
【猫狗数据集】定义模型并进行训练模型
2020.3.10
发现数据集没有完整的上传到谷歌的colab上去,我说怎么计算出来的step不对劲。
测试集是完整的。
训练集中cat的确是有10125张图片,而dog只有1973张,所以完成一个epoch需要迭代的次数为:
(10125+1973)/128=94.515625,约等于95。
顺便提一下,有两种方式可以计算出数据集的量:
第一种:print(len(train_dataset))
第二种:在../dog目录下,输入ls | wc -c
今天重新上传dog数据集。
分割线-----------------------------------------------------------------
数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
之前准备好了数据集:
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
这节我们要定义模型然后开始进行训练啦。
首先还是在谷歌colab中的目录如下:
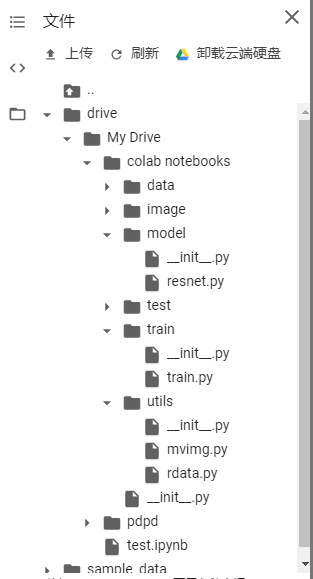
其中rdata是我们读取数据的文件,将其进行改造一下:
from torch.utils.data import DataLoader import torchvision import torchvision.transforms as transforms import torch def load_dataset(batch_size): #预处理 transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.ToTensor()]) path = "/content/drive/My Drive/colab notebooks/data/dogcat" train_path=path+"/train" test_path=path+"/test" #使用torchvision.datasets.ImageFolder读取数据集指定train和test文件夹 train_data = torchvision.datasets.ImageFolder(train_path, transform=transform) train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=1) test_data = torchvision.datasets.ImageFolder(test_path, transform=transform) test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=1) """ print(train_data.classes) #根据分的文件夹的名字来确定的类别 print(train_data.class_to_idx) #按顺序为这些类别定义索引为0,1... print(train_data.imgs) #返回从所有文件夹中得到的图片的路径以及其类别 print(test_data.classes) #根据分的文件夹的名字来确定的类别 print(test_data.class_to_idx) #按顺序为这些类别定义索引为0,1... print(test_data.imgs) #返回从所有文件夹中得到的图片的路径以及其类别 """ return train_loader,test_loader,train_data,test_data
进行数据增强时,我们暂时只选择两种,一是将图片随机切割成224×224大小,因为大多数网络的输入大小是这个,同时将其转换成tensor。这里需要注意的是:ToTensor()要在所有的数据增强之后,除了标准化。因为ToTensor()会将图像转换为pytorch的tensor类型,同时还会将每个像素转换为0-1之间的数值。
最终我们要返回的是train_loader,test_loader,train_data,test_data。
train_loader,test_loader:就不必多说了,用于加载数据集的
train_data,test_data:传过去这个是为了获取数据集的长度。
然后在train.py中就可以定义模型并进行训练了。
resnet.py中是存储的resnet的模型,这里是从pytorch中的torchvision中的resnet拷贝过来的,当然我们也可以直接使用torchvision中的模型,里面封装了很多模型。
模型结构:
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=2, bias=False) )
在train.py中,我们一步步来解析:
import sys #为了避免找不到相应目录下的文件,将该目录加入到path中 sys.path.append("/content/drive/My Drive/colab notebooks") from utils import rdata from model import resnet import torch.nn as nn import torch import numpy as np import torchvision #设置随机种子 np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) #torch.backends.cudnn.deterministic一般设置成True即可 #如果网络的结构不是经常变换的,也就是固定的,将 #torch.backends.cudnn.benchmark设置True torch.backends.cudnn.deterministic = True #torch.backends.cudnn.benchmark = False torch.backends.cudnn.benchmark = True #将模型和数据放入到gpu中有两种方式,一种是model.to(device),另一种是model.cuda() device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #就是每次输入到网络中图像的个数 batch_size=128 #读取数据 train_loader,test_loader,train_data,test_data=rdata.load_dataset(batch_size) #为了方便起见,我们直接从torchvision中获得模型,但是该模型默认是imagenet数据集,类别有1000类,我们通过以下方式获取非预训练的模型,并修改最后全连接层为2类 model =torchvision.models.resnet18(pretrained=False) model.fc = nn.Linear(model.fc.in_features,2,bias=False) model.cuda() #print(model) #定义训练的epochs num_epochs=50 #定义学习率 learning_rate=0.01 #定义损失函数 criterion=nn.CrossEntropyLoss() #optimizer #=torch.optim.Adam(model.parameters(),lr=learning_rate) #定义优化方法,简单起见,就是用带动量的随机梯度下降 optimizer = torch.optim.SGD(params=model.parameters(), lr=0.1, momentum=0.9, weight_decay=1*1e-4) # 计算step total_step = len(train_loader) #定义模型训练函数 def train(): #打印每一个epoch的输出 for epoch in range(num_epochs): #为了计算每个epoch的损失 tot_loss = 0.0 #计算每个epoch的正确的个数 correct = 0 #i是step,images是图片张量,lables是标签 for i ,(images, labels) in enumerate(train_loader): #将数据放入到GPU中 images = images.cuda() labels = labels.cuda() # Forward pass #图片张量送入网络计算输出 outputs = model(images) #取得概率大的那个结果 _, preds = torch.max(outputs.data,1) loss = criterion(outputs, labels) # Backward and optimizer #反向传播优化网络参数 optimizer.zero_grad() loss.backward() optimizer.step() #累加每个step的损失 tot_loss += loss.data #每隔2个step就打印当前损失 if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item())) #统计正确的个数 correct += torch.sum(preds == labels.data).to(torch.float32) ### Epoch info #### #epoch损失 epoch_loss = tot_loss/len(train_data) print('train loss: ', epoch_loss) #epoch准确率 epoch_acc = correct/len(train_data) print('train' + ' acc: ', epoch_acc) train()
关于step、epoch、batch_size之间的关系可以看:
https://www.cnblogs.com/xiximayou/p/12405485.html
最后,我们在test.ipynb中输入命令进行训练,不过先要进入到train目录下:

然后到第一个epoch完成:
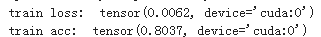
再到最后一个epoch完成:

有93%的准确率了。这还仅仅是简单的训练。
发现train loss和train acc中输出不太好,这样处理一下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号