

Python获取网页指定内容(BeautifulSoup工具的使用方法)
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能,此文中所有的功能都是基于BeautifulSoup这个包。
1 Pyhton获取网页的内容(也就是源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址所对应的源代码,urllib2是需要用到的包,以上三句代码就能获得网页的整个源代码
2 获取网页中想要的内容(先要获得网页源代码,再分析网页源代码,找所对应的标签,然后提取出标签中的内容)
2.1 以豆瓣电影排名为例子
网址是http://movie.douban.com/top250?format=text,进入网址后就出现如下的图
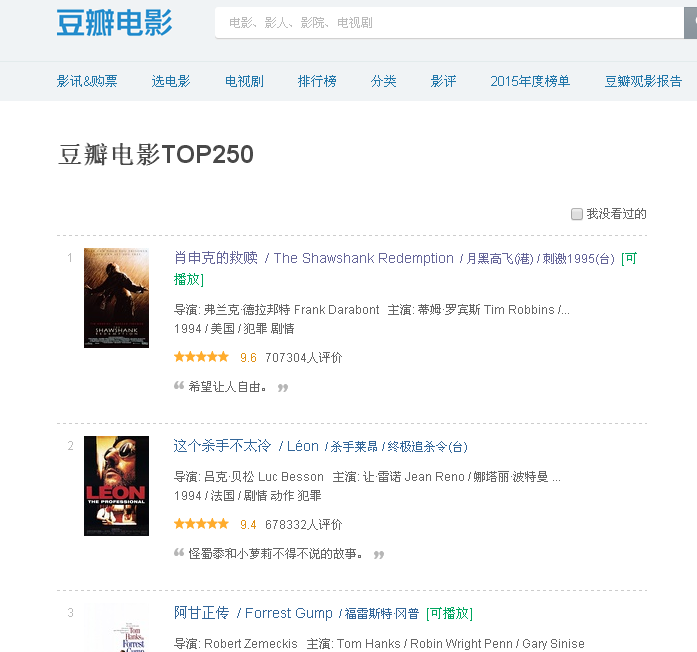
现在我需要获得当前页面的所有电影的名字,评分,评价人数,链接

由上图画红色圆圈的是我想得到的内容,画蓝色横线的为所对应的标签,这样就分析完了,现在就是写代码实现,Python提供了很多种方法去获得想要的内容,在此我使用BeautifulSoup来实现,非常的简单

#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,你也可以写入文件中
前三行代码获得整个网页的源代码,之后开始使用BeautifulSoup进行标签分析,find_all方法是找到所有此标签的内容,然后在在此标签中继续寻找,如果标签有特殊的属性声明则一步就能找出来,如果没有特殊的属性声明就像此图中的评价人数前面的标签只有一个‘span’那么就找到所有的span标签,按顺序从中选相对应的,在此图中是第三个,所以这种方法可以找特定行或列的内容。代码比较简单,很容易就实现了,如果有什么地方不对,还请大家指出,大家共同学习。

源代码地址:http://download.csdn.net/detail/danielntz/9577390
转自:https://blog.csdn.net/danielntz/article/details/51861168


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现