Elasticsearch简单使用和环境搭建
Elasticsearch简单使用和环境搭建
1 Elasticsearch简介

Elasticsearch是一个可用于构建搜索应用的成品软件,它最早由Shay Bannon创建并于2010年2月发布。现在已经非常流行,成为商业解决方案之外一个开源的重要选择。
Elasticsearch是一个基于Lucene的搜索服务器,提供一个分布式多用户能力的全文搜索引擎,基于RESTful web借口,使用Java开发,在Apache许可条款下开发源代码发布。做到准实时搜索、稳定、可靠、安装使用方便。
Elasticsearch具有合理的默认配置,默认就是分布式工作模式,使用对等架构(P2P)避免单点故障(SPOF),易于横向扩展新的节点。此外由于没有对索引中的数据结构强行添加限制,从而允许用户调整现有数据模型。
2 Elasticsearch下载安装
官网下载页面中有ZIP、TAR、DEB、RPM几种格式的安装包提供下载。
step1 下载

下载并解压Elasticsearch的最新版本
step2 运行

在Uinx上运行命令: bin/elasticsearch,在Windows环境下运行命令:bin\elasticsearch.bat。
step3 访问

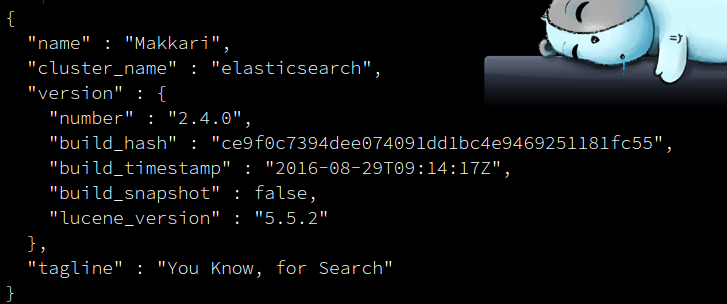
运行命令: curl -X GET http://localhost:9200/
结果:
3 插件的安装和使用
3.1 head插件
elasticsearch-head是elastic search集群的一个web前端。源代码托管在github.com,地址是:https://github.com/mobz/elasticsearch-head。这是一个学习elasticsearch的利器。
安装
有两种方式来使用head。一种方式是作为ealsticsearch的插件,另一种是将其作为一个独立的webapp来运行。这里将其作为elasticsearch插件来使用。
在线安装步骤:
- sudo elasticsearch/bin/plugin install mobz/elasticsearch-head
- 在浏览器中浏览,http://localhost:9200/_plugin/head/
离线安装步骤:
- wget https://github.com/mobz/elasticsearch-head/archive/master.zip
- elasticsearch/bin/plugin file:/path/elasticsearch-head-master.zip
- 在浏览器中浏览,http://localhost:9200/_plugin/head/

3.2 IK分词插件
这里使用的是elasticsearch-analysis-ik,这是一个将Lucence IK分词器集成到elasticsearch的ik分词器插件,并且支持自定义的词典。源代码托管在github.com上,地址是:https://github.com/medcl/elasticsearch-analysis-ik。
安装
- 1,在github上下载同elasticsearch匹配的版本
- 2,将下载zip包,在解压到elasticsearch/plugin/ik下
- 3,重启elasticsearch
3.2.1测试IK分词
IK分词安装后有三种分词策略:ik、ik_max_word和ik_smart。ik和ik_max_word分词效果相同,对输入文本根据词典穷尽各种分割方法是细力度分割策略。ik_smart会对输入文本根据词典以及歧义判断等方式进行一次最合理的粗粒度分割。可以在Terml中使用curl查看分词效果。
- 分词策略ik/ik_max_word
$ curl -G 'localhost:9200/_analyze?analyzer=ik&pretty=true' --data-urlencode "text=中华人民共和国国歌"
{
"tokens" : [ {
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}, {
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
}, {
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
}, {
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
}, {
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
}, {
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
}, {
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
}, {
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}, {
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 9
} ]
}
- 分词策略ik_smart
$ curl -G 'localhost:9200/_analyze?analyzer=ik_smart&pretty=true' --data-urlencode "text=中华人民共和国国歌"
{
"tokens" : [ {
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}, {
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
} ]
}
注
这里使用的版本分别是:
| soft | version |
|---|---|
| elasticsearch | 2.4.0 |
| elasticsearch-head | master分支的当前版本 |
| elasticsearch-analysis-ik | 1.10.0 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号