
1.缓存的受益与成本
(1)受益
加速读写:通过缓存加速读写速度:CPU L1/L2/L3 Cache,Linux page Cache加速硬盘读写,浏览器换成,Ehcache缓存数据库结果
降低后端负载:侯丹服务器通过前端缓存降低负载:业务端使用Redis降低后端mysql负载等
(2)成本
数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关
代码维护成本:多了一层缓存逻辑
运维成本:例如Redis Cluster
(3)使用场景
降低后端负载:
-对高消耗的SQL:jojn结果集/分组统计结果缓存
加速请求响应
-利用Redis/Memcache优化IO响应时间
大量写合并为批量写:
如计数器先RDBedis累加批量写DB
2.缓存更新策略
(1)LRU/LFU/FIFO算法剔除:例如maxmemory-policy
一致性最差,维护成本底
(2)超时剔除:例如expire(设置过期时间)
一致性较差,维护成本底
(3)主动更新:开发控制生命周期
一致性强,维护成本高
(4)两条建议
低一致性:最大内存和淘汰策略
高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底
3.换成粒度控制三个角度
(1)通用性:全量属性更好
(2)占用空间;部分属性更好
(3)代码维护:表面上全量属性更好
4.缓存穿透-大量请求不命中
(1)产生原因:
业务代码自身问题
恶意攻击,爬虫等
(2)如何发现问题
业务的响应时间
业务本身问题
相关指标:总调用数,缓存层命中数,存储层命中数
(3)解决方式1-缓存空对象
如果在缓存层miss,在storage数据库层也是miss,正常是直接返回给客户端,解决方式直接把获取不到的结果缓存到缓存层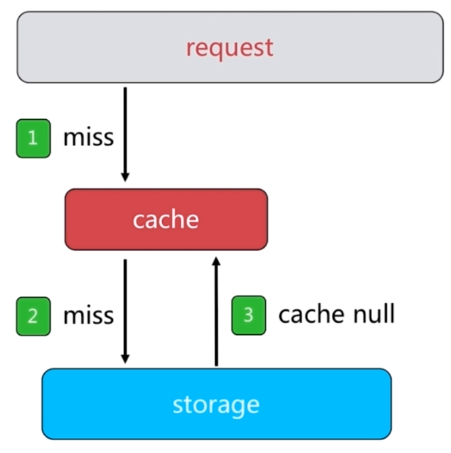
两个问题:
问题一:需要更多的键
问题二:缓存层和存储层数据“短期”不一致
(4)解决方式2-布隆过滤器拦截
5.无底洞问题
(1)关键点:
更多的机器!=更高的性能
批量接口需求(mget,mset等)
数据增长与水平扩展需求
(2)优化IO的几种方法
命令本身优化:例如慢查询keys,hgetall bigkey
减少网络通信次数
降低接入成本:例如客户端长连接/连接池,NIO等
(4)四种批量优化的方法
串行mget
串行IO
并行IO
hash_tag
6.热点key重建优化
(1)问题描述:热点key+大量的线程做重建时间
(2)三个目标
目标1:减少重缓存的次数
目标2:数据尽可能一致
目标3:减少潜在危险
(3)两个解决方式
第一:互斥锁(mutex key)
互斥锁流程:第一个获取缓存需要重建的线程如果发现了到了重建的时候,把重建查询数据库加上一把锁,当在这个时间段完成这个工作后,打开锁。当在这个过程中有其它线程获取缓存,发现重建的过程被锁住了,因为只有一个线程可以做这个事情,然后等在输出,只有发现锁解开的时候,就可以直接获取到缓存
优点:思路简单,保证一致性
缺点:代码复杂度增加,存在死锁的风险
第二:永远不过期
缓存层面:没有设置过期时间(没有用expire)
功能层面:为每个value添加逻辑过期时间,但发现超过逻辑过期时间后,会使用单独的线程去构建缓存
优点:基本杜绝热点key重建问题
缺点:不保证一致性,逻辑过期时间增加维成本和内存成本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号