
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 课程班级博客链接 |
| 这个作业要求链接 | 作业要求链接 |
| 我的课程学习目标 | 通过本课程学习软件工程科目来学习计算机软件开发和维护 |
| 这个作业在哪些方面帮助我实现学习目标 | 帮助我了解psp流程,了解如何开发个人项目及练习github的操作 |
| 项目Github的仓库链接地址 | 项目仓库 |
任务1
阅读教师博客“常用源代码管理工具与开发工具”内容要求,点评班级博客中已提交相关至少3份作业。
点评链接1:https://www.cnblogs.com/krypton052/p/14551169.html#4842158
点评链接2:https://www.cnblogs.com/labmem/p/14550336.html#4842160
点评链接3:https://www.cnblogs.com/hc82/p/14549034.html#4842161
任务2
详细阅读《构建之法》第1章、第2章,掌握PSP流程。(已完成)
任务3
项目开发背景:背包问题(Knapsack Problem,KP)是NP Complete问题,也是一个经典的组合优化问题,有着广泛而重要的应用背景。{0-1}背包问题({0-1 }Knapsack Problem,{0-1}KP)是最基本的KP问题形式,它的一般描述为:从若干具有价值系数与重量系数的物品(或项)中,选择若干个装入一个具有载重限制的背包,如何选择才能使装入物品的重量系数之和在不超过背包载重前提下价值系数之和达到最大?
D{0-1} KP 是经典{ 0-1}背包问题的一个拓展形式,用以对实际商业活动中折扣销售、捆绑销售等现象进行最优化求解,达到获利最大化。D{0-1}KP数据集由一组项集组成,每个项集有3项物品可供背包装入选择,其中第三项价值是前两项之和,第三项的重量小于其他两项之和,算法求解过程中,如果选择了某个项集,则需要确定选择项集的哪个物品,每个项集的三个项中至多有一个可以被选择装入背包,D{0-1} KP问题要求计算在不超过背包载重量 的条件下,从给定的一组项集中选择满足要求装入背包的项,使得装入背包所有项的价值系数之和达到最大;D{0-1}KP instances数据集是研究D{0-1}背包问题时,用于评测和观察设计算法性能的标准数据集;动态规划算法、回溯算法是求解D{0-1}背包问题的经典算法。查阅相关资料,设计一个采用动态规划算法、回溯算法求解D{0-1}背包问题的程序,程序基本功能要求如下:
1.可正确读入实验数据文件的有效D{0-1}KP数据;
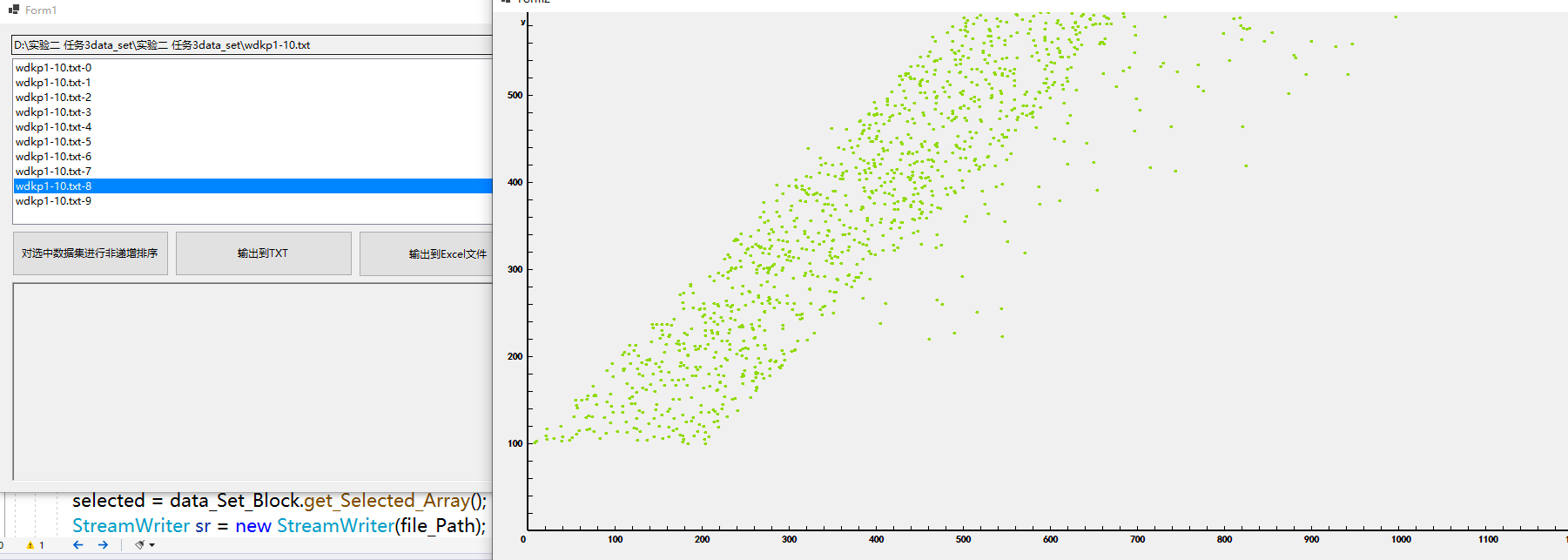
2.能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图;
3.能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;
4.用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位);
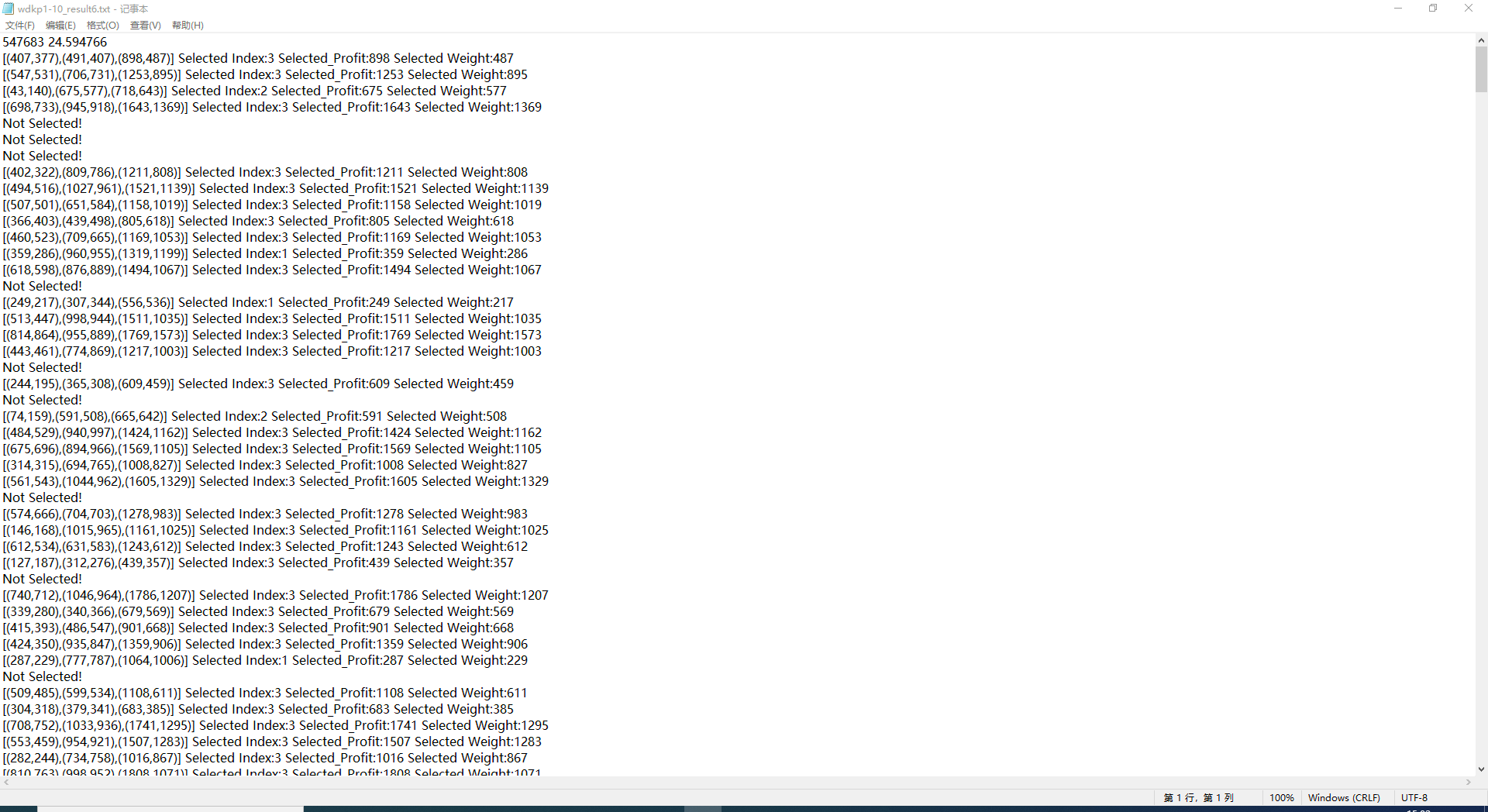
5.任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件。
1.需求分析
1.能够正确读入实验数据文件的有效D{0-1}KP数据,即从给定的txt文件中正确切割、正确读取数据。
2.能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图,将这一组数据直观的显示出来,并且需要新坐标系,重量设为x,价值设为y,来绘制新坐标轴。
3.能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序。产品的“价值重量比”高就是说重量很轻,价值很高。价值重量比越高,这个产品的销售半径就越大。
4.使用者能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间,即可以对同一组数据选择不同的算法进行计算最优解,求解向量。
5.对于任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件,可以一次求解,永久使用。
2.功能设计
1.基本功能
①从给定的txt文件中可以正确读入有效数据(已完成)
②绘制任意一组D{0-1}KP数据以重量为横轴,价值为纵轴的数据散点图(已完成)
③能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序(已完成)
④用户能够自主选择动态规划算法、回溯算法求解指定D{0-1}KP数据的最优解和求解时间(已完成)
⑤任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件。(已完成)
2.扩展功能
①可以将几个数据集合并求解(懒得写)
②将多个数据集的结果进行对比(懒得写)
③计算价值背包容量比(最优解/背包容量)(已完成)
3.设计实现
设计本程序共有七个类,首先是两个窗体类和主进程类,第一个窗体类Form1主要用来承载程序主界面,第二个窗体类Form2用来显示散点图。然后分别是数据块类data_Set_Block、数据集类item_Set、输出到文件的类out_Put_Data、将数据集按照第三项价值重量比排序并显示出来的的窗体类third_Sort。
Form1不仅承载程序主界面,同时也肩负着从文件中读取数据的任务,而且他的数据块列表承载了文件中的各个数据块的有效信息.重要函数有处理文件的函数、切割文件的函数、将数据存储到对应的data_Block_Set对象中的函数等。
Form2主要是通过对form1传来的数据块信息进行绘图,还有生成坐标系等工作。主要的函数就是绘制散点图、绘制坐标系、根据新原点确定新位置三个函数。
data_Set_Block主要是承载文件中一个数据块的信息,包含有多少的数据集、背包容量多大、各个数据集的对象等,而且还可以对整个数据块进行动态规划法和回溯法的计算,保存运行时间等。主要的函数就是回溯法计算、动态规划法计算、获取最优解、获取解向量。
item_Set主要是承载一个数据块中的一个数据集(包括三个物品信息),和数据集中物品的选择信息,以及获取特定物品重量价值等功能。主要函数就是获取重量价值、获取第三个数据项的价值重量比、设置和获取选中情况。
out_Put_Data类主要是承担将特定数据块的解向量、求解时间、最优解输出到文件中的功能,包括向txt文件或excel文件中写入数据并保存,主要函数就是写入到txt和写入到excel。
third_Sort类主要是根据传入数据块的每个数据集的第三个数据项的价值重量比进行非递增排序,并在dataGridView中显示出来(未与数据库进行连接),主要函数就是排序函数。
各个基础模块间功能相互独立,即实现最底层功能的函数互相独立,更高级的函数调用低级函数进行处理,尽量提高代码的复用性,上面的各个函数主要指的是非基础功能函数,为底层功能函数的聚合体,对于关键函数我认为没有必要画流程图,没什么难度,只在具体实现上有些坑,需要自己慢慢修改,部分注释已经足够。
4.测试运行
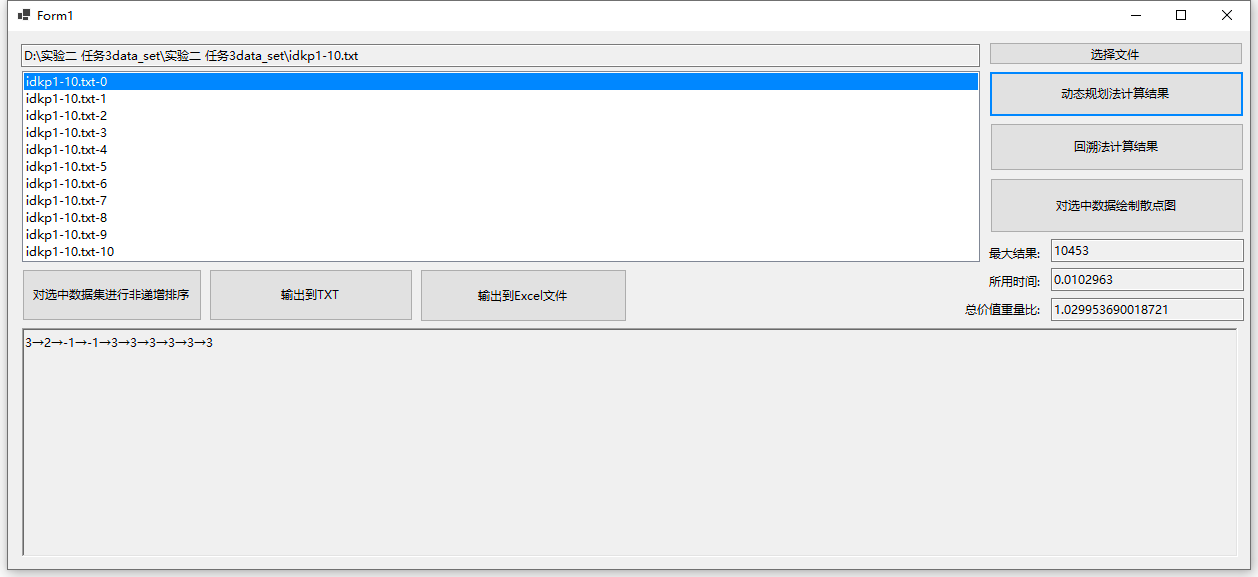
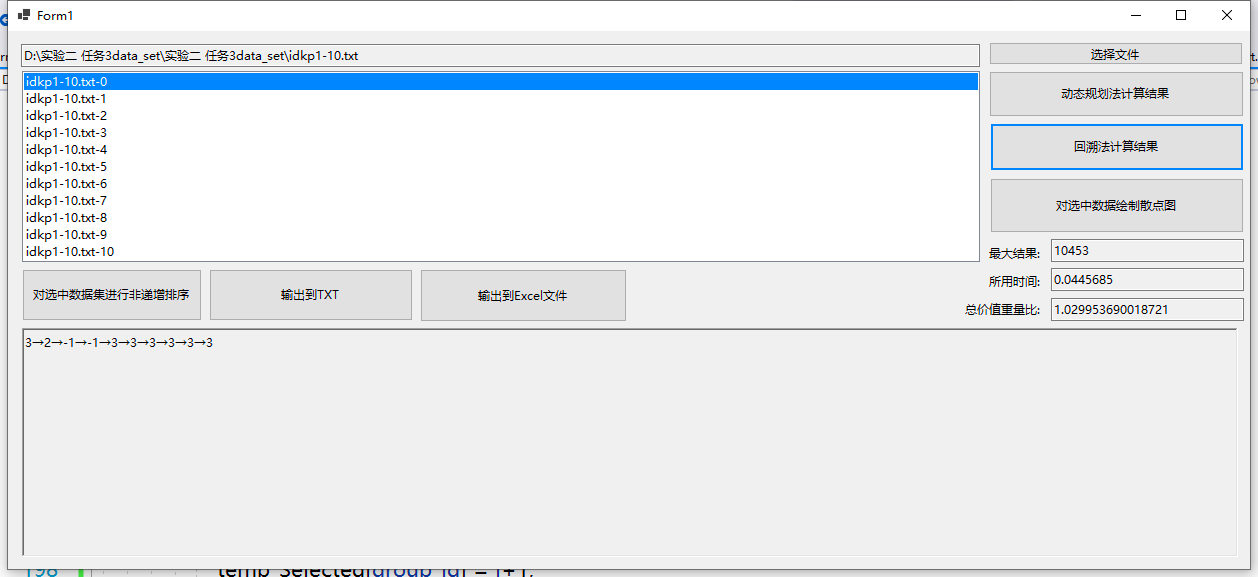
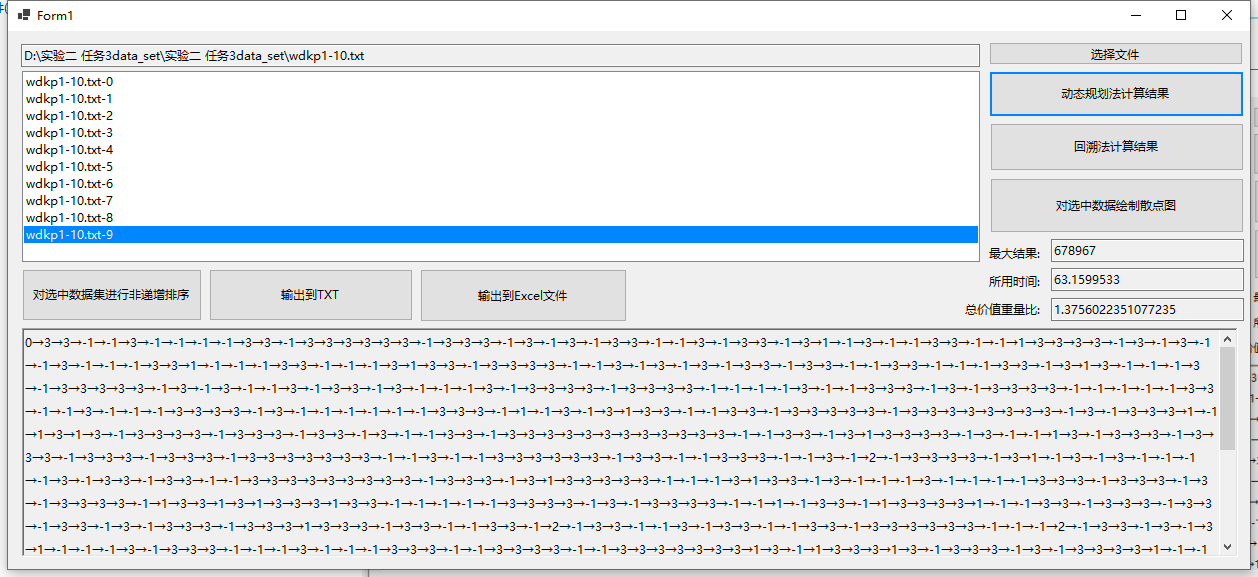
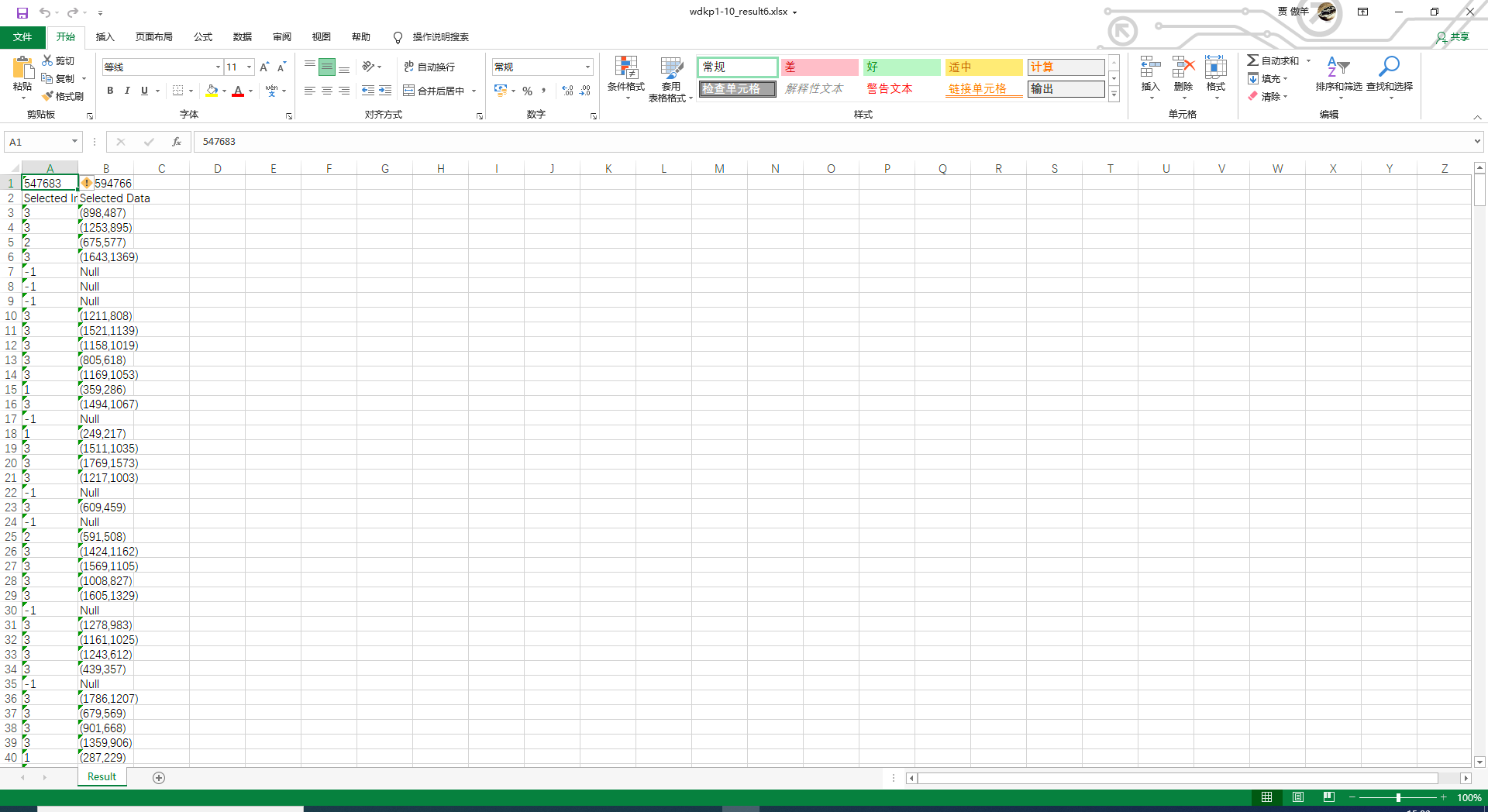
由于回溯法对于较大数据集的处理时间过长,因此仅测试了几组较小数据,这里仅展示idkp数据集文件中的第0号数据集,对于下面的结果,当前数据项的选择为-1时则本数据项不选,123分别对应选择的物品编号。
测试结果1(idkp0 动态规划法测试结果):
测试结果2(idkp0 回溯法测试结果):
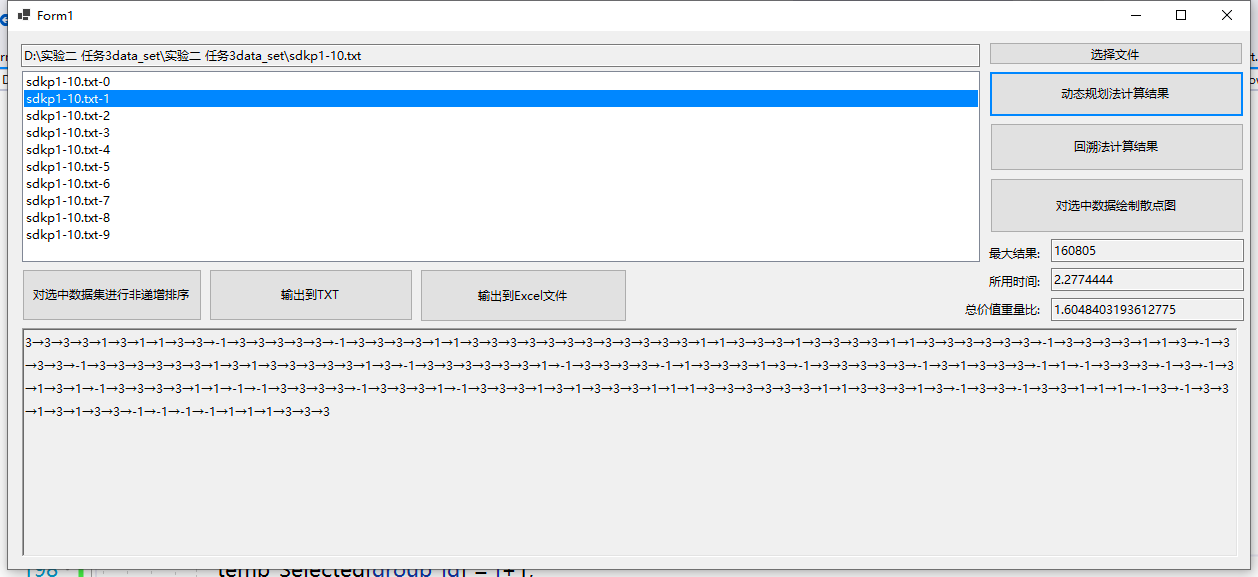
测试结果3(sdkp2 动态规划法):
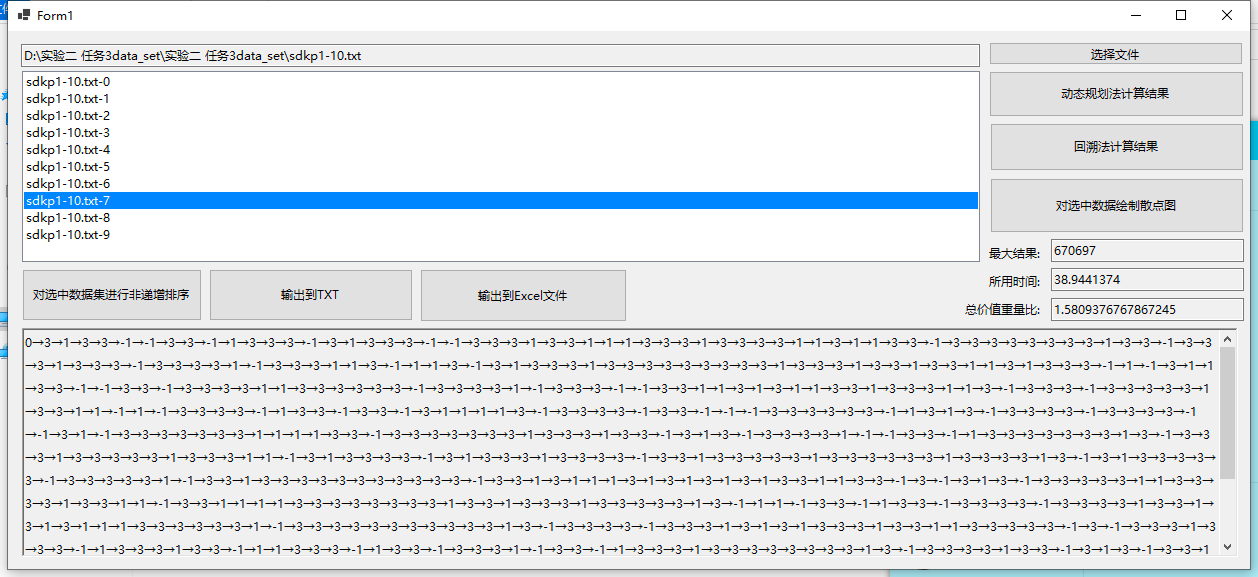
测试结果3(sdkp7 动态规划法):
测试结果4(sdkp9 动态规划法):
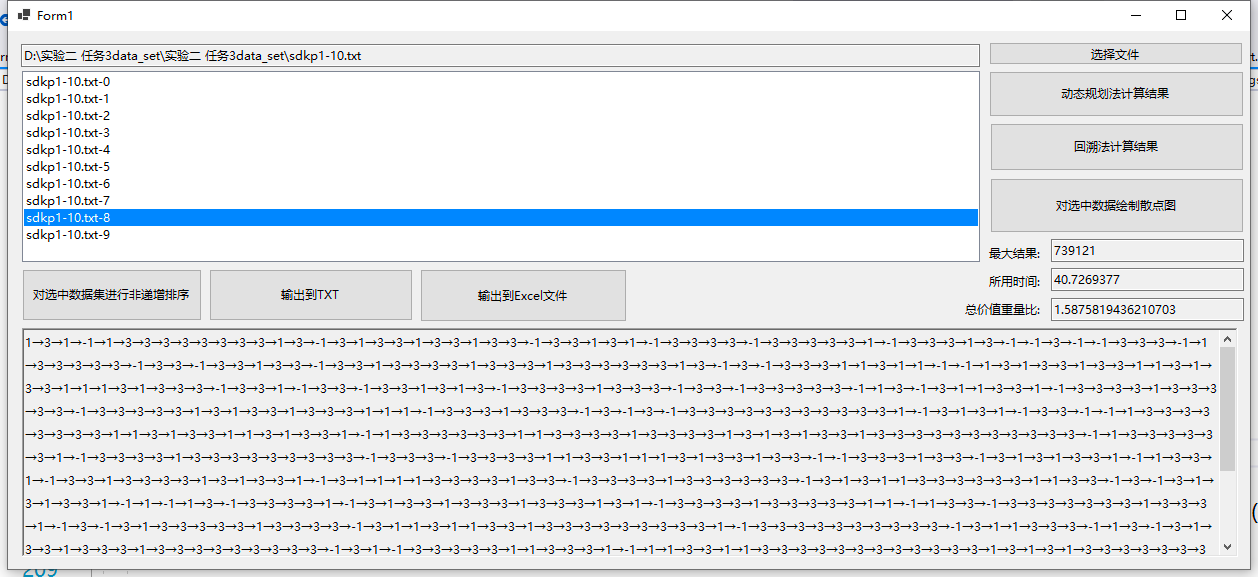
测试结果5(wdkp9 动态规划法):
散点图测试结果:
输出到txt文件的测试结果:
输出到excel文件的测试结果:
5.满意的代码片段
读取和切割文件的函数:
//从选中文件中读取源数据
private void read_Data_Set()
{
//清空中间数据
temp_Data = "";
//读取文件按行读取
String line = "";
//文件行数计数器清零
file_Lines_Count = 0;
try
{
//创建流读取对象sr
using (StreamReader sr = new StreamReader(data_Set_File_Path))
{
//当文件读取完毕结束读取
while ((line = sr.ReadLine()) != null)
{
//如果是空行则不加到中间数据
if (!string.IsNullOrWhiteSpace(line))
{
temp_Data += line+"\n";
file_Lines_Count++;
}
}
//去掉最后多出来的一个换行符
temp_Data = temp_Data.Substring(0, temp_Data.Length - 1);
}
}
catch (Exception e)
{
MessageBox.Show("Read Error!");
MessageBox.Show(e.Message);
}
}
//在文件数据全部读取到中间数据字符串后写入中间数据文件再进行切割
private void cut_Data_Set()
{
//清空数据集和列表1
data_Sets.Clear();
listBox1.Items.Clear();
//文件行数要去掉第一行和最后一行的开始结束符
file_Lines_Count -= 2;
//去掉第一行
int first_Line_End_Index = temp_Data.IndexOf('\n');
temp_Data = temp_Data.Remove(0, first_Line_End_Index + 1);
//去掉最后一行
int last_Line_Start_Index = temp_Data.LastIndexOf('\n');
temp_Data = temp_Data.Substring(0, last_Line_Start_Index);
//写入中间数据文件
string temp = "";
StreamWriter sw = new StreamWriter("test.txt");
sw.Write(temp_Data);
sw.Close();
//检测是否是6的倍数,每个数据集在文件中应该为6行
if ( file_Lines_Count % 6 != 0)
{
MessageBox.Show("File Error!");
return;
}
//通过文件行数来计算数据集的数量
group_Counts = file_Lines_Count / 6;
StreamReader sr = new StreamReader("test.txt");
for (int i = 0; i < group_Counts; i++)
{
data_Set_Block temp_Set;
//奇数行为提示信息,不需要进行处理,仅对偶数行进行处理
temp = sr.ReadLine();
temp = sr.ReadLine();
//提取d和c的字符串
string[] blocks = temp.Split(",");
string d_Str = blocks[0].Split("*")[1];
string c_Str = blocks[1].Split(" ").Last();
//去掉结尾的字符
c_Str = c_Str.Substring(0, c_Str.Length - 1);
//将d和c的字符串转为整型
int temp_d = Convert.ToInt32(d_Str);
int temp_c = Convert.ToInt32(c_Str);
//初始化当前数据集
temp_Set = new data_Set_Block(temp_d, temp_c );
//读取profit行的字符串
temp = sr.ReadLine();
temp = sr.ReadLine();
//切割profit行字符串
temp = temp.Substring(0, temp.Length - 1);
string[] profit_Array_Str = temp.Split(",");
//读取weight行的字符串
temp = sr.ReadLine();
temp = sr.ReadLine();
//切割weight行字符串
temp = temp.Substring(0, temp.Length - 1);
string[] weight_Array_Str = temp.Split(",");
//初始化profit和weight数组
int[] profit_Array = new int[profit_Array_Str.Length];
int[] weight_Array = new int[weight_Array_Str.Length];
for (int j = 0; j < profit_Array_Str.Length; j++)
{
//对应转换
profit_Array[j] = Convert.ToInt32(profit_Array_Str[j]);
weight_Array[j] = Convert.ToInt32(weight_Array_Str[j]);
}
//初始化数据集的profit和weight数组
temp_Set.init_Item_Sets(profit_Array, weight_Array);
//加入数据集列表中
data_Sets.Add(temp_Set);
//在listbox中添加当前数据集选项
listBox1.Items.Add(openFileDialog1.SafeFileName + "-" + i.ToString());
}
sr.Close();
//删除中间文件
File.Delete("test.txt");
}
6.总结
在本次的个人项目中,我通过对任务的逐步分解,由上倒下,逐步分解,逐步设计,通过实现基础模块,每个小程序模块完成一个确定的功能,并在这些模块之间建立必要的联系,通过模块的互相协作完成整个功能,同时各个基本模块都要遵从相对独立,功能单一,结构清晰,接口简单的原则。比如求解最优的算法的模块是基于数据项类的模块的功能实现的,而数据项类的模块是最基础的模块,是需要最先实现的,但是实现的功能很弱,并且在分析时是上层模块先给出定义,直到在分析到最底层功能时,才实现基础模块,然后再向前逐步完成较大的功能模块。
7.展示PSP
| 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|
| 计划 | 30 | 70 |
| 估计这个任务需要多少时间,并规划大致工作步骤 | 40 | 60 |
| 开发 | 660 | 1120 |
| 需求分析 (包括学习新技术) | 30 | 100 |
| 生成设计文档 | 40 | 80 |
| 设计复审 (和同事审核设计文档) | 40 | 80 |
| 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| 具体设计 | 40 | 80 |
| 具体编码 | 400 | 600 |
| 代码复审 | 30 | 40 |
| 测试(自我测试,修改代码,提交修改) | 50 | 80 |
| 报告 | 80 | 255 |
| 计算工作量 | 30 | 80 |
| 编写博客 | 120 | 140 |
| 事后总结 ,并提出过程改进计划 | 30 | 35 |
通过对计划时间和实际完成时间的对比,我发现在这次的个人项目开发中,开发过程占用的时间和预期有着很大的差别,其主要原因是,在开发过程中很多问题在经过测试后又发现了新的问题,不得不去完善自己的设计和重新编码,而且由于经验不足,Bug的数量远大于预期,也是拖累具体编码实现的完成时间的重要原因。在以后的需求分析,设计实现中要注意考虑问题更加全面一下,不要太过于片面。
8.GitHub上的任务
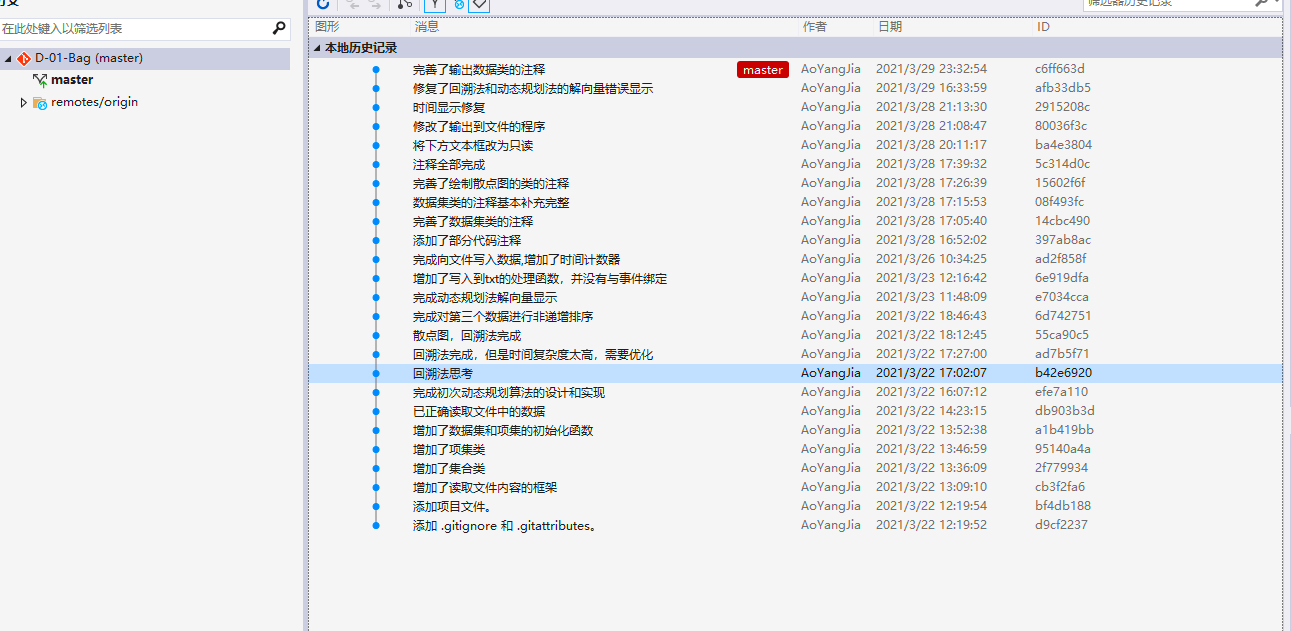
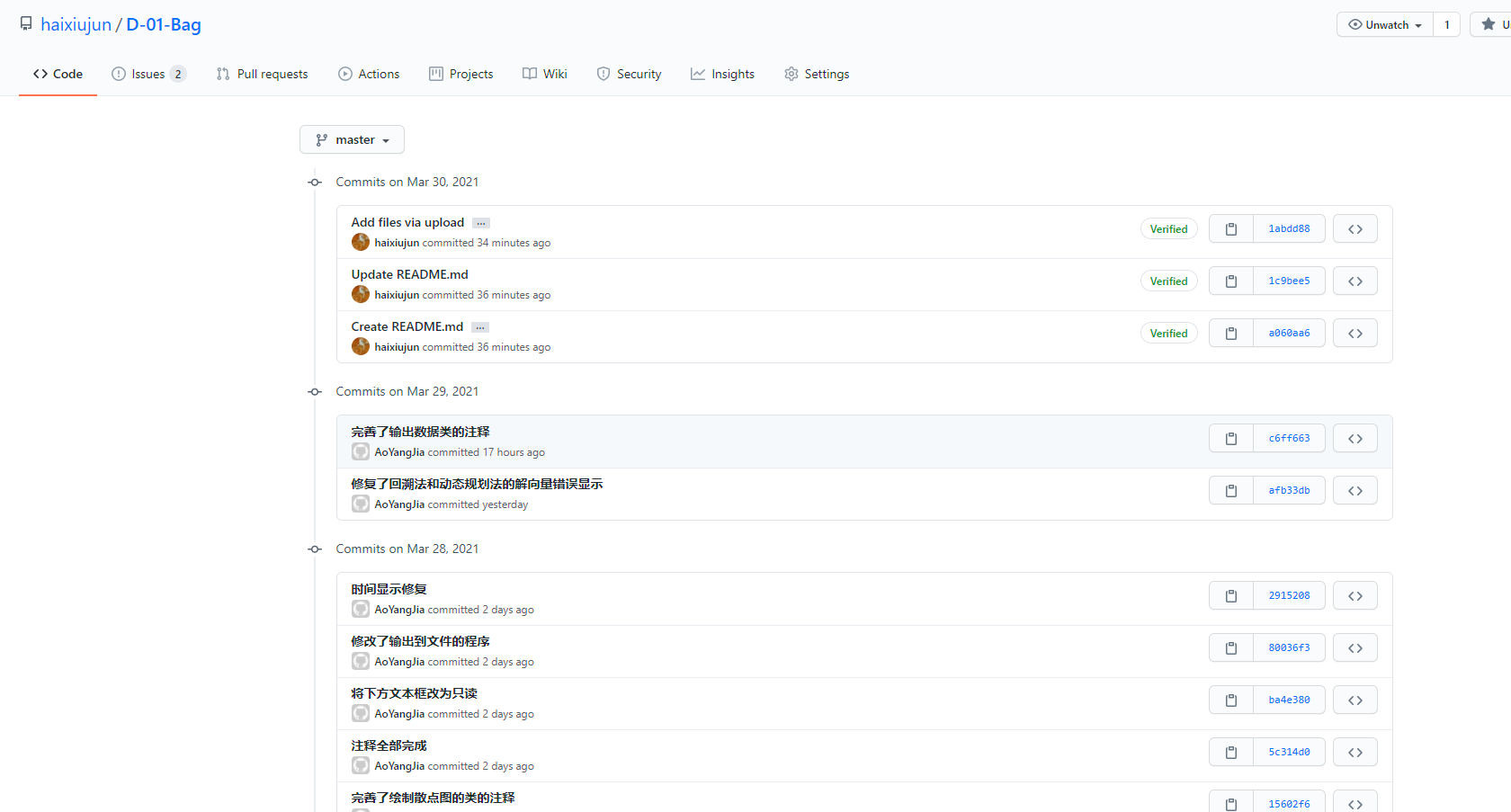
首先是commit,共28次commit(截至2021.3.30.16:07),由于一开始不会操作,因此多commit了几次:
其次是readme.md文件:

对于.gitignore文件,由于是自动生成的,自己没有太过于研究,不过应该改改就能给java项目或者python项目使用:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号