
转载:深入了解.NET中堆和栈的比较--二
看到这么多朋友对于这系列文章的赞同,决定将这系列文章转载过来,方便更多的朋友加深对.net核心基础的理解……
.NET中栈和堆的比较 #2
原文出处:
http://www.c-sharpcorner.com/UploadFile/rmcochran/csharp_memory2B01142006125918PM/csharp_memory2B.aspx
尽管在.NET framework下我们并不需要担心内存管理和垃圾回收(Garbage Collection),但是我们还是应该了解它们,以优化我们的应用程序。同时,还需要具备一些基础的内存管理工作机制的知识,这样能够有助于解释我们日常程序编写中的变量的行为。在本文中我将讲解我们必须要注意的方法传参的行为。
在第一部分里我介绍了栈和堆的基本功能,还介绍到了在程序执行时值类型和引用类型是如何分配的,而且还谈到了指针。
* 参数,大问题
这里有一个代码执行时的详细介绍,我们将深入第一部分出现的方法调用过程...
当我们调用一个方法时,会发生以下的事情:
1.方法执行时,首先在栈上为对象实例中的方法分配空间,然后将方法拷贝到栈上(此时的栈被称为帧),但是该空间中只存放了执行方法的指令,并没有方法内的数据项。
3.方法参数的分配和拷贝是需要空间的,这一点是我们需要进一步注意。
示例代码如下:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
此时栈开起来是这样的: 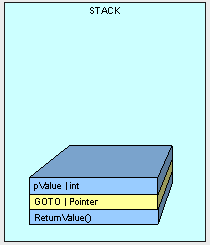
就像第一部分讨论的那样,放在栈上的参数是如何被处理的,需要看看它是值类型还是引用类型。值类型的值将被拷贝到栈上,而引用类型的引用(或者说指针)将被拷贝到栈上。
* 值类型传递
首先,当我们传递一个值类型参数时,栈上被分配好一个新的空间,然后该参数的值被拷贝到此空间中。
来看下面的方法:
class Class1
{
public void Go()
{
int x = 5;
AddFive(x);
Console.WriteLine(x.ToString());
}
public int AddFive(int pValue)
{
pValue += 5;
return pValue;
}
}
方法Go()被放置到栈上,然后执行,整型变量"x"的值"5"被放置到栈顶空间中。
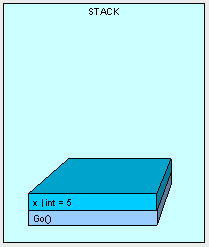
然后AddFive()方法被放置到栈顶上,接着方法的形参值被拷贝到栈顶,且该形参的值就是"x"的拷贝。
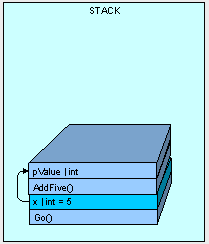
当AddFive()方法执行完成之后,线程就通过预先放置的指令返回到Go()方法的地址,然后从栈顶依次将变量pValue和方法AddFive()移除掉:
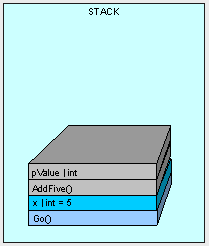
所以我们的代码输出的值是"5",对吧?这里的关键之处就在于任何传入方法的值类型参数都是复制拷贝的,所以原始变量中的值是被保留下来而没有被改变的。
必须注意的是,如果我们要将一个非常大的值类型数据(如数据量大的struct类型)入栈,它会占用非常大的内存空间,而且会占有过多的处理器周期来进行拷贝复制。栈并没有无穷无尽的空间,它就像在水龙头下盛水的杯子,随时可能溢出。struct是一个能够存放大量数据的值类型成员,我们必须小心地使用。
这里有一个存放大数据类型的struct:
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
来看看当我们执行了Go()和DoSometing()方法时会发生什么:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(x);
}
public void DoSomething(MyStruct pValue)
{
// DO SOMETHING HERE....
}
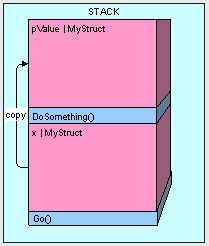
这将会非常的低效。想象我们要是传递2000次MyStruct,你就会明白程序是怎么瘫痪掉的了。
那么我们应该如何解决这个问题?可以通过下列方式来传递原始值的引用:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(ref x);
}
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
public void DoSomething(ref MyStruct pValue)
{
// DO SOMETHING HERE....
}
通过这种方式我们能够提高内存中对象分配的效率。
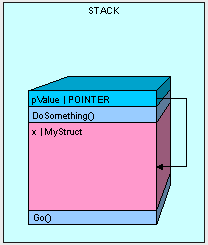
唯一需要注意的是,在我们通过引用传递值类型时我们会修改该值类型的值,也就是说pValue值的改变会引起x值的改变。执行以下代码,我们的结果会变成"123456",这是因为pValue实际指向的内存空间与x变量声明的内存空间是一致的。
public void Go()
{
MyStruct x = new MyStruct();
x.a = 5;
DoSomething(ref x);
Console.WriteLine(x.a.ToString());
}
public void DoSomething(ref MyStruct pValue)
{
pValue.a = 12345;
}
* 引用类型传递
传递引用类型参数的情况类似于先前例子中通过引用来传递值类型的情况。
如果我们使用引用类型:
public class MyInt
{
public int MyValue;
}
然后调用Go()方法,MyInt对象将放置在堆上:
public void Go()
{
MyInt x = new MyInt();
}
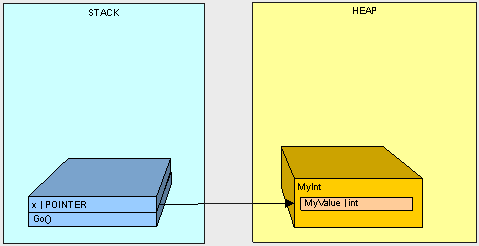
如果我们执行下面的Go()方法:
public void Go()
{
MyInt x = new MyInt();
x.MyValue = 2;
DoSomething(x);
Console.WriteLine(x.MyValue.ToString());
}
public void DoSomething(MyInt pValue)
{
pValue.MyValue = 12345;
}
将发生这样的事情...
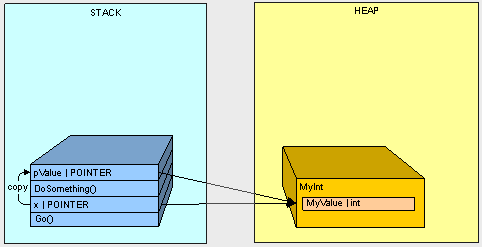
1.方法Go()入栈
2.Go()方法中的变量x入栈
3.方法DoSomething()入栈
4.参数pValue入栈
5.x的值(MyInt对象的在栈中的指针地址)被拷贝到pValue中
因此,当我们通过MyInt类型的pValue来改变堆中MyInt对象的MyValue成员值后,接着又使用指向该对象的另一个引用x来获取了其MyValue成员值,得到的值就变成了"12345"。
而更有趣的是,当我们通过引用来传递一个引用类型时,会发生什么?
让我们来检验一下。假如我们有一个"Thing"类和两个继承于"Thing"的"Animal"和"Vegetable" 类:
public class Thing
{
}
public class Animal:Thing
{
public int Weight;
}
public class Vegetable:Thing
{
public int Length;
}
然后执行下面的Go()方法:
public void Go()
{
Thing x = new Animal();
Switcharoo(ref x);
Console.WriteLine(
"x is Animal : "
+ (x is Animal).ToString());
Console.WriteLine(
"x is Vegetable : "
+ (x is Vegetable).ToString());
}
public void Switcharoo(ref Thing pValue)
{
pValue = new Vegetable();
}
变量x被返回为Vegetable类型。
x is Animal : False
x is Vegetable : True
让我们来看看发生了什么:
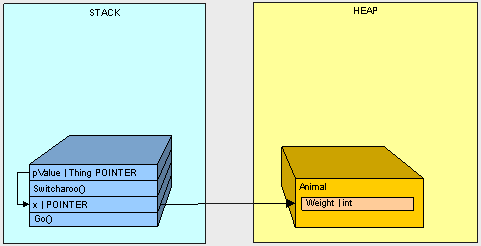
1.Go()方法入栈
2.x指针入栈
3.Animal对象实例化到堆中
4.Switcharoo()方法入栈
5.pValue入栈且指向x
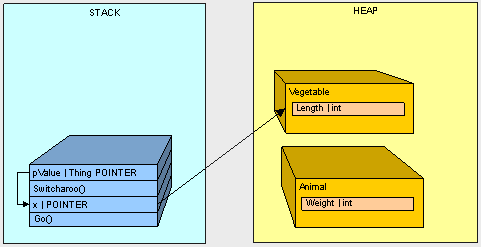
6.Vegetable对象实例化到堆中
7.x的值通过被指向Vegetable对象地址的pValue值所改变。
如果我们不使用Thing的引用,相反的,我们得到结果变量x将会是Animal类型的。
如果以上代码对你来说没有什么意义,那么请继续看看我的文章中关于引用变量的介绍,这样能够对引用类型的变量是如何工作的会有一个更好的理解。
我们看到了内存是怎样处理参数传递的,在系列的下一部分中,我们将看看栈中的引用变量发生了些什么,然后考虑当我们拷贝对象时是如何来解决某些问题的。
To be continued...
文章发表于园子:http://www.cnblogs.com/c2303191/articles/1065675.html
作者:xirong
出处:http://www.cnblogs.com/xirongliu
说明:本文是自己学习编程的一个历程,版权归作者和博客园共有,欢迎转载,请标明原文连接,如有问题 xirong 联系我,非常感谢。


