
rest-framework框架——APIView和序列化组件
一、快速实例
http://www.cnblogs.com/yuanchenqi/articles/8719520.html


restful协议 ---- 一切皆是资源,操作只是请求方式 ----book表增删改查 /books/ books /books/add/ addbook /books/(\d+)/change/ changebook /books/(\d+)/delete/ delbook ----book表增删改查 url里面不能出现动词!! /books/ -----get books ----- 返回当前所有数据 /books/ -----post books ----- 返回提交数据 /books/(\d+)-----get bookdetail ----- 返回当前查看的单条数据 /books/(\d+)-----put bookdetail ----- 返回更新数据 /books/(\d+)-----delete bookdetail ----- 返回空 http://www.cnblogs.com/yuanchenqi/articles/8719520.html http://www.django-rest-framework.org/tutorial/quickstart/#quickstart class Books(View): def get(self,request): pass # 查看所有书籍 def post(self,request): pass # 添加书籍 class BooksDetail(View): def get(self,request,id): pass # 查看具体书籍 def put(self,request,id): pass # 更新某本书籍 def delete(self,request,id): pass # 删除某本书籍 http://www.django-rest-framework.org/tutorial/quickstart/#quickstart restframework(Django) app pip install django pip install djangorestframework ----针对数据:json (1)Django的原生request: 浏览器 ------------- 服务器 "GET url?a=1&b=2 http/1.1\r\user_agent:Google\r\ncontentType:urlencoded\r\n\r\n" "POST url http/1.1\r\user_agent:Google\r\ncontentType:urlencoded\r\n\r\na=1&b=2" request.body: a=1&b=2 request.POST: if contentType:urlencoded: a=1&b=2----->{"a":1,"b":2} (2)restframework 下的APIView: (3) class PublishSerializers(serializers.Serializer): name=serializers.CharField() email=serializers.CharField() PublishSerializers(queryset,many=true) PublishSerializers(model_obj) --------------------------- 总结: 1 reuqest类----源码 2 restframework 下的APIView--源码 url(r'^books/$', views.BookView.as_view(),name="books")# View下的view books/一旦被访问: view(request) ------APIView: dispatch() 3 def dispatch(): 构建request对象 self.request=Request(request) self.request._request self.request.GET # get self.request.data # POST PUT 分发----if get请求: if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed response = handler(request, *args, **kwargs) # self.get(request, *args, **kwargs) return response 4 序列化类 # from django.core import serializers # ret=serializers.serialize("json",publish_list) restframework下的序列类 BookModelSerializers 将queryset或者model对象序列成一json数据 bs=BookModelSerializers(book_list,many=True,context={'request': request}) bs=BookModelSerializers(book,context={'request': request}) 还可以做校验数据,json-------》queryset/model-->记录 bs=BookModelSerializers(data=request.data) if bs.is_valid(): print(bs.validated_data) bs.save() # 重写create方法 5 操作数据: 以Book表为例 class BookView(APIView): # 查看所有书籍 def get(self,request): book_list=Book.objects.all() bs=BookModelSerializers(book_list,many=True,context={'request': request}) return Response(bs.data) # 添加一本书籍 def post(self,request): # post请求的数据 bs=BookModelSerializers(data=request.data) if bs.is_valid(): print(bs.validated_data) bs.save()# create方法 return Response(bs.data) else: return Response(bs.errors) class BookDetailView(APIView): # 查看一本书籍 def get(self,request,id): book=Book.objects.filter(pk=id).first() bs=BookModelSerializers(book,context={'request': request}) return Response(bs.data) # 更新一本书籍 def put(self,request,id): book=Book.objects.filter(pk=id).first() bs=BookModelSerializers(book,data=request.data) if bs.is_valid(): bs.save() return Response(bs.data) else: return Response(bs.errors) # 删除某一本书籍 def delete(self,request,id): Book.objects.filter(pk=id).delete() return Response() restframework 1 APIView 2 序列组件 3 视图、 4 组件(认证权限频率) 5 数据解析器 6 分页和Response
1、准备模型和路由
models.py:
from django.db import models
# Create your models here.
class User(models.Model):
name = models.CharField(max_length=32)
pwd = models.CharField(max_length=32)
type_choice = ((1, "普通用户"), (2, "VIP"), (3, "SVIP"))
user_type = models.IntegerField(choices=type_choice, default=1)
class Token(models.Model):
user = models.OneToOneField("User", on_delete=models.CASCADE)
token = models.CharField(max_length=128)
def __str__(self):
return self.token
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.IntegerField()
pub_date = models.DateField()
publish = models.ForeignKey("Publish", on_delete=models.CASCADE)
authors = models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
def __str__(self):
return self.name
urls.py:
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('publishes/', views.PublishView.as_view())
]
2、安装djangorestframework
pip install djangorestframework
3、添加'rest_framework'到我的settings.py中
INSTALLED_APPS = ( ... 'rest_framework', )
二、restframework下的APIView
1、Django的原生request
class PublishView(View):
def get(self, request):
print('get', request.GET)
return HttpResponse('123')
def post(self, request):
print('post', request.POST)
print('body', request.body)
print(type(request))
return HttpResponse('POST')
(1)request.GET
访问地址http://127.0.0.1:8000/publishes/?a=3&c=7 ,打印得到get请求数据:<QueryDict: {'a': ['3'], 'c': ['7']}>。get请求类似形式如下:
"GET url?a=1&b=2 http/1.1\r\user_agent:Google\r\ncontentType:urlencoded\r\n\r\n"
(2)request.POST和request.body
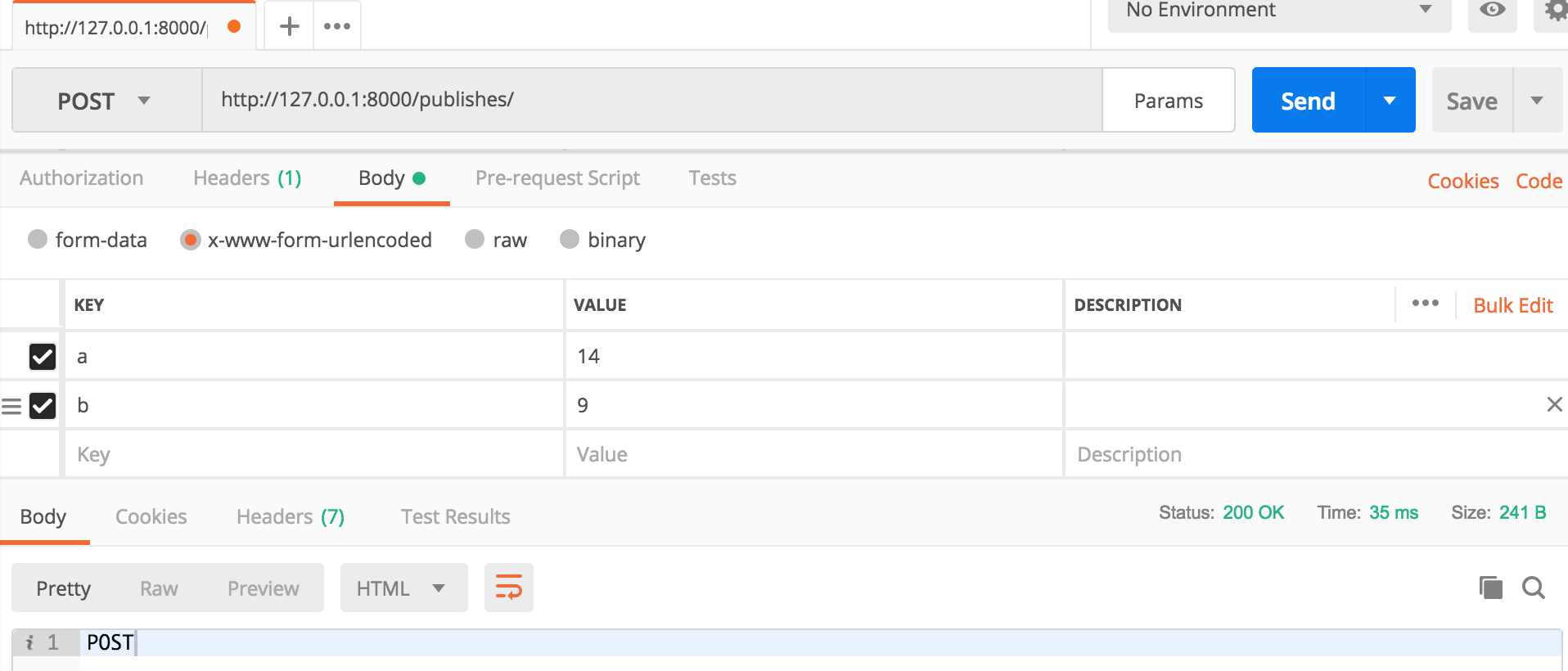
在Postman提交post请求,打印结果如下所示:
post <QueryDict: {'a': ['14'], 'b': ['9']}>
body b'a=14&b=9'
body放的是原数据,即报文,没有做任何解析。
post会帮忙做contentType是否是urlencoded的判断,如果是的会帮忙将 a=1&b=2 转化为 {"a":1,"b":2} 。post请求类似形式如下:
"POST url http/1.1\r\user_agent:Google\r\ncontentType:urlencoded\r\n\r\na=1&b=2"
(3)打印type(request)分析源码
打印得到<class 'django.core.handlers.wsgi.WSGIRequest'>。可以引入WSGIRequest来查看源码:
from django.core.handlers.wsgi import WSGIRequest
关于post源码如下所示:
class WSGIRequest(HttpRequest):
def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
def _set_post(self, post):
self._post = post
POST = property(_get_post, _set_post)
处理请求的多种可能:
def _load_post_and_files(self):
"""Populate self._post and self._files if the content-type is a form type"""
if self.method != 'POST':
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
return
if self._read_started and not hasattr(self, '_body'):
self._mark_post_parse_error()
return
if self.content_type == 'multipart/form-data':...
elif self.content_type == 'application/x-www-form-urlencoded':
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
如果content_type是urlencoded,post里面才会有QueryDict,将body里的内容做成字典的形式。
如果content_type不是form-data也不是urlencoded,则QueryDict里没有值,一个空的字典。
2、引入APIView并分析源码
from rest_framework.views import APIView
进入rest_framework/view.py中查看APIView的源码:
(1)APIView继承的是django的View类
class APIView(View):
@classmethod
def as_view(cls, **initkwargs):
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):...
view = super(APIView, cls).as_view(**initkwargs) # 执行父类View里的as_view方法,返回view
return csrf_exempt(view) # 返回的依然是View中的view方法
因此访问publishes/地址后,执行views.PublishView.as_view(),返回的是view方法。VIew.view方法执行返回dispatch(),在这里优先执行子类的dispatch,因此APIView.dispatch(request)执行。
(2)APIView里的dispatch方法
def initialize_request(self, request, *args, **kwargs):
parser_context = self.get_parser_context(request)
# 实例化一个Request类的对象
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
# 用initialize将旧request构建为一个新的request
request = self.initialize_request(request, *args, **kwargs)
可以看到在dispatch中,使用initialize方法将旧的request构建为了一个新的request。在initialize_request中,返回实例化的Request类对象。
(3)观察Request类实例化时对request进行的操作
class Request(object): def __init__(self, request, parsers=None, authenticators=None, negotiator=None, parser_context=None): self._request = request self._data = Empty self._files = Empty self._full_data = Empty # 默认为空 @property def data(self): if not _hasattr(self, '_full_data'): self._load_data_and_files() return self._full_data def _load_data_and_files(self): """ Parses the request content into `self.data`. """ if not _hasattr(self, '_data'): self._data, self._files = self._parse() if self._files: self._full_data = self._data.copy() self._full_data.update(self._files) else: self._full_data = self._data # if a form media type, copy data & files refs to the underlying # http request so that closable objects are handled appropriately. if is_form_media_type(self.content_type): self._request._post = self.POST self._request._files = self.FILES def _parse(self): """ Parse the request content, returning a two-tuple of (data, files) May raise an `UnsupportedMediaType`, or `ParseError` exception. """ media_type = self.content_type try: stream = self.stream except RawPostDataException: if not hasattr(self._request, '_post'): raise # If request.POST has been accessed in middleware, and a method='POST' # request was made with 'multipart/form-data', then the request stream # will already have been exhausted. if self._supports_form_parsing(): return (self._request.POST, self._request.FILES) stream = None if stream is None or media_type is None: if media_type and is_form_media_type(media_type): empty_data = QueryDict('', encoding=self._request._encoding) else: empty_data = {} empty_files = MultiValueDict() return (empty_data, empty_files) parser = self.negotiator.select_parser(self, self.parsers) if not parser: raise exceptions.UnsupportedMediaType(media_type) try: parsed = parser.parse(stream, media_type, self.parser_context) except Exception: # If we get an exception during parsing, fill in empty data and # re-raise. Ensures we don't simply repeat the error when # attempting to render the browsable renderer response, or when # logging the request or similar. self._data = QueryDict('', encoding=self._request._encoding) self._files = MultiValueDict() self._full_data = self._data raise # Parser classes may return the raw data, or a # DataAndFiles object. Unpack the result as required. try: return (parsed.data, parsed.files) except AttributeError: empty_files = MultiValueDict() return (parsed, empty_files)
可以看到最终是通过_parse方法,进行解析器解析。
3、利用新的request取数据
class PublishView(APIView):
def get(self, request):
print('request.data', request.data)
print('request.data type', type(request.data))
print('request._requet.GET', request._request.GET)
print('request.GET', request.GET)
return HttpResponse('123')
def post(self, request):
# 原生request支持的操作
# print('post', request.POST)
# print('body', request.body)
# print(type(request))
from django.core.handlers.wsgi import WSGIRequest
# 新的request支持的操作
print("request.data", request.data)
print("request.data type", type(request.data))
return HttpResponse('POST')
(1)打印Postman发送的json格式POST请求

控制台输出如下:
request.data {'name': 'yuan', 'email': '123@qq.com'}
request.data type <class 'dict'>
(2)打印Postman发送的urlencoded的POST请求
控制台输出如下:
request.data <QueryDict: {'a': ['14'], 'b': ['9']}>
request.data type <class 'django.http.request.QueryDict'>
(3)打印Postman发送的get请求
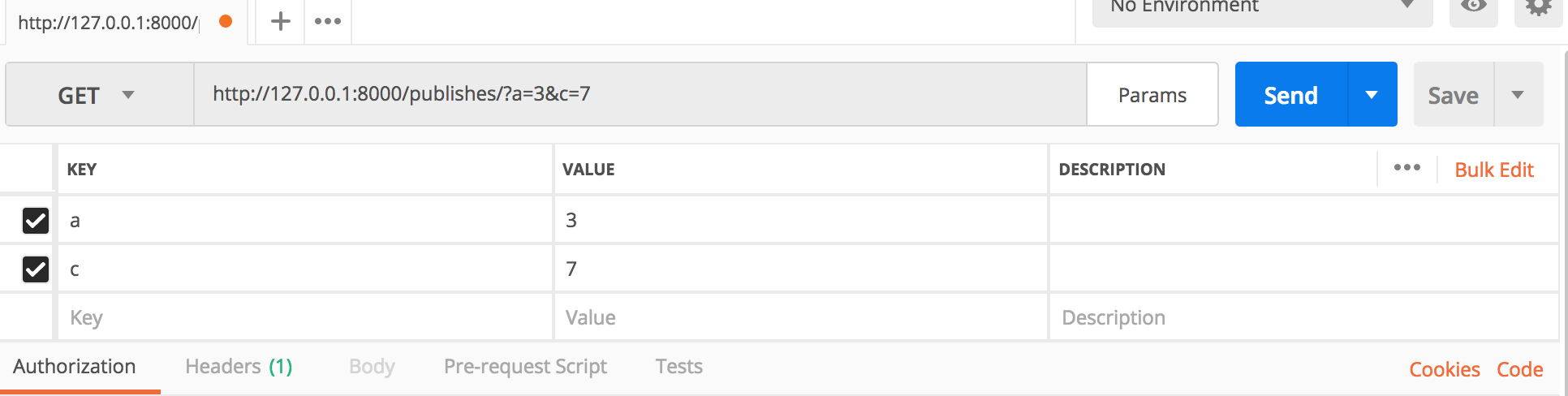
控制台输出如下:
request.data <QueryDict: {}>
request.data type <class 'django.http.request.QueryDict'>
request._requet.GET <QueryDict: {'a': ['3'], 'c': ['7']}>
request.GET <QueryDict: {'a': ['3'], 'c': ['7']}>
说明只处理了POST请求的request.data,get请求获取数据必须通过request._request.GET,rest为了方便用户使用,也为request.GET做了重新赋值,因此也可以使用requet.GET获取数据。
request.body只放请求体里的数据,get请求没有请求体,因此输出的是<QueryDict: {}>。
三、序列化
python中的json包主要提供了dump,load来实现dict与字符串之间的序列化与反序列化。
但是json包不能序列化django的models里面的对象实例。
1、序列化方式一:将QuerySet对象转化为数组套字典
from django.shortcuts import render, HttpResponse
from django.views import View
from .models import Publish
import json
class PublishView(View):
def get(self, request):
# QuerySet对象不能进行json序列化
# 方式1:values(*field):调用者是queryset对象,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
# 再使用list()方法强转为列表,组成列表里面放字典的数据结构
publish_list = list(Publish.objects.all().values("name", "email"))
return HttpResponse(json.dumps(publish_list))
def post(self, request):
pass
注意:
(1)values(*field):
调用者是queryset对象,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列:
<QuerySet [{'name': '橘子出版社', 'email': '456@qq.com'}, {'name': '苹果出版社', 'email': '123@qq.com'}]>
(2)list():
将序列强行转化为数组:
[{'name': '橘子出版社', 'email': '456@qq.com'}, {'name': '苹果出版社', 'email': '123@qq.com'}]
(3)json.dumps():
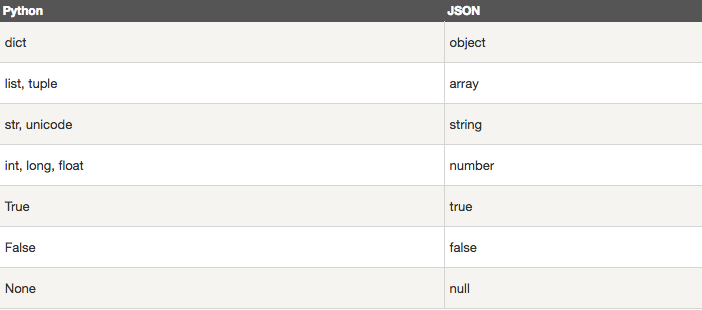
json.dumps 用于将 Python 对象编码成 JSON 字符串。以下是python 原始类型向 json 类型的转化对照表:
2、序列化方式二:model_to_dict(obj)
(1)循环QuerySet构建可序列化数据结构
from django.views import View
from .models import Publish
import json
class PublishView(View):
def get(self, request):
# QuerySet对象不能进行json序列化
# 方式2:
publish_list = Publish.objects.all()
temp = []
for obj in publish_list:
temp.append({
"name": obj.name,
"name": obj.email
})
print(temp) # [{'name': '456@qq.com'}, {'name': '123@qq.com'}]
return HttpResponse(json.dumps(temp))
def post(self, request):
pass
这样写的问题是有多少字段就要加多少个字段,而且如果不知道是哪张表或者有哪些字段,就无法构建数据。
(2)引入model_to_dict完成改写
model_to_dict是用于将model对象转换为字典的方法。
from django.views import View
from .models import Publish
import json
class PublishView(View):
def get(self, request):
# QuerySet对象不能进行json序列化
# 方式2:
from django.forms.models import model_to_dict
publish_list = Publish.objects.all()
temp = []
for obj in publish_list:
temp.append(model_to_dict(obj))
print(temp) # [{'name': '456@qq.com'}, {'name': '123@qq.com'}]
return HttpResponse(json.dumps(temp))
(3)测试理解model_to_dict方法
在pycharm的python console测试:
>>>from django.forms.models import model_to_dict
>>>from app01 import models
>>>print(models)
<module 'app01.models' from '/Users/hqs/PycharmProjects/restDemo/app01/models.py'>
>>>obj = models.Publish.objects.all()
>>>print(obj)
<QuerySet [<Publish: 橘子出版社>, <Publish: 苹果出版社>]>
>>>obj = models.Publish.objects.filter(pk=2).first()
>>>obj # obj是一个model对象
<Publish: 橘子出版社>
>>>model_to_dict(obj)
{'id': 2, 'name': '橘子出版社', 'email': '456@qq.com'}
由此可见有几个字段就转化为几个键值对的字典。
3、序列化方式三:serializers.serizlize("json",publish_list)
serializers是django的序列化组件。
from django.views import View
from .models import Publish
import json
class PublishView(View):
def get(self, request):
# QuerySet对象不能进行json序列化
# 方式3:
from django.core import serializers
publish_list = Publish.objects.all()
ret = serializers.serialize("json", publish_list)
return HttpResponse(json.dumps(ret))
def post(self, request):
pass
注意:
(1)__init__.py中serialize函数原型
def serialize(format, queryset, **options):
"""
Serialize a queryset (or any iterator that returns database objects) using
a certain serializer.
"""
s = get_serializer(format)()
s.serialize(queryset, **options)
return s.getvalue()
传递给 serialize 方法的参数有二:一个序列化目标格式,另外一个是序列化的对象QuerySet. (事实上,第二个参数可以是任何可迭代的Django Model实例,但它很多情况下就是一个QuerySet).
(2)序列化后数据组织形式
"[{\"model\": \"app01.publish\", \"pk\": 2, \"fields\": {\"name\": \"\\u6a58\\u5b50\\u51fa\\u7248\\u793e\", \"email\": \"456@qq.com\"}}, {\"model\": \"app01.publish\", \"pk\": 3, \"fields\": {\"name\": \"\\u82f9\\u679c\\u51fa\\u7248\\u793e\", \"email\": \"123@qq.com\"}}]"
4、序列化方式四:(推荐)rest_framework serializers
from django.views import View
from .models import Publish
import json
from rest_framework import serializers
class PublishSerializers(serializers.Serializer):
"""为QuerySet做序列化"""
name = serializers.CharField()
email = serializers.CharField()
class PublishView(View):
def get(self, request):
# 方式4:
publish_list = Publish.objects.all()
ret = PublishSerializers(publish_list, many=True) # 描述是model对象还是QuerySet True:queryset
return HttpResponse(json.dumps(ret))
def post(self, request):
pass
注意:
(1)分析继承了Serializers的子类PublishSerializers
>>>from app01.views import PublishSerializers
>>>publish_list = models.Publish.objects.all()
>>>PublishSerializers(publish_list, many=True) # 描述是model对象还是QuerySet
PublishSerializers(<QuerySet [<Publish: 橘子出版社>, <Publish: 苹果出版社>]>, many=True):
name = CharField()
email = CharField()
>>>ps = PublishSerializers(publish_list, many=True)
>>>ps.data
[OrderedDict([('name', '橘子出版社'), ('email', '456@qq.com')]), OrderedDict([('name', '苹果出版社'), ('email', '123@qq.com')])]
(2)Serializer是对QuerySet和model对象做序列化的
在序列化时,第一个参数传递要序列化的对象,第二个参数many是向组件声明到底是model对象还是QuerySet。
many=True:QuerySet many=False:model对象(默认)
四、restframe序列化
1、序列化get请求
from django.shortcuts import render, HttpResponse
from django.views import View
from .models import *
import json
from rest_framework import serializers
from rest_framework.views import APIView
from rest_framework.response import Response
class BookSerializers(serializers.Serializer):
title = serializers.CharField(max_length=32)
price = serializers.IntegerField()
pub_date = serializers.DateField()
publish = serializers.CharField(source="publish.name")
# authors = serializers.CharField(source="authors.all")
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.name)
return temp
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
bs = BookSerializers(book_list, many=True) # 序列化结果
# return HttpResponse(bs.data)
return Response(bs.data)
def post(self):
pass
注意:
(1)一对多、多对多字段配置source参数
class BookSerializers(serializers.Serializer):
title = serializers.CharField(max_length=32)
price = serializers.IntegerField()
pub_date = serializers.DateField()
publish = serializers.CharField(source="publish.name")
authors = serializers.CharField(source="authors.all")
配置了source='publish.name'参数后,BookSerializers在序列化时,"publish"不再是取str(obj.publish),而是取obj.publish.name。页面显示如下所示:
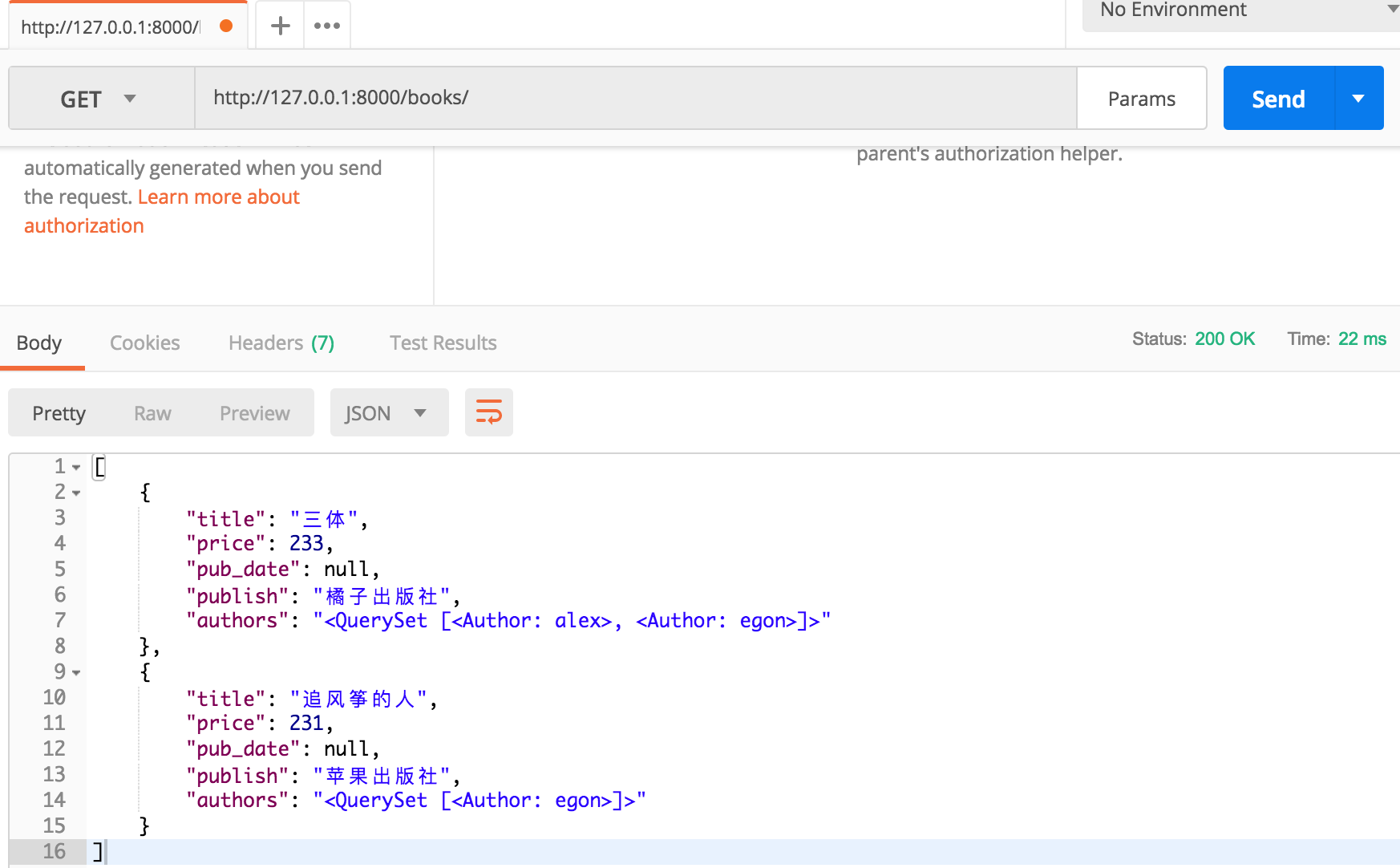
可以看到source字段在一对多字段比较好用,多对多字段显示为QuerySet,显示不够美观。
(2)引入rest_framework避免浏览器访问报错
在settings.py引入应用rest_framework:
INSTALLED_APPS = [
'django.contrib.admin',
......
'app01.apps.App01Config',
'rest_framework',
]
显示效果:

(3)针对多对多字段使用SerializerMethodField
source字段在一对多字段比较好用,多对多字段显示为QuerySet,显示不够美观。
class BookSerializers(serializers.Serializer):
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.name)
return temp
BookSerializers在序列化时,"authors"不再是取obj.authors或者obj.authors.all(),而是取get_authors(obj)的返回值。注意这个方法必须是“get_"拼接配置了SerializerMethodField的字段。显示效果如下:

2、ModelSerializer(类似ModelForm)
需要对django model 的实例进行序列化。ModelSerializer 类提供了一个捷径让你可以根据 Model 来创建 Serializer。
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
publish = serializers.CharField(source="publish.name")
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.name)
return temp
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
bs = BookModelSerializers(book_list, many=True) # 序列化结果
return Response(bs.data)
def post(self):
pass
注意:
(1)ModelSerializer 类和 Serializer 类一样,不过添加了以下功能:
- 它会基于 model 自动创建一些字段
- 它会自动生成一些验证,比如 unique_together 验证。
- 它包含简单的默认的 create() 和 update()
(2)fileds="__all__"帮忙转换所有字段
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
显示效果:
(3)给publish和authors字段做自定义配置
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
publish = serializers.CharField(source="publish.name")
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.name)
return temp
显示效果如下所示:

3、提交POST请求
BookModelSerializers也可以将json数据转为QuerySet.
class BookView(APIView):
def get(self, request):...
def post(self, request):
# POST请求的数据
bs = BookModelSerializers(data=request.data)
if bs.is_valid(): # 验证数据是否合格
print(bs.validated_data)
bs.save() # create方法
return Response(bs.data) # 当前添加的数据
else:
return Response(bs.errors)
(1)不做自定义配置情况下提交
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
在Postman提交json POST请求:
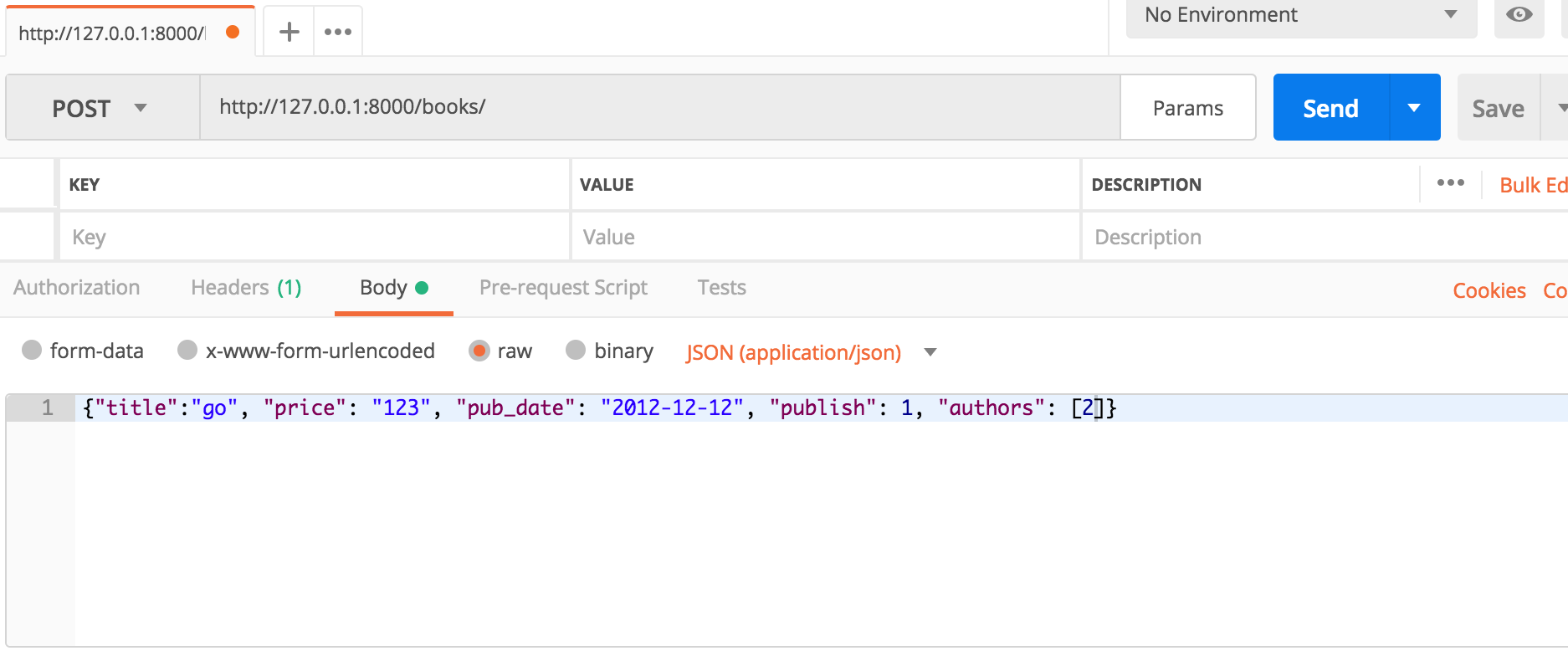
注意多对多字段一定要用列表组织数据。
(2)return Response(bs.data)返回的是当前添加数据
提交POST请求后,当前添加数据显示如下:

4、重写save中的create方法
前面提交POST请求时,将BookModelSerializers去除了自定义配置。这因为ModelSerializer的create方法不支持source的用法。因此必须还自定义一个create方法。
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
publish = serializers.CharField(source="publish.pk")
def create(self, validated_data):
print(validated_data) # {'publish': {'name': '1'}, 'title': 'go', 'price': 123, 'pub_date': datetime.date(2012, 12, 12)}
authors = validated_data['authors']
# 添加记录
book_obj = Book.objects.create(title=validated_data["title"], price=validated_data["price"],
pub_date=validated_data["pub_date"], publish_id=validated_data["publish"]["pk"])
book_obj.authors.add(*authors) # 添加多对多的方式
return book_obj
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
bs = BookModelSerializers(book_list, many=True) # 序列化结果
# return HttpResponse(bs.data)
return Response(bs.data)
def post(self, request):
# POST请求的数据
bs = BookModelSerializers(data=request.data)
if bs.is_valid(): # 验证数据是否合格
print(bs.validated_data)
bs.save() # create方法
return Response(bs.data) # 当前添加的数据
else:
return Response(bs.errors)
提交POST请求显示效果如下:

5、单条数据的GET\PUT\DELETE请求
class BookDetailView(APIView):
def get(self, request, id):
book_obj = Book.objects.filter(pk=id).first()
print(book_obj)
bs = BookModelSerializers(book_obj)
return Response(bs.data) # 查看的单条数据
def put(self, request, id):
book_obj = Book.objects.filter(pk=id).first()
bs = BookModelSerializers(book_obj, data=request.data) # 做更新操作
if bs.is_valid(): # 校验更新数据是否有问题
bs.save() # ModelSerializer类的update方法
return Response(bs.data) # 查看更新的数据
else:
return HttpResponse(bs.errors)
def delete(self, reqeust, book_id):
Book.objects.filter(pk=book_id).delete()
return Response() # 删除操作返回空
注意:
(1)配置url
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('publishes/', views.PublishView.as_view()),
re_path(r'^books/$', views.BookView.as_view()),
re_path(r'^books/(\d+)/$', views.BookDetailView.as_view())
]
(2)将BookModelSerializers迁移到新建文件夹解耦
from rest_framework import serializers
from .models import *
class BookModelSerializers(serializers.ModelSerializer):
class Meta:
# 帮忙转换没有自己写的字段
model = Book
fields = "__all__"
# publish = serializers.CharField(source="publish.pk")
# authors = serializers.SerializerMethodField()
# def get_authors(self, obj):
# temp = []
# for author in obj.authors.all():
# temp.append(author.name)
# return temp
# def create(self, validated_data):
# print(validated_data) # {'publish': {'name': '1'}, 'title': 'go', 'price': 123, 'pub_date': datetime.date(2012, 12, 12)}
# authors = validated_data['authors']
# # 添加记录
# book_obj = Book.objects.create(title=validated_data["title"], price=validated_data["price"],
# pub_date=validated_data["pub_date"], publish_id=validated_data["publish"]["pk"])
# book_obj.authors.add(*authors) # 添加多对多的方式
# return book_obj
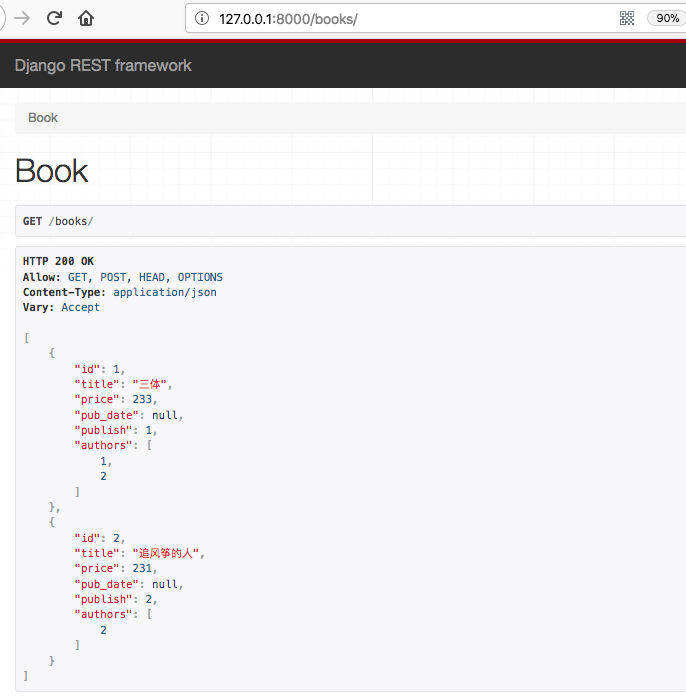
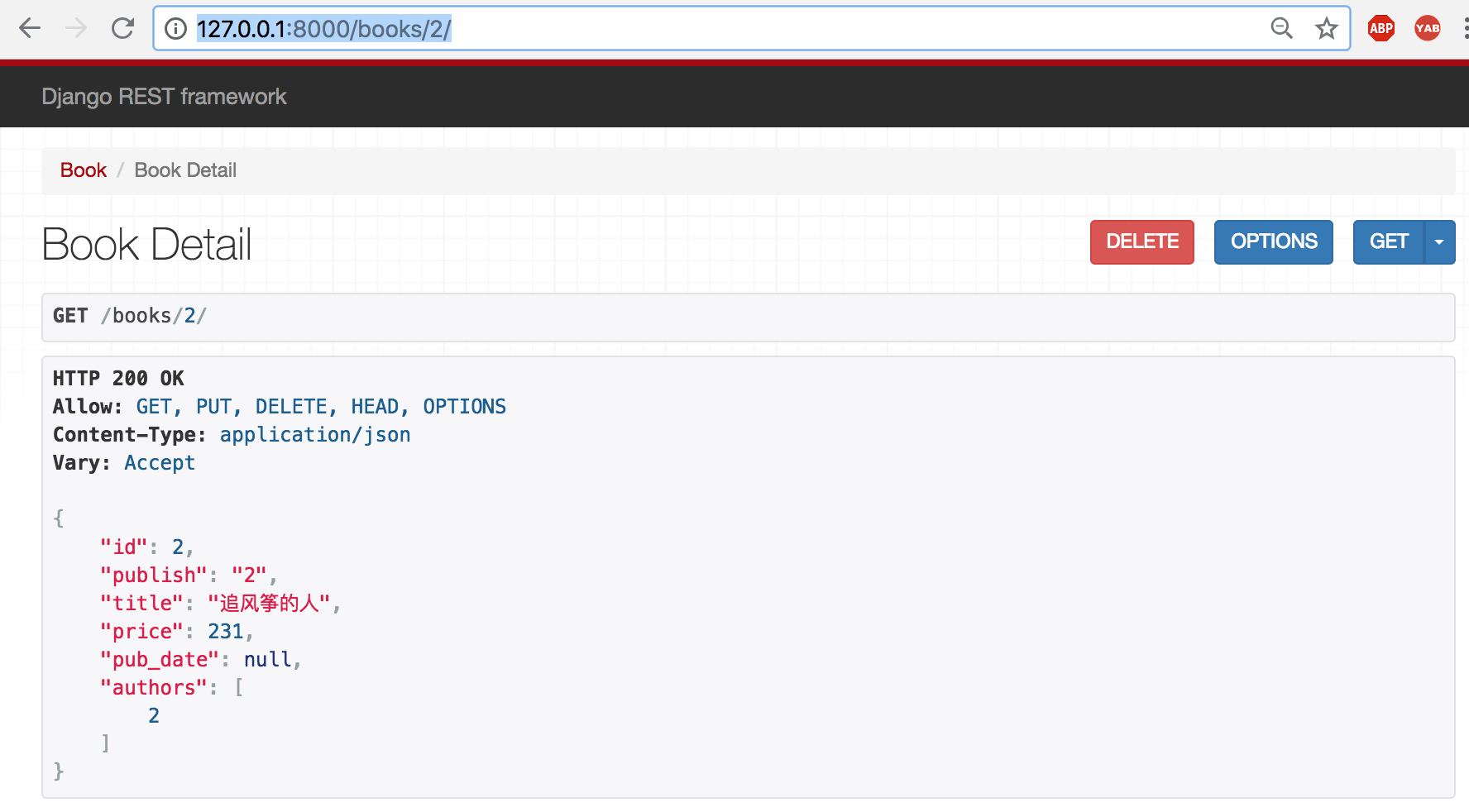
(3)/books/(\d+) —— get请求 :返回当前查看的单条数据
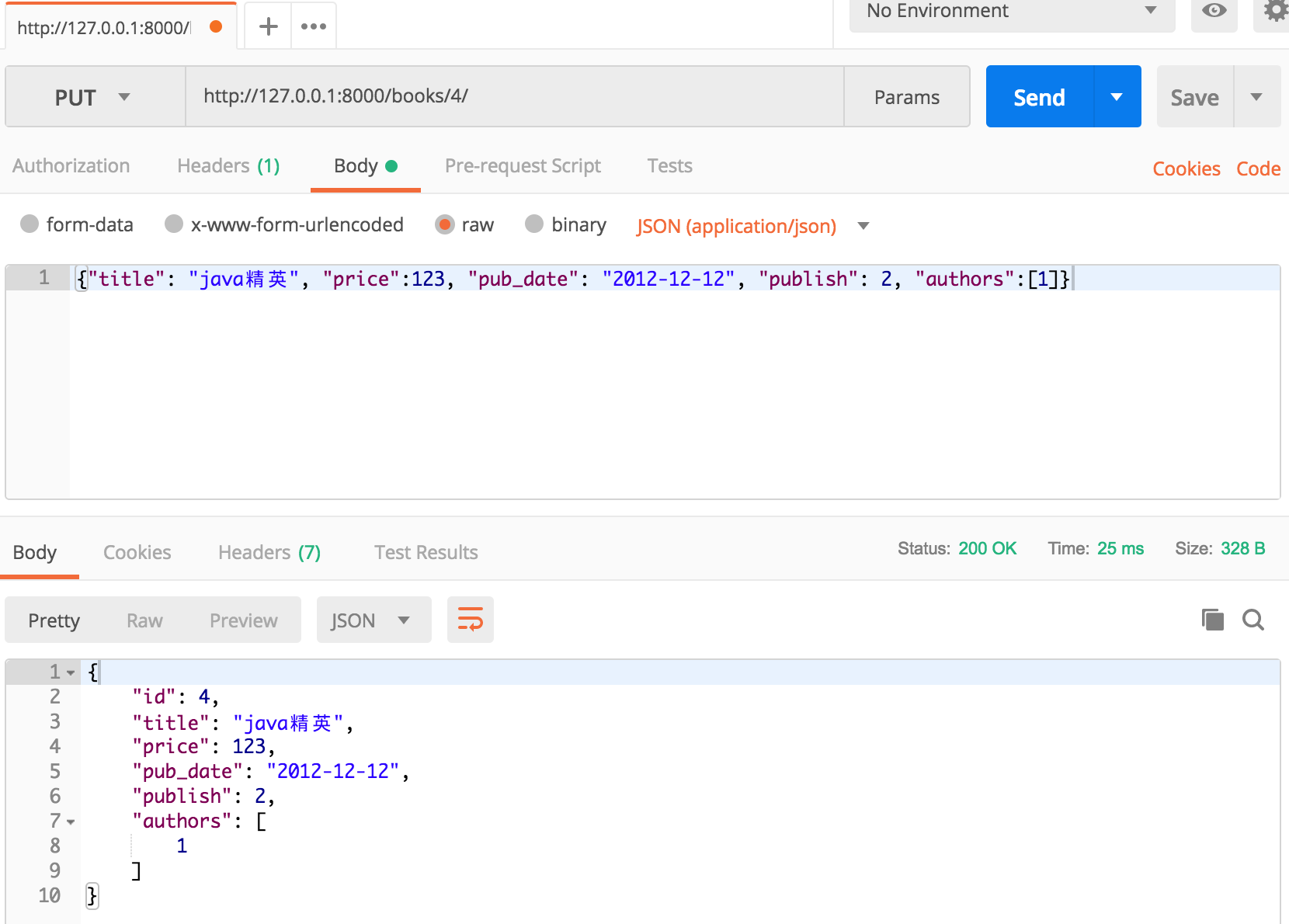
(4)/books/(\d+)——put请求:返回更新数据
(5)/book/(\d+)——delete请求:返回空
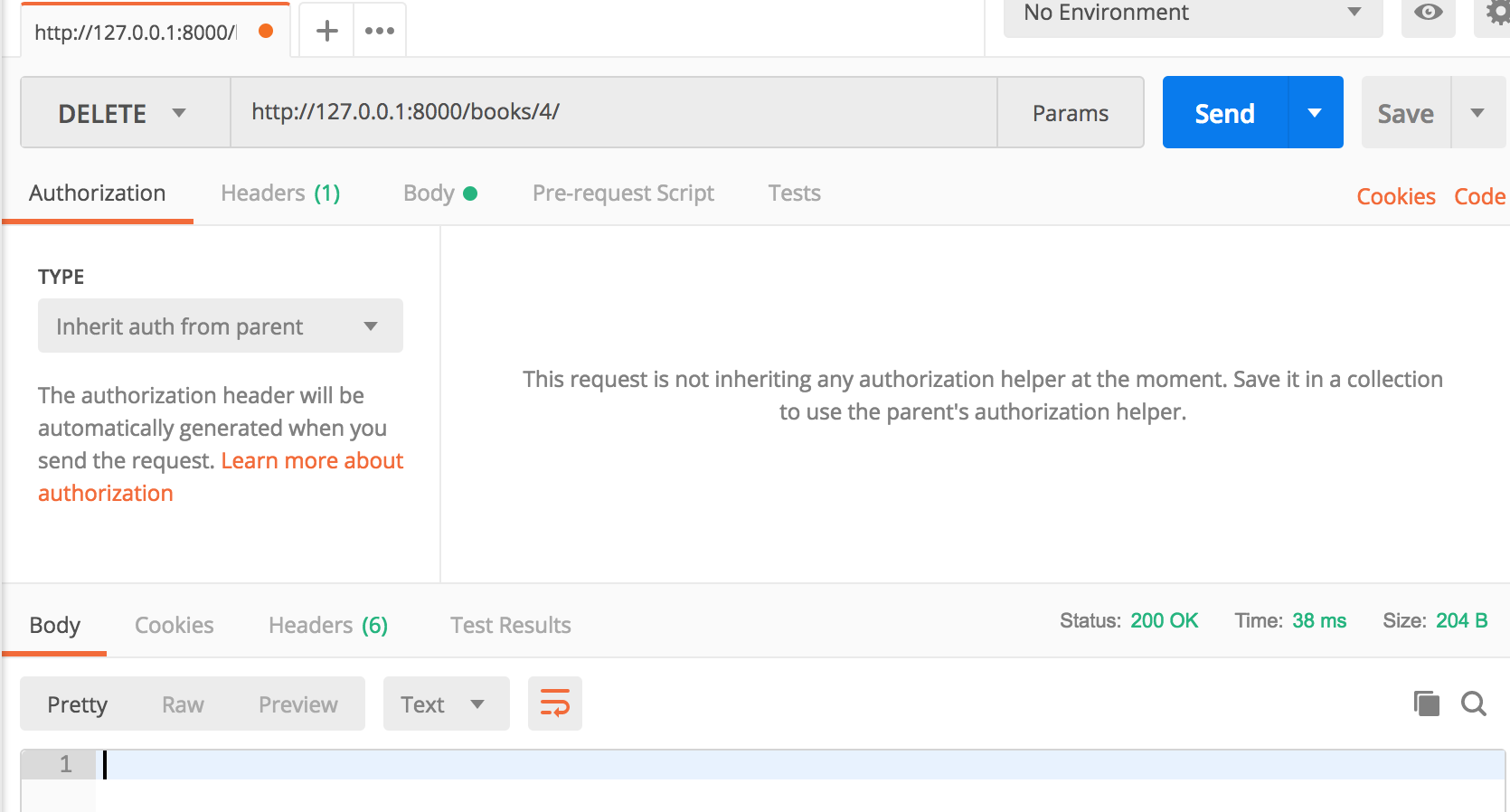
再次发送get请求可以发现id=4的这条数据已经删除了。
6、超链接API:Hyperlinked
class PublishModelSerializers(serializers.ModelSerializer):
class Meta:
model = Publish
fields = "__all__"
publish = serializers.HyperlinkedIdentityField(
view_name='detail_publish', # detail_publish:url别名
lookup_field="publish_id", # publish_id:url中(\d+)的值
lookup_url_kwarg="pk") # pk:命名分组名称
(1)urls.py配置修改:用name取别名
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^publishes/$', views.PublishView.as_view(), name="publish"),
re_path(r'^publishes/(\d+)/$', views.PublishDetailView.as_view(), name="detail_publish"),
re_path(r'^books/$', views.BookView.as_view(), name="books"),
re_path(r'^books/(\d+)/$', views.BookDetailView.as_view(), name="detail_book")
]
(2)urls.py配置修改:命名分组
命名分组就是给具有默认分组编号的组另外再给一个别名。命名分组的语法格式如下:
(?P<name>正则表达式) #name是一个合法的标识符
在这里给(\d+)做命名分组:
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^publishes/$', views.PublishView.as_view(), name="publish"),
re_path(r'^publishes/(?P<pk>\d+)/$', views.PublishDetailView.as_view(), name="detail_publish"),
re_path(r'^books/$', views.BookView.as_view(), name="books"),
re_path(r'^books/(?P<pk>\d+)/$', views.BookDetailView.as_view(), name="detail_book")
]
(3)添加context={"request": request}参数解决报错
在使用了HyperlinkedIdentityField后,要求BookModelSerializers序列化时必须添加context={"request": request}
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
bs = BookModelSerializers(book_list, many=True, context={"request": request}) # 序列化结果
# return HttpResponse(bs.data)
return Response(bs.data)
def post(self, request):
# POST请求的数据
bs = BookModelSerializers(data=request.data)
if bs.is_valid(): # 验证数据是否合格
print(bs.validated_data)
bs.save() # create方法
return Response(bs.data) # 当前添加的数据
else:
return Response(bs.errors)
class BookDetailView(APIView):
def get(self, request, pk):
book_obj = Book.objects.filter(pk=pk).first()
print(book_obj)
bs = BookModelSerializers(book_obj, context={"request": request})
return Response(bs.data) # 查看的单条数据
def put(self, request, pk):
book_obj = Book.objects.filter(pk=pk).first()
bs = BookModelSerializers(book_obj, data=request.data)
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
def delete(self, reqeust, book_id):
Book.objects.filter(pk=book_id).delete()
return Response() # 删除操作返回空
(4)测试验证
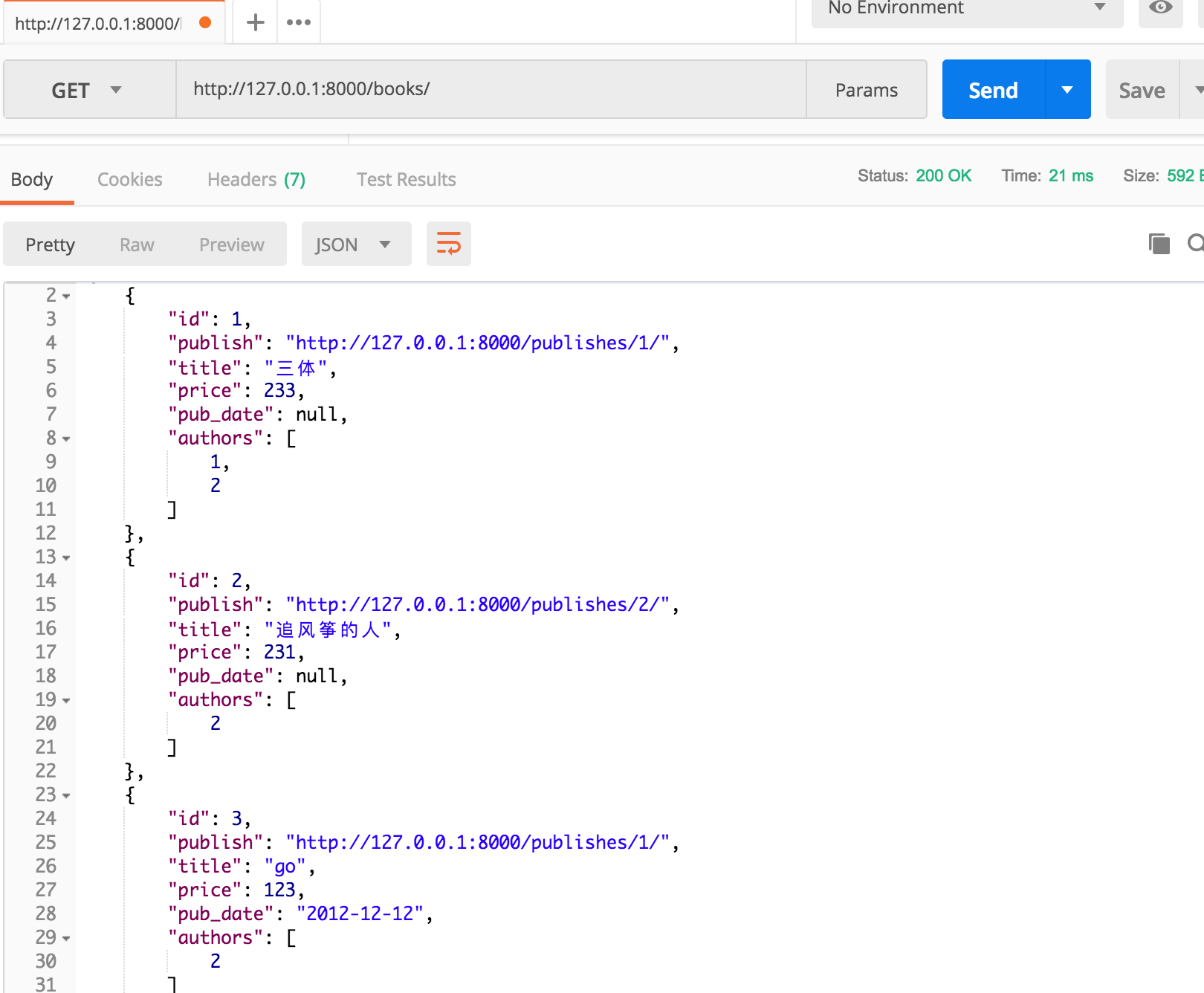
五、反序列化
接收前端传过来的json处理是由Parser解析器执行,反序列化只进行验证和保存。
当前端给DRF发post的请求的时候,前端给我们传过来的数据,要进行一些校验再保存到数据库。
这些校验以及保存工作,DRF的Serializer也给我们提供了一些方法了。首先要写反序列化用的一些字段,这些字段要跟序列化区分开。Serializer提供了.is_valid() 和.save()方法。
1、反序列化create示例
SerDemo/serializers.py文件:
class BookSerializer(serializers.Serializer): """Book序列化类,注意与models对应""" id = serializers.IntegerField(required=False) # required=False设置该字段无需校验 title = serializers.CharField(max_length=32) # ChoiceField字段处理 CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) # choice字段配置source参数,显示对应名,read_only设置只读,只在序列化时使用 category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) # 图书的类别 # write_only设置只写,只反序列化时使用 w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField( ) # 当序列化与反序列化的类型不同时,需要分别生成read_only和write_only两个字段 # 外键字段处理 publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) # 多对多字段处理(通过many字段与ForeignKey区分) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) def create(self, validated_data): # 重写save中的create方法 book_obj = Book.objects.create( title = validated_data['title'], category=validated_data['w_category'], # 注意取反序列化字段 pub_time=validated_data['pub_time'], publisher_id=validated_data['publisher_id'] ) book_obj.author.add(*validated_data['author_list']) # 添加多对多 return book_obj
SerDemo/views.py文件:
# 方式三:基于rest_framework框架实现序列化(pip install djangorestframework) from rest_framework.views import APIView from rest_framework.response import Response from .serializers import BookSerializer # 自定义序列化类 class BookView(APIView): def get(self, request): # 第一个图书对象 # book_obj = Book.objects.first() # ret = BookSerializer(book_obj) book_list = Book.objects.all() ret = BookSerializer(book_list, many=True) # 使用序列化器序列化 """ 序列化的数据保存在ret.data中 """ return Response(ret.data) """ 得出来的结果会使用Django REST framework模板,在serializers.py中定制好序列化类后,显示效果如下所示: HTTP 200 OK Allow: GET, HEAD, OPTIONS Content-Type: application/json Vary: Accept [ { "id": 1, "title": "python开发", "category": "Python", "pub_time": "2011-08-27", "publisher": { "id": 1, "title": "人民日报社" }, "author": [ { "id": 1, "name": "阿萨德" }, { "id": 2, "name": "阿加莎" } ] }, { "id": 2, "title": "go开发", "category": "Go", "pub_time": "2015-09-30", "publisher": { "id": 2, "title": "湖北日报社" }, "author": [ { "id": 2, "name": "于华吉" } ] }, { "id": 3, "title": "Linux开发", "category": "Linux", "pub_time": "2008-08-27", "publisher": { "id": 3, "title": "长江日报设" }, "author": [ { "id": 1, "name": "阿萨德" }, { "id": 3, "name": "阿迪力" } ] } ] """ def post(self, request): print(request.data) serializer = BookSerializer(data=request.data) # 序列化器校验前端传回来的数据 if serializer.is_valid(): serializer.save() # 验证成功后保存数据库 # 因为ModelSerializer的create方法不支持source的用法。因此必须还自定义一个create方法。 return Response(serializer.validated_data) # validated_data存放验证通过的数据 else: return Response(serializer.errors) # errors存放错误信息 ''' 发送post请求接口设计 POST /books/list { "title": "nodejs的使用教程", "w_category": "1", "pub_time": "2018-10-27", "publisher_id": 1, "author_list": [1,2,3] } '''
2、PATCH请求示例(更新操作)
SerDemo/serializers.py文件:
class BookSerializer(serializers.Serializer): """Book序列化类,注意与models对应""" id = serializers.IntegerField(required=False) # required=False设置该字段无需校验 title = serializers.CharField(max_length=32) # ChoiceField字段处理 CHOICES = ((1, "Python"), (2, "Go"), (3, "Linux")) # choice字段配置source参数,显示对应名,read_only设置只读,只在序列化时使用 category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) # 图书的类别 # write_only设置只写,只反序列化时使用 w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField( ) # 当序列化与反序列化的类型不同时,需要分别生成read_only和write_only两个字段 # 外键字段处理 publisher = PublisherSerializer(read_only=True) publisher_id = serializers.IntegerField(write_only=True) # 多对多字段处理(通过many字段与ForeignKey区分) author = AuthorSerializer(many=True, read_only=True) author_list = serializers.ListField(write_only=True) def create(self, validated_data): # 重写save中的create方法 book_obj = Book.objects.create( title = validated_data['title'], category=validated_data['w_category'], # 注意取反序列化字段 pub_time=validated_data['pub_time'], publisher_id=validated_data['publisher_id'] ) book_obj.author.add(*validated_data['author_list']) # 添加多对多 return book_obj def update(self, instance, validated_data): # 判断对应项是否更新,如果更新则替换 instance.title = validated_data.get('title', instance.title) instance.category = validated_data.get('category', instance.category) instance.pub_time = validated_data.get('pub_time', instance.pub_time) instance.publisher_id = validated_data.get('publisher_id', instance.publisher_id) if validated_data.get("author_list"): instance.author.set(validated_data["author_list"]) instance.save() # 保存 return instance
SerDemo/views.py文件:
class BookEditView(APIView): def get(self, request, id): """ 查看单条数据 :param request: :param id: :return: """ book_obj = Book.objects.filter(id=id).first() ret = BookSerializer(book_obj) return Response(ret.data) ''' GET /books/retrieve/3 { "id": 3, "title": "Linux开发", "category": "Linux", "pub_time": "2008-08-27", "publisher": { "id": 3, "title": "长江日报社" }, "author": [ { "id": 1, "name": "阿萨德" }, { "id": 3, "name": "阿斯达" } ] } ''' def put(self, request, id): """更新操作""" book_obj = Book.objects.filter(id=id).first() serializer = BookSerializer( book_obj, # 待更新对象 data=request.data, # 要更新的数据 partial=True # 重点:进行部分验证和更新 ) if serializer.is_valid(): serializer.save() # 保存 return Response(serializer.validated_data) # 返回验证通过的数据 else: return Response(serializer.errors) # 返回验证错误的数据
3、对字段自定义验证
如果需要对一些字段进行自定义的验证,DRF也提供了钩子方法。
(1)单个字段的验证
class BookSerializer(serializers.Serializer): """Book序列化类,注意与models对应""" id = serializers.IntegerField(required=False) # required=False设置该字段无需校验 title = serializers.CharField(max_length=32) # 代码省略 def validated_title(self, value): # 对字段进行验证:校验title字段 if "python" not in value.lower(): # 如果python不在value字段中 raise serializers.ValidationError("标题必须含有python") # 自定义错误信息 return value
在提交put请求时,如果提交{"title": “go语言开发”},没有包含python则会返回错误提示。
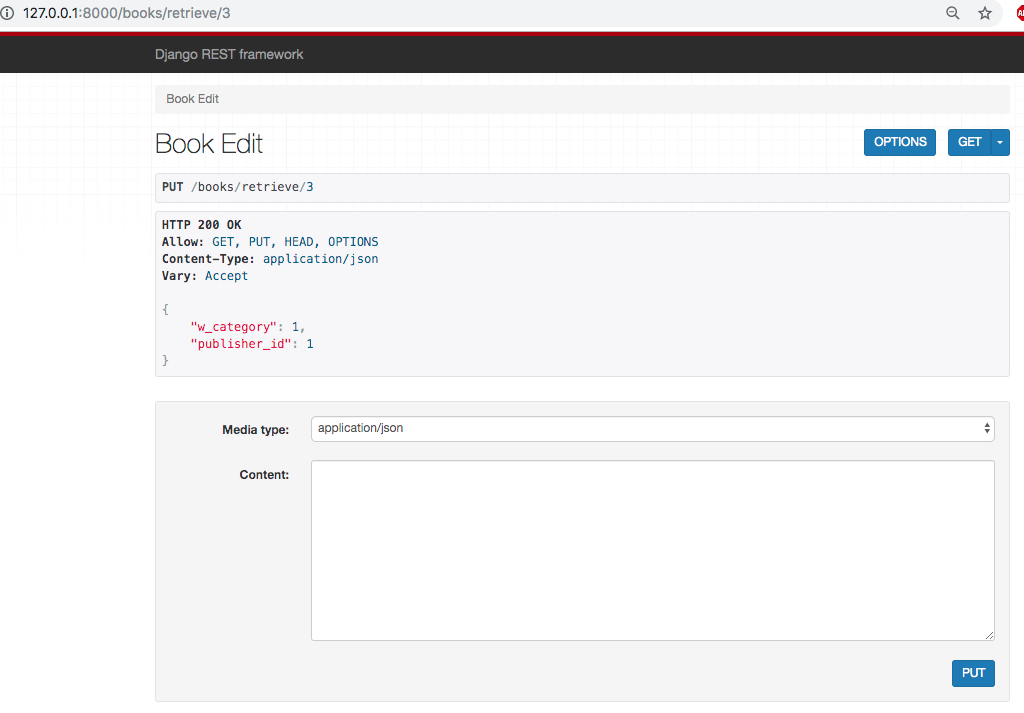
(2)多个字段的验证
class BookSerializer(serializers.Serializer): """Book序列化类,注意与models对应""" id = serializers.IntegerField(required=False) # required=False设置该字段无需校验 title = serializers.CharField(max_length=32) # 代码省略 def validate(self, attrs): # 对多个字段进行比较验证 # 执行更新操作:{"w_category": 1,"publisher_id": 1} # 注意JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来 if attrs['w_category'] == 1 and attrs['publisher_id'] == 1: # 联合校验分类和标题 return attrs else: raise serializers.ValidationError('分类以及出版社不符合要求') # 抛出异常
效果如下所示:
(3)验证器 validators
def my_validate(value): # 自定义验证器 if "fuck" in value.lower(): raise serializers.ValidationError("不能含有敏感信息") else: return value class BookSerializer(serializers.Serializer): """Book序列化类,注意与models对应""" id = serializers.IntegerField(required=False) # required=False设置该字段无需校验 title = serializers.CharField(max_length=32, validators=[my_validate]) # 添加自定义验证器 # 代码省略
此时title字段不仅有了自定义的验证器,又有了单个字段验证,如果执行一个不满足两个条件的更新请求:{"title":"fuck"}
返回结果如下所示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号