Java课程设计之——爬虫
Java课程设计之——爬虫
1.主要使用到的技术
(1)Jsoup
(2)Dao模式
2.网络爬虫简介
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫——百度百科。
3.Jsoup爬虫简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。它的主要功能是从一个URL,文件或者字符串来解析HTML,并且可以操作HTML元素、属性、文本。
4.实现爬虫
(1)网络爬虫的设计思路
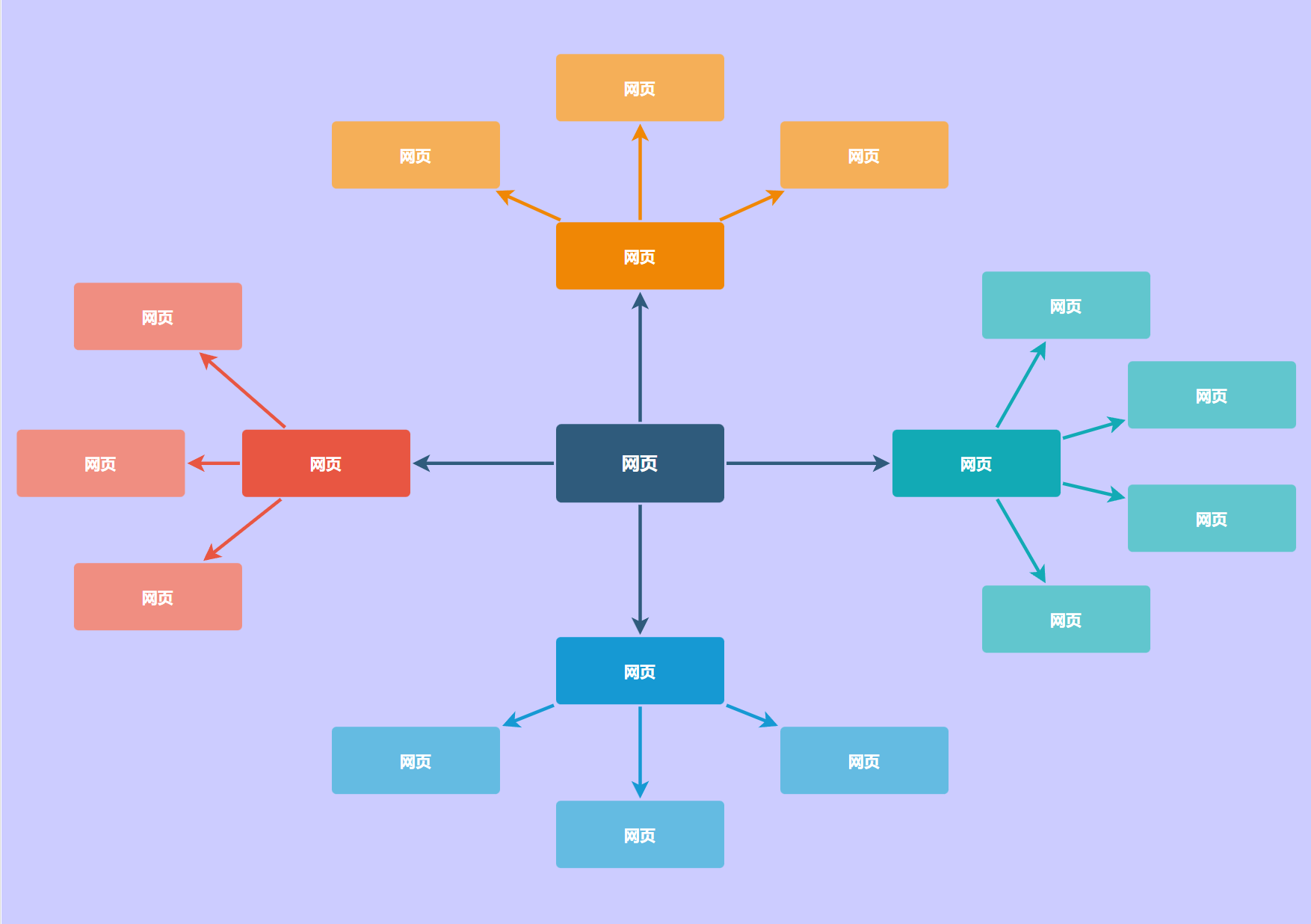
网络爬虫的基本思路就是解析当前的网页,然后在这个网页里面再对下一层的网页进行解析,层层解析然后判断自己需要的内容和判断是否有重复的内容,然后爬取出来,每次爬取网站的全部链接大概一分钟,950条左右的链接(因为很多链接被删除或者需要校园网,所以链接的数量大量减少,大概1秒钟出20条链接),我的爬虫策略可能有些问题所以需要的时间略长。
(2)功能实现
爬虫类图
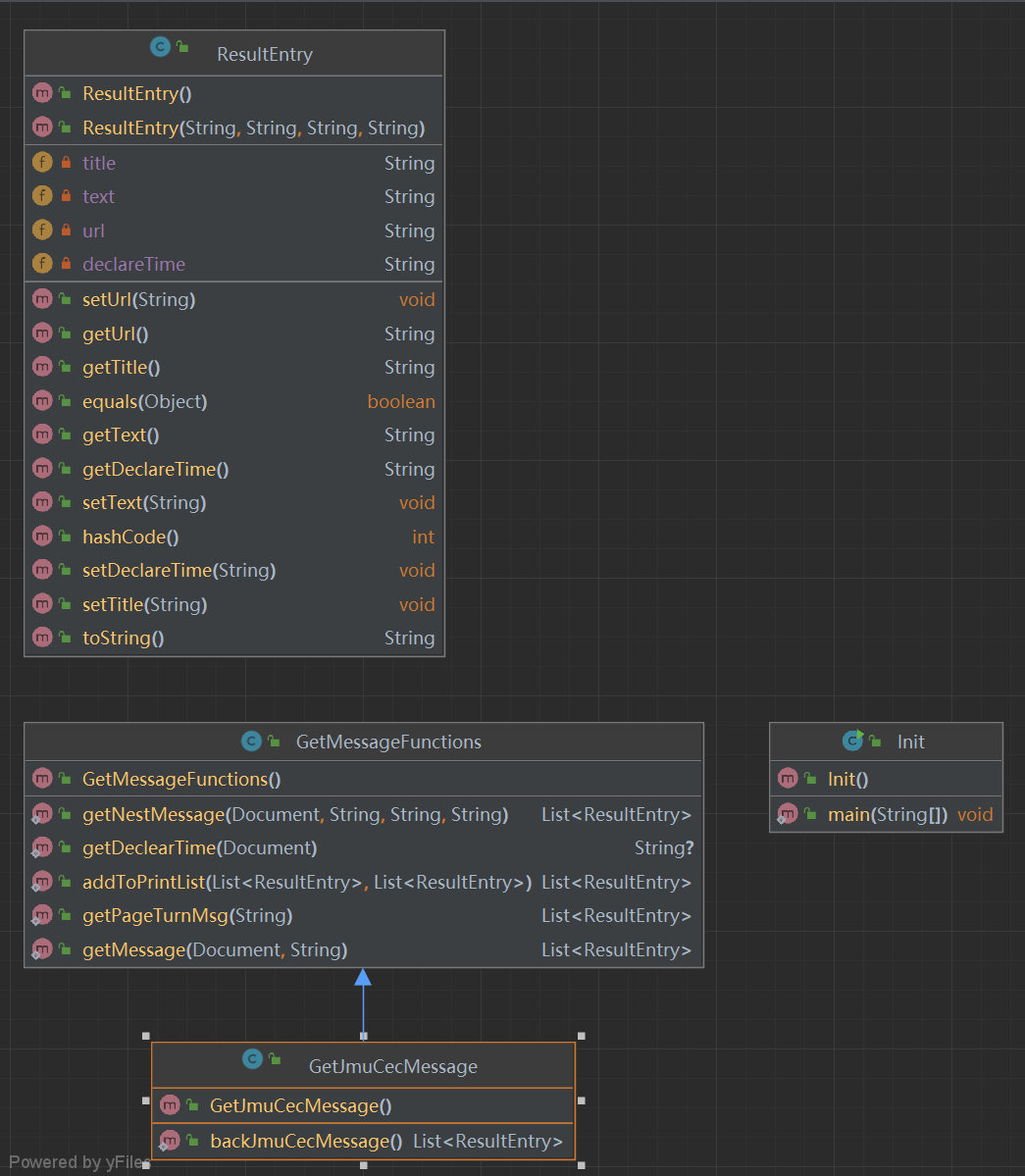
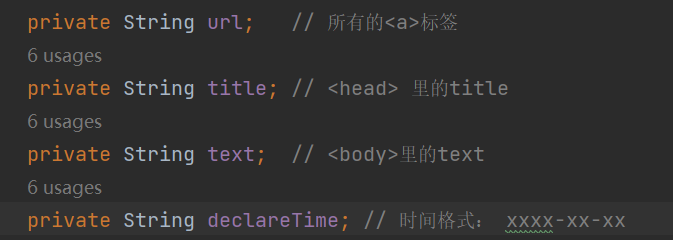
我们小组组长给我的任务是,我爬取的内容放在一个List数组中,每个元素中的元素为网址url,文章的标题title,网址的具体内容text和文章发表的时间declareTime,这些放在ResultEntry类中。
CrawDAO
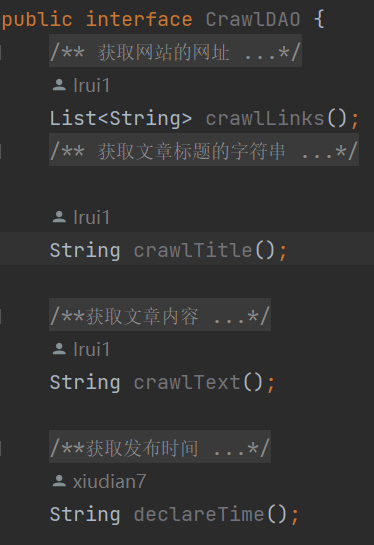
首先观察计算机工程学院网站的源码我发现网站分为了四个部分,分别是header、banner、conter和footer
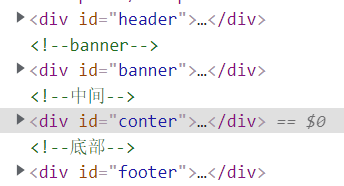
header里面存放的是一些大的标签比如学院首页、学院概况等等,这里的内容需要爬取。banner的内容是一些图片,这里不需要爬取。conter里面的内容就是各种的学院新闻,是此次爬取的重点。最后一部分是footer,这部分是院长信箱和书记信箱等等,对于本次的任务没有必要爬取。
此次的爬虫任务我分成了两部分来上实现,因为大部分的链接里面都嵌套着链接,所以我的思想是先把表层的链接爬取出来,然后再对每条链接进行再次的解析爬取,在这当中还要解决翻页的问题。

观察这个网址的存储结构,每个我需要爬取的网址都在class标签下,所以第一步就应该将计算机网站的所有class标签爬取下来,这里我使用了Set数组,防止有一些class标签重复。
上代码(只展示部分关键代码):
Set<String> classSet = new HashSet<String>();
Elements div = document.getElementsByTag("div");
for (Element element : div) {
String aClass = element.attr("class");
if (aClass != ""){ classSet.add(aClass);}
}
每个class爬取下来之后,我将对每个class标签进行分别的解析爬取。将每个class里面的li标签取出来,这就是一个具体文章的网址,然后再将此网站解析,就能得出文章的内容。这里设置了一个函数实现返回ResultEntry里面的内容。
getMessage方法
Set<ResultEntry> backSet=new HashSet<>();
Elements select = connection.select(selection);
for (Element element : select) {
Elements a = element.getElementsByTag("a");
ResultEntry e=new ResultEntry();
String href = a.attr("href");
e.setUrl("http://cec.jmu.edu.cn/"+href);
String title = a.attr("title");e.setTitle(title);
try {
String text = Jsoup.connect(e.getUrl()).get().text();e.setText(text);
String declearTime = getDeclearTime(Jsoup.connect(e.getUrl()).get());
e.setDeclareTime(declearTime);
backSet.add(e);
}catch (Exception ex){
continue;
}
}
List<ResultEntry>backList=new ArrayList<>(backSet);
return backList;
因为计算机学院网站给的都是相对路径,所以我需要加一些前缀将其网址补齐(这里可以用abs的方法获取绝对路径,这里可以有很大的改进空间),这里我专门设置了一个函数来获取发布时间。

时间都分布在er_right_xnew标签中,所以我抓取这个标签的内容即可,但是这个标签的内容是“发布人: 时间:2023-01-06 ”,我需要的只是“2023-01-06”,所以还需处理一下。
getDeclearTime
String text = connection.select("div.er_right_xnew_date").text();
int indexOf = text.indexOf("时间:");
int suffixNum=3;
if (indexOf != -1) {return (text.substring(indexOf + suffixNum));}
else {return null;}
获取到表层的链接之后,将对此链接进行进一步的解析。如果我不进行翻页的处理的话,内容将大大减少,有的部分有20多页,数据量很大。



通过观察这些翻页的网址发现,只需要改变一个数字就可以实现翻页,并且这个数字还很有特点。这个部分一共18页,第二页就是17,第三页就是16,所以我就将这个数字取出来就行,然后通过遍历就能访问所有的页面。

所有的页数都在“span”这个标签下,先将所有这个标签爬取下来然后进行爬取。
getPageTurnMsg
List<ResultEntry>backList=new ArrayList<>();
List<ResultEntry>list=new ArrayList<>();
int index=href.indexOf(".htm");
int number=Integer.parseInt(href.substring(5, index));
//换页的前缀
String prefix = href.substring(0, 5);
String prefixHref;
//每个模块的网址关键字都不同,所以遍历所有网址需要先进行判断
String xyxw="xyxw/";String tztg="tztg/";String xyfc="xyfc/";String xssw="xssw/";String xwtz="xwtz";
if(prefix.equals(xyxw)) {
prefixHref="http://cec.jmu.edu.cn/xwtz/";}
else if (prefix.equals(tztg)){
prefixHref="http://cec.jmu.edu.cn/bksjy/";}
else if (prefix.equals(xyfc)){
prefixHref="http://cec.jmu.edu.cn/xwtz/";}
else if (prefix.equals(xssw)) {
prefixHref = "http://cec.jmu.edu.cn/";
} else{ prefixHref="http://cec.jmu.edu.cn/kyj/";}
for (int i=number;i>=1;i--){
Document document = Jsoup.connect(prefixHref + prefix + i + ".htm").get();
if(prefix.equals(xssw)||prefix.equals(xwtz)) {
list = getNestMessage(document, "div.er_right_new>ul>li", "..", "http://cec.jmu.edu.cn");
addToPrintList(backList,list);
}
list=getNestMessage(document,"div.er_right_new>ul>li","../..","http://cec.jmu.edu.cn");
addToPrintList(backList,list);
}
return backList;
getNestMessage
Set<ResultEntry>backSet=new HashSet<>();
Elements select = connection.select(selection);
for (Element element : select) {
Elements a = element.getElementsByTag("a");
ResultEntry e=new ResultEntry();
String href = a.attr("href").replace(target,repleacement);
e.setUrl(href);
String title = a.attr("title");e.setTitle(title);
try {
String text = Jsoup.connect(e.getUrl()).get().text();
String declearTime = getDeclearTime(Jsoup.connect(e.getUrl()).get());
e.setDeclareTime(declearTime);
int textBeginIndex = text.indexOf("正文");
e.setText(text.substring(textBeginIndex+2));
backSet.add(e);
System.out.println(e.toString());
}catch (Exception ex){
continue;
}
}
List<ResultEntry>backList=new ArrayList<>(backSet);
return backList;
总结:这些函数都是返回一个List,我再将每个函数返回的List合并到一个总的函数中,最后将总的数组返回给合作者即可,至此,我的任务也基本完成了,虽然完成的方法有点笨哈哈,后面一定还会去改进,这次组长安排的任务比较简单,等课设结束后一定将这个课设自己再写一遍。

