
transformer笔记
基础结构:
输入:[batch_size,sequence_length,embedding dimension]
batch_size:句子的个数
sequence_length:句子的长度
embedding dimension:
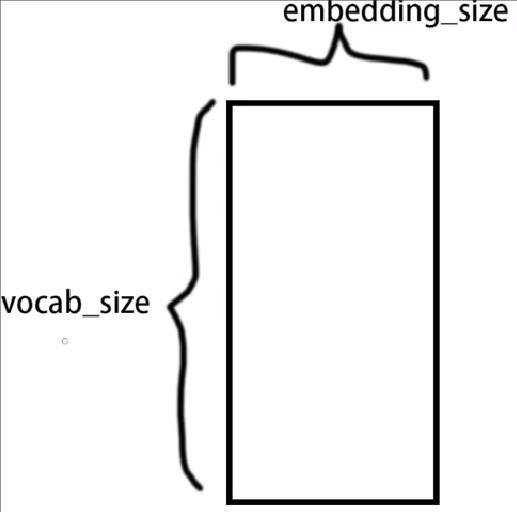
vocab_size:总字数
embedding_size:字向量维度的大小
什么是位置嵌入?
位置嵌入提供了每个字的位置信息。位置嵌入的维度是:
[max sequence_length,embedding dimension]
max sequence_length:超参数,限定句子的最大长度
初始化字向量:[vocab_size,embedding dimension]

其中pos是指句中字的位置,取值范围是[0,max sequense length] ,i是指字向量的维度,取值范围是[0,embedding dimension],d_model是指字向量维度大小。
什么是自注意力机制?
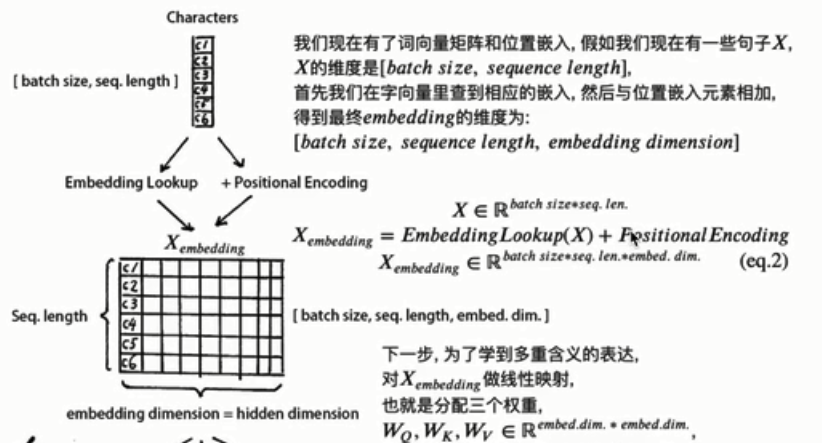
也就是初始输入:[batchsize,sequence length]
位置信息:[batchsize,sequence length,embedding dimension]
初始输入+位置信息(利用了广播机制?)
然后使用Q,K,V进行线性变换。
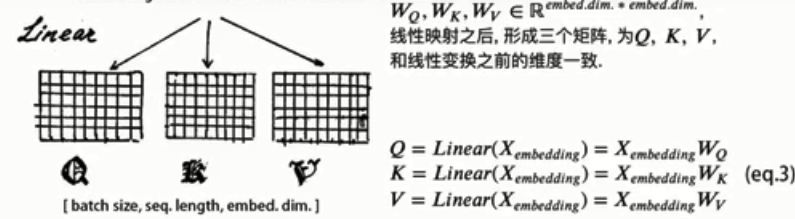
多头自注意力?
放缩点积注意力:
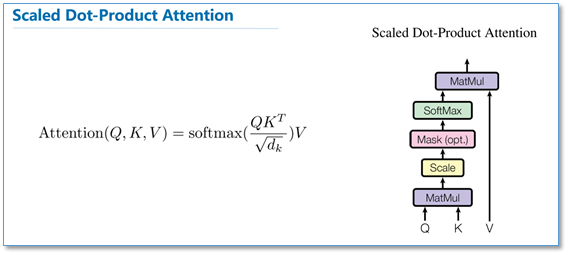
Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。

什么是attention mask?
超出当前句长的句子需要padding到最大句长。一般情况下使用的是0填充 ,但是在进行softmax时,e0=1。为了让无效的区域不参与计算,需要做一个mask让这些区域无效,一般会对无效的区域加一个很大的负数的偏置:

其他的操作?
(1)残差连接

(2)Layer Norm。

阿尔法和贝尔塔用来弥补归一化过程中损失掉的信息。
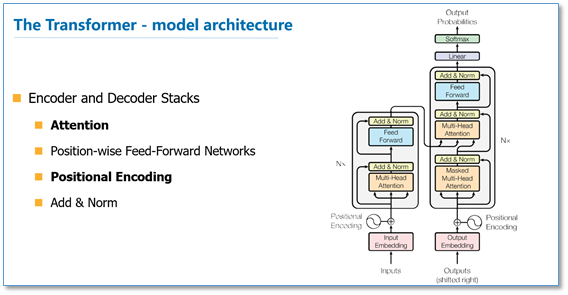
整体结构?


参考:
https://www.bilibili.com/video/BV1sE411Y7cP?from=search&seid=360256464200193261
https://blog.csdn.net/NeilGY/article/details/88721545


