ai绘画基础总结(二)模型插件安装
模型
授人以渔不如授人以渔,这里先给出一些常用的下载地址,首先声明,国内能下载模型的地方很少一盘都是网盘。所以网站是国外的,懂得都懂。
模型干什么的?怎么用?有什么区?
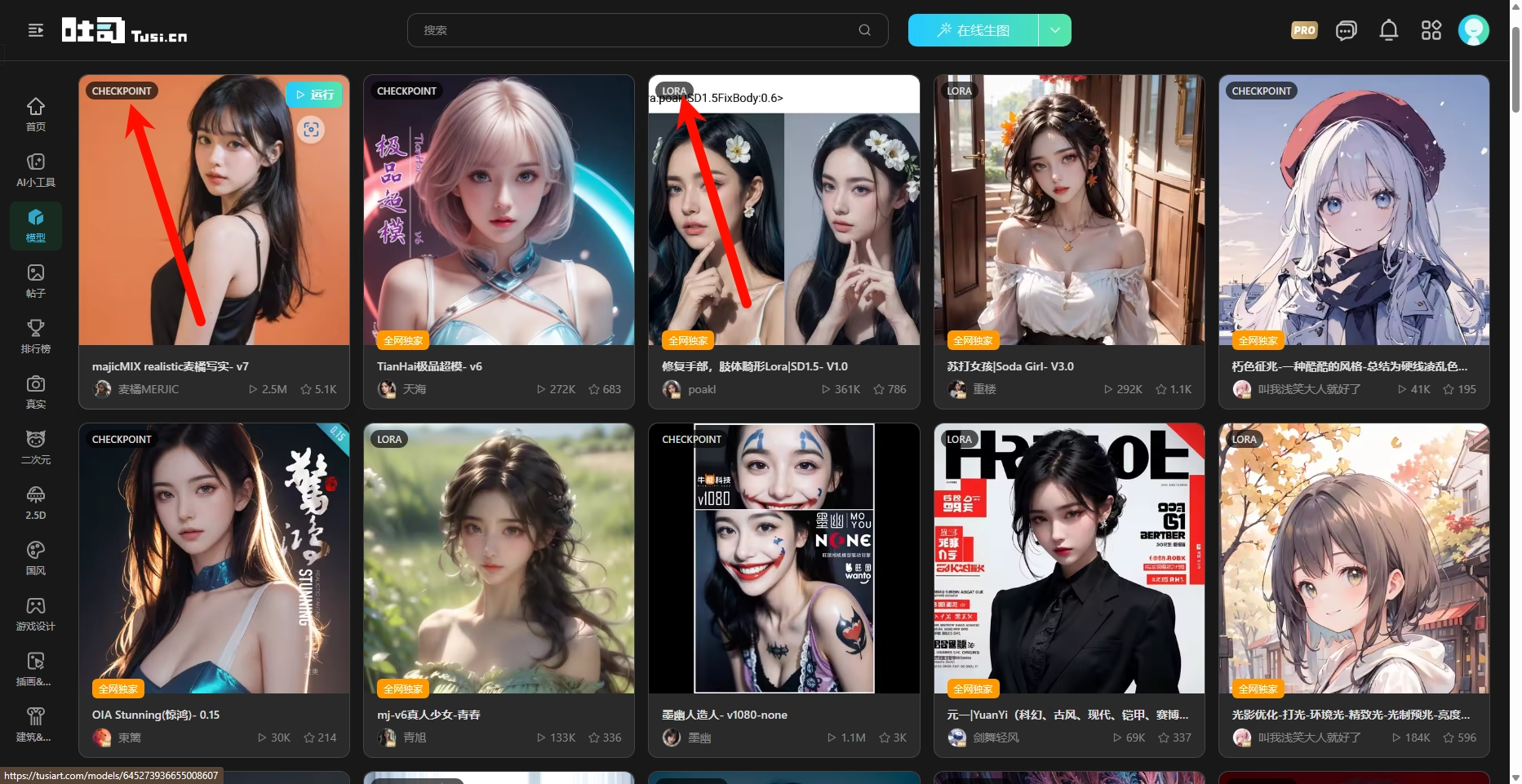
模型主要学习这5类,要是细分,那可太多。我们下载模型单纯看文件名后缀区分不了,所以没必要讲后缀。可以在上传模型到:Stable Diffusion 法术解析 (novelai.dev)解析。下载的时候如上图,看下作者上传的是什么类型的模型。按照对应的模型类型拷贝或者直接下载到对应的文件夹内就可以。要是主模型很多也可以在文件夹里再新建文件夹进行分类。
| 模型分类 | 解释 | 功能 | 路径 |
|---|---|---|---|
| Checkpoint(主模型) | Checkpoint 大模型是一种深度学习模型,通过将模型参数保存到磁盘上并随时恢复它们来避免重新训练模型的昂贵成本和时间。这种方法可以使用较少的内存和计算资源来加载大型模型,并在需要时恢复模型参数以进行预测。 | Checkpoint 模型是基础模型(主模型),常用大模型有sd1.0,sd1.5,sd2.0,SDXL等等。决定 AI 绘画的整体风格,文件比较大。 | *\ComfyUI\models\checkpoints |
| Controlnet | 是一种用于生成图像的深度学习模型,它通过在生成过程中引入外部控制信号来改进生成质量。ControlNet 通过将外部控制信号(如文本描述、关键点或方向向量)与生成网络的输入相结合来实现这一点,从而允许更精细的控制生成的图像内容。 | 在控制生成图的姿态、线条、结构、深度等方面有非常惊艳的效果。 | *\ComfyUI\models\controlnet |
| VAE(变分自解码器) | 变分自编码器(Variational Autoencoder,VAE)是一种深度学习模型,用于无监督学习,其中模型被训练以重建输入数据。VAE 由两部分组成:编码器和解码器。编码器将输入数据编码为一个低维度的潜在向量,而解码器则将潜在向量解码为重建数据。VAE 通过最大化重建数据的概率来学习数据的潜在分布。 | 它的效果类似于我们熟悉的滤镜,可以调整生成图片的色彩饱和度。 | *\ComfyUI\models\vae *\ComfyUI\models\vae_approx |
| Embeddings | 嵌入(Embedding)是一种将输入数据映射到连续向量空间的技术,通常用于自然语言处理、计算机视觉和推荐系统等领域。嵌入模型将输入数据(如单词、图像或用户)映射到固定大小的向量,这些向量可以用于后续的机器学习任务,如分类、聚类和预测。 | 使用提示词来进行 AI绘画,为准确画出预期的角色、物品、行为或者画风,通常需要输入比较多的提示词去描述和限定它。 | *\ComfyUI\models\embeddings |
| LORA | 利低秩适配(Low-Rank Adaptation,LoRA)是一种用于迁移学习的方法,它允许在新任务上微调预训练模型,同时保持原始预训练模型的不变。LoRA 通过在预训练模型的输出和任务特定模型的输入之间引入一个低秩适配矩阵来实现这一点,从而最小化对原始预训练模型的影响。 | 擅长调整画风,用于动作、角色等其他特定概念。 | *\ComfyUI\models\loras |
常用模型推荐
Checkpoint 模型
-
Stable Diffusion 1.5(Stable Diffusion 原模型 v1.5)
-
Anything(二次元风格图像生成)
-
AbyssOrangeMix2(二次元风格图像生成)
-
OrangeMixs(二次元风格图像生成)
-
Counterfeit(高质量二次元人物和风景图像生成)
-
MeinaMix(高质量二次元风格人物图像生成)
-
ChilloutMix(亚洲真人照片风格图像生成)
-
Deliberate(欧美真人照片风格图像生成)
-
DreamShaper(写实、原画等多种风格的人像和风景图像生成)
-
Lyriel(支持多种风格的人物和风景图像生成)
-
Protogen(支持多种风格的人物和风景图像生成)
-
Dreamlike diffusion(插画风格图像生成)
-
Dreamlike photoreal(真实风格图像生成)
-
Realistic vision(真实世界风格的任务和环境图像生成)
-
DDicon(B 端风格元素图像生成,配合 DDICON_lora 的LoRA模型使用)
-
Product Design(工业产品设计相关图像生成)
-
Isometric Future(等距微缩风格图像生成)
-
Vectorartz Diffusion(矢量风格图像生成)
-
Samdoesarts Ultmerge(Samdoesars 艺术风格图像生成)
-
Flonix MJ Style(Flonix MJ 插画风格图像生成)
-
architectural design sketches with markers(建筑设计草图风格图像生成)
-
XSarchitectural-InteriorDesign-ForXSLora(室内设计风格图像生成)
-
Re V Animated(动漫人物或场景的 2.5D 或 3D 图像生成)
LoRA 模型
- KoreanDollLikeness(韩国真人照片风格)【推荐主模型:ChilloutMix】
- JapaneseDollLikeness(日本真人照片风格)【推荐主模型:ChilloutMix】
- ThaiDollLikeness(泰国真人照片风格)【推荐主模型:ChilloutMix】
- 墨心(水墨画风格)【推荐主模型:ChilloutMix】
- Gacha splash LORA(带背景的立绘风格)
- 沁彩 Colorwater(水彩风格)
- blindbox(盲盒娃娃风格)【推荐主模型:RevAnimated】
- DDicon_lora(B端元素风格)【推荐主模型:DDicon】
- Freljord(场景凤格)
- 剪纸(剪纸风格)
- Anime Lineart(线稿画风格)【推荐主模型:Anything v4.5】
- Concept Scenery Scene(风景场景风格)【推荐主模型:Counterfeit v2.5】
- Howls Moving Castle(哈尔移动城堡风格)
- Makoto Shinkai(新海诚风格)
- Studio Ghibli Style(吉卜力风格)【推荐主模型:Anything v4.5】
- Airconditioner(城镇、荒野等风景场景风格)
- Stamp_v1(图标 Loga 风格)
VAE 模型
- vae.ft-ema-560000-ema-pruned(Stabilily Al 官方发布的 VAE,适用于大部分场量)
- vae-ft-mse-840000-ema-pruned(Stability Al 官方发布的 VAE,适用于大部分场景)
- kl-f8-anime2(适用于二次元动漫场景)
- Grapefruit VAE(适用于二次元动漫场景)
常用下载地址
欢迎在评论区补充,相互学习。
国外:
国内(需要登录是常态):
吐司 tusi.cn | 可在线生图的 AI 模型分享社区,还是免费的! (tusiart.com)(部分需要付费,也是独家模型)
LiblibAI·哩布哩布AI - 中国领先的AI创作平台(部分需要开会员)
ai导航工具集
AI工具集 | 700+ AI工具集合官网,国内外AI工具集导航大全 (ai-bot.cn)
Hugging Face–有趣的Hugging Face模型 | Ai导航 (ainavpro.com)
工作流
学习工作流难免抄作业,可以学学大佬的流程思维方式。如果想完美复刻工作流,注意看下别人使用的模型,你有没有,国外的环境相对较好,国内的好多人都是将模型改名上传。也有很多自炼的,所以很多东西仅供参考。
详细工作流学习参考第三部分
国外:
国内:
一个大佬的github地址:(现在16类 41项)ZHO-ZHO-ZHO/ComfyUI-Workflows-ZHO: 我的 ComfyUI 工作流合集 | My ComfyUI workflows collection (github.com)介绍了插件和节点等,很有参考价值
插件
安装方法,满血包里面有绝大多数常用的插件:
1.下载插件解压粘贴到里面,主要不要文件夹套娃(点开文件夹还要点开一层文件夹才能看到文件)
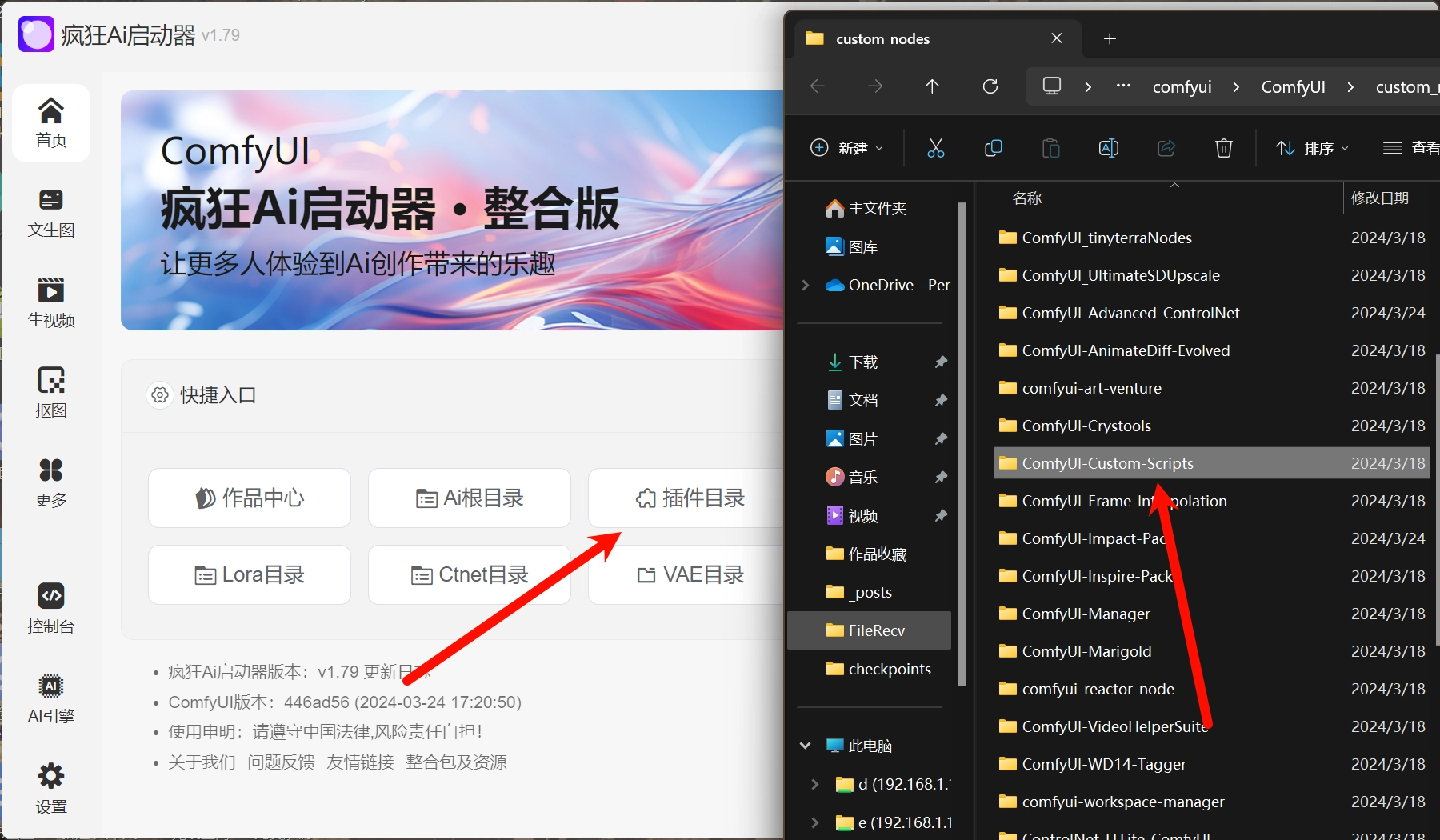
2.注意下载安装的时候可以切换源,国内也可享用。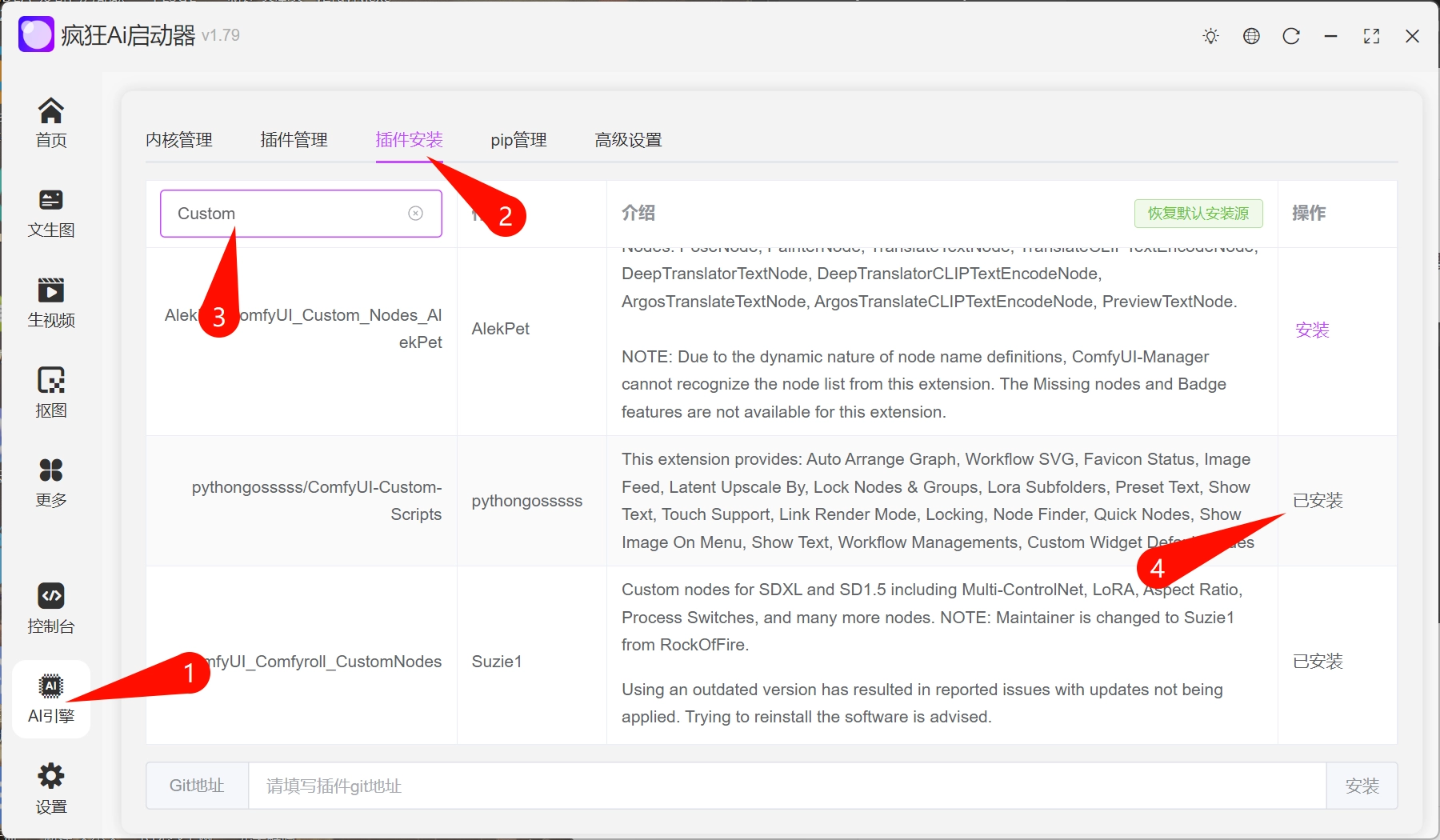
3.ComfyUI管理器界面安装
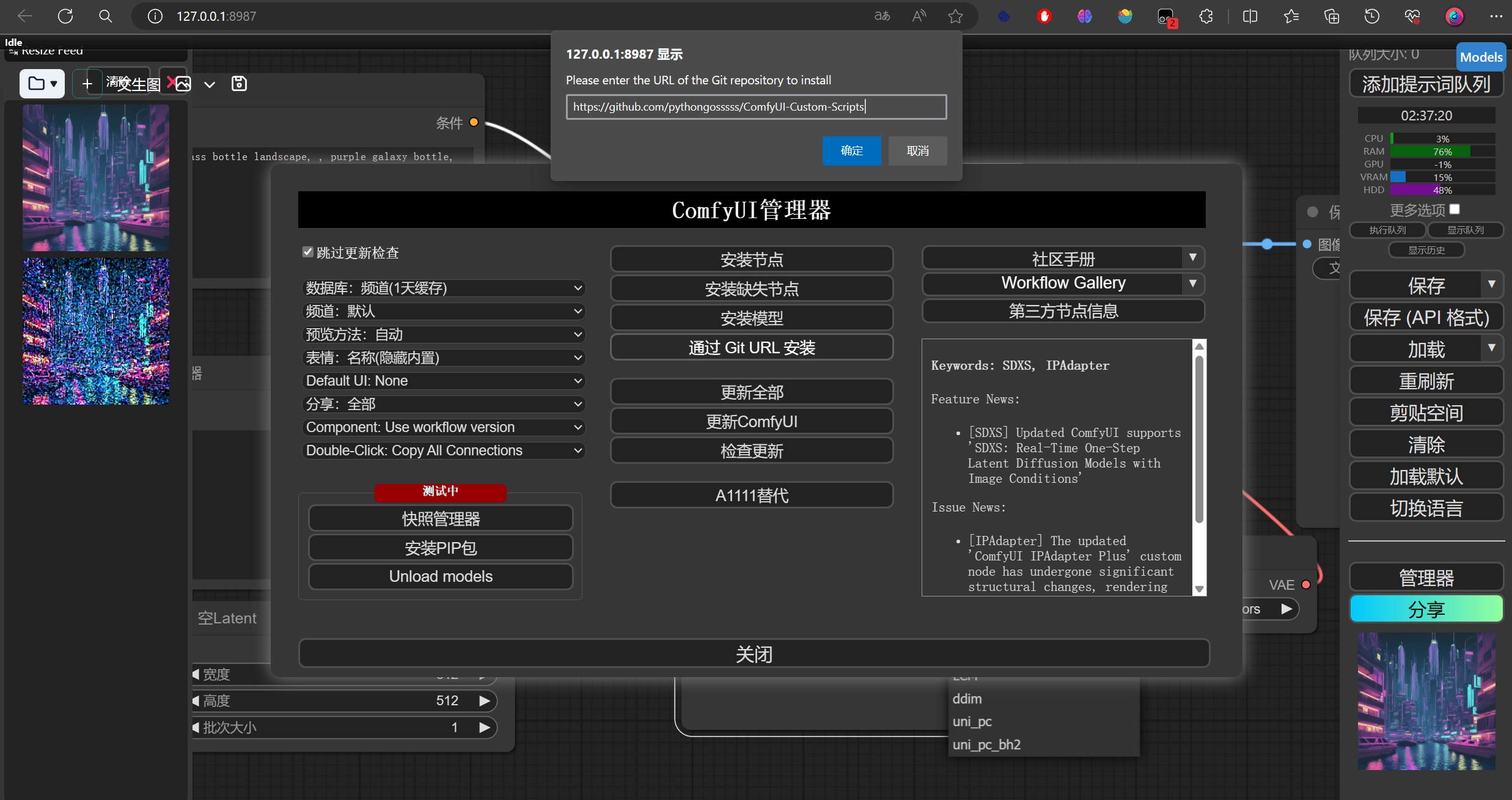
下载插件可能需要科学,已经打包好了放在企鹅群:306146537
插件安装经常会有提示更新,这个很正常。
AIGODLIKE-COMFYUI-TRANSLATION
第一步当然是汉化了
功能:能汉化界面(安装完成后要手动去设置语言),添加能翻译的文本编码器(这个很重要,你就不需要输英文,或者手动翻译了。新建节点>ALEK节点>条件 然后就可以看到了)
pythongosssss/ComfyUI-Custom-Scripts
功能:自动提示词补全、二级菜单、网络对齐、模型信息查看(来源civitai.com国外)、颜色自定义、网页小图标等等。。。
SD放大
功能:SD放大
ComfyUI WD 1.4 Tagger
我在这里的时候踩了一个坑,自动下载反推提示词模型需要代理,但是自动下载是在控制台执行的,代理需要开启tun,控制台才能链接代理,要是控制台也了连接不了请参考:AI绘画拉取模型失败,DOS开启代理 | XiSoul Blog's
当然你要是感觉不影响你可以手动下载模型复制到插件的模型文件夹内:
E:\comfyui\ComfyUI\custom_nodes\ComfyUI-WD14-Tagger\models
模型地址:SmilingWolf (Smiling Wolf) (huggingface.co)
功能:传入图片,反推提示词。
SDXL Prompt Styler
twri地址:twri/sdxl_prompt_styler: Custom prompt styler node for SDXL in ComfyUI (github.com)
wolfden地址:wolfden/ComfyUi_PromptStylers: Style Prompts for ComfyUI (github.com)(标准比第一种多一些)
风格json文件件路径:
E:\comfyui\ComfyUI\custom_nodes\sdxl_prompt_styler
当你有一套固定的风格提示词的时候,你可以直接编辑base.json文件,添加自己的风格模板。
功能:SDXL风格化提示词,SDXL风格化提示词(高级),记录提示词,高级,用很简单的提词生成不错的图形。
ComfyUI's ControlNet Auxiliary Preprocessors
功能:菜单中多出ControlNet预处理器标签页,可是手部修复,控制姿势
和WD1.4反推一样需要科学下载模型,文件后缀.pth
模型地址:*\ComfyUI\custom_nodes\comfyui_controlnet_aux\ckpts\lllyasviel\Annotators
里面每个模型都是以文件夹的形式存放


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫