


Pandas对象(数据结构)
Pandas是Python的一个扩展程序库,是在Numpy基础上建立的,提供高性能、易使用的数据结构和数据分析工具。
-
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Excel 等中导入数据;
-
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征;
-
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas对象(数据结构)
Pandas 三个基本的数据结构是 :Series (一维数据对象)、 DataFrame(二维数据对象)和 Index(标签对象)。Pandas数据对象可以看成增强版的Numpy数组,不过行列不仅仅只是简单的数据索引,还可以带上标签,是一种显式定义的索引,索引可以是重复的。
Series对象
Series对象是一个带索引数据构成的一维数组。
pandas.Series(data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray、字典、列表类型等)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
In [1]: import pandas as pd
#输入的数组可以是列表或Numpy数组,index默认整数序列
In [2]: data = pd.Series([0.3,0.05,1,30])
In [3]: data
Out[3]:
0 0.30
1 0.05
2 1.00
3 30.00
dtype: float64
In [4]: data.index #Series的索引是一个pd.Index类型对象
Out[4]: RangeIndex(start=0, stop=4, step=1)
In [5]: data[0] #和Numpy一样可以通过整数索引进行取值
Out[5]: 0.3
#添加显性索引,索引会覆盖顺序整数索引,但是两种索引方式都可用
In [8]: data = pd.Series([0.3,0.07,3,4],index=['a','b','c','d'])
In [9]: data
Out[9]:
a 0.30
b 0.07
c 3.00
d 4.00
dtype: float64
In [10]: data[1]
Out[10]: 0.07
In [11]: data['b']
Out[11]: 0.07
#添加显性整数索引,索引会覆盖原来顺序整数索引,原来的顺序整数索引不可用
In [12]: data = pd.Series([0.23,9,3,6],index=[2,7,3,9])
In [13]: data
Out[13]:
2 0.23
7 9.00
3 3.00
9 6.00
dtype: float64
In [14]: data[2]
Out[14]: 0.23
#输入一个字典,index默认为排序的key值
In [15]: population_dict = {'California': 3333333,
'Texas': 233242321,'New York': 43897653,
'Florida':32097644,'Illinois':2222229}
In [16]: population = pd.Series(population_dict)
In [17]: population
Out[17]:
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
dtype: int64
In [18]: population['Texas']
Out[18]: 233242321
#显性索引也具有切片功能
In [19]: population['California':'New York']
Out[19]:
California 3333333
Texas 233242321
New York 43897653
dtype: int64
#也可以输入一个标量,每个索引上都重复赋值
In [20]: pd.Series(3,index=['a','b','c'])
Out[20]:
a 3
b 3
c 3
dtype: int64
#筛选索引应用
In [21]: pd.Series({'a':1,'b':2,'c':3},index=['a','c'])
Out[21]:
a 1
c 3
dtype: int64
DataFrame对象
DataFrame对象可以看成是有序排列的若干Series对象,DataFrame除了有index属性外,还有columns属性。
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
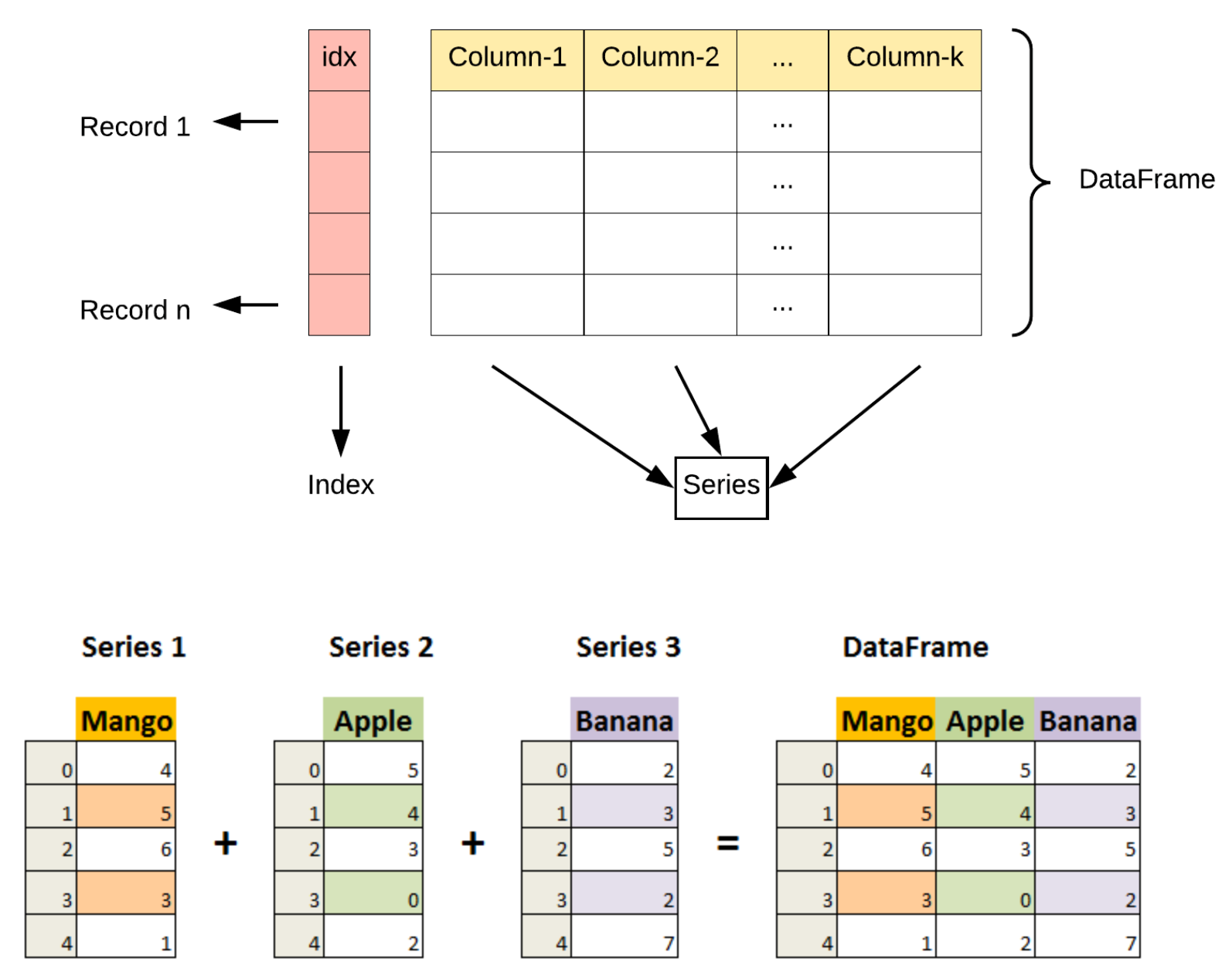
#通过单个Series创建
In [22]: pd.DataFrame(population,columns=['population'])
Out[22]:
population
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
#通过字典列表创建,缺失值用NaN补充
In [23]: data = [{'a':i,'b':i**2} for i in range(5)]
In [24]: pd.DataFrame(data)
Out[24]:
a b
0 0 0
1 1 1
2 2 4
3 3 9
4 4 16
In [25]: pd.DataFrame([{'a':1,'b':2},
{'c':3,'b':4}])
Out[25]:
a b c
0 1.0 2 NaN
1 NaN 4 3.0
#通过Series对象字典创建
In [26]: area = pd.Series({'California': 3883333, 'Texas': 233771,'New York':435653,
'Florida':320644,'Illinois':2224429})
In [27]: area
Out[27]:
California 3883333
Texas 233771
New York 435653
Florida 320644
Illinois 2224429
dtype: int64
In [28]: population
Out[28]:
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
dtype: int64
In [29]: pd.DataFrame({'population':population,'area':area})
Out[29]:
population area
California 3333333 3883333
Texas 233242321 233771
New York 43897653 435653
Florida 32097644 320644
Illinois 2222229 2224429
#通过Numpy二维数组创建
In [30]: import numpy as np
In [31]: pd.DataFrame(np.random.rand(3,2),columns=['a','b'],index=['ff','dd','gg'])
Out[31]:
a b
ff 0.258254 0.591041
dd 0.091217 0.029136
gg 0.822554 0.661956
#通过Numpy结构化数组创建
In [32]: A = np.zeros(3,dtype=[('a','i8'),('b','f8')])
In [33]: A
Out[33]: array([(0, 0.), (0, 0.), (0, 0.)], dtype=[('a', '<i8'), ('b', '<f8')])
In [34]: pd.DataFrame(A)
Out[34]:
a b
0 0 0.0
1 0 0.0
2 0 0.0
Index对象
Series和DataFrame对象的显性索引其实是一个Index对象,可以看做一个不可变的数组或有序集合(元素可以重复)。
In [35]: ind = pd.Index([2,3,5,7])
In [36]: ind
Out[36]: Int64Index([2, 3, 5, 7], dtype='int64')
#可以像数组一样索引
In [37]: ind[1]
Out[37]: 3
In [38]: ind[::2]
Out[38]: Int64Index([2, 5], dtype='int64')
#与数组有相似的属性
In [40]: print(ind.size,ind.shape,ind.ndim,ind.dtype)
4 (4,) 1 int64
#可以进行数集运算
In [41]: indA = pd.Index([1,3,5,7,9])
In [42]: indB = pd.Index([2,3,5,7,8])
In [43]: indA & indB #交集
Out[43]: Int64Index([3, 5, 7], dtype='int64')
In [44]: indA | indB #并集
Out[44]: Int64Index([1, 2, 3, 5, 7, 8, 9], dtype='int64')
In [45]: indA ^ indB #异或
Out[45]: Int64Index([1, 2, 8, 9], dtype='int64')

