim)) else: self.register_parameter('bias', None) self.reset_parameters() def reset_parameters(self): init.kaiming_uniform_(self.weight) if self.use_bias: init.zeros_(self.bias) def forward(self, adjacency, input_feature): """邻接矩阵是稀疏矩阵,因此在计算时使用稀疏矩阵乘法 Args: ------- adjacency: torch.sparse.FloatTensor 邻接矩阵 input_feature: torch.Tensor 输入特征 """ device = "cuda" if torch.cuda.is_available() else "cpu" support = torch.mm(input_feature, self.weight.to(device)) output = torch.sparse.mm(adjacency, support) if self.use_bias: output += self.bias.to(device) return output def __repr__(self): return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')' # ## 模型定义 class GcnNet(nn.Module): """ 定义一个包含两层GraphConvolution的模型 """ def __init__(self, input_dim=1433): super(GcnNet, self).__init__() self.gcn1 = GraphConvolution(input_dim, 16) self.gcn2 = GraphConvolution(16, 7) def forward(self, adjacency, feature): h = F.relu(self.gcn1(adjacency, feature)) logits = self.gcn2(adjacency, h) return logits
进行训练和测试:
# ## 模型训练 # 超参数定义 learning_rate = 0.1 weight_decay = 5e-4 epochs = 200 # 模型定义:Model, Loss, Optimizer device = "cuda" if torch.cuda.is_available() else "cpu" model = GcnNet().to(device) criterion = nn.CrossEntropyLoss().to(device) optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) adjacency, features, labels, train_mask, val_mask, test_mask= load_data() tensor_x = features.to(device) tensor_y = labels.to(device) tensor_train_mask = torch.from_numpy(train_mask).to(device) tensor_val_mask = torch.from_numpy(val_mask).to(device) tensor_test_mask = torch.from_numpy(test_mask).to(device) indices = torch.from_numpy(np.asarray([adjacency.row, adjacency.col]).astype('int64')).long() values = torch.from_numpy(adjacency.data.astype(np.float32)) tensor_adjacency = torch.sparse.FloatTensor(indices, values, (2708, 2708)).to(device) # 训练主体函数 def train(): loss_history = [] val_acc_history = [] model.train() train_y = tensor_y[tensor_train_mask] for epoch in range(epochs): logits = model(tensor_adjacency, tensor_x) # 前向传播 train_mask_logits = logits[tensor_train_mask] # 只选择训练节点进行监督 loss = criterion(train_mask_logits, train_y) # 计算损失值 optimizer.zero_grad() loss.backward() # 反向传播计算参数的梯度 optimizer.step() # 使用优化方法进行梯度更新 train_acc, _, _ = test(tensor_train_mask) # 计算当前模型训练集上的准确率 val_acc, _, _ = test(tensor_val_mask) # 计算当前模型在验证集上的准确率 # 记录训练过程中损失值和准确率的变化,用于画图 loss_history.append(loss.item()) val_acc_history.append(val_acc.item()) print("Epoch {:03d}: Loss {:.4f}, TrainAcc {:.4}, ValAcc {:.4f}".format( epoch, loss.item(), train_acc.item(), val_acc.item())) return loss_history, val_acc_history # 测试函数 def test(mask): model.eval() with torch.no_grad(): logits = model(tensor_adjacency, tensor_x) test_mask_logits = logits[mask] predict_y = test_mask_logits.max(1)[1] accuarcy = torch.eq(predict_y, tensor_y[mask]).float().mean() return accuarcy, test_mask_logits.cpu().numpy(), tensor_y[mask].cpu().numpy() if __name__ == "__main__": train() test_accuracy, _, _ = test(tensor_test_mask) print("测试准确率是:{:.4f}".format(test_accuracy))
结果:
Loading cora dataset... Epoch 000: Loss 1.9681, TrainAcc 0.3286, ValAcc 0.3467 Epoch 001: Loss 1.7307, TrainAcc 0.4786, ValAcc 0.4033 Epoch 002: Loss 1.5521, TrainAcc 0.5214, ValAcc 0.4033 Epoch 003: Loss 1.3685, TrainAcc 0.6143, ValAcc 0.5100 Epoch 004: Loss 1.1594, TrainAcc 0.75, ValAcc 0.5767 Epoch 005: Loss 0.9785, TrainAcc 0.7857, ValAcc 0.5900 Epoch 006: Loss 0.8226, TrainAcc 0.8286, ValAcc 0.5867 Epoch 007: Loss 0.6849, TrainAcc 0.8929, ValAcc 0.6200 Epoch 008: Loss 0.5448, TrainAcc 0.9429, ValAcc 0.6433 Epoch 009: Loss 0.4152, TrainAcc 0.9429, ValAcc 0.6667 Epoch 010: Loss 0.3221, TrainAcc 0.9857, ValAcc 0.6767 Epoch 011: Loss 0.2547, TrainAcc 1.0, ValAcc 0.7033 Epoch 012: Loss 0.1979, TrainAcc 1.0, ValAcc 0.7167 Epoch 013: Loss 0.1536, TrainAcc 1.0, ValAcc 0.7000 Epoch 014: Loss 0.1276, TrainAcc 1.0, ValAcc 0.6700 Epoch 015: Loss 0.1122, TrainAcc 1.0, ValAcc 0.6867 Epoch 016: Loss 0.0979, TrainAcc 1.0, ValAcc 0.6800 Epoch 017: Loss 0.0876, TrainAcc 1.0, ValAcc 0.6700 Epoch 018: Loss 0.0821, TrainAcc 1.0, ValAcc 0.6667 Epoch 019: Loss 0.0799, TrainAcc 1.0, ValAcc 0.6800 Epoch 020: Loss 0.0804, TrainAcc 1.0, ValAcc 0.6933 Epoch 021: Loss 0.0852, TrainAcc 1.0, ValAcc 0.6833 Epoch 022: Loss 0.0904, TrainAcc 1.0, ValAcc 0.6700 Epoch 023: Loss 0.0914, TrainAcc 1.0, ValAcc 0.6700 Epoch 024: Loss 0.0926, TrainAcc 1.0, ValAcc 0.6400 Epoch 025: Loss 0.0953, TrainAcc 1.0, ValAcc 0.6300 Epoch 026: Loss 0.0931, TrainAcc 1.0, ValAcc 0.6467 Epoch 027: Loss 0.0880, TrainAcc 1.0, ValAcc 0.6600 Epoch 028: Loss 0.0851, TrainAcc 1.0, ValAcc 0.6567 Epoch 029: Loss 0.0814, TrainAcc 1.0, ValAcc 0.6600 Epoch 030: Loss 0.0756, TrainAcc 1.0, ValAcc 0.6433 Epoch 031: Loss 0.0709, TrainAcc 1.0, ValAcc 0.6567 Epoch 032: Loss 0.0682, TrainAcc 1.0, ValAcc 0.6467 Epoch 033: Loss 0.0656, TrainAcc 1.0, ValAcc 0.6700 Epoch 034: Loss 0.0628, TrainAcc 1.0, ValAcc 0.6633 Epoch 035: Loss 0.0618, TrainAcc 1.0, ValAcc 0.6833 Epoch 036: Loss 0.0617, TrainAcc 1.0, ValAcc 0.6700 Epoch 037: Loss 0.0615, TrainAcc 1.0, ValAcc 0.6667 Epoch 038: Loss 0.0615, TrainAcc 1.0, ValAcc 0.6600 Epoch 039: Loss 0.0616, TrainAcc 1.0, ValAcc 0.6733 Epoch 040: Loss 0.0613, TrainAcc 1.0, ValAcc 0.6800 Epoch 041: Loss 0.0610, TrainAcc 1.0, ValAcc 0.6867 Epoch 042: Loss 0.0603, TrainAcc 1.0, ValAcc 0.6800 Epoch 043: Loss 0.0598, TrainAcc 1.0, ValAcc 0.6667 Epoch 044: Loss 0.0592, TrainAcc 1.0, ValAcc 0.6833 Epoch 045: Loss 0.0584, TrainAcc 1.0, ValAcc 0.6833 Epoch 046: Loss 0.0575, TrainAcc 1.0, ValAcc 0.6967 Epoch 047: Loss 0.0570, TrainAcc 1.0, ValAcc 0.6900 Epoch 048: Loss 0.0565, TrainAcc 1.0, ValAcc 0.6933 Epoch 049: Loss 0.0560, TrainAcc 1.0, ValAcc 0.6867 Epoch 050: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6900 Epoch 051: Loss 0.0557, TrainAcc 1.0, ValAcc 0.6900 Epoch 052: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6967 Epoch 053: Loss 0.0554, TrainAcc 1.0, ValAcc 0.6867 Epoch 054: Loss 0.0552, TrainAcc 1.0, ValAcc 0.6867 Epoch 055: Loss 0.0550, TrainAcc 1.0, ValAcc 0.6933 Epoch 056: Loss 0.0549, TrainAcc 1.0, ValAcc 0.7000 Epoch 057: Loss 0.0548, TrainAcc 1.0, ValAcc 0.7000 Epoch 058: Loss 0.0547, TrainAcc 1.0, ValAcc 0.7067 Epoch 059: Loss 0.0546, TrainAcc 1.0, ValAcc 0.7000 Epoch 060: Loss 0.0545, TrainAcc 1.0, ValAcc 0.6967 Epoch 061: Loss 0.0545, TrainAcc 1.0, ValAcc 0.6967 Epoch 062: Loss 0.0544, TrainAcc 1.0, ValAcc 0.7067 Epoch 063: Loss 0.0544, TrainAcc 1.0, ValAcc 0.7067 Epoch 064: Loss 0.0543, TrainAcc 1.0, ValAcc 0.7033 Epoch 065: Loss 0.0542, TrainAcc 1.0, ValAcc 0.7000 Epoch 066: Loss 0.0542, TrainAcc 1.0, ValAcc 0.7000 Epoch 067: Loss 0.0542, TrainAcc 1.0, ValAcc 0.7033 Epoch 068: Loss 0.0542, TrainAcc 1.0, ValAcc 0.7067 Epoch 069: Loss 0.0542, TrainAcc 1.0, ValAcc 0.7033 Epoch 070: Loss 0.0543, TrainAcc 1.0, ValAcc 0.7033 Epoch 071: Loss 0.0543, TrainAcc 1.0, ValAcc 0.7000 Epoch 072: Loss 0.0543, TrainAcc 1.0, ValAcc 0.7033 Epoch 073: Loss 0.0544, TrainAcc 1.0, ValAcc 0.7067 Epoch 074: Loss 0.0544, TrainAcc 1.0, ValAcc 0.7067 Epoch 075: Loss 0.0545, TrainAcc 1.0, ValAcc 0.7133 Epoch 076: Loss 0.0545, TrainAcc 1.0, ValAcc 0.7100 Epoch 077: Loss 0.0546, TrainAcc 1.0, ValAcc 0.7133 Epoch 078: Loss 0.0546, TrainAcc 1.0, ValAcc 0.7067 Epoch 079: Loss 0.0547, TrainAcc 1.0, ValAcc 0.7133 Epoch 080: Loss 0.0547, TrainAcc 1.0, ValAcc 0.7033 Epoch 081: Loss 0.0548, TrainAcc 1.0, ValAcc 0.7100 Epoch 082: Loss 0.0549, TrainAcc 1.0, ValAcc 0.7067 Epoch 083: Loss 0.0549, TrainAcc 1.0, ValAcc 0.7133 Epoch 084: Loss 0.0549, TrainAcc 1.0, ValAcc 0.7067 Epoch 085: Loss 0.0550, TrainAcc 1.0, ValAcc 0.7100 Epoch 086: Loss 0.0550, TrainAcc 1.0, ValAcc 0.7033 Epoch 087: Loss 0.0551, TrainAcc 1.0, ValAcc 0.7133 Epoch 088: Loss 0.0551, TrainAcc 1.0, ValAcc 0.7067 Epoch 089: Loss 0.0552, TrainAcc 1.0, ValAcc 0.7100 Epoch 090: Loss 0.0553, TrainAcc 1.0, ValAcc 0.6967 Epoch 091: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7067 Epoch 092: Loss 0.0554, TrainAcc 1.0, ValAcc 0.6900 Epoch 093: Loss 0.0556, TrainAcc 1.0, ValAcc 0.7100 Epoch 094: Loss 0.0557, TrainAcc 1.0, ValAcc 0.6833 Epoch 095: Loss 0.0561, TrainAcc 1.0, ValAcc 0.7033 Epoch 096: Loss 0.0558, TrainAcc 1.0, ValAcc 0.6833 Epoch 097: Loss 0.0557, TrainAcc 1.0, ValAcc 0.7100 Epoch 098: Loss 0.0547, TrainAcc 1.0, ValAcc 0.7133 Epoch 099: Loss 0.0546, TrainAcc 1.0, ValAcc 0.6900 Epoch 100: Loss 0.0555, TrainAcc 1.0, ValAcc 0.7033 Epoch 101: Loss 0.0561, TrainAcc 1.0, ValAcc 0.6700 Epoch 102: Loss 0.0579, TrainAcc 1.0, ValAcc 0.6967 Epoch 103: Loss 0.0577, TrainAcc 1.0, ValAcc 0.6633 Epoch 104: Loss 0.0600, TrainAcc 1.0, ValAcc 0.7000 Epoch 105: Loss 0.0550, TrainAcc 1.0, ValAcc 0.6967 Epoch 106: Loss 0.0540, TrainAcc 1.0, ValAcc 0.6767 Epoch 107: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6967 Epoch 108: Loss 0.0528, TrainAcc 1.0, ValAcc 0.7000 Epoch 109: Loss 0.0571, TrainAcc 1.0, ValAcc 0.6700 Epoch 110: Loss 0.0643, TrainAcc 1.0, ValAcc 0.6933 Epoch 111: Loss 0.0583, TrainAcc 1.0, ValAcc 0.6800 Epoch 112: Loss 0.0533, TrainAcc 1.0, ValAcc 0.6700 Epoch 113: Loss 0.0552, TrainAcc 1.0, ValAcc 0.7067 Epoch 114: Loss 0.0534, TrainAcc 1.0, ValAcc 0.6967 Epoch 115: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6833 Epoch 116: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6800 Epoch 117: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6933 Epoch 118: Loss 0.0601, TrainAcc 1.0, ValAcc 0.6700 Epoch 119: Loss 0.0707, TrainAcc 1.0, ValAcc 0.6667 Epoch 120: Loss 0.0670, TrainAcc 1.0, ValAcc 0.6500 Epoch 121: Loss 0.0574, TrainAcc 1.0, ValAcc 0.6467 Epoch 122: Loss 0.0589, TrainAcc 1.0, ValAcc 0.7033 Epoch 123: Loss 0.0493, TrainAcc 1.0, ValAcc 0.6800 Epoch 124: Loss 0.0591, TrainAcc 1.0, ValAcc 0.6900 Epoch 125: Loss 0.0482, TrainAcc 1.0, ValAcc 0.6600 Epoch 126: Loss 0.0562, TrainAcc 1.0, ValAcc 0.6667 Epoch 127: Loss 0.0538, TrainAcc 1.0, ValAcc 0.6900 Epoch 128: Loss 0.0579, TrainAcc 1.0, ValAcc 0.6867 Epoch 129: Loss 0.0557, TrainAcc 1.0, ValAcc 0.6833 Epoch 130: Loss 0.0615, TrainAcc 1.0, ValAcc 0.6733 Epoch 131: Loss 0.0570, TrainAcc 1.0, ValAcc 0.6667 Epoch 132: Loss 0.0612, TrainAcc 1.0, ValAcc 0.6700 Epoch 133: Loss 0.0669, TrainAcc 1.0, ValAcc 0.6967 Epoch 134: Loss 0.0544, TrainAcc 1.0, ValAcc 0.6767 Epoch 135: Loss 0.0605, TrainAcc 1.0, ValAcc 0.6567 Epoch 136: Loss 0.0546, TrainAcc 1.0, ValAcc 0.6567 Epoch 137: Loss 0.0586, TrainAcc 1.0, ValAcc 0.7033 Epoch 138: Loss 0.0501, TrainAcc 1.0, ValAcc 0.6833 Epoch 139: Loss 0.0600, TrainAcc 1.0, ValAcc 0.7067 Epoch 140: Loss 0.0513, TrainAcc 1.0, ValAcc 0.6633 Epoch 141: Loss 0.0587, TrainAcc 1.0, ValAcc 0.6733 Epoch 142: Loss 0.0556, TrainAcc 1.0, ValAcc 0.6833 Epoch 143: Loss 0.0586, TrainAcc 1.0, ValAcc 0.6967 Epoch 144: Loss 0.0565, TrainAcc 1.0, ValAcc 0.6900 Epoch 145: Loss 0.0586, TrainAcc 1.0, ValAcc 0.6833 Epoch 146: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6767 Epoch 147: Loss 0.0589, TrainAcc 1.0, ValAcc 0.6800 Epoch 148: Loss 0.0562, TrainAcc 1.0, ValAcc 0.6900 Epoch 149: Loss 0.0560, TrainAcc 1.0, ValAcc 0.6933 Epoch 150: Loss 0.0565, TrainAcc 1.0, ValAcc 0.6833 Epoch 151: Loss 0.0547, TrainAcc 1.0, ValAcc 0.6767 Epoch 152: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6967 Epoch 153: Loss 0.0549, TrainAcc 1.0, ValAcc 0.6933 Epoch 154: Loss 0.0567, TrainAcc 1.0, ValAcc 0.7000 Epoch 155: Loss 0.0556, TrainAcc 1.0, ValAcc 0.6867 Epoch 156: Loss 0.0568, TrainAcc 1.0, ValAcc 0.6967 Epoch 157: Loss 0.0558, TrainAcc 1.0, ValAcc 0.6967 Epoch 158: Loss 0.0568, TrainAcc 1.0, ValAcc 0.6867 Epoch 159: Loss 0.0560, TrainAcc 1.0, ValAcc 0.6867 Epoch 160: Loss 0.0563, TrainAcc 1.0, ValAcc 0.6933 Epoch 161: Loss 0.0562, TrainAcc 1.0, ValAcc 0.6967 Epoch 162: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6833 Epoch 163: Loss 0.0556, TrainAcc 1.0, ValAcc 0.7000 Epoch 164: Loss 0.0554, TrainAcc 1.0, ValAcc 0.7033 Epoch 165: Loss 0.0556, TrainAcc 1.0, ValAcc 0.6967 Epoch 166: Loss 0.0553, TrainAcc 1.0, ValAcc 0.6900 Epoch 167: Loss 0.0555, TrainAcc 1.0, ValAcc 0.7033 Epoch 168: Loss 0.0554, TrainAcc 1.0, ValAcc 0.6967 Epoch 169: Loss 0.0560, TrainAcc 1.0, ValAcc 0.6833 Epoch 170: Loss 0.0558, TrainAcc 1.0, ValAcc 0.6900 Epoch 171: Loss 0.0561, TrainAcc 1.0, ValAcc 0.7033 Epoch 172: Loss 0.0560, TrainAcc 1.0, ValAcc 0.6967 Epoch 173: Loss 0.0559, TrainAcc 1.0, ValAcc 0.6833 Epoch 174: Loss 0.0557, TrainAcc 1.0, ValAcc 0.6967 Epoch 175: Loss 0.0554, TrainAcc 1.0, ValAcc 0.7033 Epoch 176: Loss 0.0554, TrainAcc 1.0, ValAcc 0.7033 Epoch 177: Loss 0.0551, TrainAcc 1.0, ValAcc 0.6933 Epoch 178: Loss 0.0553, TrainAcc 1.0, ValAcc 0.6967 Epoch 179: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7000 Epoch 180: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6900 Epoch 181: Loss 0.0556, TrainAcc 1.0, ValAcc 0.7000 Epoch 182: Loss 0.0557, TrainAcc 1.0, ValAcc 0.7033 Epoch 183: Loss 0.0558, TrainAcc 1.0, ValAcc 0.6933 Epoch 184: Loss 0.0556, TrainAcc 1.0, ValAcc 0.6867 Epoch 185: Loss 0.0555, TrainAcc 1.0, ValAcc 0.7033 Epoch 186: Loss 0.0554, TrainAcc 1.0, ValAcc 0.7000 Epoch 187: Loss 0.0552, TrainAcc 1.0, ValAcc 0.6933 Epoch 188: Loss 0.0552, TrainAcc 1.0, ValAcc 0.6933 Epoch 189: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7000 Epoch 190: Loss 0.0554, TrainAcc 1.0, ValAcc 0.7000 Epoch 191: Loss 0.0554, TrainAcc 1.0, ValAcc 0.6933 Epoch 192: Loss 0.0555, TrainAcc 1.0, ValAcc 0.7000 Epoch 193: Loss 0.0555, TrainAcc 1.0, ValAcc 0.7000 Epoch 194: Loss 0.0555, TrainAcc 1.0, ValAcc 0.6933 Epoch 195: Loss 0.0554, TrainAcc 1.0, ValAcc 0.6933 Epoch 196: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7000 Epoch 197: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7033 Epoch 198: Loss 0.0553, TrainAcc 1.0, ValAcc 0.6933 Epoch 199: Loss 0.0553, TrainAcc 1.0, ValAcc 0.7033 测试准确率是:0.6480
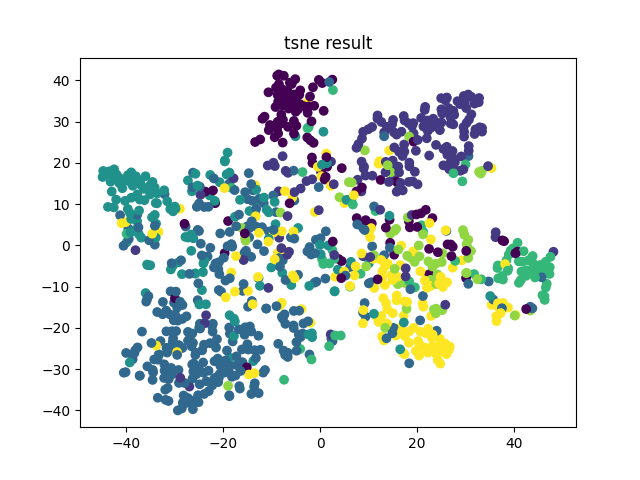
最后是进行tsne降维可视化:
from sklearn.manifold import TSNE test_accuracy, test_data, test_labels = test(tensor_test_mask) tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000) # TSNE降维,降到2 low_dim_embs = tsne.fit_transform(test_data) plt.title('tsne result') plt.scatter(low_dim_embs[:,0], low_dim_embs[:,1], marker='o', c=test_labels) plt.savefig("tsne.png")
参考:
https://blog.csdn.net/weixin_39373480/article/details/88742200
【深入浅出图神经网络】


