
python实现adaboost
什么是adaboost?
Boosting,也称为增强学习或提升法,是一种重要的集成学习技术,能够将预测精度仅比随机猜度略高的弱学习器增强为预测精度高的强学习器,这在直接构造强学习器非常困难的情况下,为学习算法的设计提供了一种有效的新思路和新方法。作为一种元算法框架,Boosting几乎可以应用于所有目前流行的机器学习算法以进一步加强原算法的预测精度,应用十分广泛,产生了极大的影响。而AdaBoost正是其中最成功的代表,被评为数据挖掘十大算法之一。在AdaBoost提出至今的十几年间,机器学习领域的诸多知名学者不断投入到算法相关理论的研究中去,扎实的理论为AdaBoost算法的成功应用打下了坚实的基础。AdaBoost的成功不仅仅在于它是一种有效的学习算法,还在于
1)它让Boosting从最初的猜想变成一种真正具有实用价值的算法;
2)算法采用的一些技巧,如:打破原有样本分布,也为其他统计学习算法的设计带来了重要的启示;
3)相关理论研究成果极大地促进了集成学习的发展;
算法描述?



算法流程?
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。整个过程如下所示:
1. 先通过对N个训练样本的学习得到第一个弱分类器;
2. 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器 ;
3. 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4. 最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。
由Adaboost算法的描述过程可知,该算法在实现过程中根据训练集的大小初始化样本权值,使其满足均匀分布,在后续操作中通过公式来改变和规范化算法迭代后样本的权值。样本被错误分类导致权值增大,反之权值相应减小,这表示被错分的训练样本集包括一个更高的权重。这就会使在下轮时训练样本集更注重于难以识别的样本,针对被错分样本的进一步学习来得到下一个弱分类器,直到样本被正确分类[36]。在达到规定的迭代次数或者预期的误差率时,则强分类器构建完成。
具体例子:

有十个样本,初始化的权重1/10=0.1。然后选取一个阈值,当x<2.5是分为1,x>2.5时分为-1,此时错误分类的有编号为7,8,9的三个,错误率为3/10=0.3。

然后计算第一个弱分类器的系数。 再更新每一个样本的权重。



以上解释摘自:百度百科、统计学习方法
下面是代码实现: 代码来源: https://github.com/eriklindernoren/ML-From-Scratch
from __future__ import division, print_function import numpy as np import math from sklearn import datasets import matplotlib.pyplot as plt import pandas as pd # Import helper functions from mlfromscratch.utils import train_test_split, accuracy_score, Plot # Decision stump used as weak classifier in this impl. of Adaboost class DecisionStump(): def __init__(self): # Determines if sample shall be classified as -1 or 1 given threshold self.polarity = 1 # The index of the feature used to make classification self.feature_index = None # The threshold value that the feature should be measured against self.threshold = None # Value indicative of the classifier's accuracy self.alpha = None class Adaboost(): """Boosting method that uses a number of weak classifiers in ensemble to make a strong classifier. This implementation uses decision stumps, which is a one level Decision Tree. Parameters: ----------- n_clf: int The number of weak classifiers that will be used. """ def __init__(self, n_clf=5): self.n_clf = n_clf def fit(self, X, y): n_samples, n_features = np.shape(X) # Initialize weights to 1/N w = np.full(n_samples, (1 / n_samples)) self.clfs = [] # Iterate through classifiers for _ in range(self.n_clf): clf = DecisionStump() # Minimum error given for using a certain feature value threshold # for predicting sample label min_error = float('inf') # Iterate throught every unique feature value and see what value # makes the best threshold for predicting y for feature_i in range(n_features): feature_values = np.expand_dims(X[:, feature_i], axis=1) unique_values = np.unique(feature_values) # Try every unique feature value as threshold for threshold in unique_values: p = 1 # Set all predictions to '1' initially prediction = np.ones(np.shape(y)) # Label the samples whose values are below threshold as '-1' prediction[X[:, feature_i] < threshold] = -1 # Error = sum of weights of misclassified samples error = sum(w[y != prediction]) # If the error is over 50% we flip the polarity so that samples that # were classified as 0 are classified as 1, and vice versa # E.g error = 0.8 => (1 - error) = 0.2 if error > 0.5: error = 1 - error p = -1 # If this threshold resulted in the smallest error we save the # configuration if error < min_error: clf.polarity = p clf.threshold = threshold clf.feature_index = feature_i min_error = error # Calculate the alpha which is used to update the sample weights, # Alpha is also an approximation of this classifier's proficiency clf.alpha = 0.5 * math.log((1.0 - min_error) / (min_error + 1e-10)) # Set all predictions to '1' initially predictions = np.ones(np.shape(y)) # The indexes where the sample values are below threshold negative_idx = (clf.polarity * X[:, clf.feature_index] < clf.polarity * clf.threshold) # Label those as '-1' predictions[negative_idx] = -1 # Calculate new weights # Missclassified samples gets larger weights and correctly classified samples smaller w *= np.exp(-clf.alpha * y * predictions) # Normalize to one w /= np.sum(w) # Save classifier self.clfs.append(clf) def predict(self, X): n_samples = np.shape(X)[0] y_pred = np.zeros((n_samples, 1)) # For each classifier => label the samples for clf in self.clfs: # Set all predictions to '1' initially predictions = np.ones(np.shape(y_pred)) # The indexes where the sample values are below threshold negative_idx = (clf.polarity * X[:, clf.feature_index] < clf.polarity * clf.threshold) # Label those as '-1' predictions[negative_idx] = -1 # Add predictions weighted by the classifiers alpha # (alpha indicative of classifier's proficiency) y_pred += clf.alpha * predictions # Return sign of prediction sum y_pred = np.sign(y_pred).flatten() return y_pred def main(): data = datasets.load_digits() X = data.data y = data.target digit1 = 1 digit2 = 8 idx = np.append(np.where(y == digit1)[0], np.where(y == digit2)[0]) y = data.target[idx] # Change labels to {-1, 1} y[y == digit1] = -1 y[y == digit2] = 1 X = data.data[idx] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5) # Adaboost classification with 5 weak classifiers clf = Adaboost(n_clf=5) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print ("Accuracy:", accuracy) # Reduce dimensions to 2d using pca and plot the results Plot().plot_in_2d(X_test, y_pred, title="Adaboost", accuracy=accuracy) if __name__ == "__main__": main()
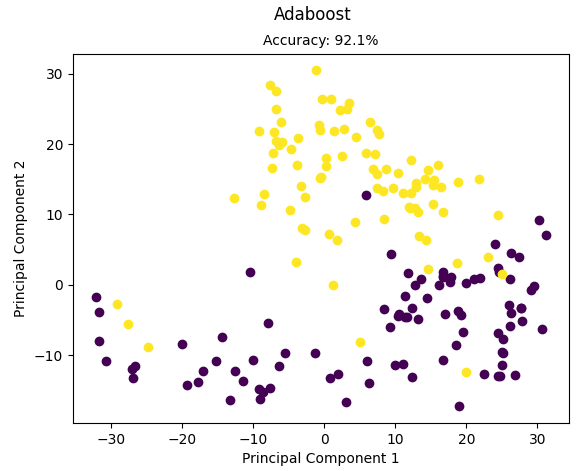
运行结果:
Accuracy: 0.9213483146067416

 浙公网安备 33010602011771号
浙公网安备 33010602011771号