并发编程笔记
创建线程
Thread
重写run方法
Thread thread = new Thread(){
@Override
public void run() {
LOGGER.debug("run thread");
}
};
thread.start();
Runnable
实现Runnable接口,作为参数传递到Thread类
// Runnable runnable = new Runnable() {
// public void run() {
// LOGGER.debug("run thread");
// }
// };
// lambda
Runnable runnable = () -> LOGGER.debug("run thread");
Thread thread = new Thread(runnable, "t1");
thread.start();
Thread类中的Runnable
当成员target不为空时执行target的run方法
class Thread{
private Runnable target;
Thread(Runnable target){
this.target = target;
}
@Override
public void run() {
if (target != null) {
target.run();
}
}
Callbale
Callable 区别与 Runnable : 有返回值且抛异常
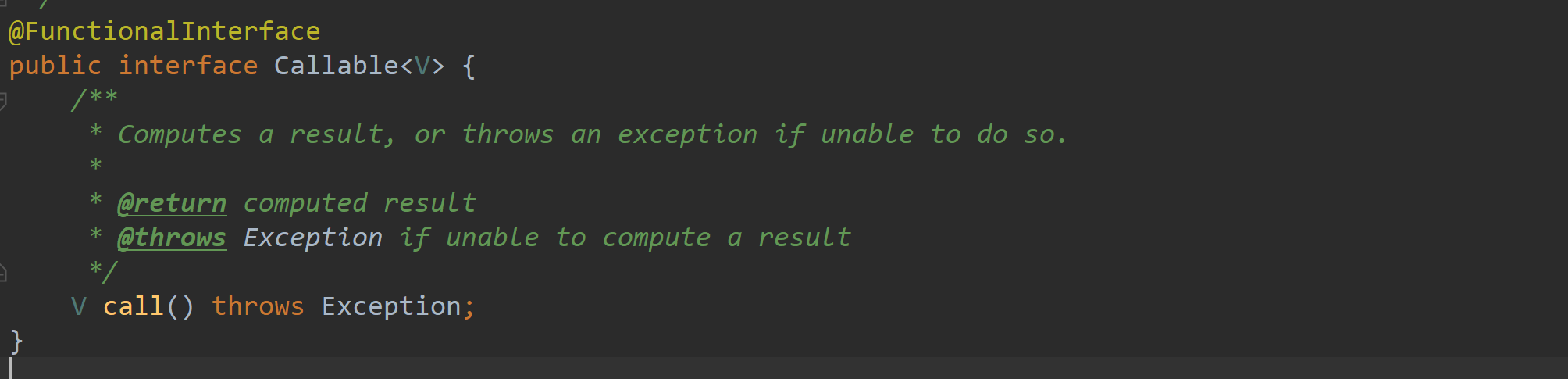
FutureTask futureTask = new FutureTask<>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
Thread.sleep(2000);
LOGGER.debug("run thread");
return 1;
}
});
Thread t2 = new Thread(futureTask, "t2");
t2.start();
// 打印返回结果,堵塞2s
Object o = futureTask.get();
LOGGER.debug("{}", o);
Future接口
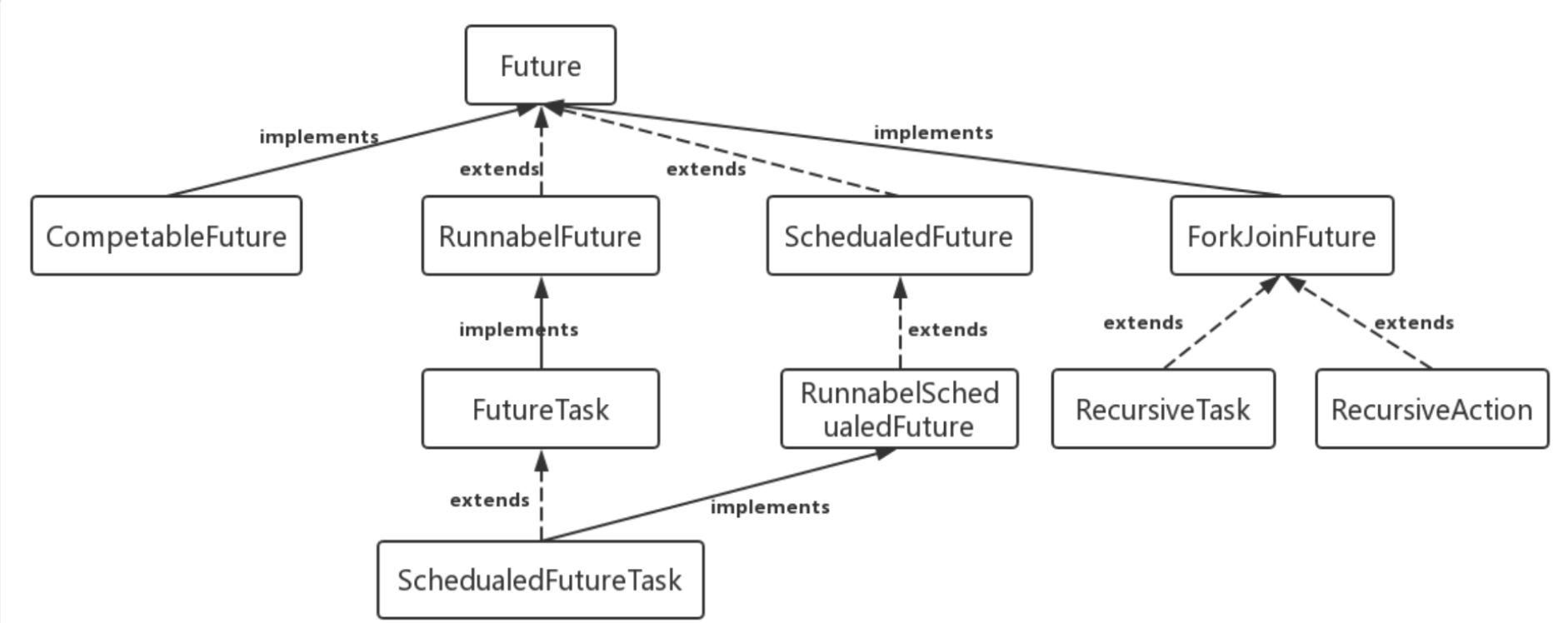
FutureTask实现了RunnableFuture,又实现Runnable、Future接口,了线程返回值等方法
public interface RunnableFuture<V> extends Runnable, Future<V> {
线程栈
- 虚拟机栈:每个线程都会有一个独立的栈
- 栈帧:线程中每个方法都是一个栈帧,栈帧中保存了该函数的返回地址和局部变量等信息
- 活动栈帧:每个线程只有一个活动栈帧,就是正在执行的方法
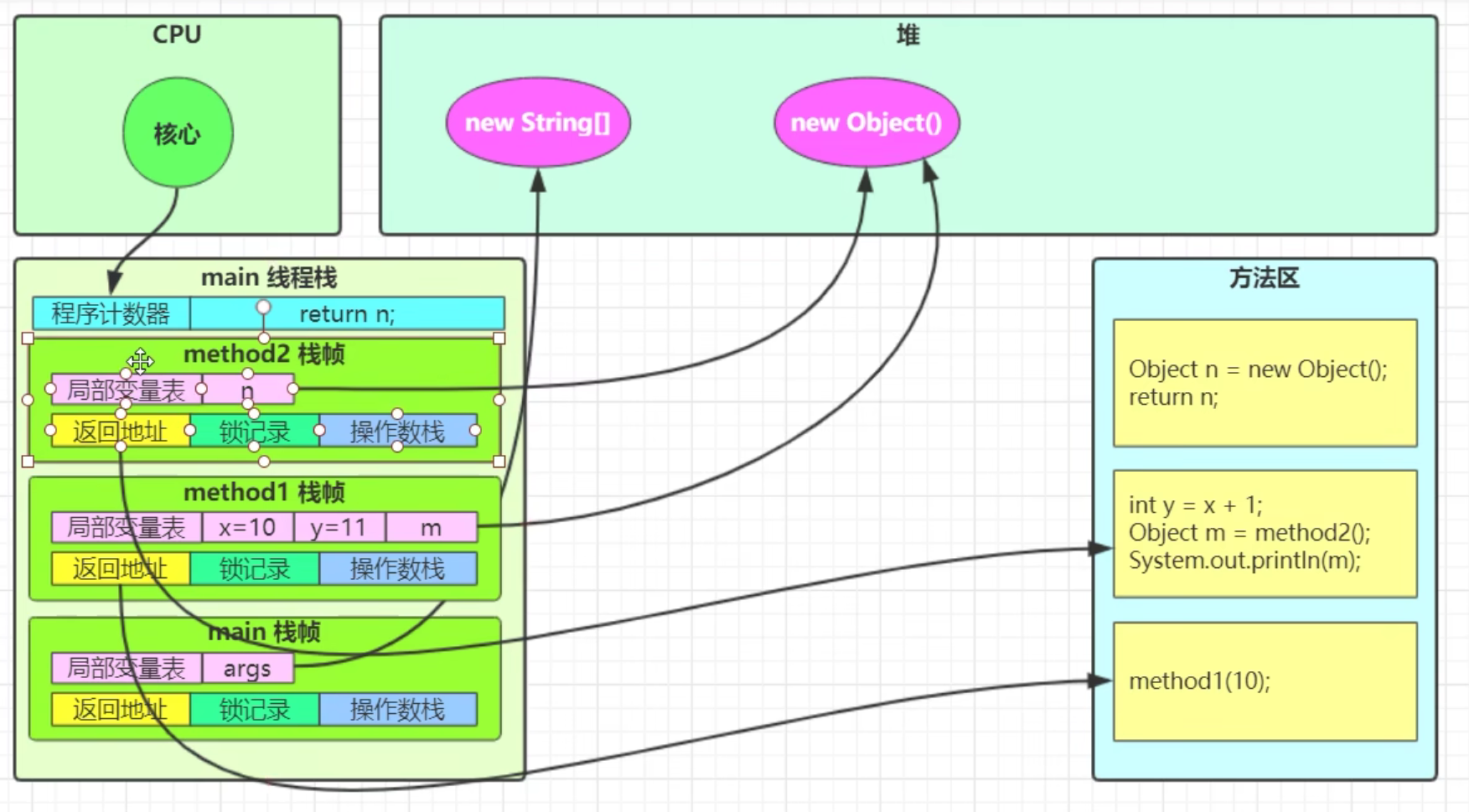
线程上下文切换
因为以下一些原因导致cpu不再执行当前的线程,转而执行另一个线程的代码。
发生的原因,有如下几个:
- 线程的cpu时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了sleep,yield,wait,join,park,sychronized,lock等方法
线程通讯
wait、notify
- obj.wait(); 让object监视器的线程等待
- obj.notify(); 让object上正在等待的线程中挑一个唤醒
- obj.notifyAll(); 让object上正在等待的线程全部唤醒
new Thread(() -> {
synchronized (lock) {
try {
log.info("thread {} start..", Thread.currentThread().getName());
//lock.wait();
lock.wait(1000);
log.info("thread {} end..", Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1").start();
// Thread.sleep(2000);
// synchronized (lock) {
// lock.notify();
// }
log.info("main end..");
解决虚假唤醒
Park&Unpark
park方法的作用就是停下一个线程,unpark就是唤醒线程
Park&Unpark实现交替执行
/**
* 输出:abcabcabcabcabc
*/
public class PackAndUnpack {
static Thread t1;
static Thread t2;
static Thread t3;
public static void main(String[] args) throws InterruptedException {
t1 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
LockSupport.park();
System.out.print("a");
LockSupport.unpark(t2);
}
}, "t1");
t2 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
LockSupport.park();
System.out.print("b");
LockSupport.unpark(t3);
}
}, "t2");
t3 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
LockSupport.park();
System.out.print("c");
LockSupport.unpark(t1);
}
}, "t3");
t1.start();
t2.start();
t3.start();
LockSupport.unpark(t1);
}
}
线程安全
临界区
一段代码块内如果存在对共享资源的多线程读写操作,这段代码块成为临界区
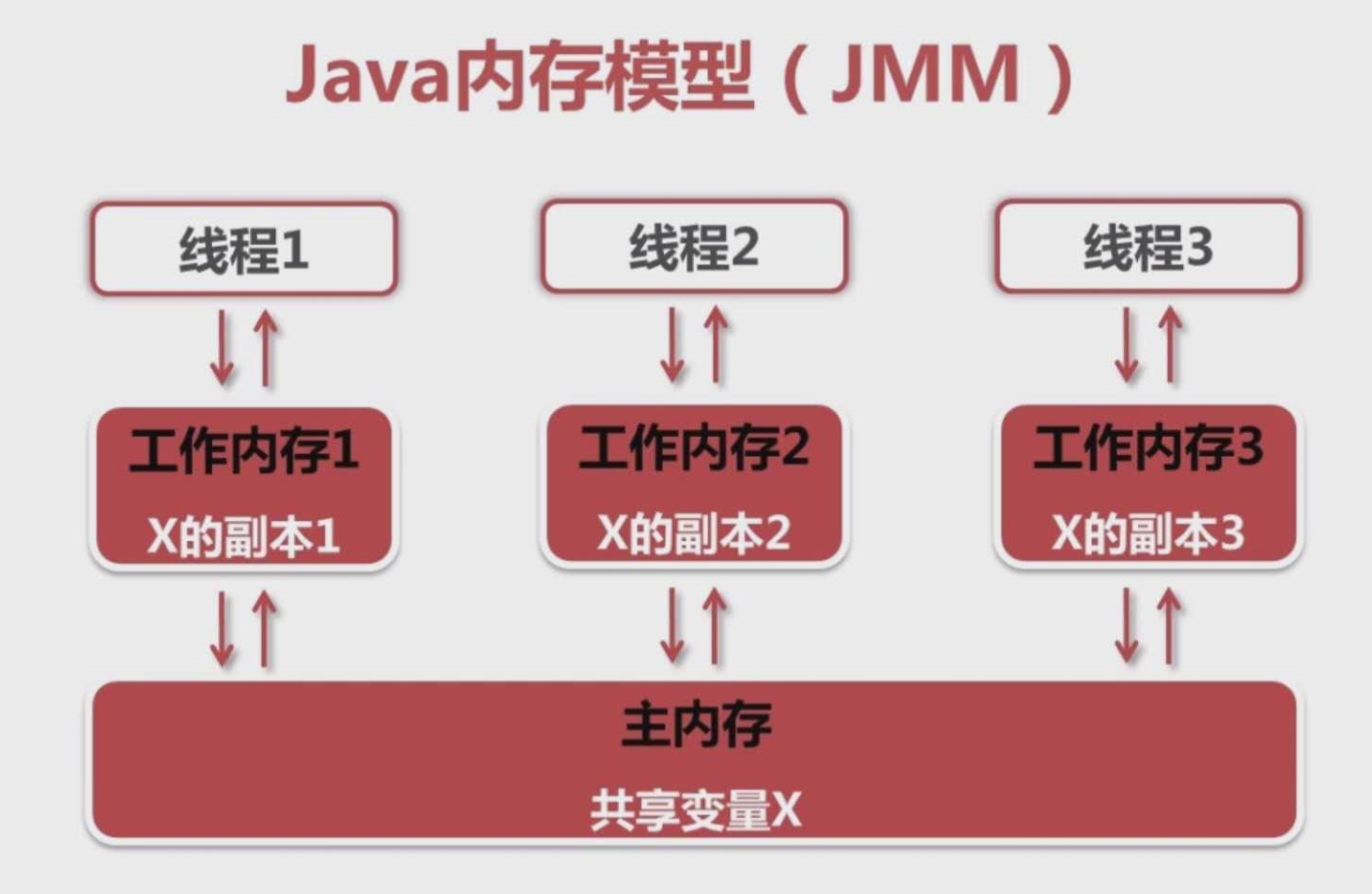
可见性
可见性是指当一个线程修改了共享变量的值,其它线程能够适时得知这个修改共享变量:如果一个变量在多个线程的内存中都存在副本,那么这个变量就是这几个线程的共享变量
有序性
有序性:编译器为了优化性能,有时候会改变程序中语句的先后顺序(指令重排),有序性指的是程序按照代码的先后顺序执行
synchronized
- 修饰实例方法:作用于当前对象实例加锁,进入同步代码前要获得 当前对象的实例锁
- 修饰静态方法:相当于给当前对象加锁,会作用域类的所有对象实例,进入同步代码前要获得当前class的锁。因为静态成员不属于任何一个类对象,(无论多少个对象都只有一份)。
- 修饰代码块:指定加锁对象,对给定对象/类加锁,synchronized(this|object)表示进入同步代码块一定要获得该锁
1、synchronized关键字加到static静态方法和synchronized(class)代码块上实质都是给Class类上锁。
2、synchronized关键字加到实例方法上是给对象实例上锁
3、尽量不要使用synchronized(String a)因为jvm中,字符串常量池具有缓存功能
volatile
volatile关键字是用于保证有序性和可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值
- 保证可见性
volatile保证可见性底层原理是
内存屏障
1.对volatile变量进行写指令时,加入写屏障
2.对volatile变量进行读指令时,加入读屏障
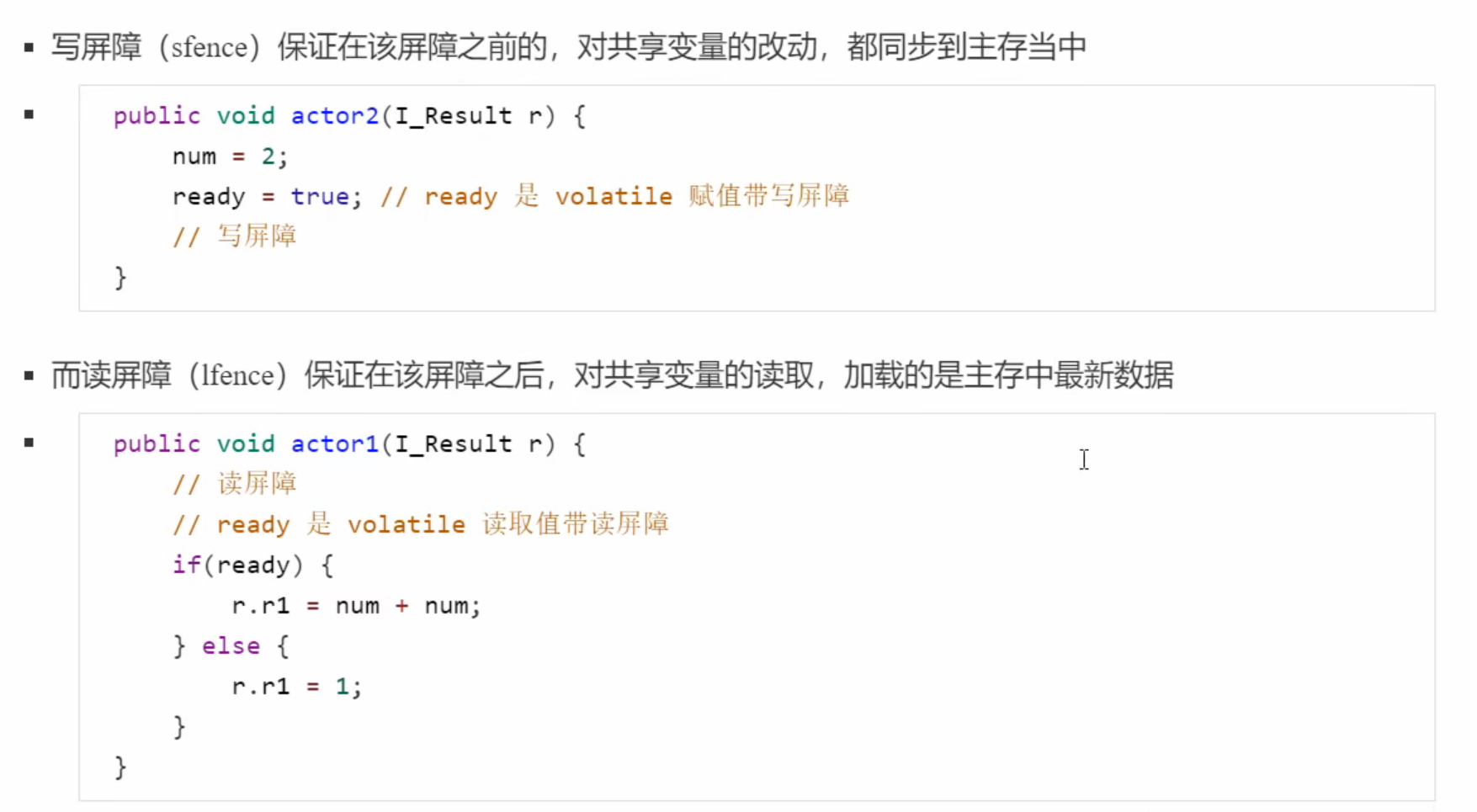
- 保证有序性
内存屏障同样保证了指令的有序性,禁用指令重排序
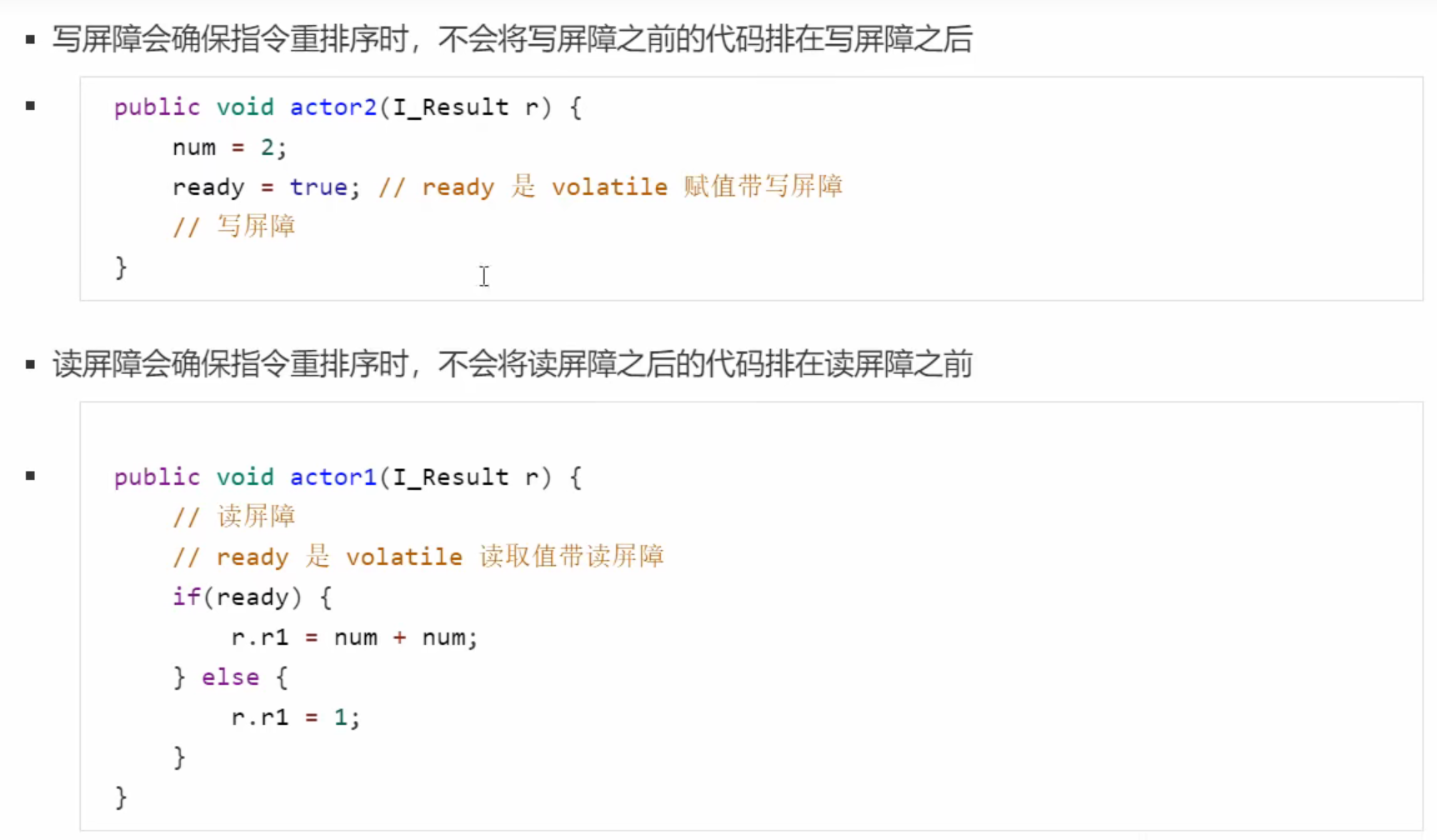
happens-before
happens-before是保证程序执行的原子性、可见性和有序性规则:
1、程序顺序原则。即在一个线程内必须保证语义的串行性(as-if-serial),也就是说按照代码顺序执行;
2、锁原则。解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之前,也就是说,在一个锁被解锁后,再加锁,那么加锁的动作必须在解锁动作之后(操作同一个锁);
3、volatile原则。volatile变量的写,发生与读之前,这样保证了volatile变量的可见性。简单理解就是volatile变量在每次被线程访问时,都强迫于从主内存中读取该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时候,不同的线程总能看到该变量的最新值;
4、线程启动原则。线程的start()方法先于它的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见;
5、传递性。A先于B,B先于C,那么A必然先于C;
6、线程终止原则。线程的所有操作先于线程的终结,Thread.join()方法的作用是等待当前执行的线程终止。假设在线程B在终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见;
7、线程中断原则。对线程interrupt()方法的调用先发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否中断;
8、对象的终结原则。对象的构造函数执行,结束先于finalize方法
ReentrantLock
特点:
1.可中断
2.可以设置超时时间
3.可以设置为公平锁
4.支持多个条件变量
基本语法
// 获取锁
reentrantLock.lock();
try {
// 临界区
} finally {
// 释放锁
reentrantLock.unlock();
}
可重入
ReentrantLock 可重入锁:一个线程可以多次获取同一把锁·
static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
method1();
}
public static void method1() {
lock.lock();
try {
log.debug("execute method1");
method2();
} finally {
lock.unlock();
}
}
public static void method2() {
lock.lock();
try {
log.debug("execute method2");
method3();
} finally {
lock.unlock();
}
}
public static void method3() {
lock.lock();
try {
log.debug("execute method3");
} finally {
lock.unlock();
}
}
可打断
lockInterruptibly()方法有竞争就进入阻塞队列等待,但可以被打断
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
log.debug("启动...");
try {
//没有竞争就会获取锁
//有竞争就进入阻塞队列等待,但可以被打断
lock.lockInterruptibly();
//lock.lock(); //不可打断
} catch (InterruptedException e) {
e.printStackTrace();
log.debug("等锁的过程中被打断");
return;
}
try {
log.debug("获得了锁");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("获得了锁");
t1.start();
try {
sleep(1);
log.debug("执行打断");
t1.interrupt();
} finally {
lock.unlock();
}
锁(可设置)超时
- tryLock() 方法可指定超时时间,超时后释放锁
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
log.debug("启动...");
try {
if (!lock.tryLock(1, TimeUnit.SECONDS)) {
log.debug("获取等待 1s 后失败,返回");
return;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
log.debug("获得了锁");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("获得了锁");
t1.start();
try {
sleep(2);
} finally {
lock.unlock();
}
(可设置是否为)公平锁
公平: 先来就能先执行
不公平: 不保证先来就先执行
- ReentrantLock 默认非公平锁,可在构造方法中指定为公平锁
ReentrantLock lock = new ReentrantLock(false);
(多个)条件变量
条件变量最主要的作用是用来管理线程执行对某些状态的依赖性
ReentrantLock可针对多个Condition,每个Condition处理不同逻辑
static ReentrantLock lock = new ReentrantLock();
static Condition waitCigaretteQueue = lock.newCondition();
static Condition waitbreakfastQueue = lock.newCondition();
static volatile boolean hasCigrette = false;
static volatile boolean hasBreakfast = false;
public static void main(String[] args) {
new Thread(() -> {
try {
lock.lock();
while (!hasCigrette) {
try {
waitCigaretteQueue.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("等到了它的烟");
} finally {
lock.unlock();
}
}).start();
new Thread(() -> {
try {
lock.lock();
while (!hasBreakfast) {
try {
waitbreakfastQueue.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("等到了它的早餐");
} finally {
lock.unlock();
}
}).start();
sleep(1);
sendBreakfast();
sleep(1);
sendCigarette();
}
private static void sendCigarette() {
lock.lock();
try {
log.debug("送烟来了");
hasCigrette = true;
waitCigaretteQueue.signal();
} finally {
lock.unlock();
}
}
private static void sendBreakfast() {
lock.lock();
try {
log.debug("送早餐来了");
hasBreakfast = true;
waitbreakfastQueue.signal();
} finally {
lock.unlock();
}
}
CAS
原子类的compareAndSet方法,比较要修改的值和最新的值是一致,一致则更新
- CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
/**
* 无锁实现共享资源的安全性
*/
public class CasDemo {
public static void main(String[] args) {
Account account = new AccountSync(10000);
Account.demo(account);
Account account2 = new AccountSafe(10000);
Account.demo(account2);
}
}
/**
* 无锁方式,原子类(重试)
*/
class AccountSafe implements Account {
private AtomicInteger balance; //原子整数
public AccountSafe(Integer balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return balance.get();
}
@Override
public void withdraw(Integer amount) {
while (true) {
int prev = balance.get();
int next = prev - amount;
// 判断balance和prev是否相等
if (balance.compareAndSet(prev, next)) {
break;
}
}
// 可以简化为下面的方法
// balance.addAndGet(-1 * amount);
}
}
/**
* 同步锁方式(堵塞)
*/
class AccountSync implements Account{
private Integer value;
public AccountSync(Integer value) {
this.value = value;
}
@Override
public Integer getBalance() {
return value;
}
@Override
public synchronized void withdraw(Integer amount) {
value = value - amount;
}
}
interface Account {
// 获取余额
Integer getBalance();
// 取款
void withdraw(Integer amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(Account account) {
List<Thread> ts = new ArrayList<>();
long start = System.nanoTime();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(10);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance()
+ " cost: " + (end-start)/1000_000 + " ms");
}
}
特点:
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
● CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
● synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
● CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
○ 因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
○ 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
原子类
原子整数
● AtomicBoolean
● AtomicInteger
● AtomicLong
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++
System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i
System.out.println(i.incrementAndGet());
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i
System.out.println(i.decrementAndGet());
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i--
System.out.println(i.getAndDecrement());
// 获取并加值(i = 0, 结果 i = 5, 返回 0)
System.out.println(i.getAndAdd(5));
// 加值并获取(i = 5, 结果 i = 0, 返回 0)
System.out.println(i.addAndGet(-5));
// 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.getAndUpdate(p -> p - 2));
// 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.updateAndGet(p -> p + 2));
// 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
// getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
原子引用
● AtomicReference
● AtomicMarkableReference
● AtomicStampedReference
class DecimalAccountSafeCas implements DecimalAccount {
AtomicReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return ref.get();
}
@Override
public void withdraw(BigDecimal amount) {
while (true) {
BigDecimal prev = ref.get();
BigDecimal next = prev.subtract(amount);
if (ref.compareAndSet(prev, next)) {
break;
}
}
}
}
public interface DecimalAccount {
// 获取余额
BigDecimal getBalance();
// 取款
void withdraw(BigDecimal amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(DecimalAccount account) {
List<Thread> ts = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(BigDecimal.TEN);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(account.getBalance());
}
}
ABA 问题
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程希望:
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
// 这个共享变量被它线程修改过?
String prev = ref.get();
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C"));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}
ABA问题的解决
AtomicStampedReference(维护版本号)、AtomicMarkableReference(仅维护是否修改过)
- AtomicStampedReference(维护版本号)
维护一个版本号,每次修改原子类时,版本号递增
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
- AtomicMarkableReference(仅维护是否修改过)
只需要判断原子类是否被修改过
/**
* CAS解决ABA问题:AtomicMarkableReference(仅维护是否修改过)
*/
import java.util.concurrent.atomic.AtomicMarkableReference;
public class AtomicMarkableReferenceDemo {
private static final Logger log= LoggerFactory.getLogger(AtomicMarkableReferenceDemo.class);
static AtomicMarkableReference<String> ref = new AtomicMarkableReference<>("A", true);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
log.debug("是否修改过 {}", !ref.isMarked());
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
Thread.sleep(1000);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", true, false));
}
private static void other() throws InterruptedException {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
true, false));
log.debug("是否修改过 {}", !ref.isMarked());
}, "t1").start();
Thread.sleep(500);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
true, false));
log.debug("是否修改过 {}", !ref.isMarked());
}, "t2").start();
}
}
线程池
ThreadPoolExecutor
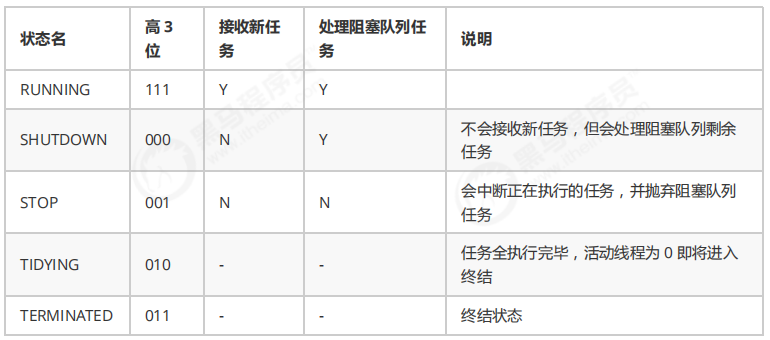
- 线程池状态
hreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值 --
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
ThreadPoolExecutor
● corePoolSize 核心线程数目 (最多保留的线程数)
● maximumPoolSize 最大线程数目
● keepAliveTime 生存时间 - 针对救急线程
● unit 时间单位 - 针对救急线程
● workQueue 阻塞队列
● threadFactory 线程工厂 - 可以为线程创建时起个好名字
● handler 拒绝策略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
工厂方法创建线程池
newFixedThreadPool
适用于任务量已知,相对耗时的任务
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newCachedThreadPool
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。
适合任务数比较密集,但每个任务执行时间较短的情况
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newSingleThreadExecutor
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。
任务执行完毕,这唯一的线程也不会被释放。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
和自己创建一个线程来工作的区别:
● 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
和Executors.newFixedThreadPool(1)的区别
● Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改
○ FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
● Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
○ 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
提交线程池的方法
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
关闭线程池
/*
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
*/
void shutdown();
/*
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
*/
List<Runnable> shutdownNow();
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
应用
public class TestStarvation {
static final List<String> MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(1);
ExecutorService cookPool = Executors.newFixedThreadPool(1);
waiterPool.execute(() -> {
log.debug("处理点餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
waiterPool.execute(() -> {
log.debug("处理点餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗