
Kafka监听数据库的数据变化并且实时汇总输出统计值
项目需求
一个数据库的大表(百万级别),每次group后进行sum操作,比较耗时,借助kafka实现实时统计分析
搭建测试环境
为了测试方法,基于本地的docker进行部署(yml文件下载),里面包括了:Zookpper,Kafka服务,schema registry, kafka connect, ksqldb等
-
docker安装成功后,基于kafka客户端工具进行测试,这里需要连接部署kafka服务的端口
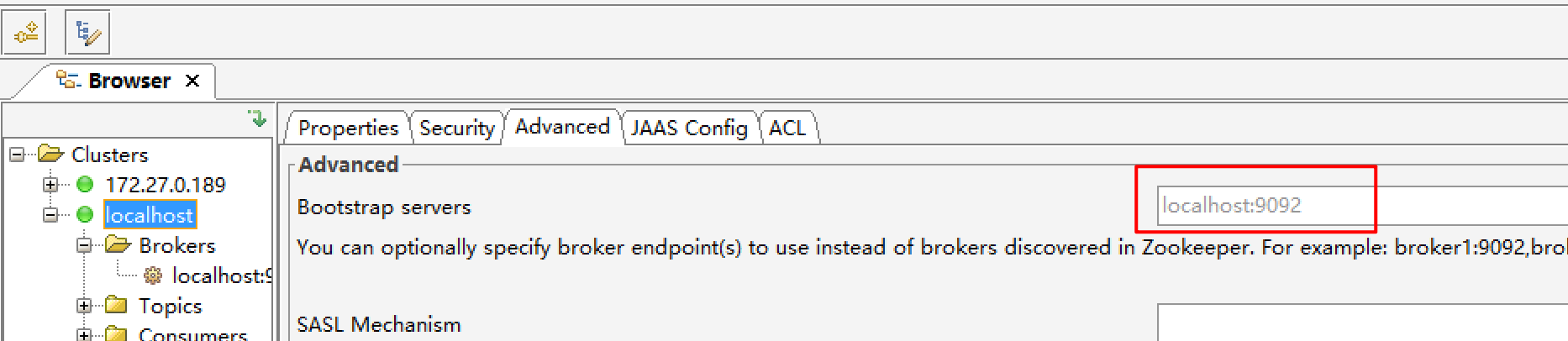
-
基于docker命令查看部署服务的network名称,如果之前以及基于docker安装了sqlserver,则需要将其修改为同一个network

安装Linux版本的sqlserver数据库(也可以编辑上面的yml文件,将sqlserver和kafka服务一起安装,这样它们就在同一个network了)
- 基于Docker进行安装
docker pull mcr.microsoft.com/mssql/server:2017-latest - 启动sqlserver,需要指定network
docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=xxxx" -p 11433:1433 --name sqlserver --network kafkawithconnect_default -d mcr.microsoft.com/mssql/server:2017-latest - 如果需要修改sqlserver的network,则可以通过下面命令进行操作
- 先连接新的网桥:
docker network connect new_network 容器ID(new_network是新名称) - 再断开旧的网桥:
docker network disconnect old_network 容器ID(old_network 是旧名称)
- 先连接新的网桥:
- 开启数据库的capture功能
-- Enable Database for CDC template -- ==== USE MyDB GO EXEC sys.sp_cdc_enable_db GO - 开启table的监听功能
USE MyDB GO EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'MyTable', @role_name = NULL, @supports_net_changes = 1 GO - 启动sqlserver的代理服务
- 进入sqlserver容器 :
docker exec -it --user root sqlserver bash - 执行命令:
/opt/mssql/bin/mssql-conf set sqlagent.enabled true - 顺便记录下其内网ip,后面会用,比如是 172.18.0.4
- 重启sql容器
- 进入sqlserver容器 :
- 查看数据库的代理状态
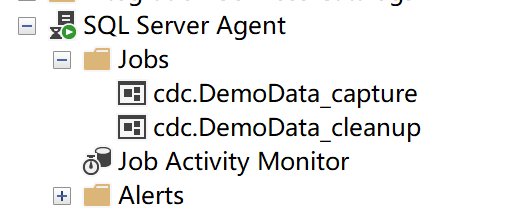
kafka服务关联sqlserver
基于kafka-connect进行配置
- 通过docker exec进入容器kafka-connect
- 基于curl来配置和数据库的连接
curl -k -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d ' { "name": "nonpharm_copy_connect2", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.hostname": "172.18.0.4", //sqlserver 内网ip "database.port": "1433", "database.user": "sa", "database.password": "xxx", "database.dbname": "DemoData", //database name "database.server.name": "cf037dc10467", //数据库服务名称,如果是基于docker部署,也是容器的名称 "table.whitelist": "dbo.nonpharm_copy2", //table name "database.history.kafka.bootstrap.servers": "broker:29092", "database.history.kafka.topic": "sshist_nonpharm_copy2", "transforms.unwrap.delete.handling.mode":"rewrite", "transforms":"unwrap,route", "transforms.route.type":"org.apache.kafka.connect.transforms.RegexRouter", "transforms.route.regex":"([^.]+)\\.([^.]+)\\.([^.]+)", "transforms.unwrap.drop.tombstones":"false", "transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState", "transforms.route.replacement":"sqlserv_$3" } }' - 运行后查看状态
curl -k http://localhost:8083/connectors/nonpharm_copy_connect2/status,这一步很关键,要确保是running状态并且没有任何错误,然后通过kafka客户端能看到对应的topic,这个算是原始的数据流,修改数据库的table,这里就会有新值

- 删除connect的命令
curl -X DELETE http://localhost:8083/connectors/<connector-name>
基于KSql进行数据操作
- 进入到KSql服务
docker exec --interactive --tty ksqldb ksql http://localhost:8088 - 如果需要从数据的开始进行设置,则需要设置
SET 'auto.offset.reset' = 'earliest'; - 通过命令查看当前的topic/stream/table
Show topics; show streams; show tables; - 创建Stream :
create stream Pharm_source_s_all with (kafka_topic='sqlserv_PharmXInvoiceItem_V2',value_format='avro');- 也可以创建Table,要看具体需求,简单来说,stream相当于记录数据库每行的每个动作(无边界且不可修改,消费的时候数据库的变化会实时显示),而table是记录最新值(有边界,运行一次后,数据库的实时更新不会同步,相当于展示的是stream当时的快照)。
- 基于原始的topic创建table
create table NonPharm_copy_source (Id bigint PRIMARY key,MychemID int,ExtendedCostExGst double,QuantitySupplied double) with (kafka_topic='sqlserv_nonpharm_copy2',value_format='avro');
- 基于原始的topic创建table
- 如果数据都是追加而没有更新的,并且需要基于客户端实时显示,则应该创建Stream
- 和数据库进行关联的topic,要基于avro格式来创建。
- 也可以创建Table,要看具体需求,简单来说,stream相当于记录数据库每行的每个动作(无边界且不可修改,消费的时候数据库的变化会实时显示),而table是记录最新值(有边界,运行一次后,数据库的实时更新不会同步,相当于展示的是stream当时的快照)。
- 创建成功后,可以通过describe tablename/streamname来查看数据类型;也可以通过select查询来测试这个最新创建的table
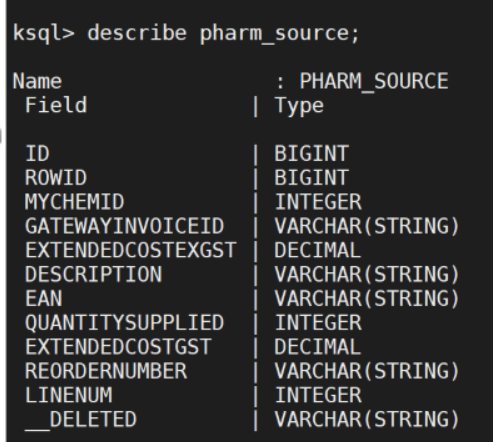
- 基于业务需要,设置需要实时汇总的数据查询
create table NonPharm_cpoy_live as select MychemID,SUM(ExtendedCostExGst) as totalMoney ,SUM(QuantitySupplied) as totalCount,SUM(ExtendedCostExGst)/SUM(QuantitySupplied) as unitprice from NONPHARM_copy_SOURCE group by MychemID emit changes;创建成功后,会显示NonPharm_cpoy_live这个topic

- 通过
print 'NONPHARM_CPOY_LIVE' from BEGINNING;查询实时汇总的数据

到这里,基于kafka监听sqlserver数据实时变化并且输出汇总数据的服务器端配置基本就结束了,还有几点需要注意的:
- 基于yml创建docker的时候,如果不是在本机操作,则一定需要将这个IP改完部署服务的ip,并且在kafka客户端连接的配置也需要用这个IP
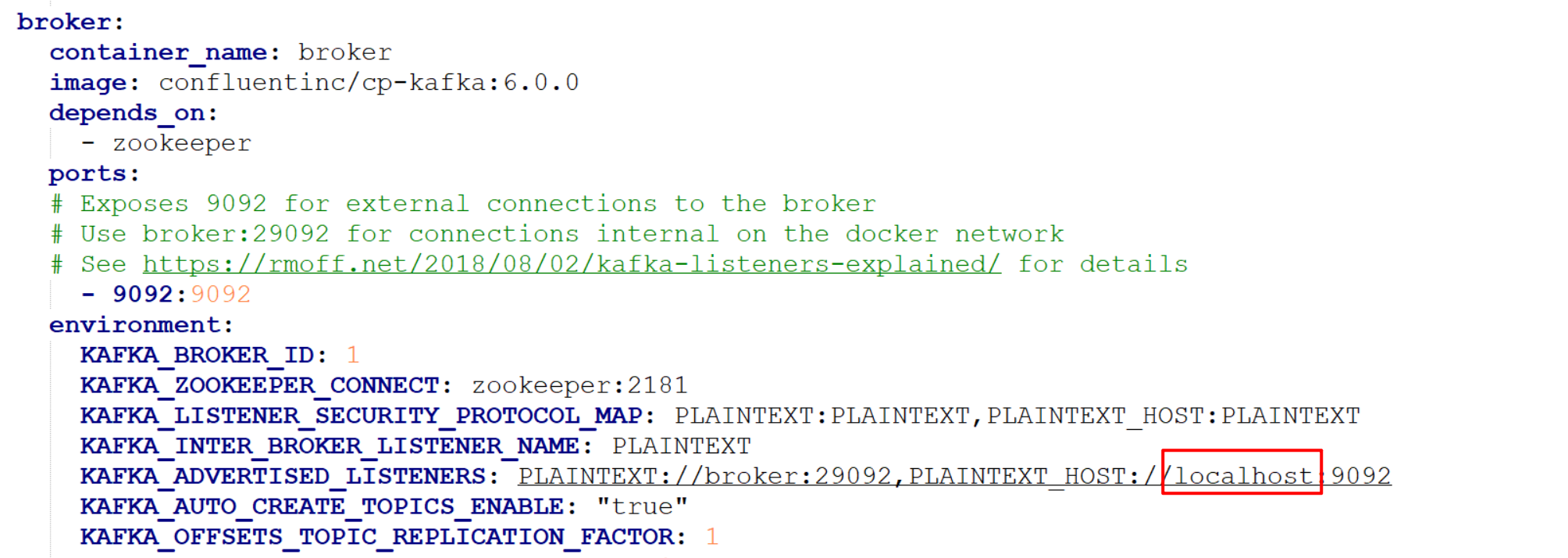
- 测试的时候,如果sqlserver数据类型是decimal,导入到ksql后进行相除汇总,如果除不尽,则返回的是null,所以后面是先在sqlserver将decimal转为float后再导入到KSQL,如果有高手能指点这块,非常感谢!
- 创建新的table最好使用新名字(即使之前的table已经被删除了)
- 如果需要客户端每次从头开始消费,则需要设置不同的GroupId
- Table VS Stream
- 理论上,我们可以不通过KSQL进行汇总,而是再各自的客户端进行汇总,但是通过KSQL汇总的好处是汇总一次,其它客户端或者数据看板可以直接使用,比较方便
- 如果是基于JSON的数据源,则消费的时候没什么特别的;但如果是基于AVRO的格式,则需要再消费的时候配置反序列化的方式,以NET Core为例:
var consumer = new ConsumerBuilder<int, GenericRecord>(config).SetValueDeserializer(new AvroDeserializer<GenericRecord>(schemaRegistry).AsSyncOverAsync()).Build()
Demo下载
一把吉他,一部单反,行走江湖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号