
transformer中的位置嵌入pytorch代码
class PositionalEncoding(nn.Module): "Implement the PE function." def __init__(self, d_model, dropout, max_len=5000): #d_model=512,dropout=0.1, #max_len=5000代表事先准备好长度为5000的序列的位置编码,其实没必要, #一般100或者200足够了。 super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # Compute the positional encodings once in log space. pe = torch.zeros(max_len, d_model) #(5000,512)矩阵,保持每个位置的位置编码,一共5000个位置, #每个位置用一个512维度向量来表示其位置编码 position = torch.arange(0, max_len).unsqueeze(1) # (5000) -> (5000,1) div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) # (0,2,…, 4998)一共准备2500个值,供sin, cos调用 pe[:, 0::2] = torch.sin(position * div_term) # 偶数下标的位置 pe[:, 1::2] = torch.cos(position * div_term) # 奇数下标的位置 pe = pe.unsqueeze(0) # (5000, 512) -> (1, 5000, 512) 为batch.size留出位置 self.register_buffer('pe', pe) def forward(self, x): x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) # 接受1.Embeddings的词嵌入结果x, #然后把自己的位置编码pe,封装成torch的Variable(不需要梯度),加上去。 #例如,假设x是(30,10,512)的一个tensor, #30是batch.size, 10是该batch的序列长度, 512是每个词的词嵌入向量; #则该行代码的第二项是(1, min(10, 5000), 512)=(1,10,512), #在具体相加的时候,会扩展(1,10,512)为(30,10,512), #保证一个batch中的30个序列,都使用(叠加)一样的位置编码。 return self.dropout(x) # 增加一次dropout操作 # 注意,位置编码不会更新,是写死的,所以这个class里面没有可训练的参数。
注意,位置编码不会更新,是写死的,所以这个class里面没有可训练的参数。
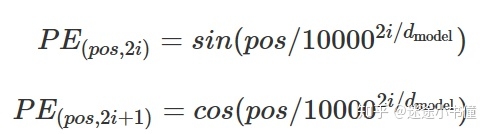
为了计算这个公式,上面的代码写的比较风骚,以2i为偶数为例子:

将字编码和位置嵌入联合使用:
nn.Sequential(Embeddings(d_model,src_vocab), PositionalEncoding(d_model,dropout)) # 例如,d_model=512, src_vocab=源语言的词表大小, #dropout=0.1即 dropout rate
摘自:https://zhuanlan.zhihu.com/p/107889011
补充另外一种实现:
import torch import torch.nn as nn import numpy as np class PositionalEncoding(nn.Module): def __init__(self, d_model, max_seq_len): """初始化。 Args: d_model: 一个标量。模型的维度,论文默认是512 max_seq_len: 一个标量。文本序列的最大长度 """ super(PositionalEncoding, self).__init__() # 根据论文给的公式,构造出PE矩阵 position_encoding = np.array([ [pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)] for pos in range(max_seq_len)]) # 偶数列使用sin,奇数列使用cos position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2]) position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2]) position_encoding = torch.from_numpy(position_encoding) # 在PE矩阵的第一行,加上一行全是0的向量,代表这`PAD`的positional encoding # 在word embedding中也经常会加上`UNK`,代表位置单词的word embedding,两者十分类似 # 那么为什么需要这个额外的PAD的编码呢?很简单,因为文本序列的长度不一,我们需要对齐, # 短的序列我们使用0在结尾补全,我们也需要这些补全位置的编码,也就是`PAD`对应的位置编码 pad_row = torch.zeros([1, d_model]) position_encoding = torch.cat((pad_row, position_encoding)) print(position_encoding) # 嵌入操作,+1是因为增加了`PAD`这个补全位置的编码, # Word embedding中如果词典增加`UNK`,我们也需要+1。看吧,两者十分相似 self.position_encoding = nn.Embedding(max_seq_len + 1, d_model) self.position_encoding.weight = nn.Parameter(position_encoding,requires_grad=False) def forward(self, input_len): """神经网络的前向传播。 Args: input_len: 一个张量,形状为[BATCH_SIZE, 1]。每一个张量的值代表这一批文本序列中对应的长度。 Returns: 返回这一批序列的位置编码,进行了对齐。 """ # 找出这一批序列的最大长度 max_len = torch.max(input_len) tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor # 对每一个序列的位置进行对齐,在原序列位置的后面补上0 # 这里range从1开始也是因为要避开PAD(0)的位置 input_pos = tensor( [list(range(1, len + 1)) + [0] * (max_len - len) for len in input_len]) return self.position_encoding(input_pos) pe = PositionalEncoding(10, 5) input_lens = torch.tensor([[4],[3],[2]], dtype=torch.long) pe(input_lens)

