
12 2018 档案
摘要:一、认识ITIL ITIL即 IT基础架构库 (Information Technology Infrastructure Library,信息技术基础架构库)由英国政府部门CCTA(Central Computing and Telecommunications Agency)在20世纪80年代末
阅读全文
摘要:一、自动化运维与持续集成 自动化运维与Saltstack 部署基于python语言的WEB发布环境 django+uwsgi+nginx 导出excel超时问题 持续集成(Continuous integration) LAMP部署owncloud程序 二、Docker容器 docker安装(一)
阅读全文
摘要: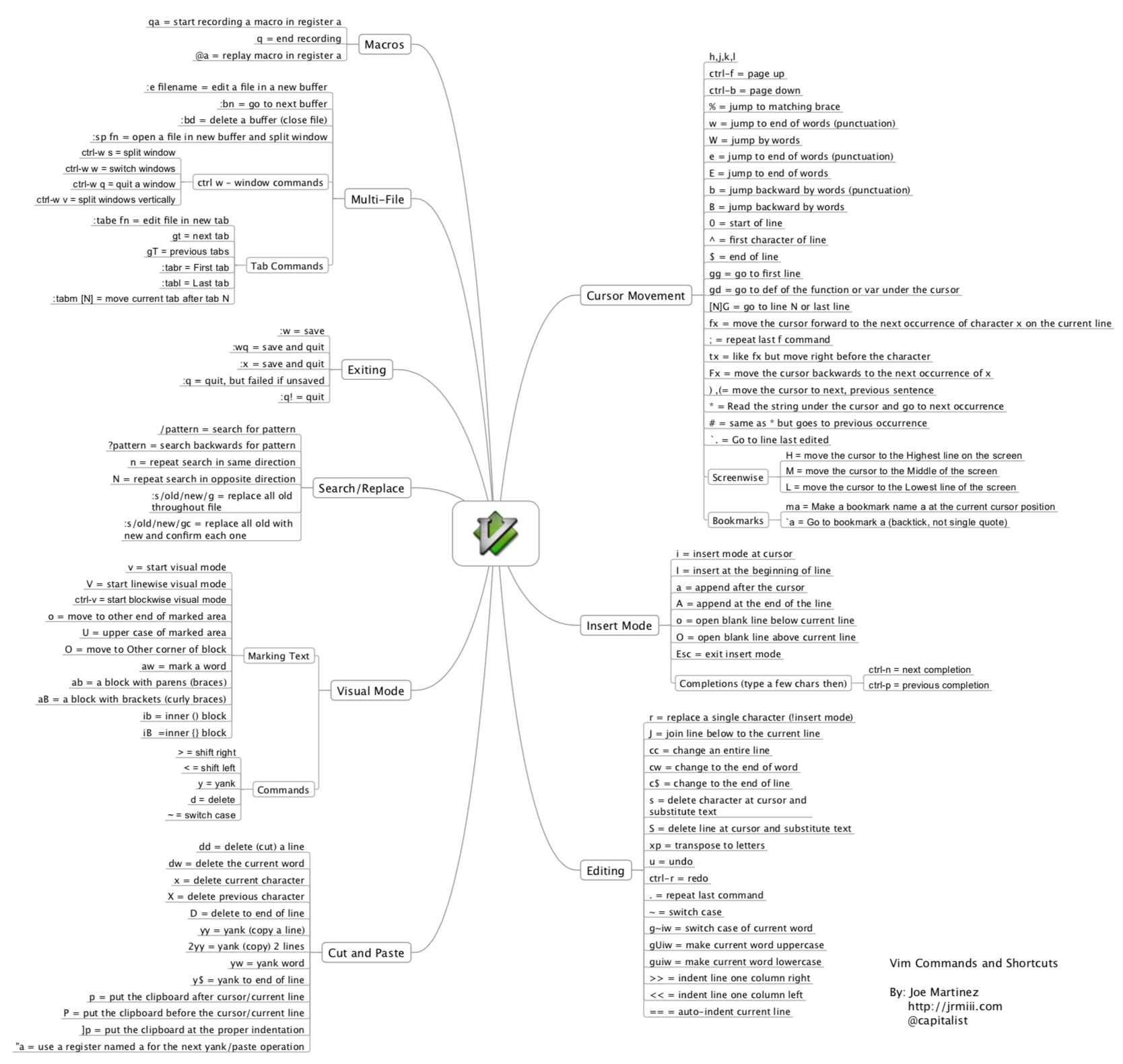
阅读全文
摘要:一、自动化运维介绍 1、自动化运维产生背景 传统的IT运维是将数据中心中的网络设备、服务器、数据库、中间件、存储、虚拟化、硬件等资源进行统一监控,当资源出现告警时,运维人员通过工具或者基于经验进行排查,找出问题并加以解决。但是,随着互联网+时代的到来,移动互联网、云计算和大数据技术得到了广泛应用,从
阅读全文
摘要:一、什么是高可用? nginx做负载均衡,能达到分发请求的目的,但是不能很好的避免单点故障。 1、nginx集群单点问题 分发器宕机怎么处理? 假如nginx服务器挂掉了,那么所有的服务也会跟着瘫痪 。 一种方法是人为监控,发现主分发器宕机后,立马登录备分发器,并给它分配虚ip。 另一种办法是用软件
阅读全文
摘要:一、集群介绍 1、传统web访问模型 (1)传统web访问模型完成一次请求的步骤 1)用户发起请求 2)服务器接受请求 3)服务器处理请求(压力最大) 4)服务器响应请求 (2)传统模型缺点 单点故障; 单台服务器资源有限(客户端则是无限的); 单台服务器处理耗时长(客户等待时间过长); (3)传统
阅读全文
摘要:一、Nginx优化思路 1、优化目的 标准情况下,软件默认的参数都是对安装软件的硬件标准(最低配置)来设置的,目前我们服务器的硬件资源远远大于要求的标准,所以为了让服务器性能更加出众,充分利用服务器的硬件资源,我们一般需要优化APP的并发数来提升服务器的性能。 总结来说:1.服务器大并发实现;2.提
阅读全文
摘要:一、Nginx虚拟主机 一个web服务器软件默认情况下只能发布一个web,因为一个web分享出去需要三个条件(IP、Port、Domain name) Nginx 虚拟主机 实现 一个web服务器软件发布多个web 。 虚拟主机 就是将一台物理服务器划分成多个“虚拟”的服务器,每个虚拟主机都可以有独
阅读全文
摘要:一、Nginx介绍 Nginx (engine x) 是一个高性能的HTTP和反向代理服务,也是一个IMAP/POP3/SMTP服务。 1、Nginx历史和特性 Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2
阅读全文
摘要:一、业务部署逻辑 1、服务器部署架构 2、软件部署文档 3、日常维护文档 二、测试 1、开发上传代码到源码系统 2、上线一测服务器(内测) 3、预发布测试(公测) 三、上线 1、产品需求确认 2、产品研发确认 3、产品测试确认 4、上线流程文档 5、跟着统计用户反馈情况
阅读全文
摘要:一、服务器选择 服务器,也称伺服器,是提供计算服务的设备。现在可选择的服务器主要分为两种:物理服务器和云服务器。 1、物理服务器 物理服务器的构成包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面
阅读全文
摘要:1、接触过几种爬虫模块 urllib、requests这两种爬虫模块。 2、robots协议是什么? 它就是一个防君子不防小人的协议,网站有一些数据不想被爬虫程序爬取,可以编写robots协议文件,明确指明哪些内容可以爬取哪些不可以爬取。 requests模块中并没有使用硬性的语法对该协议进行生效操
阅读全文
摘要:需求:爬取的是基于文字的网易新闻数据(国内、国际、军事、航空)。 基于Scrapy框架代码实现数据爬取后,再将当前项目修改为基于RedisSpider的分布式爬虫形式。 一、基于Scrapy框架数据爬取实现 1、项目和爬虫文件创建 2、爬虫文件编写——解析新闻首页获取四个板块的url 执行爬虫文件,
阅读全文
摘要:一、分布式爬虫介绍 分布式爬虫概念:多台机器上执行同一个爬虫程序,实现网站数据的分布爬取。 1、原生的Scrapy无法实现分布式爬虫的原因? 调度器无法在多台机器间共享 :因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls列表中的url。 管道无法
阅读全文
摘要:针对问题:如果想对某一个网站的全站数据进行爬取,该如何处理? 解决方案: 1. 手动请求的发送:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法) 2. CrawlSpider:基于CrawlSpider的自动爬取进行实现(更加简洁和高效) 一、Cra
阅读全文
摘要:一、Scrapy的日志等级 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息。 1、日志等级(信息种类) ERROR:错误 WARNING:警告 INFO:一般信息 DEBUG:调试信息(默认) 2、设置日志信息指定输出 在sett
阅读全文
摘要:Cookie 是在 HTTP 协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web 服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息。无论何时用户链接到服务器,Web 站点都可以访问 Cookie 信息cookie需要个人用户登录网站。 场景需求
阅读全文
摘要:一、介绍 持久化存储操作分为两类: 磁盘文件 和 数据库 。 而磁盘文件存储方式又分为: 基于终端指令 和 基于管道 二、基于终端指令的持久化存储 Scrapy是通过 scrapy 命令行工具进行控制的。 这里我们称之为 “Scrapy tool” 以用来和子命令进行区分。 对于子命令,我们称为 “
阅读全文
