


| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 课程班级博客链接 |
| 这个作业要求链接 | 作业要求链接 |
| 我的课程学习目标 | 学习PSP流程并运用于结对项目;学习GitHub代码的管理;学习结对编程的流程与内容 |
| 这个作业在哪些方面帮助我实现学习目标 | 学习编程、学习算法、工程实践 |
| 结对方学号-姓名 | 201873030133-杨子豪 |
| 结对方本次博客作业链接 | 链接 |
| 本项目Github的仓库链接地址 | 客户端 服务器端 |
1、实验目的与要求
(1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。
(2)掌握Github协作开发程序的操作方法。
2、实验内容和步骤
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价,具体要求如下:
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
评论
(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。(已完成)
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。(已完成)
| ----------概要部分---------- | |
|---|---|
| 代码是否符合需求和规范说明 | 符合 |
| 代码设计是否考虑周全 | 周全 |
| 代码可读性如何 | 清晰易读 |
| 代码容易维护吗 | 容易 |
| 代码的每一行都执行并检查过了吗 | 否 |
| ----------设计规范部分---------- | |
| 设计是否遵循从已知的设计模式或项目中常用的设计模式 | 是 |
| 有没有硬编码或字符串/数字等存在 | 有 |
| 代码是否依赖于某一平台,是否会影响将来的移植 | 代码由C#编写,可能会影响移植 |
| 开发者新写的代码是否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以通过调用而不用全部重新实现? | 是,用已有的Library/SDK/Framework中的功能实现 |
| 有没有无用的代码可以清除 | 有 |
| ----------代码规范部分---------- | |
| 修改的部分符合代码标准和风格么 | 符合 |
| ----------具体代码部分---------- | |
| 有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常? | 已处理 |
| 参数传递有无错误,字符串的长度是字节的长度还是字符的长度,是从0开始计数还是从1开始计数 | 无错误,字符的长度,从0开始计数 |
| 边界条件是如何处理的?switch语句和default分支是如何处理的?循环有没有可能出现死循环? | 通过前提分析推导边界条件 |
| 有没有使用断言(Assert)来保证我们认为不变的条件真的得到满足? | 否 |
| 对资源的利用,是在哪里申请,在哪里释放的?有无可能存在资源泄露?有没有优化的空间? | 自动申请释放,不会存在资源泄露,有优化的空间 |
| 数据结构中有没有用不到的元素? | 有 |
| ----------效能---------- | |
| 代码的效能(Performance)如何?最坏的情况是怎么样的? | 效能一般,数据量过大可能会需要很长的运行时间而得不到结果 |
| 代码中,特别是循环中是否有明显可优化的部分? | 无 |
| 对于系统和网络的调用是否会超时?如何处理? | 如果超时,重新调用 |
| 代码可读性如何?有没有足够的注释? | 结构清晰,但注释较少 |
| ----------可测试性---------- | |
| 代码是否需要更新或创建新的单元测试 | 否 |
博客作业中针对任务2的评分要点:
- 结对方博客链接(1分);
- 结对方Github项目仓库链接(1分);
- 符合(1)要求的博客评论(18分);
- 符合(2)要求的代码核查表(15分);
- 结对方项目仓库中的Fork、Clone、Push、Pull request、Merge pull request日志数据(5分)
任务3:采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
结对编程项目实施要求及代码部分评分细则(30分):
- 结对编程开发进度计划的要求:在项目正式之前,预估本次结对项目任务的PSP环节的消耗时间,并在PSP过程中统计实际耗时,填写PSP表格。
- 尝试采用汉堡包法实施项目结对中两个人的沟通,关于汉堡包法的阐述参见:http://www.cnblogs.com/xinz/archive/2011/08/22/2148776.html
- 理解领航员和驾驶员两种角色关系:两人都必须参与编码工作,在结对编程中两个人轮流做对方的角色。
- 将结对编程项目的源码以增量方式提交到指定同学Github账号的项目仓库中,Github结对项目仓库的代码提交日志要体现两人合作过程,项目仓库中要能看到项目多次commit的记录,和两人各自的commit记录。(5分)
- 项目必须包含src文件夹;
- 编撰两人合作开发遵守共同认可的编码规范,提交项目代码规范文档到Github项目仓库根目录下。(5分)
- 程序功能评测。( 20分)
1.需求分析陈述。(5分)
1.能够正确读入实验数据文件的有效D{0-1}KP数据,即从给定的txt文件中正确切割、正确读取数据,并将数据传送到服务器保存到数据库。
2.能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图,将这一组数据直观的显示出来,并且需要新坐标系,重量设为x,价值设为y,来绘制新坐标轴。
3.能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序。产品的“价值重量比”高就是说重量很轻,价值很高。价值重量比越高,这个产品的销售半径就越大。
4.使用者能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间,即可以对同一组数据选择不同的算法进行计算最优解,求解向量,并可以将结果存储到服务器上的数据库中
5.对于任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件,可以一次求解,永久使用。
6.需要保存日志,服务器端和客户端都需要留有日志。
2.软件设计说明。(5分)
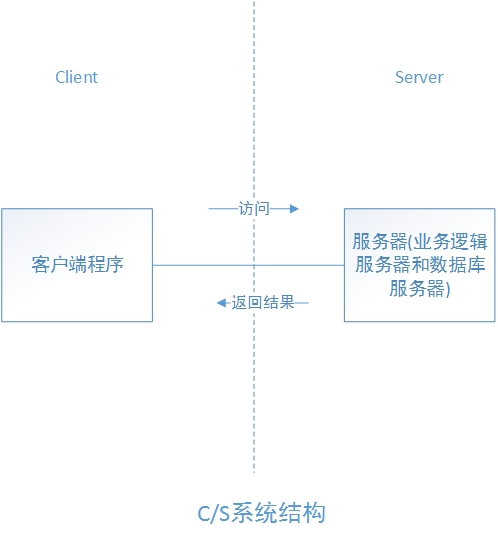
本次结对编程项目采用C/S结构进行,项目分两部分,一部分是客户端的编写,客户端主要处理本地读取的数据和传输数据到服务器和数据库,还有从服务器读取数据库中存储的结果,一部分是服务器端的编写,主要是连接数据库,接收信息,返回信息。客户端和服务器端双方通过tcp链接,并且在此基础上自定义协议进行通信和操作。同时本次项目采用了.net core平台作为开发平台,它具有跨平台、易开发等多种特点,在本次开发中尽量减少在重复工作上的工作量。
3.软件实现及核心功能代码展示:软件包括哪些类,这些类分别负责什么功能,他们之间的关系怎样?类内有哪些重要的方法,关键的方法是否需要画出流程图?(5分)
客户端的类有:
1.Articles
代表一个物品,具有重量价值等属性
2.DataExtraction
封装的数据处理类,可以对数据集进行处理、读取、传送、排序等操作,本次的遗传算法通过c语言进行实现,利用重定向数据流完成调用。
public string genetic_Algorithm(int index)
{
StreamWriter sw = new StreamWriter("data.txt");
int item_Set_Count = data_Sets[index].get_Item_Sets_Count();
int cubage = data_Sets[index].get_Cubage();
string profit = data_Sets[index].get_All_Profit_Str();
string weight = data_Sets[index].get_All_Weight_Str();
try
{
sw.WriteLine(item_Set_Count);
sw.WriteLine(cubage);
sw.WriteLine(profit);
sw.WriteLine(weight);
sw.Close();
using (Process p = new Process())
{
p.StartInfo.FileName = @"./Test1.exe";//可执行程序路径
p.StartInfo.Arguments = "";//参数以空格分隔,如果某个参数为空,可以传入""
p.StartInfo.UseShellExecute = false;//是否使用操作系统shell启动
p.StartInfo.CreateNoWindow = true;//不显示程序窗口
p.StartInfo.RedirectStandardOutput = true;//由调用程序获取输出信息
p.StartInfo.RedirectStandardInput = true; //接受来自调用程序的输入信息
p.StartInfo.RedirectStandardError = true; //重定向标准错误输出
p.Start();
p.WaitForExit();
//正常运行结束放回代码为0
string result = "";
if (p.ExitCode == 0)
{
result = p.StandardOutput.ReadToEnd();
return result;
}
}
}
catch(Exception e)
{
}
finally
{
}
return "ERROR";
}
3.DataSet
数据集类,包含一个数据集中的所有物品集,并且具有动态规划法、回溯法等处理函数。
4.ItemSet
物品集,包含三个物品对象和他们的操作函数。
5.ItemSetSort
继承了比较器的接口,可以对两个物品集按照第三项的价值重量比进行比较
6.NetworkSendData
负责和服务器端进行网络连接,并且可以进行和服务器端进行交互。
下面是一种控制字的客户端的操作流程:
public void DSW(string fn, int index)
{
try
{
int state = get_Connect_State();
if (state == 1)
{
send_Data_To_Server("DSW");
string temp = read_Data_From_Server();
if (temp.Equals("OK"))
{
int count = dataExtraction.get_items_Set_Count(index) * 3;
send_Data_To_Server(count.ToString());
temp = read_Data_From_Server();
if (temp.Equals("OK"))
{
int i = 0;
do
{
string[] send = dataExtraction.get_DSW_Str(index, i);
for (int j = 0; j < 3 && temp.Equals("OK"); j++)
{
send_Data_To_Server(fn + "#" + index.ToString() + "#" + i.ToString() + "#" + send[j]);
temp = read_Data_From_Server();
}
i++;
} while (temp.Equals("OK") && i < count);
}
}
else
{
return;
}
}
}
catch (Exception e)
{
Console.WriteLine(e.ToString());
}
}
7.OutputToFile
负责将结果和解向量输出到txt或者excel文件中
8.Program
项目的主类,是项目开始的地方
9.SortByTheThirdItem
对于给定的数据集,按照他们每一个物品集的第三个物品的价值重量比进行排序。
10.Form1、Form2、Form3
分别对应登录注册窗口、数据处理窗口和散点图绘制窗口
服务器端的类有:
1.From1
简单显示
2.MySQLConnectionClass
负责与数据库的链接和各类网络指令的操作
3.NetworkReceptionData
负责通过网络链连接与客户端进行交互
4.Program
服务器端项目的入口
5.User
用户类,本来打算显示用户名的,但是懒得做,只显示了ip和端口号
4.程序运行:程序运行时每个功能界面截图。扩展功能实现可得附加分5分。(2分)
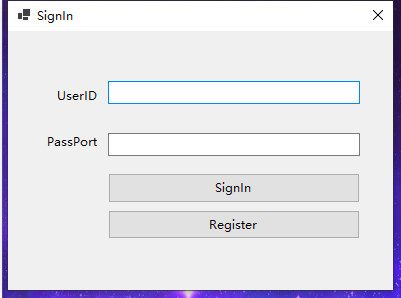
程序的登录界面,输入数字id和密码即可登陆或注册
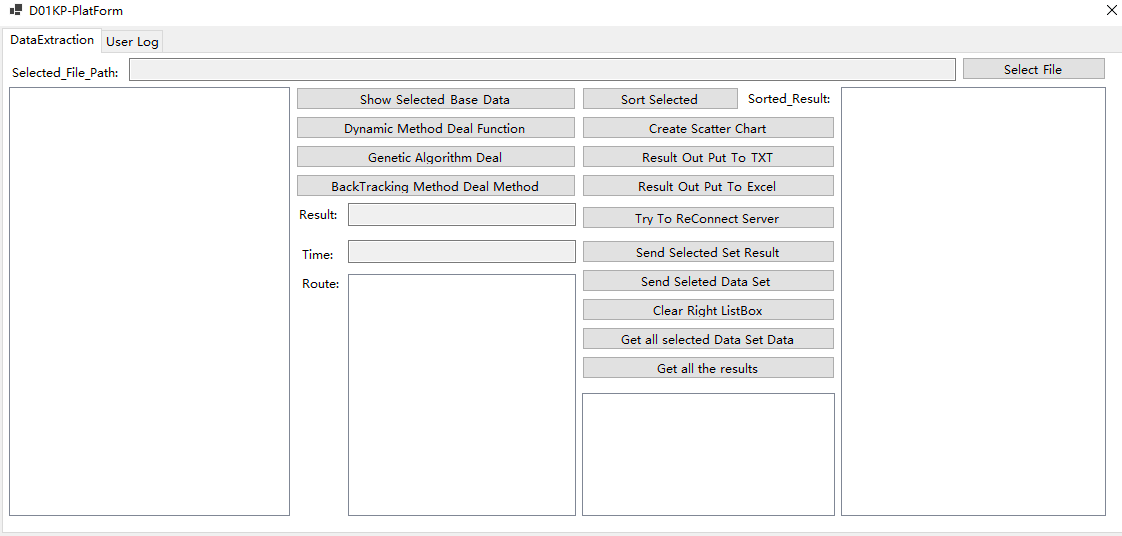
程序的主界面,分两部分,一部分是dataextraction包含数据处理的模块,Userlog则会记录你的日志,并且在较长的一段时间后自动清理日志。
最右方的列表负责显现排序好的数据集或者显示从服务器获取到的指定文件的数据集
 下方的两个列表分别负责显示结果的路径和从服务器获取所有已上传的数据集解信息
下方的两个列表分别负责显示结果的路径和从服务器获取所有已上传的数据集解信息
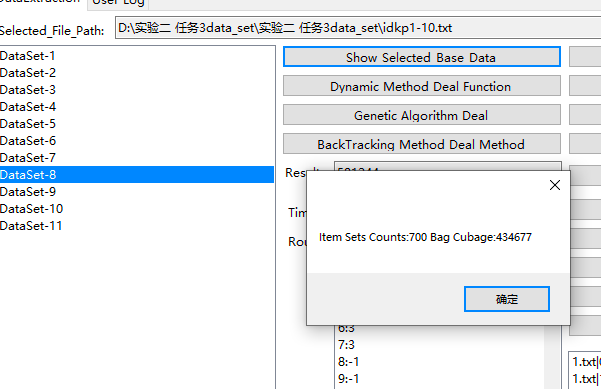
显示base data,即显示对应数据集的物品集数量和背包容量。
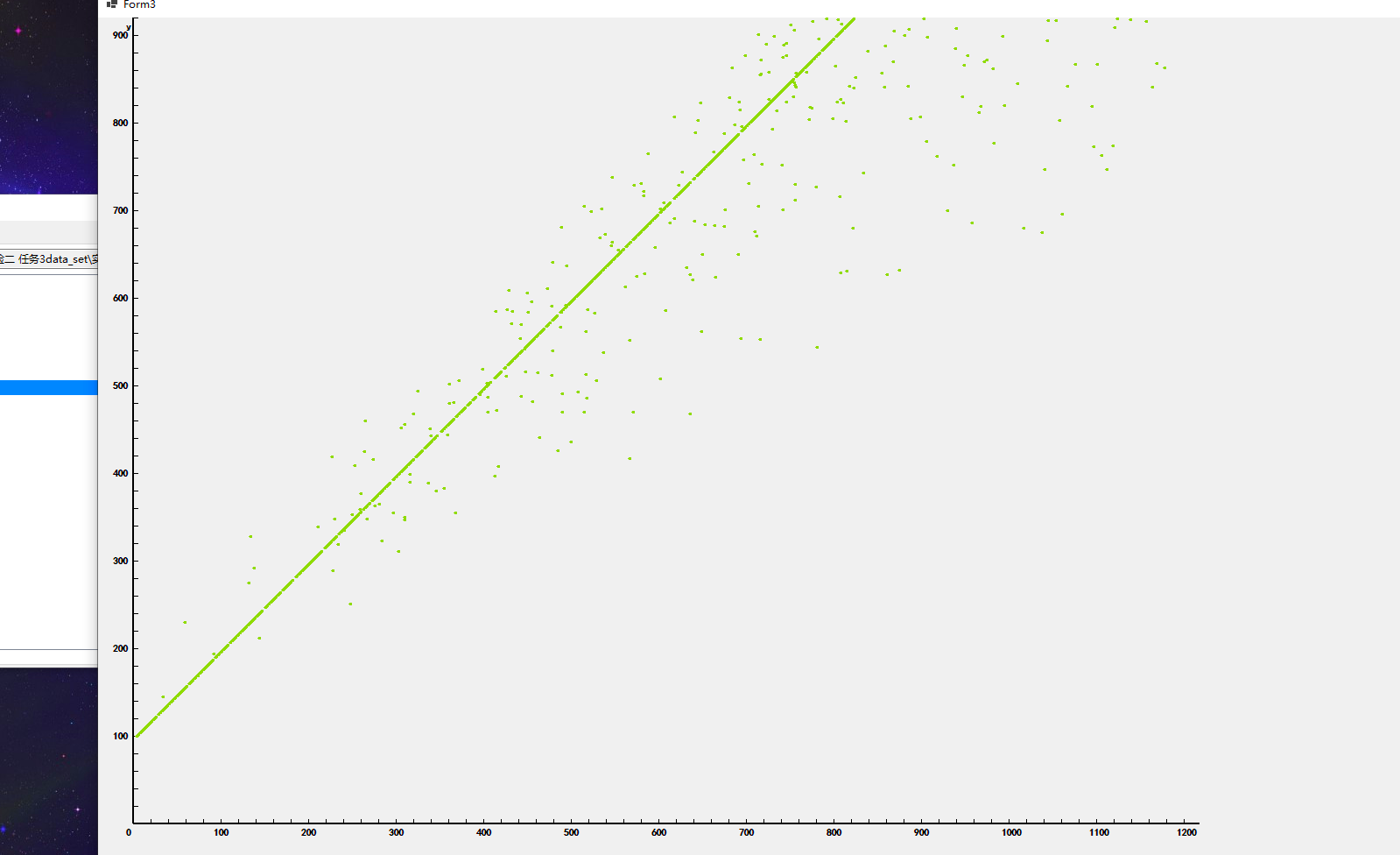
绘制出的散点图
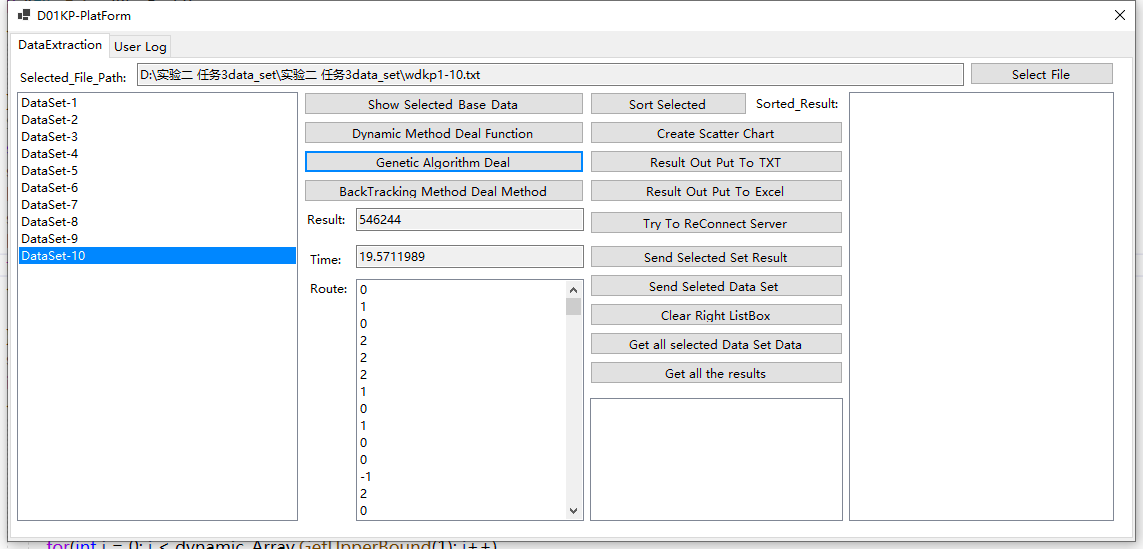
通过遗传算法解决问题,对应的结果、运行时间、解向量

将解和解向量输出到txt文件中

将解和解向量输出到excel中
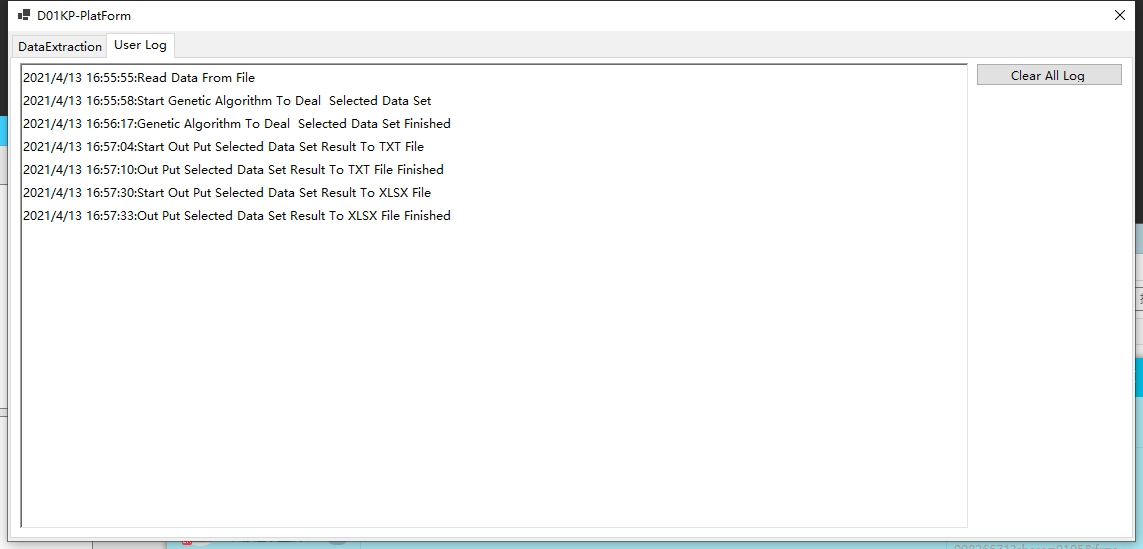
自动生成的日志信息
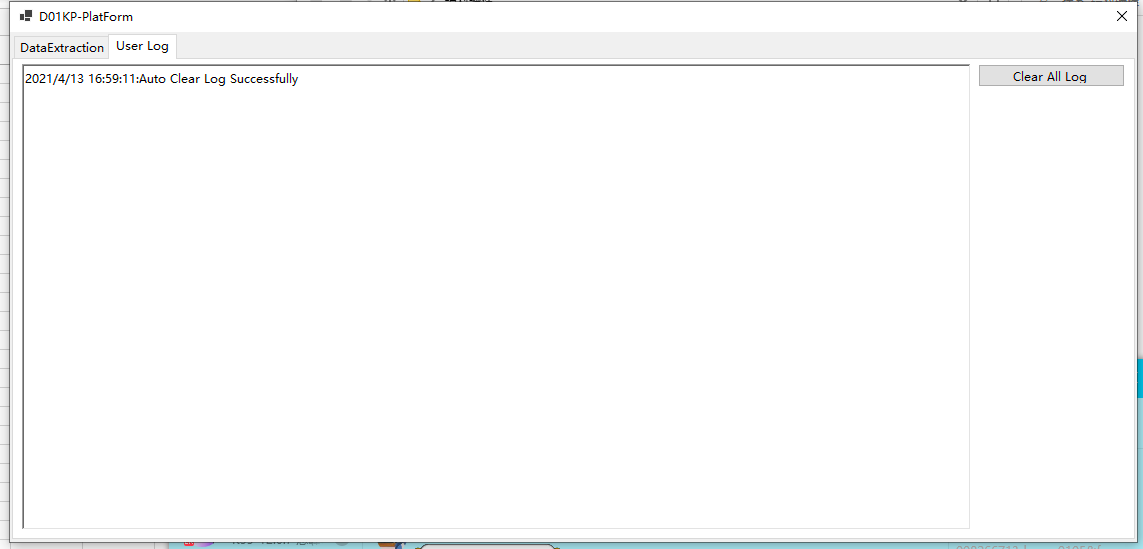
自动清理日志信息
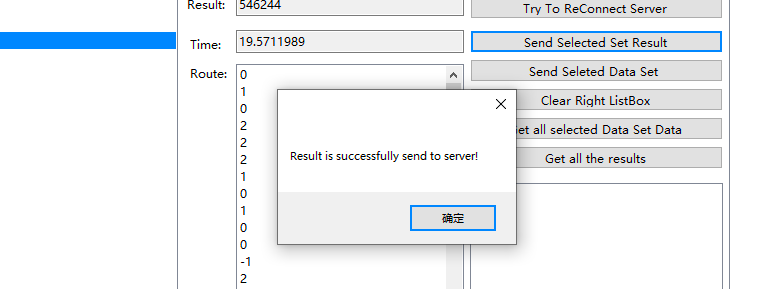
将本地运算的结果送到服务器
服务器端主窗口,左上角是连接的用户的的ip和端口号
左下角的列表是显示目前存入数据库的所有结果
服务器中的数据库的三张表
数据集数据存储的表
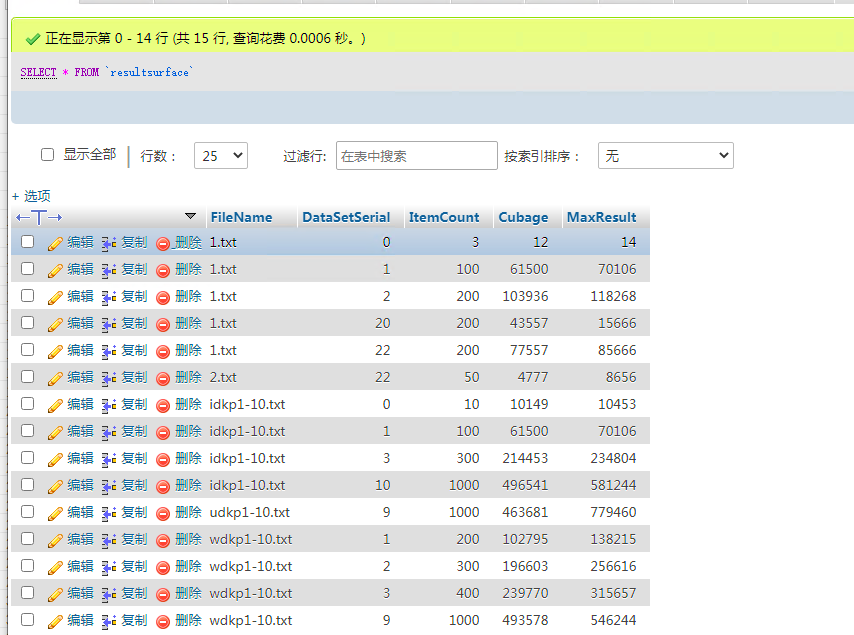
结果存储的表
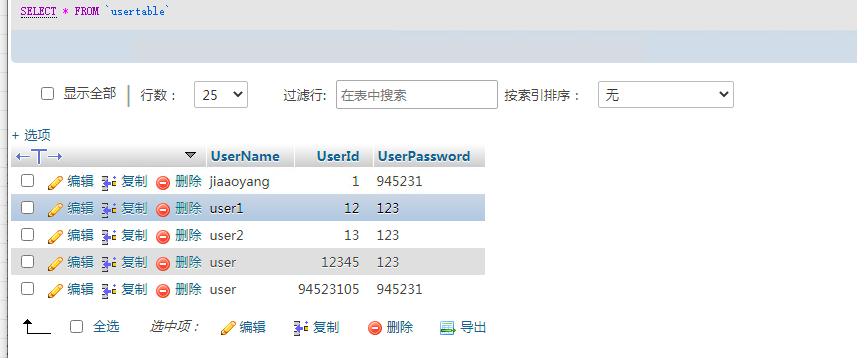
用户表
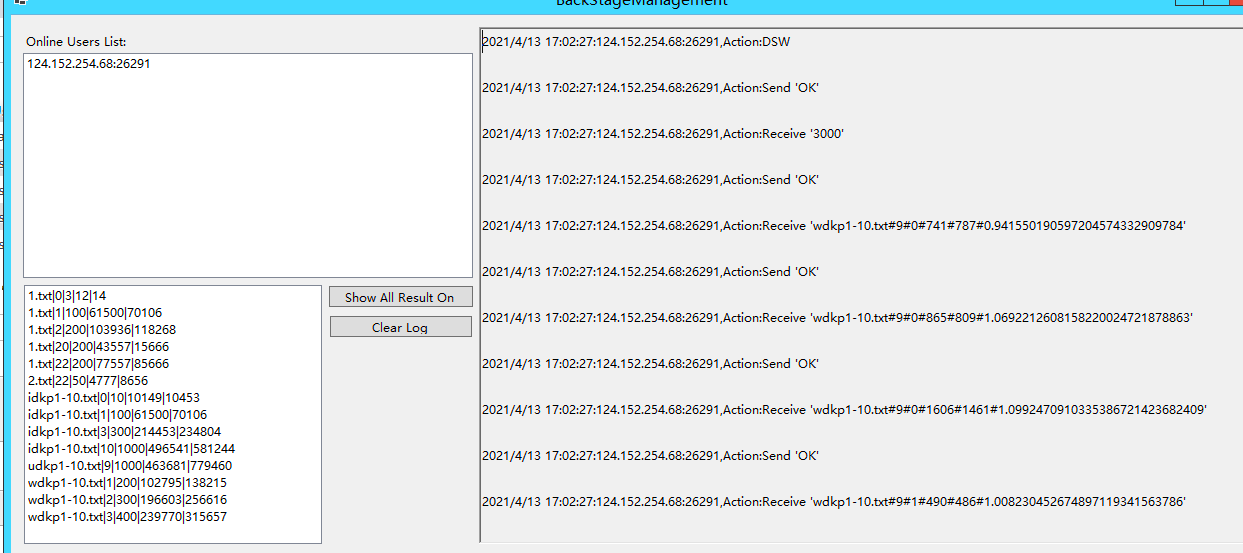
服务器端的日志
5.描述结对的过程,提供两人在讨论、细化和编程时的结对照片(非摆拍)。(3分)


6.提供此次结对作业的PSP。(4分)
| 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|
| 商讨这个任务,交流实验二的项目完成情况,并大致规划本次工作步骤 | 20 | 30 |
| 交流沟通对汉堡法和领航员与驾驶员的理解看法 | 200 | 300 |
| 编撰两人共同认可的编码规范 | 400 | 500 |
| 数据集存储在数据库功能的代码编写 | 800 | 1200 |
| 动态嵌入有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据功能的编写 | 500 | 800 |
| 人机交互界面(增加新功能) | 400 | 400 |
| 遗传算法的学习和设计 | 180 | 240 |
| 功能测试运行 | 30 | 30 |
7.小结感受:两人合作真的能够带来1+1>2的效果吗?通过这次结对合作,请谈谈你的感受和体会。(4分)
在结对编程中,任何一段代码都至少被两双眼睛看过,两个脑袋思考过。代码被不断地复审,这样可以避免牛仔式的编程。同时,结对编程避免了“我的代码”还是“他的代码”的问题,使得代码的责任不属于某个人,而是属于两个人,进而属于整个团队,这样能够帮助建立集体拥有代码的意识,在一定程度上避免了个人英雄主义。

