python实现随机森林
什么是随机森林?
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。要想理解好随机森林,就首先要了解决策树。
可以参考:
https://www.cnblogs.com/xiximayou/p/12882367.html
随机森林的工作原理?
1. 从数据集(表)中随机选择k个特征(列),共m个特征(其中k小于等于m)。然后根据这k个特征建立决策树。
2. 重复n次,这k个特性经过不同随机组合建立起来n棵决策树(或者是数据的不同随机样本,称为自助法样本)。
3. 对每个决策树都传递随机变量来预测结果。存储所有预测的结果(目标),你就可以从n棵决策树中得到n种结果。
4. 计算每个预测目标的得票数再选择模式(最常见的目标变量)。换句话说,将得到高票数的预测目标作为随机森林算法的最终预测。
针对回归问题,随机森林中的决策树会预测Y的值(输出值)。通过随机森林中所有决策树预测值的平均值计算得出最终预测值。而针对分类问题,随机森林中的每棵决策树会预测最新数据属于哪个分类。最终,哪一分类被选择最多,就预测这个最新数据属于哪一分类。
随机森林的优点和缺点?
优点:
1. 可以用来解决分类和回归问题:随机森林可以同时处理分类和数值特征。
2. 抗过拟合能力:通过平均决策树,降低过拟合的风险性。
3. 只有在半数以上的基分类器出现差错时才会做出错误的预测:随机森林非常稳定,即使数据集中出现了一个新的数据点,整个算法也不会受到过多影响,它只会影响到一颗决策树,很难对所有决策树产生影响。
缺点:
1. 据观测,如果一些分类/回归问题的训练数据中存在噪音,随机森林中的数据集会出现过拟合的现象。
2. 比决策树算法更复杂,计算成本更高。
3. 由于其本身的复杂性,它们比其他类似的算法需要更多的时间来训练。
如何理解随机森林的“随机”?
主要体现在两个方面:
1.数据的随机选取:从原始数据中采取有放回的抽样。
2.特征的随机选取:每次随机选取k个特征构造一棵树。
参考:
百度百科
https://baijiahao.baidu.com/s?id=1632582851666395020&wfr=spider&for=pc
下面是代码实现,代码来源: https://github.com/eriklindernoren/ML-From-Scratch
from __future__ import division, print_function import numpy as np import math import progressbar # Import helper functions from mlfromscratch.utils import divide_on_feature, train_test_split, get_random_subsets, normalize from mlfromscratch.utils import accuracy_score, calculate_entropy from mlfromscratch.unsupervised_learning import PCA from mlfromscratch.supervised_learning import ClassificationTree from mlfromscratch.utils.misc import bar_widgets from mlfromscratch.utils import Plot class RandomForest(): """Random Forest classifier. Uses a collection of classification trees that trains on random subsets of the data using a random subsets of the features. Parameters: ----------- n_estimators: int The number of classification trees that are used. max_features: int The maximum number of features that the classification trees are allowed to use. min_samples_split: int The minimum number of samples needed to make a split when building a tree. min_gain: float The minimum impurity required to split the tree further. max_depth: int The maximum depth of a tree. """ def __init__(self, n_estimators=100, max_features=None, min_samples_split=2, min_gain=0, max_depth=float("inf")): self.n_estimators = n_estimators # Number of trees self.max_features = max_features # Maxmimum number of features per tree self.min_samples_split = min_samples_split self.min_gain = min_gain # Minimum information gain req. to continue self.max_depth = max_depth # Maximum depth for tree self.progressbar = progressbar.ProgressBar(widgets=bar_widgets) # Initialize decision trees self.trees = [] for _ in range(n_estimators): self.trees.append( ClassificationTree( min_samples_split=self.min_samples_split, min_impurity=min_gain, max_depth=self.max_depth)) def fit(self, X, y): n_features = np.shape(X)[1] # If max_features have not been defined => select it as # sqrt(n_features) if not self.max_features: self.max_features = int(math.sqrt(n_features)) # Choose one random subset of the data for each tree subsets = get_random_subsets(X, y, self.n_estimators) for i in self.progressbar(range(self.n_estimators)): X_subset, y_subset = subsets[i] # Feature bagging (select random subsets of the features) idx = np.random.choice(range(n_features), size=self.max_features, replace=True) # Save the indices of the features for prediction self.trees[i].feature_indices = idx # Choose the features corresponding to the indices X_subset = X_subset[:, idx] # Fit the tree to the data self.trees[i].fit(X_subset, y_subset) def predict(self, X): y_preds = np.empty((X.shape[0], len(self.trees))) # Let each tree make a prediction on the data for i, tree in enumerate(self.trees): # Indices of the features that the tree has trained on idx = tree.feature_indices # Make a prediction based on those features prediction = tree.predict(X[:, idx]) y_preds[:, i] = prediction y_pred = [] # For each sample for sample_predictions in y_preds: # Select the most common class prediction y_pred.append(np.bincount(sample_predictions.astype('int')).argmax()) return y_pred
主运行函数:
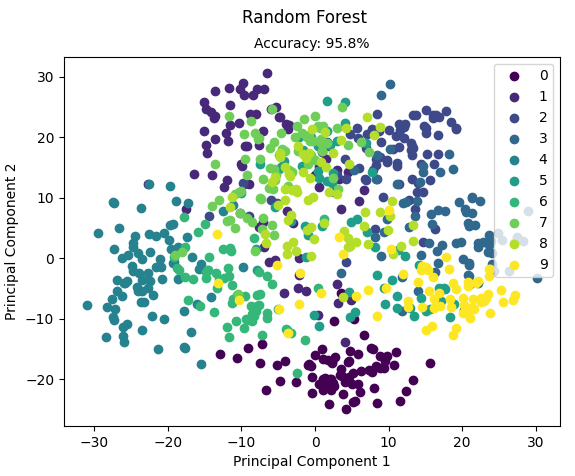
from __future__ import division, print_function import numpy as np import sys sys.path.append("/content/drive/My Drive/learn/ML-From-Scratch/") from sklearn import datasets from mlfromscratch.utils import train_test_split, accuracy_score, Plot from mlfromscratch.supervised_learning import RandomForest def main(): data = datasets.load_digits() X = data.data y = data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, seed=2) clf = RandomForest(n_estimators=100) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print ("Accuracy:", accuracy) Plot().plot_in_2d(X_test, y_pred, title="Random Forest", accuracy=accuracy, legend_labels=data.target_names) if __name__ == "__main__": main()
运行结果:
Training: 100% [------------------------------------------------] Time: 0:02:11
Accuracy: 0.958217270194986