
【猫狗数据集】利用tensorboard可视化训练和测试过程
数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
进行训练:https://www.cnblogs.com/xiximayou/p/12448300.html
保存模型并继续进行训练:https://www.cnblogs.com/xiximayou/p/12452624.html
加载保存的模型并测试:https://www.cnblogs.com/xiximayou/p/12459499.html
划分验证集并边训练边验证:https://www.cnblogs.com/xiximayou/p/12464738.html
使用学习率衰减策略并边训练边测试:https://www.cnblogs.com/xiximayou/p/12468010.html
epoch、batchsize、step之间的关系:https://www.cnblogs.com/xiximayou/p/12405485.html
我们已经能够使用学习率衰减策略了,同时也可以训练、验证、测试了。那么,我们可能想要了解训练过程中的损失和准确率的可视化结果。我们可以使用tensorboard来进行可视化。可参考:
利用tensorboard可视化:https://www.cnblogs.com/xiximayou/p/12470678.html
利用tensorboardcolab可视化:https://www.cnblogs.com/xiximayou/p/12470715.html
在此之前,我们还要优化一下我们的训练测试代码。一般情况下,我们只需要关注每一个epoch的结果就行了,可以将输入每一个step的那段代码注释掉,但是,这也存在一个问题。每次只打印出epoch的结果,有可能一个epoch要执行的时间很长,注释掉step之后没有反馈给到我们。那应该怎么办?使用python库tqdm。它会以进度条的形式告诉我们一个epoch还有多久完成,以及完成所需的时间。
接下来,我们结合代码来一起看看改变之后的结果:
main.py
import sys sys.path.append("/content/drive/My Drive/colab notebooks") from utils import rdata from model import resnet import torch.nn as nn import torch import numpy as np import torchvision import train import torch.optim as optim np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') batch_size=128 train_loader,val_loader,test_loader=rdata.load_dataset(batch_size) model =torchvision.models.resnet18(pretrained=False) model.fc = nn.Linear(model.fc.in_features,2,bias=False) model.cuda() #定义训练的epochs num_epochs=100 #定义学习率 learning_rate=0.1 #定义损失函数 criterion=nn.CrossEntropyLoss() #定义优化方法,简单起见,就是用带动量的随机梯度下降 optimizer = torch.optim.SGD(params=model.parameters(), lr=0.1, momentum=0.9, weight_decay=1*1e-4) scheduler = optim.lr_scheduler.MultiStepLR(optimizer, [40,80], 0.1) print("训练集有:",len(train_loader.dataset)) #print("验证集有:",len(val_loader.dataset)) print("测试集有:",len(test_loader.dataset)) def main(): trainer=train.Trainer(criterion,optimizer,model) trainer.loop(num_epochs,train_loader,val_loader,test_loader,scheduler) main()
这里面没有什么变化。主要是train.py
import torch from tqdm import tqdm from tensorflow import summary import datetime current_time = str(datetime.datetime.now().timestamp()) train_log_dir = '/content/drive/My Drive/colab notebooks/output/tsboardx/train/' + current_time test_log_dir = '/content/drive/My Drive/colab notebooks/output/tsboardx/test/' + current_time val_log_dir = '/content/drive/My Drive/colab notebooks/output/tsboardx/val/' + current_time train_summary_writer = summary.create_file_writer(train_log_dir) val_summary_writer = summary.create_file_writer(val_log_dir) test_summary_writer = summary.create_file_writer(test_log_dir) class Trainer: def __init__(self,criterion,optimizer,model): self.criterion=criterion self.optimizer=optimizer self.model=model def get_lr(self): for param_group in self.optimizer.param_groups: return param_group['lr'] def loop(self,num_epochs,train_loader,val_loader,test_loader,scheduler=None,acc1=0.0): self.acc1=acc1 for epoch in range(1,num_epochs+1): lr=self.get_lr() print("epoch:{},lr:{:.6f}".format(epoch,lr)) self.train(train_loader,epoch,num_epochs) #self.val(val_loader,epoch,num_epochs) self.test(test_loader,epoch,num_epochs) if scheduler is not None: scheduler.step() def train(self,dataloader,epoch,num_epochs): self.model.train() with torch.enable_grad(): self._iteration_train(dataloader,epoch,num_epochs) def val(self,dataloader,epoch,num_epochs): self.model.eval() with torch.no_grad(): self._iteration_val(dataloader,epoch,num_epochs) def test(self,dataloader,epoch,num_epochs): self.model.eval() with torch.no_grad(): self._iteration_test(dataloader,epoch,num_epochs) def _iteration_train(self,dataloader,epoch,num_epochs): total_step=len(dataloader) tot_loss = 0.0 correct = 0 #for i ,(images, labels) in enumerate(dataloader): for images, labels in tqdm(dataloader,ncols=80): images = images.cuda() labels = labels.cuda() # Forward pass outputs = self.model(images) _, preds = torch.max(outputs.data,1) loss = self.criterion(outputs, labels) # Backward and optimizer self.optimizer.zero_grad() loss.backward() self.optimizer.step() tot_loss += loss.data """ if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(epoch, num_epochs, i+1, total_step, loss.item())) """ correct += torch.sum(preds == labels.data).to(torch.float32) ### Epoch info #### epoch_loss = tot_loss/len(dataloader.dataset) epoch_acc = correct/len(dataloader.dataset) print('train loss: {:.4f},train acc: {:.4f}'.format(epoch_loss,epoch_acc)) with train_summary_writer.as_default(): summary.scalar('loss', epoch_loss.item(), epoch) summary.scalar('accuracy', epoch_acc.item(), epoch) if epoch==num_epochs: state = { 'model': self.model.state_dict(), 'optimizer':self.optimizer.state_dict(), 'epoch': epoch, 'train_loss':epoch_loss, 'train_acc':epoch_acc, } save_path="/content/drive/My Drive/colab notebooks/output/" torch.save(state,save_path+"/resnet18_final"+".t7") def _iteration_val(self,dataloader,epoch,num_epochs): total_step=len(dataloader) tot_loss = 0.0 correct = 0 #for i ,(images, labels) in enumerate(dataloader): for images, labels in tqdm(dataloader,ncols=80): images = images.cuda() labels = labels.cuda() # Forward pass outputs = self.model(images) _, preds = torch.max(outputs.data,1) loss = self.criterion(outputs, labels) tot_loss += loss.data correct += torch.sum(preds == labels.data).to(torch.float32) """ if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(1, 1, i+1, total_step, loss.item())) """ ### Epoch info #### epoch_loss = tot_loss/len(dataloader.dataset) epoch_acc = correct/len(dataloader.dataset) print('val loss: {:.4f},val acc: {:.4f}'.format(epoch_loss,epoch_acc)) with val_summary_writer.as_default(): summary.scalar('loss', epoch_loss.item(), epoch) summary.scalar('accuracy', epoch_acc.item(), epoch) def _iteration_test(self,dataloader,epoch,num_epochs): total_step=len(dataloader) tot_loss = 0.0 correct = 0 #for i ,(images, labels) in enumerate(dataloader): for images, labels in tqdm(dataloader,ncols=80): images = images.cuda() labels = labels.cuda() # Forward pass outputs = self.model(images) _, preds = torch.max(outputs.data,1) loss = self.criterion(outputs, labels) tot_loss += loss.data correct += torch.sum(preds == labels.data).to(torch.float32) """ if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(1, 1, i+1, total_step, loss.item())) """ ### Epoch info #### epoch_loss = tot_loss/len(dataloader.dataset) epoch_acc = correct/len(dataloader.dataset) print('test loss: {:.4f},test acc: {:.4f}'.format(epoch_loss,epoch_acc)) with test_summary_writer.as_default(): summary.scalar('loss', epoch_loss.item(), epoch) summary.scalar('accuracy', epoch_acc.item(), epoch) if epoch_acc > self.acc1: state = { "model": self.model.state_dict(), "optimizer": self.optimizer.state_dict(), "epoch": epoch, "epoch_loss": epoch_loss, "epoch_acc": epoch_acc, "acc1": self.acc1, } save_path="/content/drive/My Drive/colab notebooks/output/" print("在第{}个epoch取得最好的测试准确率,准确率为:{:.4f}".format(epoch,epoch_acc)) torch.save(state,save_path+"/resnet18_best"+".t7") self.acc1=max(self.acc1,epoch_acc)
首先关注summary.create_file_writer,这个函数的参数是需要存储可视化文件的地址,我们这里有train、val、test。然后是
with test_summary_writer.as_default(): summary.scalar('loss', epoch_loss.item(), epoch) summary.scalar('accuracy', epoch_acc.item(), epoch)
这之类的。我们把想要可视化的损失和准确率随epoch的变化情况传入到summary.scalar中。summary.scalar接受三个参数,第一个是图的名称,第二个是纵坐标,第三个是横坐标。
之后在test.ipynb中,我们一步步进行操作:
首先进入到train目录下:
cd /content/drive/My Drive/colab notebooks/train
然后输入魔法命令:
%load_ext tensorboard.notebook
接着就可以启动tensorboard了:
%tensorboard --logdir "/content/drive/My Drive/colab notebooks/output/tsboardx/"
启动之后会在该代码块下显示tensorboard的界面。还没有开始训练,所以暂时是看不到变化的。
接下来我们就可以开始训练了:
!python main.py
这里的结果就只截部分了。我们设定了训练100个epoch,batchsize设定为128。这里需要说明的是使用大的batchsize的同时要将学习率也设置大些,我们设置初始的学习率为0.1。并在第40个和第80个epoch进行学习率衰减,每次变为原来的0.1呗。也要切记并不是batchsize越大越好,虽然大的batchsize可以加速网络的训练,但是会造成内存不足和模型的泛化能力不好。



可以发现我们显示的界面还是比较美观的。
最后截图的是测试准确率最高的那个epoch的结果:

在查看tensorboard之前,我们看下存储内容的位置。
就是根据标红的文件中的内容进行可视化的。
最后去看一下tensorboard:
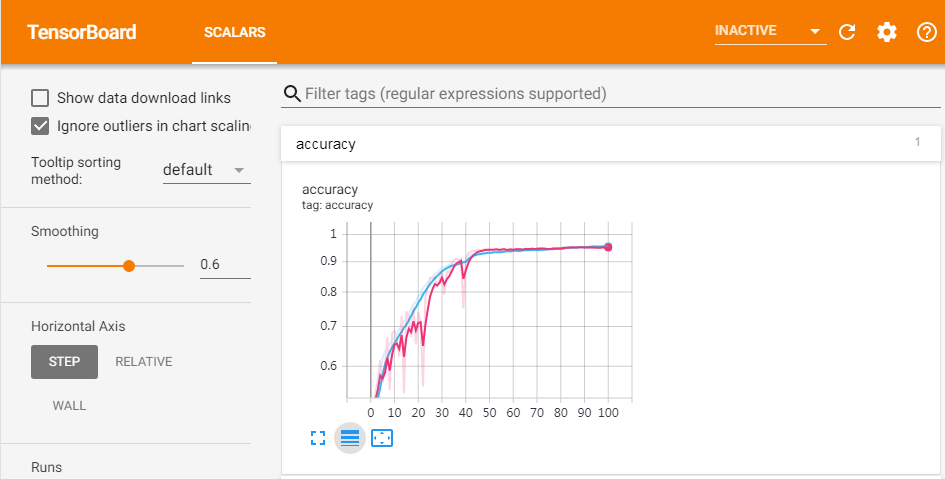

红线代表测试,蓝线代表训练。
至此,网络的训练、测试以及可视化就完成了,接下来是看看整体的目录结构:

下一节,通过在命令行指定所需的参数,比如batchsize等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号