

互联网缓存架构
互联网公司在缓存架构上是区分很大的,往往是根据企业的业务量来进行选择的,可以看如下图
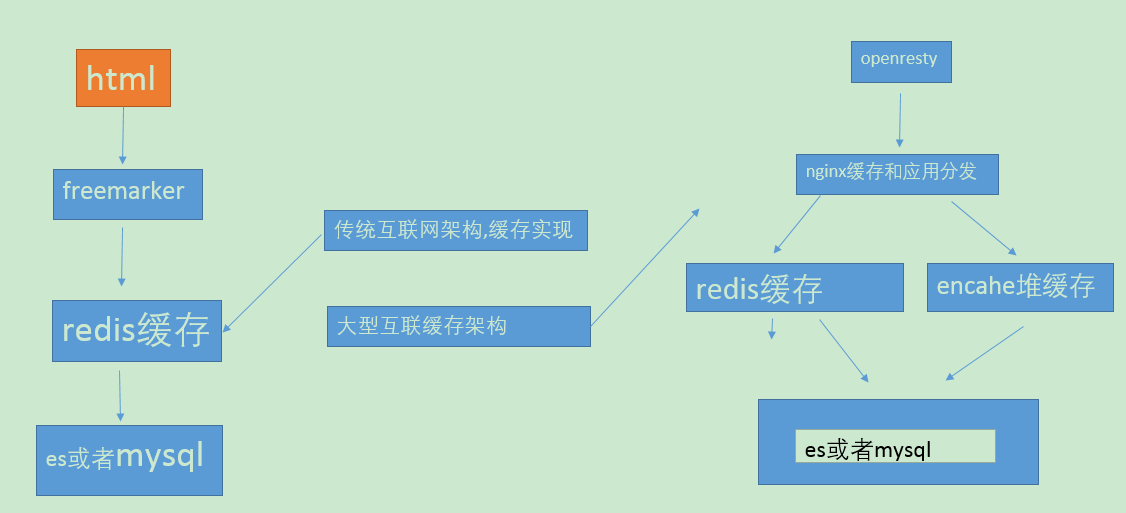
在传统的小型互联网公司,采用网页静态化技术,freemarker来加快用户的体验速度,从来来提升响应,但是如果出现了缓存血崩,缓存击穿那么对数据库将会造成很大的压力,可能导致整个架构无法使用
一 缓存击穿
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透,即使使用的es数据库,那么当大量数据进来之后还是对内容数据库压力造成很多问题
解决方案:
1.布隆过滤
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃。还有最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
补充:
Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。添加时增加计数器,删除时减少计数器。
2. 缓存空对象. 将 null 变成一个值.
也可以采用一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
二 缓存血崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
rediscluster采用的是自研的hash slot算法,而不是采用传统的缓存hash算法
,hash算法 根据根据hash将数据分配到不同的redis上,那么当其中的一个挂掉之后,就是重新进行hash计算,导致分的服务缓存地址不对,会导致很多的缓存不可以使用,就会造成缓存问题,
redis采用的hash slot是算法,算法将hash/16384槽,进行分配,当其中一个缓存服务挂掉之后,不会造成重新计算分配,只会存在一部分缓存失效
1. 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
2.数据预热
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
三 缓存类型:
个人对缓存的理解就缓存其实是一种思想,缓存也是可以区分的,缓存可以分为cpu缓存,程序外缓存,程序内缓存
1 cpu缓存,是处理器级缓存,如果缓存的数据被命中,那么他的响应速度是要超过程序外缓存和程序内缓存,
四 小型互联网架构的好处和坏处:
小型互联网架构缓存,其实很多部分没有采用es,es开启对内存的占用还是很惊人的,而且在开发维护上对公司的人要求相对就要要求高了,,通过静态化技术可以减少页面加载的时间
五 大型互联网架构的好处和坏处:
大型互联网架构:采用nginx进行进行数据缓存,10分钟更新一次,对数据进行缓存,通过lua拉去redis缓存中的数据,,如果redis缓存挂掉了,那么就从ehcashe中获取数据,即使是redis缓存血崩了,还是可以从ehcahe中获取数据,因为ehcahe是基于程序而存在的,不需要单独开启服务,所以只要程序不挂.那么这个缓存就不会崩溃,只会存在缓存击穿问题,即使击穿之后就回去查询es内存数据,

