
python实现kNN(最近邻)
什么是最近邻?
最近邻可以用于分类和回归,这里以分类为例。给定一个训练集,对新输入的实例,在训练数据集中找到与该实例最接近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类
最近邻模型的三个基本要素?
距离度量、K值的选择和分类决策规则。
距离度量:一般是欧式距离,也可以是Lp距离和曼哈顿距离。
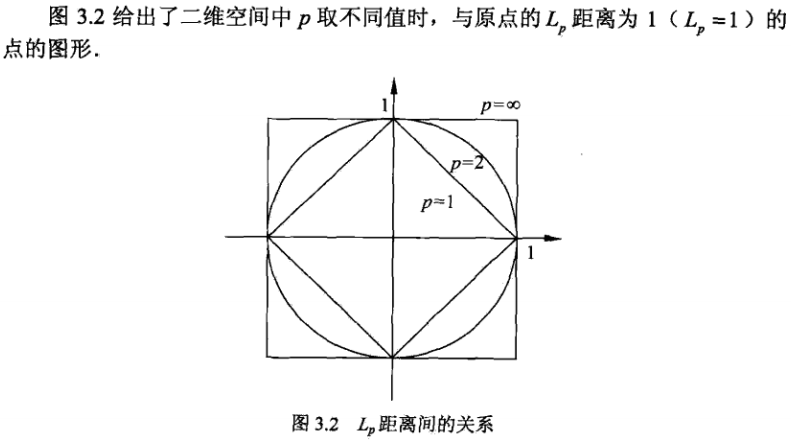
下面是一个具体的例子:

k值怎么选择?

接下来是代码实现:

from __future__ import print_function, division import numpy as np from mlfromscratch.utils import euclidean_distance class KNN(): """ K Nearest Neighbors classifier. Parameters: ----------- k: int The number of closest neighbors that will determine the class of the sample that we wish to predict. """ def __init__(self, k=5): self.k = k def _vote(self, neighbor_labels): """ Return the most common class among the neighbor samples """ counts = np.bincount(neighbor_labels.astype('int')) return counts.argmax() def predict(self, X_test, X_train, y_train): y_pred = np.empty(X_test.shape[0]) # Determine the class of each sample for i, test_sample in enumerate(X_test): # Sort the training samples by their distance to the test sample and get the K nearest idx = np.argsort([euclidean_distance(test_sample, x) for x in X_train])[:self.k] # Extract the labels of the K nearest neighboring training samples k_nearest_neighbors = np.array([y_train[i] for i in idx]) # Label sample as the most common class label y_pred[i] = self._vote(k_nearest_neighbors) return y_pred
其中一些numpy中的函数用法:
numpy.bincount()

numpy.argmax():

numpy.argsort():返回排序后数组的索引

接着是其中使用到了euclidean_distance():
def euclidean_distance(x1, x2): """ Calculates the l2 distance between two vectors """ distance = 0 # Squared distance between each coordinate for i in range(len(x1)): distance += pow((x1[i] - x2[i]), 2) return math.sqrt(distance)
这里使用的是l2距离。
运行的主函数:
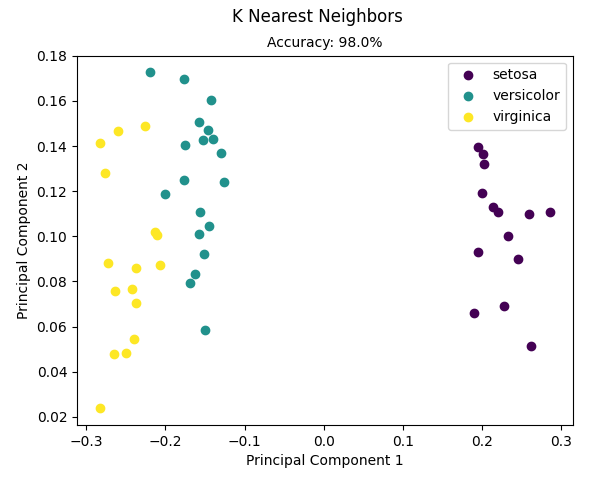
from __future__ import print_function import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from mlfromscratch.utils import train_test_split, normalize, accuracy_score from mlfromscratch.utils import euclidean_distance, Plot from mlfromscratch.supervised_learning import KNN def main(): data = datasets.load_iris() X = normalize(data.data) y = data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) clf = KNN(k=5) y_pred = clf.predict(X_test, X_train, y_train) accuracy = accuracy_score(y_test, y_pred) print ("Accuracy:", accuracy) # Reduce dimensions to 2d using pca and plot the results Plot().plot_in_2d(X_test, y_pred, title="K Nearest Neighbors", accuracy=accuracy, legend_labels=data.target_names) if __name__ == "__main__": main()
结果:
Accuracy: 0.9795918367346939
理论知识:来自统计学习方法




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析