


谈谈YOLOv2做了哪些改进
YOLOv2在第一个版本的基础上做了不少的改进,包括网络结构和训练的小技巧,anchor机制的加入,本文将对这些改进做一个梳理。
总览
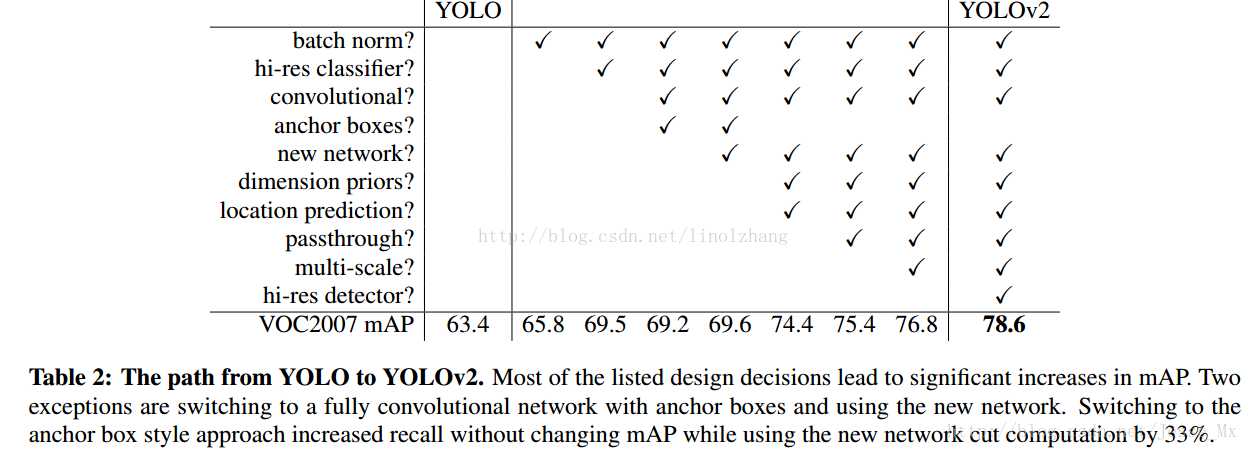
作者的实验结果总结,可以发现有很多的工程性质的trick,背后的理论却不是很多,感觉上是实验性质,能work,还要啥自行车呢?
改进分析
Batch Normalization
这个就像卷积网络中的神器,加上之后又能防止过拟合又能加速收敛。原理上,对每一批训练数据统计通道上的均值和方差,再做归一化处理,预测的时候只有一张图片,统计性质不好,用训练集的期望代表均值和方差。具体原理有很多博文解释,我一直处于不甚明白本质的状态。
加上BN之后有了2个点的提升。
大尺度预训练分类
目标检测的基础网络一般都是从分类网络来的,而且通常采用分类网络的权值初始化。问题在于,分类网络设计时输入尺寸是224,而目标检测对输入尺寸是有要求的,一般输入尺寸越大,准确率越好。这就导致初始化的权重不一定适合检测网络。
预训练初始化,主要目的是初始化浅层的一些卷积核,这些卷积核所提取的特征被认为具有通用性,用448的输入训练分类,再作为初始化会比224的好很多,提升了4个点!
新网络和跳跃结构
用了性能更好的网络,加上了passthrough层,该层将\(26 \times 26 \times 512\)的浅层特征,通过一定的组合转换成\(13 \times 13 \times 2048\)的特征图,再与网络深层对应空间大小的特征图融合,提升1个点多。
多尺度训练
这个不太明白,也是trick吧,确实有作用,能提升1个点!
anchor机制
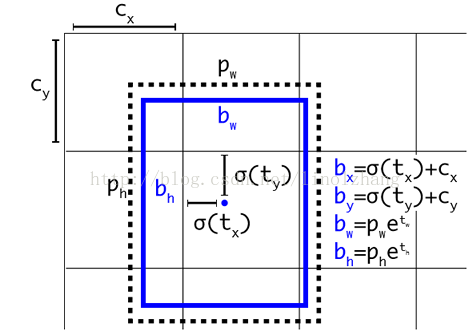
每个网格对应5个box,并且这5个box的类别可以不同,具有先验的wh,wh是对数据集的聚类分析得到的。
cxcy仍然和v1一样,是距离当前网格左上角的偏差,并被归一化到0-1之间,而宽高则变为相对于匹配的anchor的宽高,匹配anchor应该是根据IOU来的。
anchor机制的目标如下图所示
对v2的一些个人理解
对于网络和训练上的改进,就不多说了,说一下anchor机制。
v2和v1有哪些差别?v2每个网格的box自带wh,可以为不同的类别,我觉得这就是最大的差别,v2网格的每个box更合理一些。这样的好处:1.对聚集的小目标更好;2.对不同大小的目标匹配不同的anchor box,计算wh时有各自的基准wh。
YOLO的anchor与SSD的有什么不同?1.YOLO固定了anchor box的中心点范围;2.匹配机制不同,YOLO根据目标中心点确定网格,再从网格中选择合适的box,貌似不存在匹配不到的情况,SSD根据IOU大小匹配,有些位置出现的某些大小的目标IOU都小于阈值,只能匹配一个IOU最大的;3.anchor box的宽高设置上,YOLO对数据集作聚类分析,其实SSD也可以借鉴了,这种聚类分析受到数据集的影响,对新数据集可能要重做一遍才比较好,泛化性不强。
