商城项目
基础篇#
简介#
微服务基于业务边界进行服务微化拆分,各个服务独立部署运行。
分布式是指将不同的业务分布在不同的地方。
集群是指将几台服务器集中在一起,实现同一业务。
分布式中的每个节点都可以做成集群,而集群不一定就是分布式的。
环境#
老师用的Redis的版本是5.0.5,由于其他原因使用了最新版的Redis。
2020.3以后的版本不需要额外安装Lombok了,idea已经集成进去了,再引入一个lombok的maven依赖就行。
Vagrant#
可以使用VirtualBox和Vagrant组合安装centos虚拟机。Vagrant镜像库
| 操作 | 作用 |
|---|---|
| vagrant init centos/7 | 创建centos7镜像 |
| vagrant up | 启动镜像 |
| vagrant ssh | 使用命令行操作 |
解决Vagrant下载过慢的问题。Vargrantfile文件在路径C:\Windows\System32下。解决方法
虚拟机的IP地址为192.168.56.10,看第二个的IP配置;本机的IP地址为10.45.83.29,看最后一个的IP配置。
虚拟机的管理员账号的密码默认是vagrant。
MySQL#
docker启动MySQL。
docker run -p 3306:3306 --name mysql \
-v /mydata/mysql/log:/var/log/mysql \
-v /mydata/mysql/data:/var/lib/mysql \
-v /mydata/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
MySQL的密码是root。
在大型电商网站中,一般不建立外键。
MySQL的Maven版本不是和MySQL的版本一一对应的,可以上Maven的仓库查看对应情况。
前端#
在使用人人开源的前端时,先使用npm install安装所需的依赖,建议使用管理员权限打开vscode且路径不带中文。
在启动人人开源的前端时使用npm install问题容易出现node-sass和nodejs版本不匹配的问题,这时我们就需要使用mvn工具调整我们的nodejs版本。mvn使用
分布式组件#
如果配置中心和当前应用的配置文件中都配置了相同的项,以配置中心的为准。
命名空间可以基于环境进行隔离,也可以根据微服务进行隔离。
启动微服务时,nacos会默认读取微服务名.properties文件,如果没有指定则读取默认空间的默认分组。
读取多个配置集#
按列表写入需要读取的多个数据集。
spring.cloud.nacos.config.ext-config[0].data-id=datasource.yml
spring.cloud.nacos.config.ext-config[0].group=dev
spring.cloud.nacos.config.ext-config[0].refresh=true
spring.cloud.nacos.config.ext-config[1].data-id=mybatis.yml
spring.cloud.nacos.config.ext-config[1].group=dev
spring.cloud.nacos.config.ext-config[1].refresh=true
spring.cloud.nacos.config.ext-config[2].data-id=other.yml
spring.cloud.nacos.config.ext-config[2].group=dev
spring.cloud.nacos.config.ext-config[2].refresh=true
前端#
前端技术栈类比#
| 语言 | 框架 | 工具 | 项目构建 | 依赖管理 | |
|---|---|---|---|---|---|
| 前端 | javaScript | Vue、React | webstorm、vscode | webpack、gulp | npm |
| 后端 | java | Spring、SpringMVC | idea、eclipes | maven、gradle | maven |
ES6#
ES6是JavaScript语言的下一代标准,ECMAScript是浏览器脚本语言的规范,JavaScript则是规范的具体实现。
var声明的变量往往会越域,let声明的变量有严格局部作用域。var可以声明多次,let只能声明一次。var会变量提升,let不存在变量提升。变量提升是指,如果在定义前使用,var会显示undefined,let则会报错。
const声明只读变量。
模板字符串相当于加强版的字符串,用反引号`,除了作为普通字符串,还可以用来定义多行字符串,还可以在字符串中加入变量和表达式。
不定参数用来表示不确定参数个数,形如,...变量名,由...加上一个具名参数标识符组成。具名参数只能放在参数列表的最后,并且有且只有一个不定参数。
对象中定义函数,箭头函数的this不能使用,需要使用对象.属性,因为使用箭头函数之后的this不是该对象。
模块化就是把代码进行拆分,方便重复利用。类似 java 中的导包:要使用一个包,必须先导包。而 JS 中没有包的概念,而是模块。模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口;import命令用于导入其他模块提供的功能。
//解构表达式
let [a,b,c] = arr;//将arr数组的值按顺序分别赋给a,b,c
//对象解构,如果与属性值不一致需要标注
const person = {
name: "jack",
age: 21,
language: ['java', 'js', 'css']
}
const { name: nn, age, language } = person;
//箭头函数,当只有一行语句,并且需要返回结果时,可以省略 {} , 结果会自动返回。有点类似java的lambda表达式
var sum2 = (a, b) => a + b;
//等价于
var sum = function (a, b) {
return a + b;
}
//箭头函数+解构表达式
var hello2 = ({ name }) => { console.log("hello," + name) };
hello2(person);//会先name = person.name传入,再进行箭头函数的解析
//拓展运算符(...)用于取出参数对象所有可遍历属性然后拷贝到当前对象。
//1.深拷贝
let person1 = { name: "Amy", age: 15 }
let someone = { ...person1 }
//2.合并对象
let age = { age: 15 }
let name = { name: "Amy" }
let person2 = { ...age, ...name } //如果两个对象的字段名重复,后面对象字段值会覆盖前面对象的字段值
console.log(person2) //{age: 15, name: "Amy"}
Promise
Promise用于封装异步操作。
let get = function (url, data) { // 实际开发中会单独放到 common.js 中
return new Promise((resolve, reject) => {
$.ajax({
url: url,
type: "GET",
data: data,
success(result) {
resolve(result);
},
error(error) {
reject(error);
}
});
})
}
// 使用封装的 get 方法,实现查询分数
get("mock/user.json").then((result) => {
console.log("查询用户:", result);
return get(`mock/user_corse_${result.id}.json`);
}).then((result) => {
console.log("查询到课程:", result);
return get(`mock/corse_score_${result.id}.json`)
}).then((result) => {
console.log("查询到分数:", result);
}).catch(() => {
console.log("出现异常了:" + error);
});
Vue#
启动项目:npm run dev。
MVVM思想
M:即 Model,模型,包括数据和一些基本操作;V:即 View,视图,页面渲染结果;VM:即 View-Model,模型与视图间的双向操作(无需开发人员干涉)。
MVVM 中的 VM 要做的事情就是把 DOM 操作完全封装起来,开发人员不用再关心 Model和 View 之间是如何互相影响的。
安装版本2的vue:npm install vue@2。
v-bind是单向绑定,数据变了model会变,但model的修改不影响数据;v-model是双向绑定。
页面的不同部分可以拆分成独立的组件,然后在不同页面共享这些组件,避免重复开发。在Vue中,所有的Vue实例都是组件。
不同的组件不会与页面的元素进行绑定,否则就无法复用了,因此没有el属性,且data必须是一个函数,不再是一个对象。
每个Vue实例在被创建时都要经过一系列的初始化过程,Vue为声明周期的每个状态都设置了钩子函数(监听函数)。每当Vue实例处于不同的生命周期时,对应的函数就会被触发调用。
//双向绑定
<body>
<div id="app">
<input type="text" v-model="num">
<h2>
{{name}},非常帅!!!有{{num}}个人为他点赞。
</h2>
</div>
<script src="./node_modules/vue/dist/vue.js"></script>
<script>
// 创建 vue 实例
let app = new Vue({
el: "#app", // el 即 element,该 vue 实例要渲染的页面元素
data: { // 渲染页面需要的数据
name: "张三",
num: 5
}
});
</script>
</body>
商品服务#
三级分类#
遇到无法正常打开的时候,看看自己的网关微服务是否已经开启,在本项目中是GulimallGatewayApplication。
如果出现端口被占用的情况,可以先查找被占用的端口netstat -ano|findstr 10000,然后将该进程杀死taskkill /t /f /im 进程号。解决方法
在renren-fast中配置的路由中的/会被替换成-,对应的前端代码在src/views/modules对应的文件夹中。
前端项目中在src/static/config/index.js中可以配置API接口请求地址,是前端用于请求后端项目的数据。
将renren-fast项目注册到nacos的解决方案:依赖不要导入common的,而是自己导nacos,然后将renren-fast的spring版本降低,然后把出错的类改为allowedOrigins("*")。
跨域:指浏览器不能执行其他网站的脚本,它是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。同源策略是指协议,域名,端口都要相同,其中一个不同都会造成跨域。
跨域流程:非简单请求在发送真实请求前,需要先发送预检请求检查是否跨域。
解决跨域的方法:1、使用Nginx部署为同一域。2、配置当次请求允许跨域。
在自己项目配置好跨域的条件后,需要将renren-fast的跨域请求注释掉,不然会产生冲突。
在编写路由的时候要注意顺序,一般是范围小的放在前面,否则被范围大的先匹配,就会导致范围小的配置无效。也可以通过order路由顺序来确定匹配优先度。
@RequestBody:获取请求体,必须发送POST请求。SpringMVC自动将请求体的数据(json),转为对应的对象。
使用右侧的restful插件可以替代postman的功能。
navicat在一页显示不了的情况下会进行分页显示。
vscode的格式化快捷键是alt+shift+f。
在编辑时需要重新发送请求获取最新的数据,防止多人操作时互相影响。
编辑属性之后data的值被改变,由于是双向绑定的,因此输入框的数据会被改变,下次操作前需要将其重新还原为默认值。
batchDelete中提示框显示的是被删除的ID,实际上使用名称会更好。
品牌管理#
@/components/upload/singleUpload模块有问题
minio可以用于自己搭建云存储。
OSS对象云存储的bucket名称叫gulimall-xiqin。
对象存储采取的策略是用户提交前先向服务器提出请求,服务器经过校验后返回防伪签名,然后用户再通过前端上传数据到OSS上。
@Test
public void testUpload() throws FileNotFoundException{
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId,accessKeySecret);
//上传文件流
InputStream inputStream = new FileInputStream("D:\\java\\谷粒商城\\Guli Mall(包含代码、课件、sql)\\Guli Mall\\分布式基础\\资源\\pics\\0d40c24b264aa511.jpg");
ossClient.putObject("gulimall-xiqin","bug.jpg",inputStream);
ossClient.shutdown();
System.out.println("上传完成");
}
如果使用..找不到对应文件的情况下,可以使用@开始查找,默认是以src作为根目录进行查找。不过问题的发生是因为我放错文件夹了,视频后面新建了一个同名文件夹。解决方案
前端进行数据校验后,后端也需要进行数据校验,因为通过Postman这类工具可以绕过前端发送请求,前端校验数据只是起到一个提升用户体验的效果。
后端校验主要以javax.validation.constraints包为主,通过给Entity添加注解的方式实现,校验功能在类使用前添加@Validated注解。
统一的异常处理:编写异常处理类,使用@ControllerAdvice,使用@ExceptionHandler标注方法可以处理的异常。
分组校验中,分组是通过声明接口的方式创建分组,在使用时指明当前需要使用的校验分组@Validated({AddGroup.class})。
默认没有指定分组的校验注解@NotBlank,在分组校验情况@Validated({AddGroup.class})下不生效,只会在@Validated生效。
标准化产品单元(SPU):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。与类的概念相似,而SKU则与对象的概念比较类似。
因为数据库的表设计中有很多冗余设计,因此在更新值的时候需要考虑相关冗余表的值的更新。
isAuth方法可以在index.js文件中修改返回true,这样就能够增加和删除值。
平台属性#
数据库中的pms_attr表中缺少value_type属性,在后端的实体类中是包含该属性的。
视图对象(VO):接受页面传递来的数据,封装对象;将业务处理完成的对象,封装成页面要用的对象。
直接使用数据库链表操作会非常耗时,我们可以先查出全部结果后再每条结果逐个查询对应的值。
如果想要批量删除数据,可以使用or连接要删除条件,一次性发给数据库,免得多次访问数据库。
记得接受前端的数据时,加上@RequestBody将JSON数据转换成对象。
新增商品#
Controller处理请求,接受和校验数据,Service接受Controller传来的数据,进行业务处理,Controller接受Service处理完的数据,封装成页面指定的VO。
ReferenceError: PubSub is not defined错误后需要安装npm install --save pubsub-js插件,然后在main.js文件中挂载。解决方法
使用gsonformatplus可以将JSON数据转换为java实体类。
在远程调用服务的时候,只要JSON数据模型是兼容的,双方服务无需使用同一个实体类。
TO是各个微服务共用的实体类,写在common微服务中。
由于开启了事务,在debug模式下,在数据库默认读写模式下不能实时看到数据的变化,因此我们可以设置数据为读未提交,这样就能看到实时的变换。
java在进行SQL语句拼接的时候会默认将主键ID认为是自增的,我们可以在实体类的属性中设置@Table(type=IdType.INPUT),用于告诉java这个属性是需要指定的。
在发布商品的时候,商品的附加信息也需要填,否则会出现异常错误。
SPU管理下的规格无法跳转问题的解决方案是在/src/router/index.js在mainRoutes->children里面加上:{ path: '/product-attrupdate', component: _import('modules/product/attrupdate'), name: 'attr-update', meta: { title: '规格维护', isTab: true } }。解决方法
在规格参数中不能回显的元素,在属性菜单把多选改成单选即可回显。因为有过bug,选了多选的规格没有正确保存到数据库中。
基础篇总结#
- 分布式基础概念:微服务、注册中心、配置中心、远程调用、Feign、网关。
- 基础开发:SpringBoot2、SpringCloud、Mybatis-Plus、Vue组件化、阿里云对象存储。
- 环境:Vagrant、Linux、Docker、MySQL、Redis、逆向工程。
- 开发规范:数据校验JSR303、全局跨域处理、逻辑删除、业务状态码。
高级篇#
ElasticSearch#
ElasticSearch是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,可以快速地存储、搜索和分析海量数据。
ElasticSearch的底层是开源库Lucene,ElasticSearch是Lucene的封装,提供REST API的操作接口。
倒排索引概念:将整句分拆为单词,维护一个倒排表记录单词所在的所有整句的索引,按照单词出现的次数从高到低排列。
kibana可视化界面启动会比较慢,多刷新几次就好了。访问地址是:http://192.168.56.10:5601/。
ElasticSearch的访问地址为:http://192.168.56.10:9200/。
ES7开始去掉Type(类型)的概念,因为ElasticSearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在cene中的处理方式是一样的。
基本概念#
- Index(索引):动词,相当于MySQL的insert;名词,相当于MySQL的DataBase。
- Type(类型):在Index中,可以定义一个或多种类型,类似MySQL中的Table,每一种类型的数据放在一起。
- Document(文档):保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的,Document就像是MySQL中的某个Table里面的内容。
实操#
使用Put和Post指定ID,多次发送时会更新版本;Post不指定ID,自动生成唯一标识,Put不指定ID将会报错。
POST 操作和PUT 操作总会将数据重新保存并增加version 版本。POST带_update对比元数据如果一样就不进行任何操作。
bulk批量API:POST customer/external/_bulk。
全文检索字段用 match,其他非 text 字段匹配用 term。
聚合提供了从数据中分组和提取数据的能力。
Mapping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
对于已经存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移。
PDF上的ik分词器链接上写着是7.4.2版本,但实际上是5.6.11版本,版本不对应会导致ES不能正常运行。
修改/usr/share/elasticsearch/plugins/ik/config/中的 IKAnalyzer.cfg.xml即可自定义分词的词库,这里选择使用Nginx地址保存词库信息。
整合#
在导入依赖后需要自己再检查一遍是不是对应版本,因为SpringBoot版本中也指定了ES的版本,如果不对应的话,需要在Maven文件中指定。
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
<spring-cloud.version>Greenwich.SR3</spring-cloud.version>
</properties>
遇到pom文件被ignored的原因可能是之前删除了一个模块,又新建同名模块。解决方法也很简单,我们只需在设置中Maven中取消ignored即可。解决方法
IDEA复制maven模块导致sources root复用了另一个模块,解决方法是删除文件路径,重新设置正确的文件路径。解决方法
商城业务#
商品上架#
ES会对数组进行扁平化处理,会将对象的相同属性的多个值按属性合并成多个数组,这会影响我们的检索,因此我们可以使用nested标注这个是嵌入式的,不进行扁平化处理。
如果IDEA上传代码的github失败,可以在git的Log中执行Undo操作,然后重新上传。
弹幕说P132通过修改R的泛型的方法可能会导致传输过去的数据是null。
idea修改代码重启不生效,需要maven compile才生效这个方法好像没有用,而且新创建的iml文件还导致项目启动不起来,需要删除文件后才能启动。
java.lang.IllegalStateException: Duplicate key异常解决
首页#
每一个微服务都可以独立部署、运行、升级独立自治。
idea运行项目 程序包org.springframework..xxx不存在的解决办法
想要在不重启服务器的情况下,实时变化HTML页面,可以使用devtools依赖,然后在HTML页面执行ctrl+F9重新编译页面,而且要记得关闭缓存选项。
Nginx#
想要便捷地修改host地址,可以使用SwitchHosts软件。
让Nginx进行反向代理,所有来自原gulimall.com的请求都转到商品服务。
Nginx代理给网关的时候,会丢失请求的Host等信息,需要在proxy_set_header配置项中填写。
Nginx直接代理给网关,网关判断如果是/api/**则转交给对应的服务器,如果满足域名则转交给对应的服务。
检索业务#
有个小bug,图片地址是http://search.gulimall.com/static/search/img的访问不了,反而是http://search.gulimall.com/static/search//img/这种有双/的显示成功。
*.gulimall.com不包括gulimall.com,因此需要单独写。
有个bug,需要跳转的是gulimall,但是js文件中写的是gmall,因此需要修改gmall的去nginx下的html/static/index/js,把catelogLoader中搜索gmall,替换为gulimall。修改的时候要注意,是否在最新的页面上修改。
感觉考虑的不够周全,其实也有可能是点击二级分类进入检索的。
ES中的嵌入式数据的操作和普通数据的操作是不一样的。
由于原来的ES的mapping设置了不能检索,因此用一个新的mapping叫做gulimall_product。
用于去除是否仅显示有货的正则表达式应该是'/[?|&](hasS tock=)([^&]*),视频中的写法会残留一个&。
搜索框进行拼接的时候,调用函数应该使用false,而不是true。
java对空格进行了特殊的处理,将空格替换成加号,而浏览器替换成%20,因此在接受前端的参数时要注意这个问题。
前端中th操作有优先级问题,应该在外边声明变量后,在内部使用,不然会被覆盖。
品牌的面包屑会显示null,需要解决。
异步与线程池#
在实际应用中,我们不会逐个创建线程,而是将所有的多线程异步任务都交给线程池执行,因为线程池可以控制资源,性能稳定。
线程池的七大参数:核心线程数、最大线程数量、存活时间、时间单位、阻塞队列、线程的创建工厂、句柄。
阻塞队列需要我们设置一个合理的长度,默认太长可能会导致内存溢出。
CompletableFuture用于进行异步编排。
whenComplete可以处理正常和异常的计算结果,exceptionally处理异常情况。
handle和complete一样,可对结果做最后的处理(可处理异常),可改变返回值。
带Async后缀的默认异步执行,开启一个新线程, 不带该后缀的使用上一个函数传递的线程。
thenApply方法接受上一步结果,并有返回值;thenAccept方法接受上一步结果,没有返回值;thenRun方法不接受上一步结果。
allOf等待所有任务完成;anyOf只要有一个任务完成。使用get方法等待执行。
运行流程
-
线程池创建,准备好 core 数量的核心线程,准备接受任务。弹幕说是线程池需要执行任务才创建核心线程。
-
新的任务进来,用 core 准备好的空闲线程执行。
- core 满了,就将再进来的任务放入阻塞队列中。空闲的 core 就会自己去阻塞队
列获取任务执行。 - 阻塞队列满了,就直接开新线程执行,最大只能开到 max 指定的数量。
- max 都执行好了。Max-core 数量空闲的线程会在 keepAliveTime 指定的时间后自动销毁。最终保持到 core 大小。
- 如果线程数开到了 max 的数量,还有新任务进来,就会使用 reject 指定的拒绝策略进行处理。
- core 满了,就将再进来的任务放入阻塞队列中。空闲的 core 就会自己去阻塞队
-
所有的线程创建都是由指定的 factory 创建的。
商品详情#
MyBatis里面的xml文件不能引用内部类,需要写单独的VO。
需要自定义resultMap的时候,注意自定义的ID和resultMap对应。
认证服务#
在没有指定依赖版本的情况下,需要dependencyManagement来管理依赖版本。
java.lang.IllegalStateException: Error processing condition on org.springframework.boot.autoconfigur是版本冲突的问题,可以在pom文件中使用快捷键Ctrl + Alt + Shift + u查看版本,红线代表冲突。
遇到一个bug,本来是需要导依赖的,导完之后版本冲突,然后把导的依赖全删掉就可以了,应该是原有的依赖就可以了,新导入反而造成版本冲突。
如果我们返回的是JSON数据,需要在方法上加上@ResponseBody注解。
使用的短信接口不支持发送复杂的字符,之前间歇性收不到短信的原因是使用UUID的字符不符合要求,现在先使用1234作为验证码。但是视频中将code和时间组合起来,感觉要拆开了。
测试套餐,验证码值只能是数字,升级套餐申请自己的签名后,可以使用数字,数字+字母,字母等值,且长度在10以内。申请了签名并且修改的代码中的签名代码,现在可以发送字母了。
目前参考的版本是github版本,因为Gitee的前端页面涉嫌违规,看不了。
使用转发跳转网页的时候,会保持原有的方式,例如POST保持为POST等,因此在请求方式有变化的情况下,应该使用重定向。
想要在重定向中传递数据,可以使用RedirectAttributes这个类。原理是利用session,将数据放在session中,一旦跳到下一个页面取出该数据后会将其删除。因此存在分布式中session的问题。
因为有专门破解MD5的网站,破解的方法是暴力破解,因此需要加盐处理,一般是直接使用BCryptPasswordEncoder。
在编写代码的时候最好不要使用VPN,好像会对路由造成影响。
现在有个bug就是login.html页面跳转不了,会直接跳http://auth.gulimall.com/,目前是使用index页面来替代功能,现在有个奇怪的现象,在360浏览器可以显示,但是在edge浏览器不行。解决方案是清理缓存。
登录的账号是我的手机号,密码是123456。
OAuth2.0由于微博的需要认证,因此先使用gitee的API接口。参考文档
OAuth2.0中的code用于AccessToken,只能用一次,而AccessToken在一段时间内是不会变化的,因此在过期时间内都可以使用。
由于gitee传回来的参数没有UID,因此我们使用create_at作为唯一标识,而且该参数是Long型的,这也导致一个问题就是create_at是会变化的,因此会一直往数据库插入数据。解决方法也很简单,只要使用AccessToken查询ID即可,由于不影响项目运行,暂时不处理该问题。
Session共享问题:同一个服务复制多份,session不同步问题;不同服务,不同域名下session不能共享问题。
Session共享问题解决想法:session复制、客户端存储、hash一致性、统一存储。前两种基本不使用,一般使用统一存储。
解决不同域名下不能共享问题可以使用设置作用域的方式,将作用域放大到全体可用。
购物车#
京东的未登录的购物车是往cookie里面放一个user-key的方法来辨别用户。
ThreadLocal同一个线程共享数据。
消息队列#
消息队列的应用场景有:异步处理、消息解耦、流量控制。
消息队列的两大规范,JMS是sun公司推出的基于java消息队列的规范,AMQP是跨平台的网络线级协议。
安装RabbitMQ镜像docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management。
RabbMQ的后台管理的默认账号密码都是guest。
使用AmqpAdmin创建交换机、队列和绑定;使用RabbitTemplate进行发送消息。
发送的消息是对象的话,会进行序列化,因此要求对象必须实现序列化接口。或者可以实现转换器,将其转换为JSON。
@RabbitListener用于指定接受指定队列的信息,@RabbitHandler标注在方法上可以重载区分不同的消息。
订单服务#
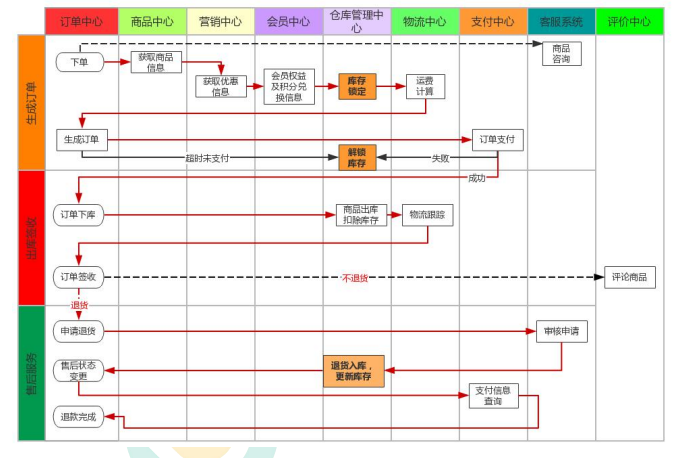
项目的小问题是购物车的价格是加入时候的价格,当价格变化的时候购物车不会自动修改,因此在结算前需要先更新商品的价格。
Feign在远程调用之前要构造一个新的请求,调用很多的拦截器。Feign远程调用丢失请求头问题,因此需要使用Feign远程调用的请求拦截器添加请求头信息。
Feign在异步情况下丢失上下文,因为使用Threadlocal来保存值,如果进程切换了,那么消息就丢失了。
模版渲染错误,可能是JSON数据没有标注@ResonseBody。该注解的作用是将方法的返回值,以特定的格式写入到response的body区域,进而将数据返回给客户端。当方法上面没有写ResponseBody,底层会将方法的返回值封装为ModelAndView对象。
有货和无货的判断和视频的不一样,视频是新建了一个属性。
运费的计算是选取电话号码的最后一位。
接口幂等性指用户对于同一操作发起的一次请求或者多次请求的结果是一致的。
因为之前使用了分布式事务,放在了common中,并且其他模块没有配置seata文件,因此启动错误,考虑到之后不使用seata进行分布式管理,因此直接将其删除了。
要注意之前在config里面创建的消费者,否则它消费了消息,项目中的消费者就无法消费了。
消息丢失是最需要考虑的问题。
支付部分讲的太差了,拦截器各种bug,由于和之前项目也差不多,都是调用API完成任务,因此跳过该部分。
支付和秒杀部分仅仅是听了,但是没有跟着写代码。
秒杀服务#
Cron表达式用于写定时任务,使用@EnableScheduling,在Spring中,Cron表达式不支持年的写法,且在周的位置上从1-7分别代表周一到周日。
Cron默认是阻塞的,会等待上一个任务完成后再执行,如果想要改变,可以让定时任务异步执行来避免阻塞等待。
秒杀(高并发)系统关注的问题:服务单一职责和独立部署、秒杀链接加密、仓库预热+快速扣减、动静分离、恶意请求拦截、流量错峰、限流&熔断&降级、队列削峰。
分布式事务#
目前通过抛异常的方式来回滚,可能会遇到因为超时异常的假失败情况,还有无法回滚已经执行的远程调用。
事务注解是使用代理对象来控制的,如果是在同一个文件中,那么被调用的函数的注解将会失效,按照调用它的函数的注解。本地事务同一个对象内事务方法互相调用默认失效。解决方法是引入aop-starter。
分布式系统经常出现的异常:机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失。
分布式系统中实现一致性的算法RAFT算法,基本思想是主从复制。
BASE理论:基本可用、软状态和最终一致性。
给分布式大事务的入口标注@GlobalTransaction,给每个远程的小事务标注Transaction。
Seata的AT模式面对高并发场景性能不够好,为了保证高并发,库存服务通过发送消息的方式自行回滚。
性能压测#
压力测试#
压力测试考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在。
使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是:内存泄漏,并发与同步。
有效的压力测试系统将应用以下这些关键条件:重复,并发,量级,随机变化。
从外部看,性能测试主要关注以下三个指标:吞吐量、响应时间和错误率。
启动JMeter只需点击bin/jmeter.bat。
性能监控#
影响性能的因素:数据库、应用程序、中间件、网络和操作系统等方面。首先考虑是属于CPU密集型还是IO密集型。
所有的对象实例以及数组都要在堆上分配,因此这是我们调优的重点。
java性能监控主要使用jvisualvm,安装java环境后在命令行输入jvisualvm启动即可,可以安装Visual GC插件更好地监控内存。
优化#
中间件越多,性能损失越大,大多都损失在网络交互上。
JMeter在访问的时候默认不获取HTML文件中所有内含的资源,可以在高级设置中设置获取,这样更加真实。
优化的方向:数据库、模版的渲染速度、静态资源。
动静分离:所有项目的静态资源都放在Nginx里面,规定/static/**的所有请求由Nginx直接返回。
遇到了访问Gateway503的错误码,尝试了其他网站都可以,就是首页无法访问,就是Product服务不可用,后来发现是没有注册上nacos,原因是10000端口又被占用了,而且这次占用了却没有在命令行报错,而是正常启动了,还是挺奇怪的,目前的解决方法是先用着10002端口。解决方案
遇到问题可以先看看空服务,可以先将空服务删除,然后再重新启动服务就可以正常显示了。
有个小bug是index.html中的第23行<img src="/static/index/img/top_find_logo.png" alt="">中的这个图片是找不到的,但是视频也没有处理。
缓存与分布式锁#
缓存使用#
适合使用缓存的数据:即时性、数据一致性不高的;访问量大且更新频率不高的数据。
给Redis缓存中方JSON字符串,拿出的JSON字符串需要转换成对应的值。
lettuce在5.1.8版本会在压测中出现堆外内存溢出的问题,我们选择切换使用jedis。但是jedis依赖导入不了,暂时搁置。
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。解决方法是将null结果缓存,并加入短暂过期时间。
缓存雪崩:指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到数据库,数据库瞬时压力过重雪崩。解决方法是在失效时间的基础上增加一个随机值。
缓存击穿:对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到数据库。解决方法是加锁。
分布式锁#
Redis占分布式锁在客户端的使用set的时候使用NX选项,在java中是Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");。这样做需要设置过期时间以防死锁。
设置了过期时间后也会出现新的问题就是删锁的时候,锁已经自动过期了,可能会把别人持有的锁删掉,因此需要给锁的值指定一个随机值来确认是否是自己的锁。删除也需要保证是原子操作,因此要结合Lua脚本。
在考虑分布式锁的问题,需要考虑到原子性和时延问题。
使用Redission依赖来实现分布式锁,redisson会进行锁的自动续期,运行期间自动给锁续上新的30s。加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,默认30s后自动删除。
如果自行设定解锁时间则不会自动续期,因此要小心使用,但项目采用自行指定的方法,因为自动续期太耗费性能。
保持数据库与缓存中的数据一致性有两种方案:双写模式和失效模式,但是这两种方式都存在暂时的数据不一致的风险。可以使用Canal中间件来保证一致性。
本系统的一致性解决方案:缓存的所有数据都有过期时间,读写数据的时候加上分布式的读写锁。
SpringCache#
缓存管理器是用于定义规则的,可用于分类管理缓存。
使用了配置类选择JSON格式,但是配置文件的过期时间又失效了,因为自定义配置类不会去读取配置文件信息。因此我们需要自行读取配置文件来进行配置。
存储同一类型的数据,都可以指定成同一个分区。
SpringCache中只有@Cacheable注解有Syn属性,但是也只是本地锁。
常规数据(读多写少,即时性,一致性要求不高的数据),可以使用SpringCache;特殊数据需要自己设计。
常用注解
注解中的key属性是表达式,如果是字符串需要添加单引号。
| 注解 | 作用 |
|---|---|
| @Cacheable | 代表当前方法的结果需要缓存,如果缓存中有,则无需调用 |
| @CacheEvict | 触发将数据从缓存删除的操作 |
| @CachePut | 不影响方法执行更新缓存 |
| @Caching | 组合以上操作 |
| @CacheConfig | 在类级别共享缓存的相同配置 |
Sentinel#
sentinel部分与SpringCloud Alibaba的笔记相同。
高并发有三宝:缓存、异步、队排好。
作者:xiqin
出处:https://www.cnblogs.com/xiqin-huang/p/17898665.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人