编译原理LR(0)项目集规范族的构造详解
转载于https://blog.csdn.net/johan_joe_king/article/details/79051993#comments
学编译原理的时候,感觉什么LL(1)、LR(0)、SLR(1)、LALR(1)思想满天飞。
而且做题的时候,一不留意,一道题就写了三页纸了。
就拿今天这个玩意儿来讲,我真的是考试前花了最多的时间,搞懂了(差不多搞懂了)这是个什么玩意儿。
以下内容,做题的话应该够了而且很!容!易!理!解!,其他学术情况恕博主也是个菜鸡。
废话就不多扯了,能搜到看到这篇文章的小伙伴也不容易,挺有缘的,根据步骤想参考资料的话,就拿出你的《编译原理第二版·清华大学出版社》吧,第二版哦!我也不知道第三版一不一样,反正页数好像是不一样。
我这里就用书上现成的例子了吧,第二版的7.2.4 LR(0)项目集规范族的构造这节本身其实写得很详细很学术很看不懂。大概跟本文有关而且有意思很重要的内容是这样的:
现在得到了一个拓广文法G'(前面有介绍怎么求,很简单就加个S'的规则就行),好这势必是一个好的开头。
S'->E
E->aA | bB
A->cA | d
B->cB | d
接下来求文法的项目,这个也简单,就给每个规则加一个点以后然后挪位置,挪一个位置就得到一个项目,操作完了以后你就得到了一堆项目,这就是你接下来要面对的核心的东西了。
1.S'->·E 2.S'->E· 3.E->·aA 4.E->a·A 5.E->aA· 6.A->·cA 7.A->c·A 8.A->cA· 9.A->·d
10.A->d· 11.E->·bB 12.E->b·B 13.E->bB· 14.B->·cB 15.B->c·B 16.B->cB· 17.B->·d 18.B->d·
有关CLOSURE闭包的构造和转向函数GOTO(I,X)的定义小伙伴们自己看书吧,说实话你要真让我复述定义我也半吊子,但内涵理解了就做题没毛病了。不过还是要提到一个“核”的概念,你可以理解为那张图的每一个状态最头上那条规则。
接下来构造项目集规范族那张图的步骤是这样的:
把有S'的项目而且点在最左边的项目作为状态I0的核,放在开头。然后看这个点后面的非终结符,是个E,接下来就去项目中找左部是E的而且点在最左边开头位置的项目,列在核的下面,这就是状态I0了,你可以画个框框然后标记一下。
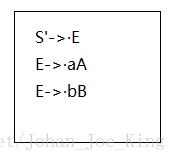
接下来还是先看核里面点后的这个非终结符E,输入E(你可以理解为在箭弧上标了个E),把点向后移一位,得到S'->E·,这其实是得到了一个新的状态的核。当然另外两个也一样,输入点后面的符号,比如输入a得到E->a·A为核的新状态,输入b得到E->b·B为核的新状态。得到新状态的核了,就顺便把这个状态剩下的项目也列出来吧,就是看核的点后面的非终结符,找以这个非终结符为左部的点在最左边的项目。当然要是点后面没有东西就不用找了,新的状态记得标号哦。
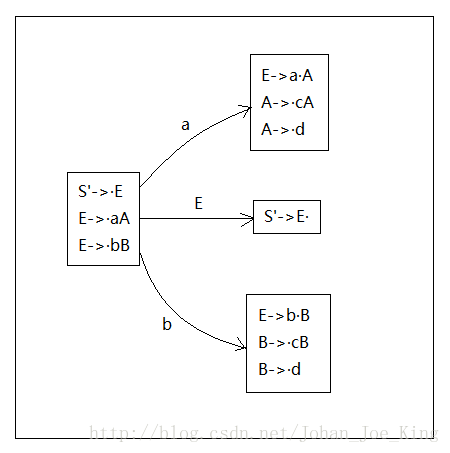
其实,讲到这里项目集规范族的构造方法部分就!完!了!接下来就是重复上面的工作,从每一个新状态出发,逐个输入每个项目点后面的符号,就是后移一位,又分别作为新的状态的核然后根据核找下面的同状态里的项目。找到找不动为止。比如我再找一个I2后面的试试:
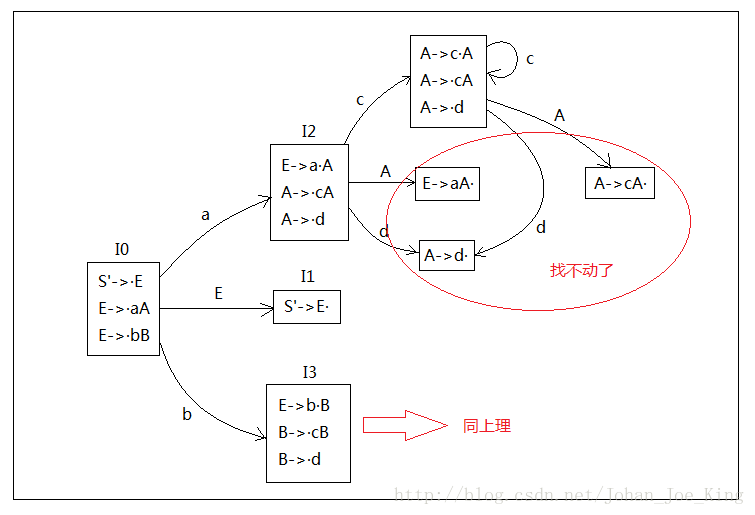
当你求出整张图的时候,恭喜你万里长征走完第一步了,后面可能涉及到的LR(0)分析表的构造,本文就“请看下回分解”了。
菜鸡写篇博客挺不容易的! 如果内容有误请小伙伴在下方评论区指点......
如果内容有误请小伙伴在下方评论区指点......

