Kafka 笔记
消息的两种模式
- 点对点模式,消费消息后删除消息
- 发布订阅模式,消息携带主题,消费消息后不删除消息
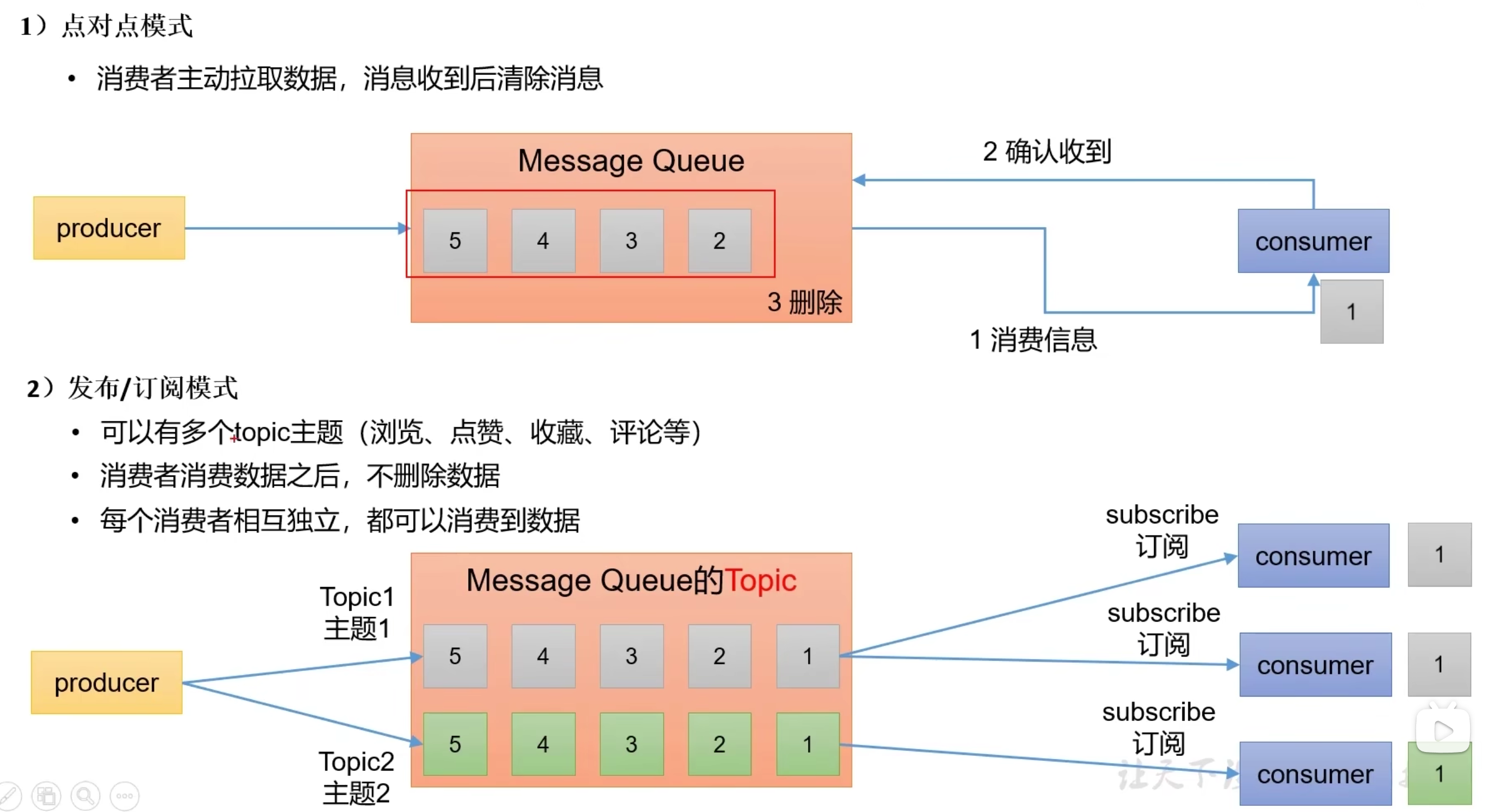
架构
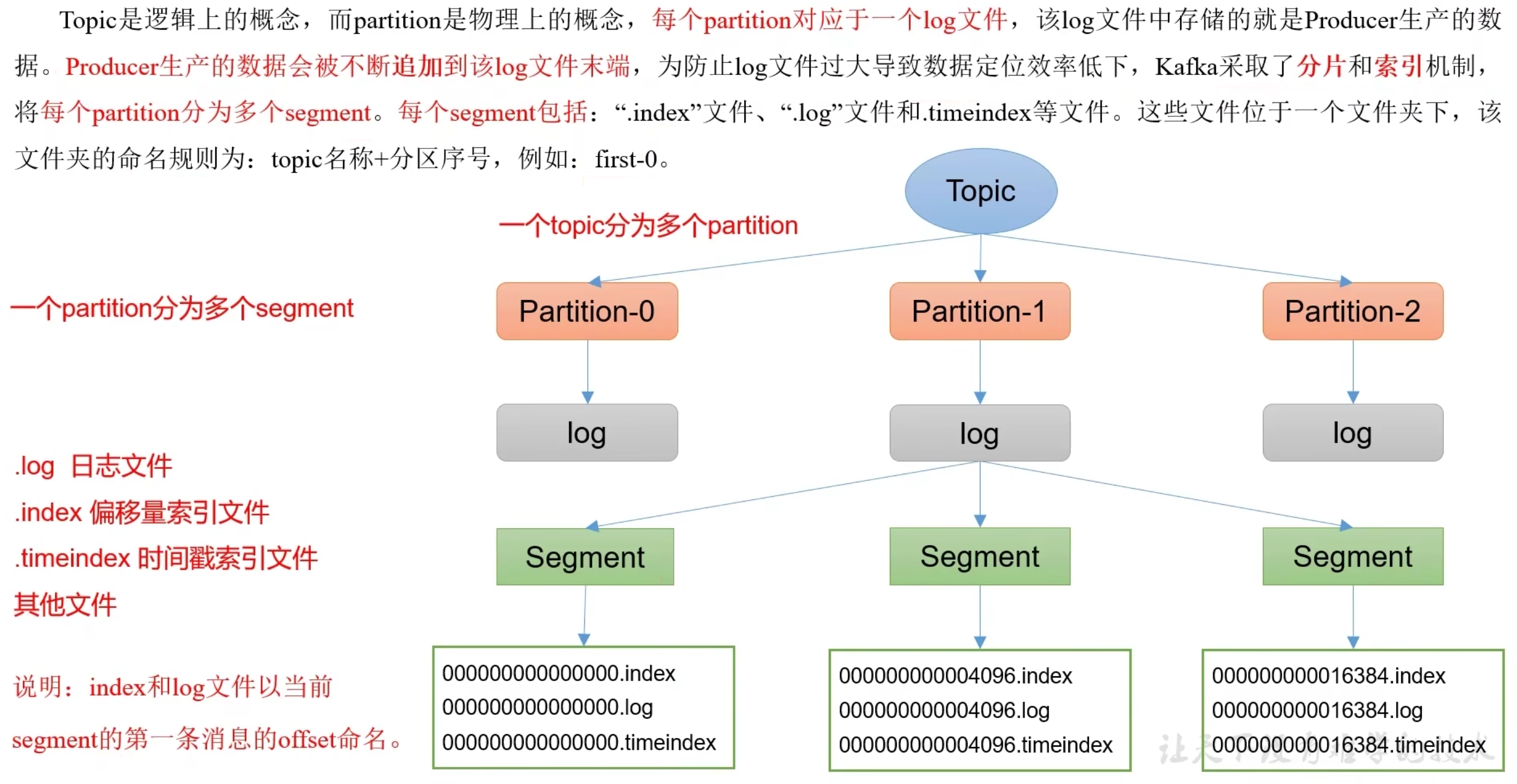
topic是逻辑上的概念,表示消息主题,每个消息都需要指定主题,一个topic分为多个partitionPartition是物理上的概念,每个Partition对应一个log存储,Partition高可用实现了主从备份broker消息代理,生产者指定topic往broker写消息,消费者通过topic从broker拿消息

命令
kafka-topics.sh

创建主题
# 创建test主题,分区数1,分区副本1
KAFKA_HOME/bin/kafka-topics.sh --create --topic test --partitions 1 --zookeeper zookeeper:2181 --replication-factor 1
查看所有主题
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper zookeeper:2181 --list
查看主题详细
$KAFKA_HOME/bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test
kafka-console-producer.sh
发送消息
--topic 指定主题
$KAFKA_HOME/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
kafka-console-consumer.sh
获取实时消息
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
获取历史消息
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
生产者
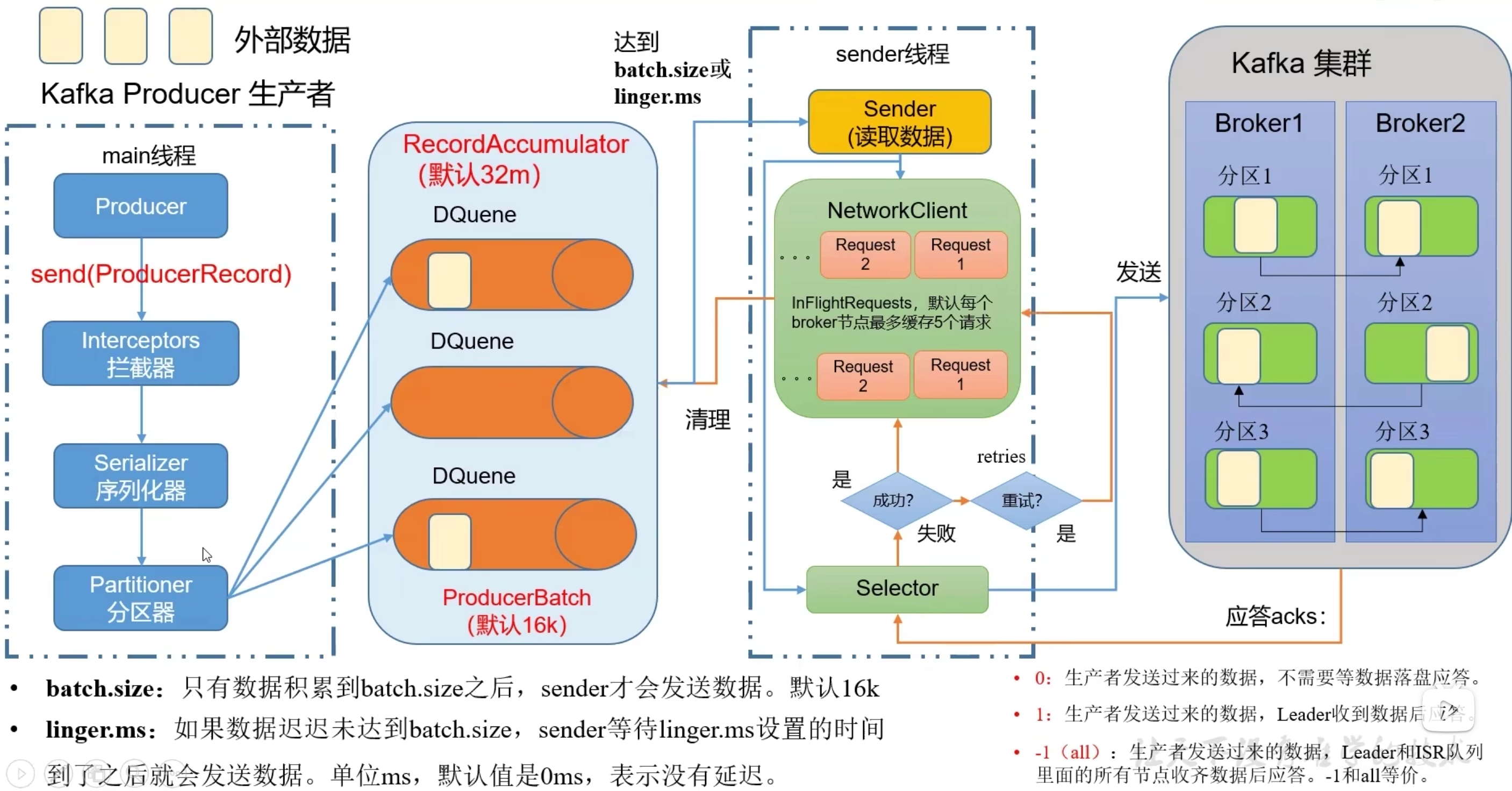
生产者发送流程
生产者主要用2个线程将数据发送到消费者:
1.main线程发送消息到RecordAccumulator
2.sender线程从RecordAccumulator拉取消息,发送到消费者
RecordAccumulator实现是双端队列(队列空间满了或者到一定时间会被读取)
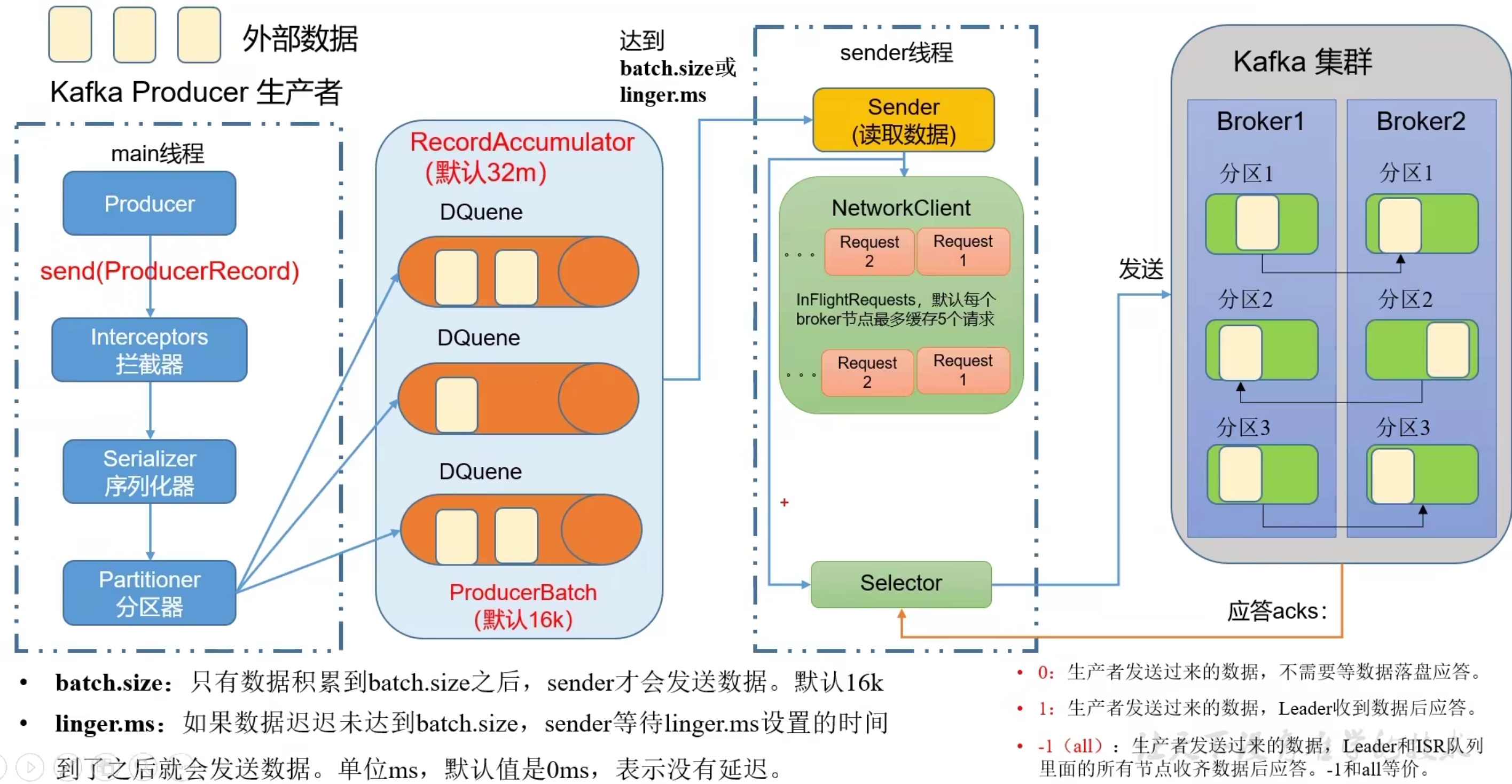
- 应答清理和重试
- 消息发送后应答0、1、-1
- 消息发送失败后可重试,默认重试次数int最大值
- 消息发送成功后清除消息
-
消息发送
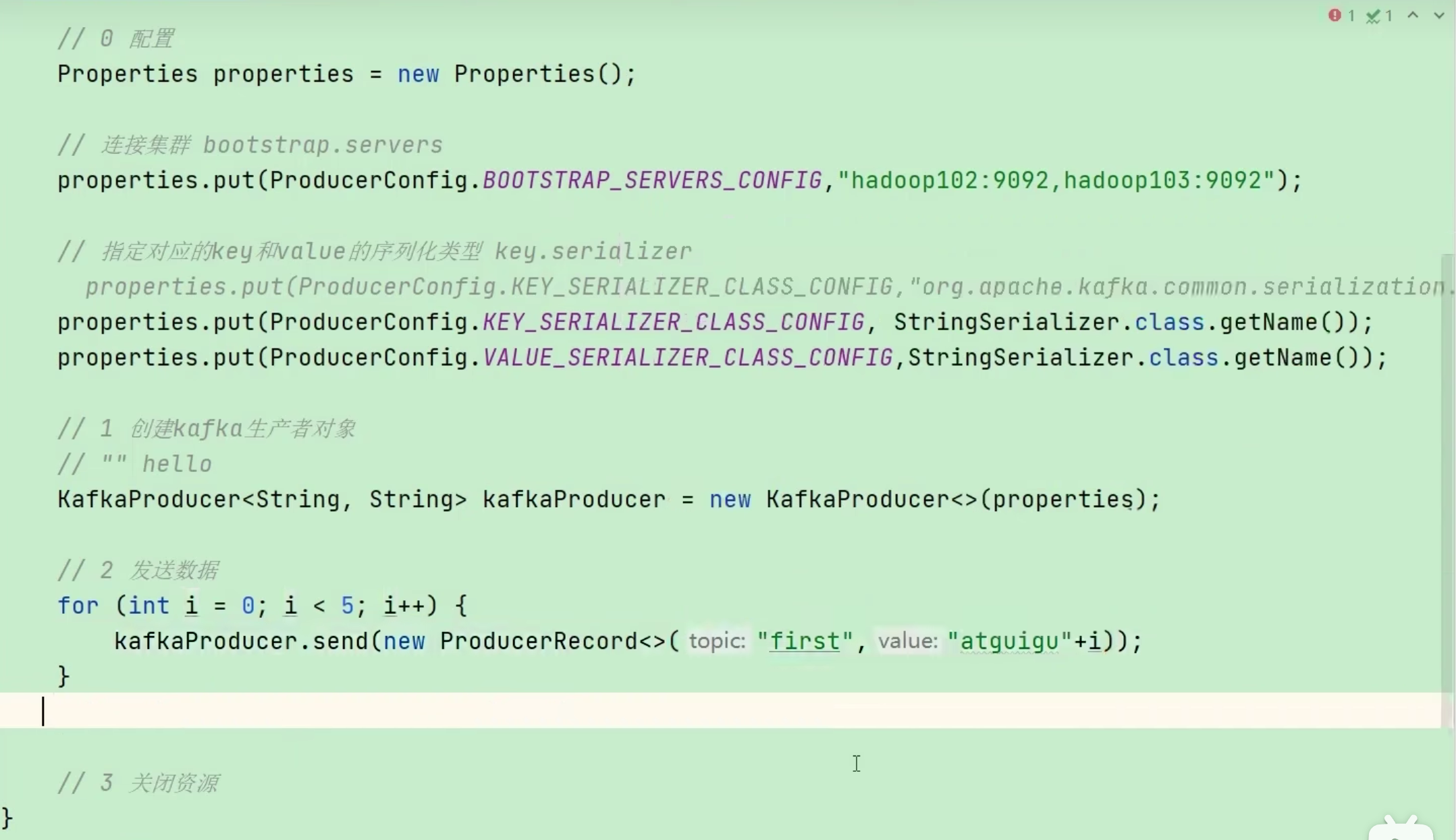
-
消息发送回调方法

-
消息同步发送
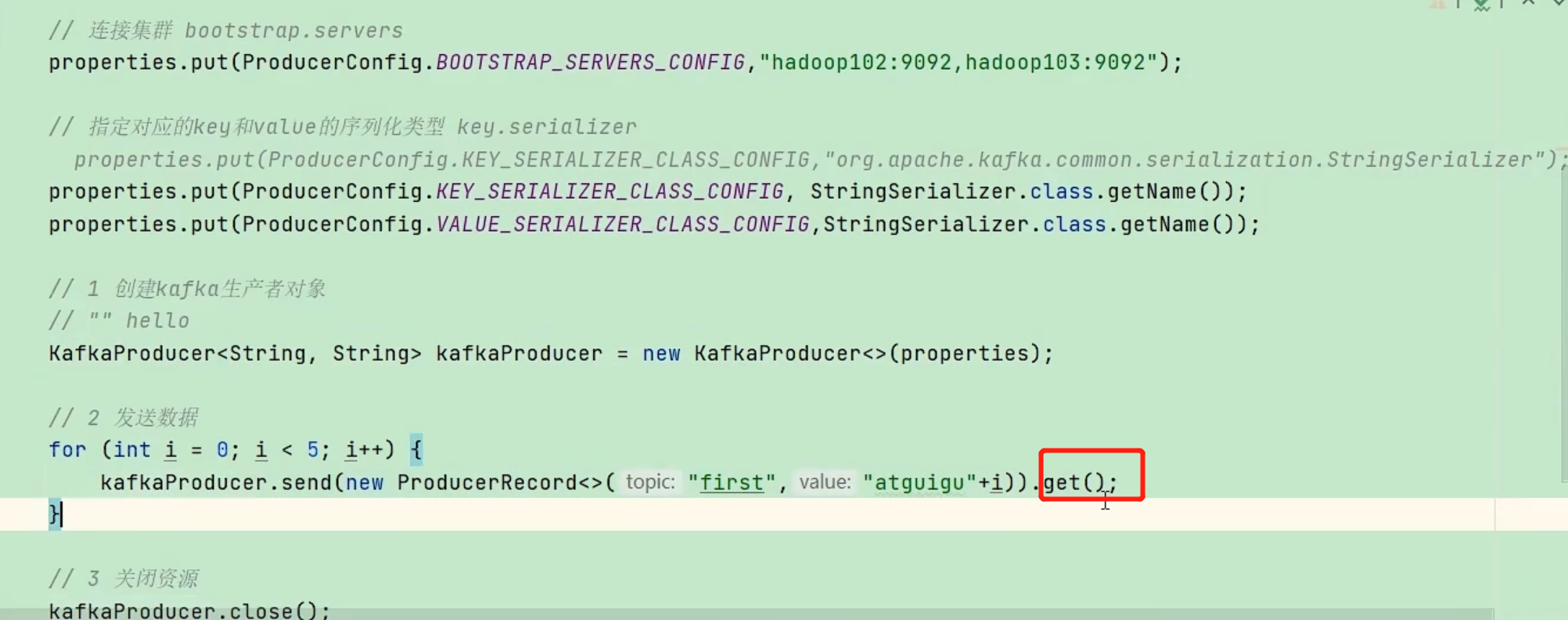
分区策略
- 默认分区策略
分区:在发送消息时指定消息到达的分区,有利于数据传输速度
- 未指定分区时,分区为key的hash值按分区数取模后的值
- 未指定key时,随机一个分区直到分区满载(粘性分区)

- 指定分区

- 自定义分区策略
- 实现Partitioner接口,返回分区数
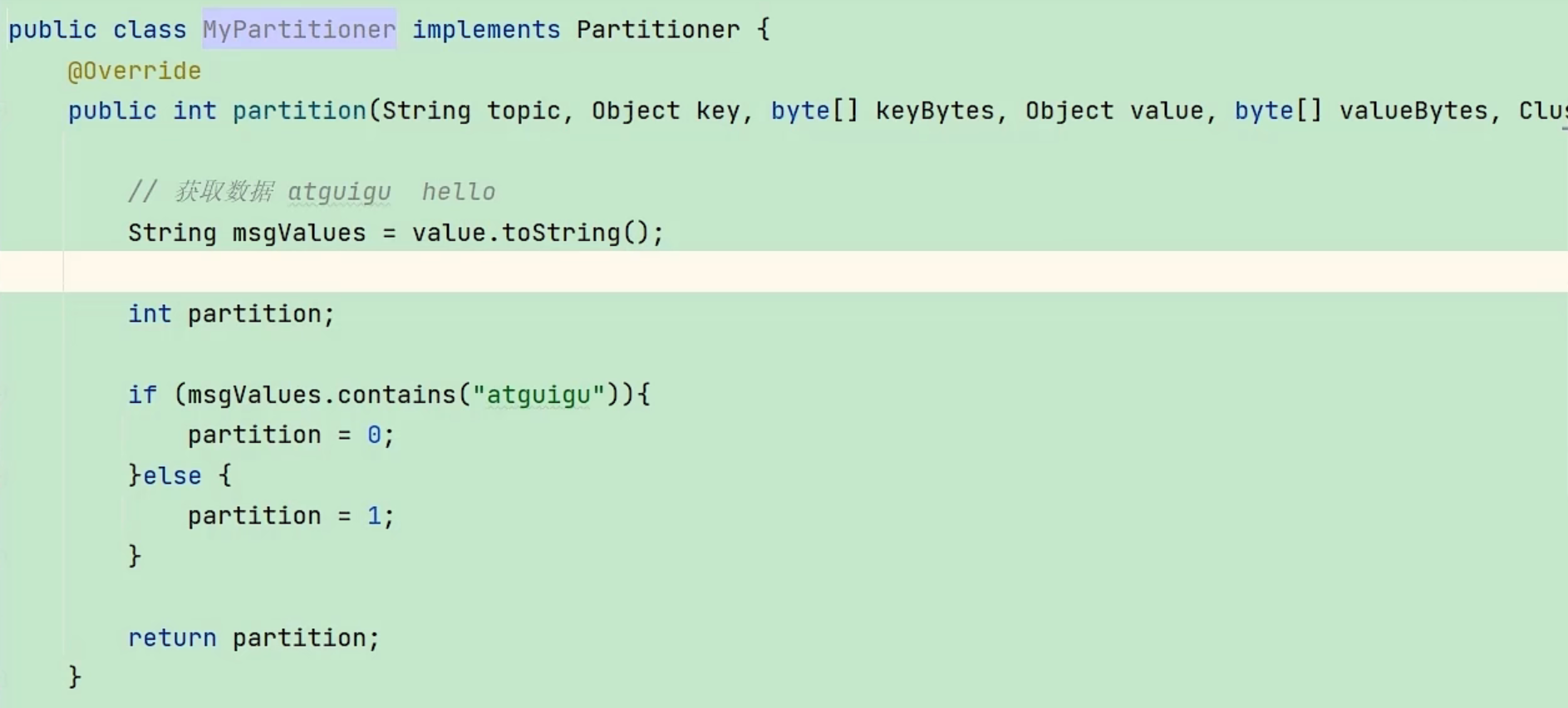
- 设置分区器

提高吞吐量
提高吞吐量的方式:
- batch.size: 批次大小,默认16k
- linger.ms : 等待时间,默认0即无需等待
- compresson.type: 压缩待发送的数据
- RecordAccumulator大小:缓存去大小默认32M
数据可靠

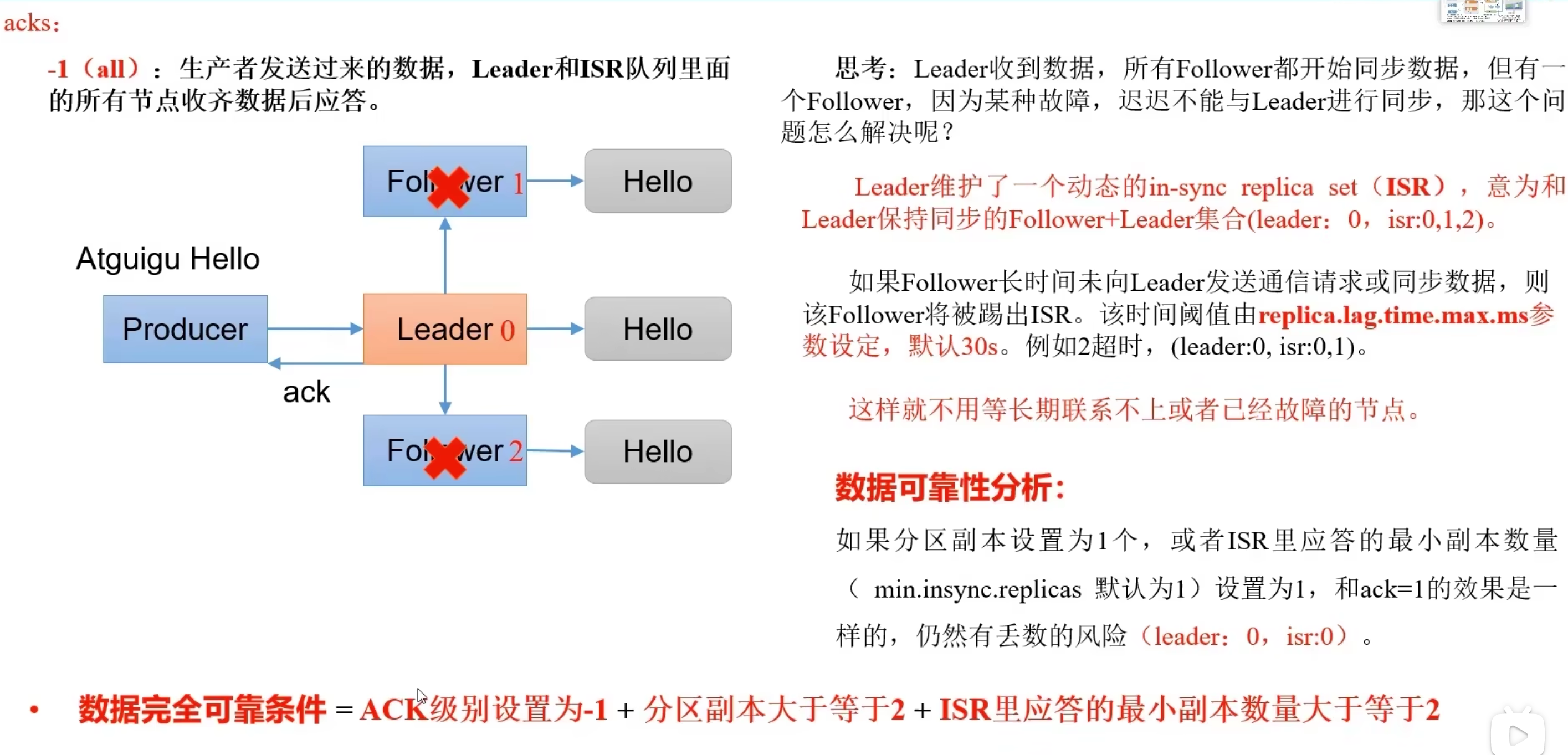
IRS机制
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护
如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
当ISR中所有Replica都向Leader发送ACK时,leader才commit
消息重复
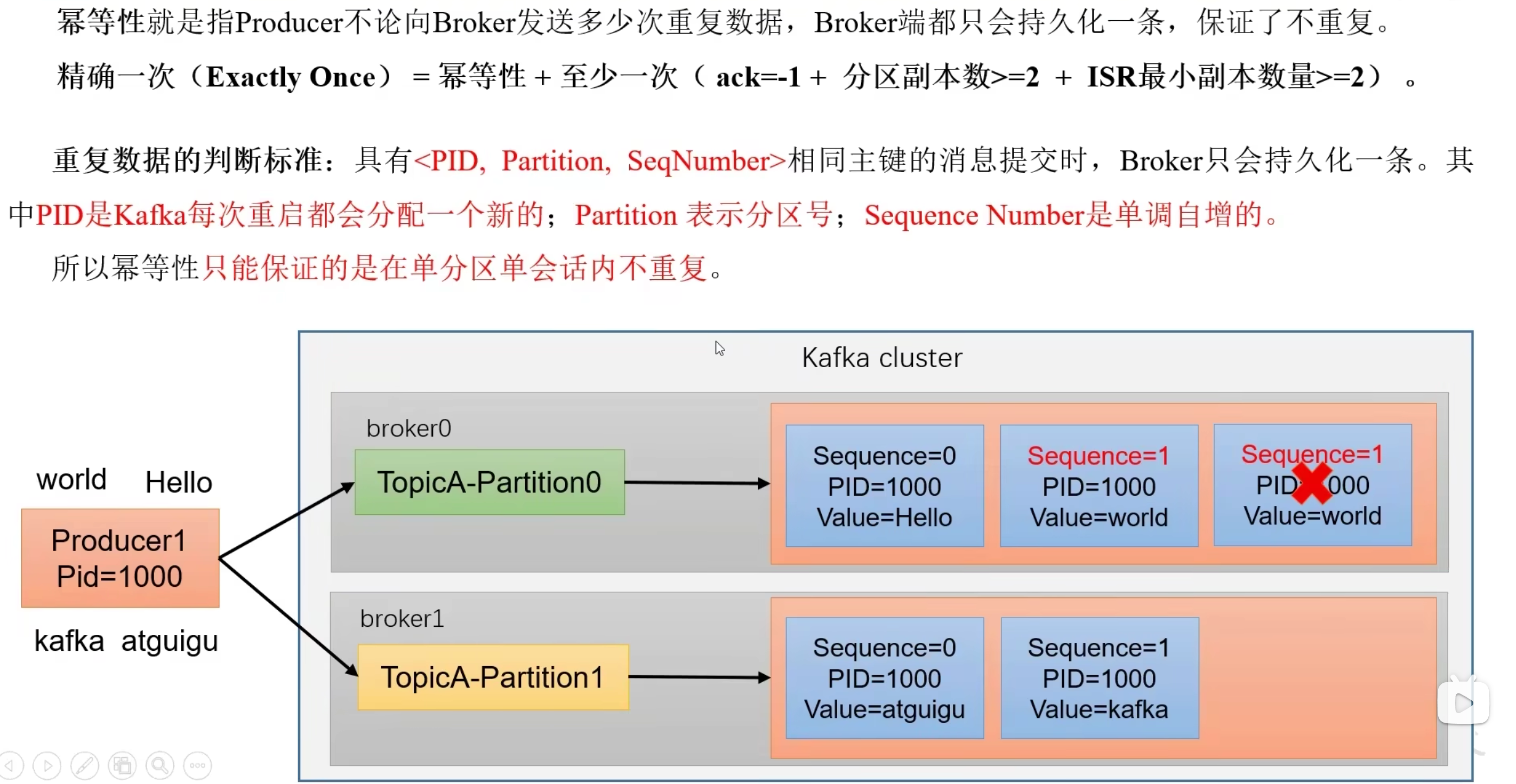
- 消息幂等性(默认开启)
幂等性:幂等性指的是多次操作,结果是一致的,kafka幂等保证数据唯一
- 用
PID + 分区号 + 序列号来判断数据是否重复 - 只能保证单分区单会话数据不重复
- 生产者事务
- 使用生产者事务必须开启
transactional.id唯一事务id - 当前消息要么全部生产成功,要么全部失败,并且故障恢复后,能够保证事务ID不变
过程:生产者创建时,设置全局唯一的事务ID与PID绑定,当producer重启后,会根据事务ID查找PID
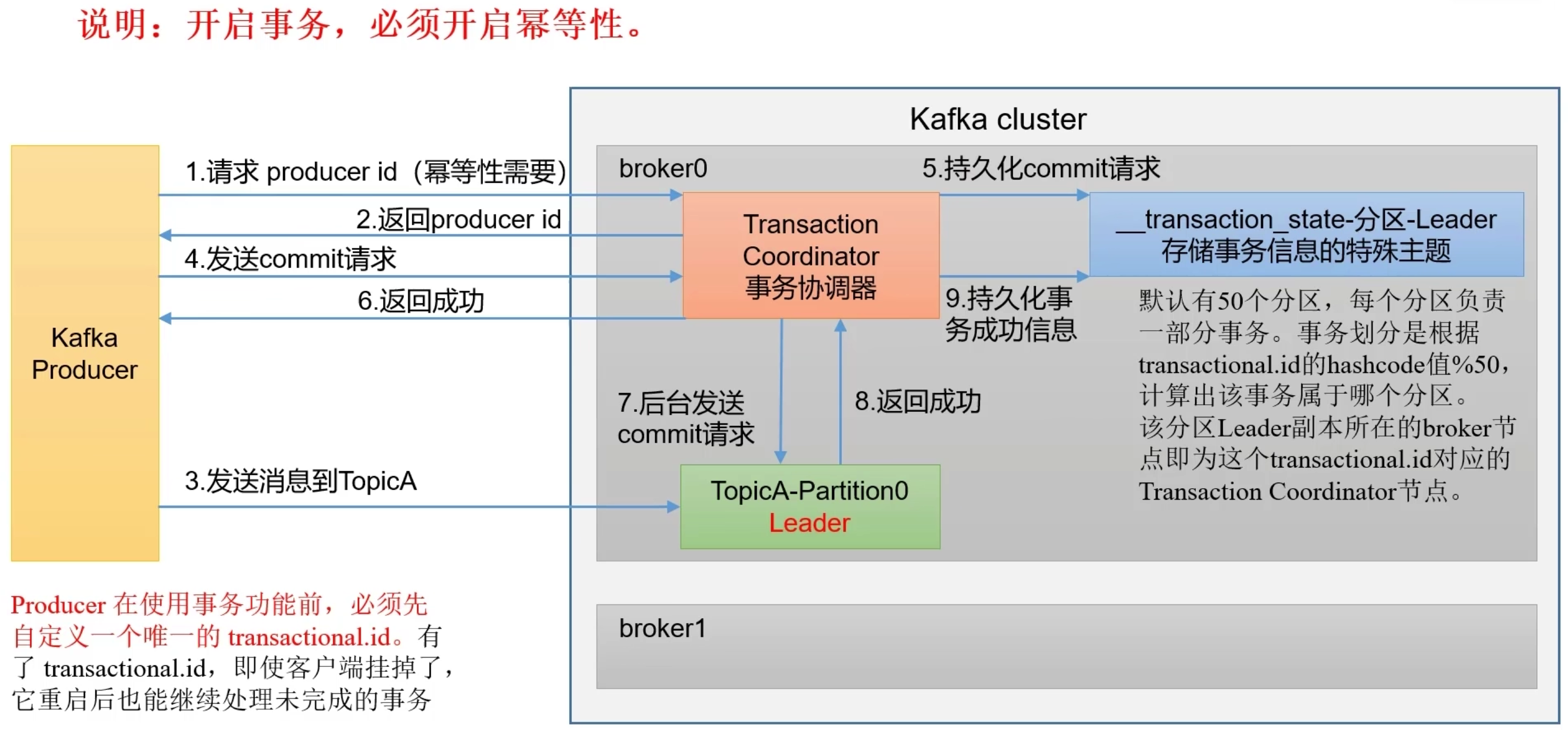
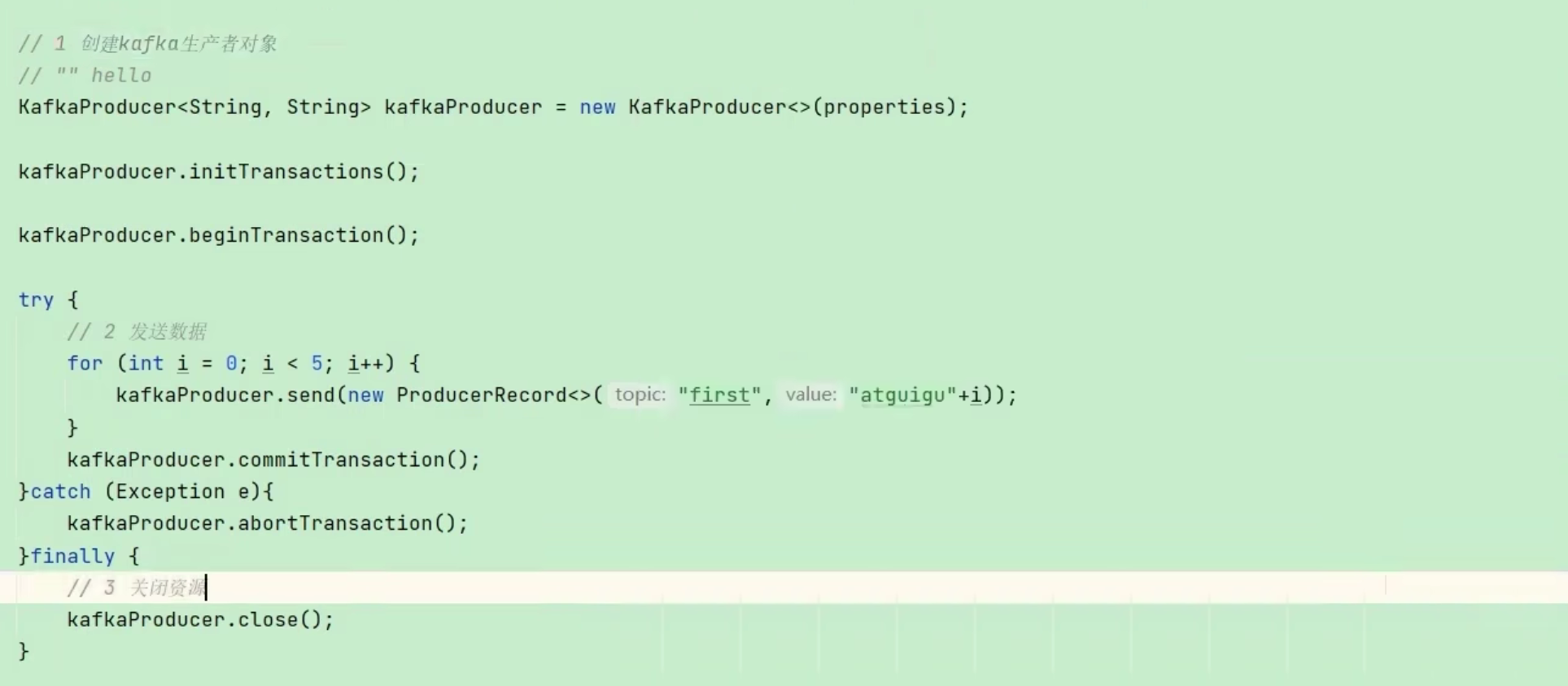
- 事务5个API

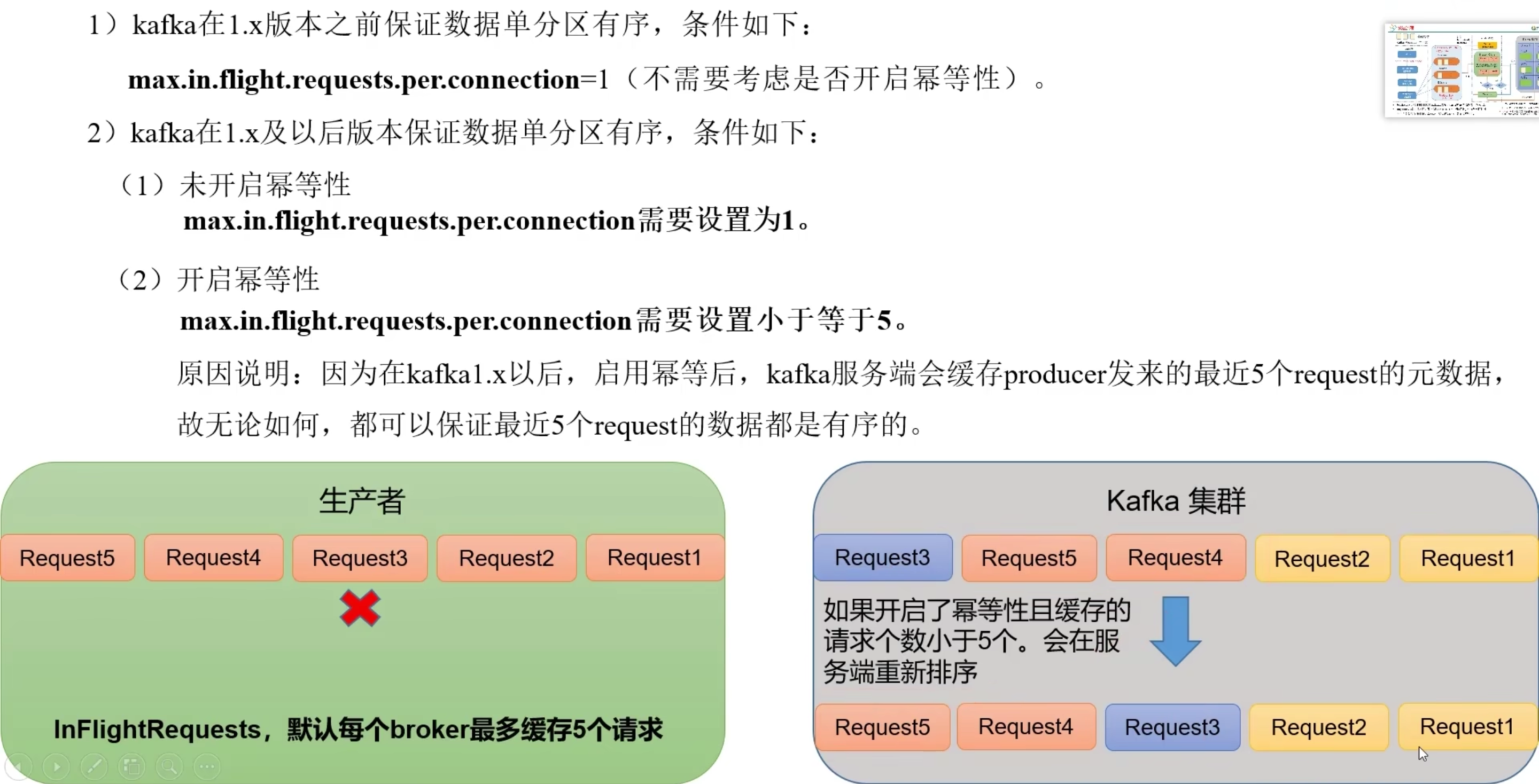
数据乱序
分区有序:数据在一个分区内有序
- 设置缓存请求大小
max.in.flight.requests.per.connection小于等于5 - 缓存大小大于1且开启幂等性,数据通过
序列号保证有序
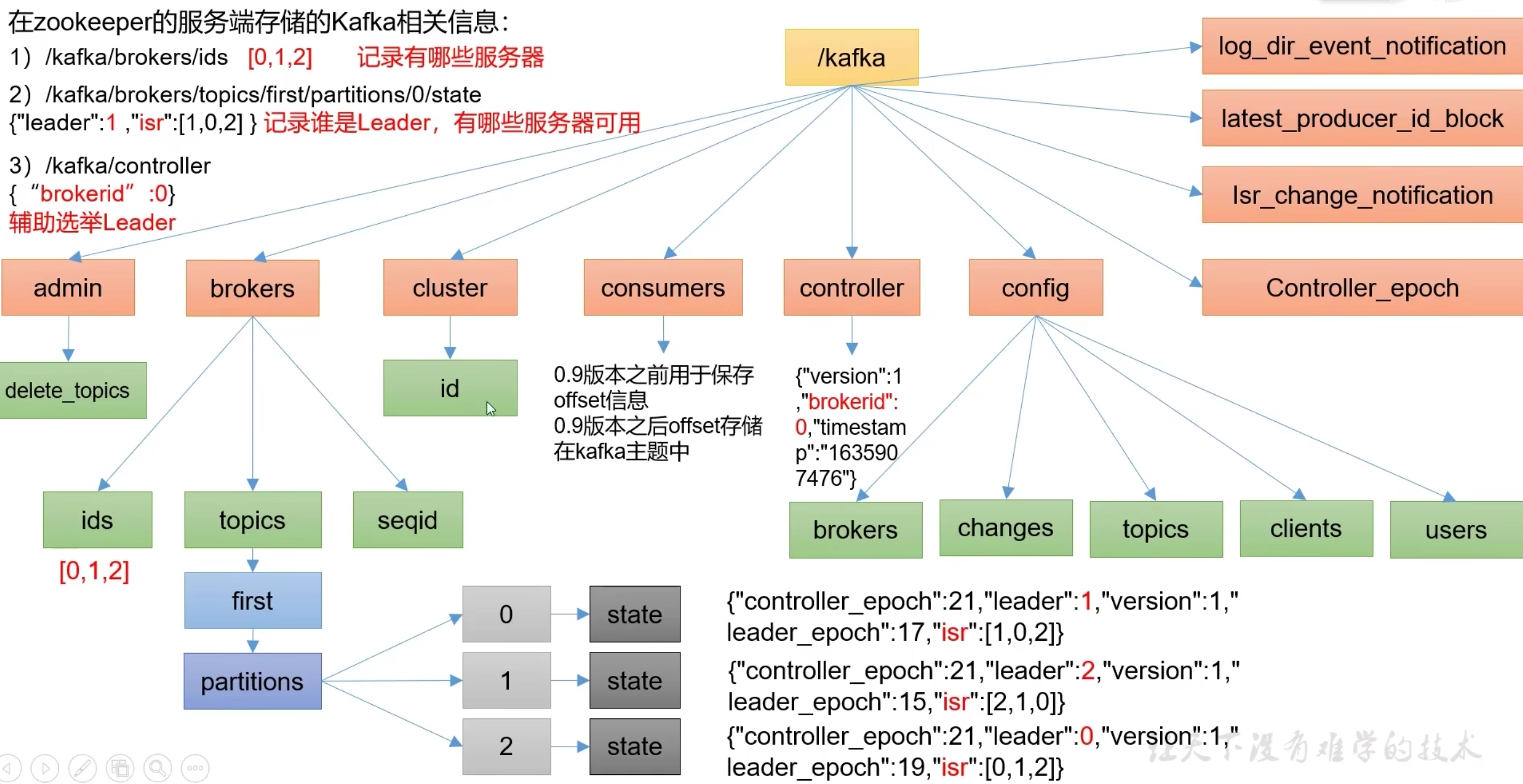
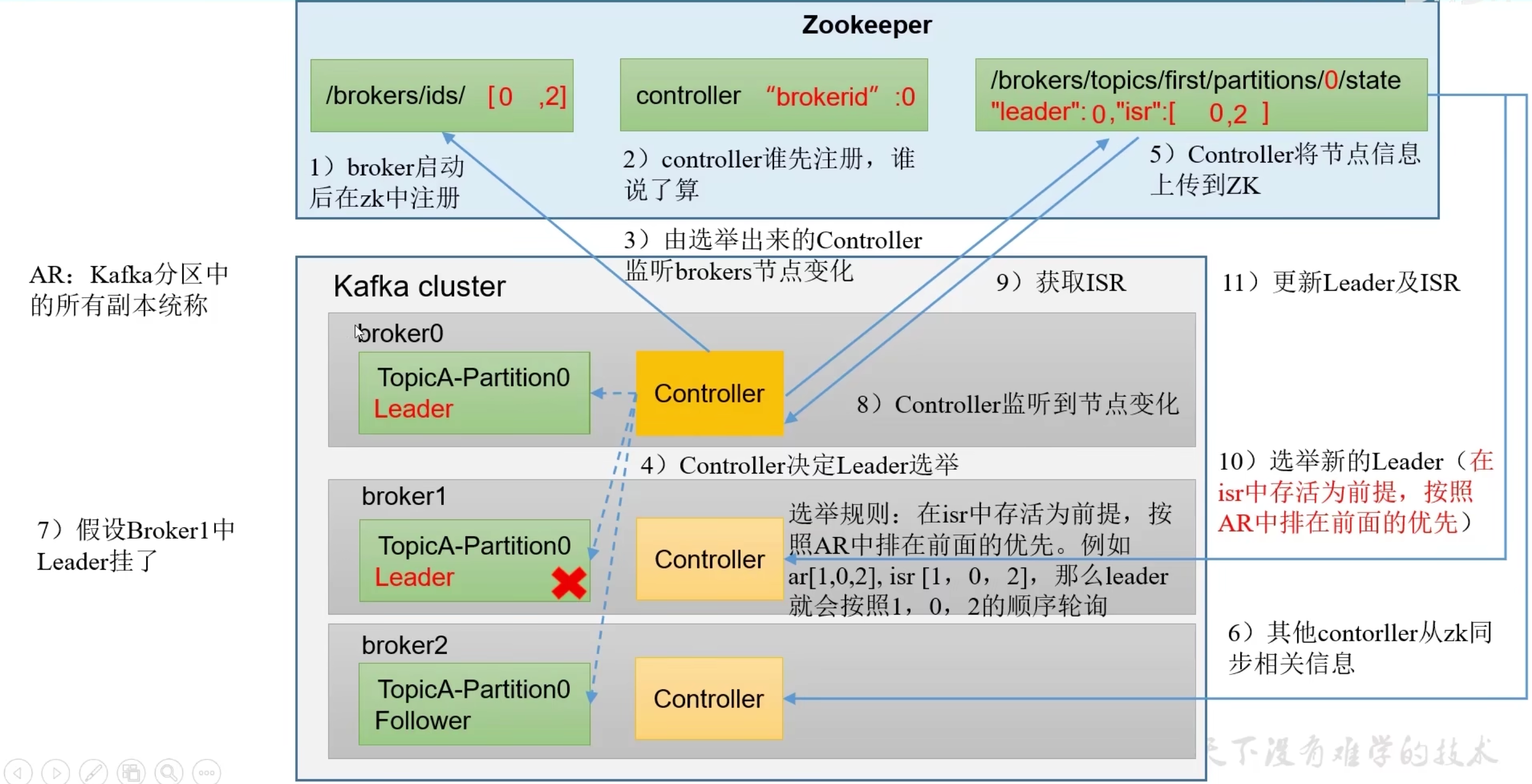
zookeeper 存储的kafka信息
- 记录哪些broker节点
- 记录谁是leader节点
- 配置信息
broker工作流程
副本
kafka默认副本一个
- kafka副本分为leader和follower,操作只会向leader发,follower同步leader信息
- 所有副本的统称为AR:ISR + OSR
分区中的所有副本统称为AR(Assigned Replicas)。
所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。
与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(Out-of-Sync Replicas)
leader选举流程
- 先选举controller(每个节点都有ctl用于选举和监听)再由controller选举leader节点
- 选举leader规则按照再ISR存活为前提按照AR节点顺序轮询
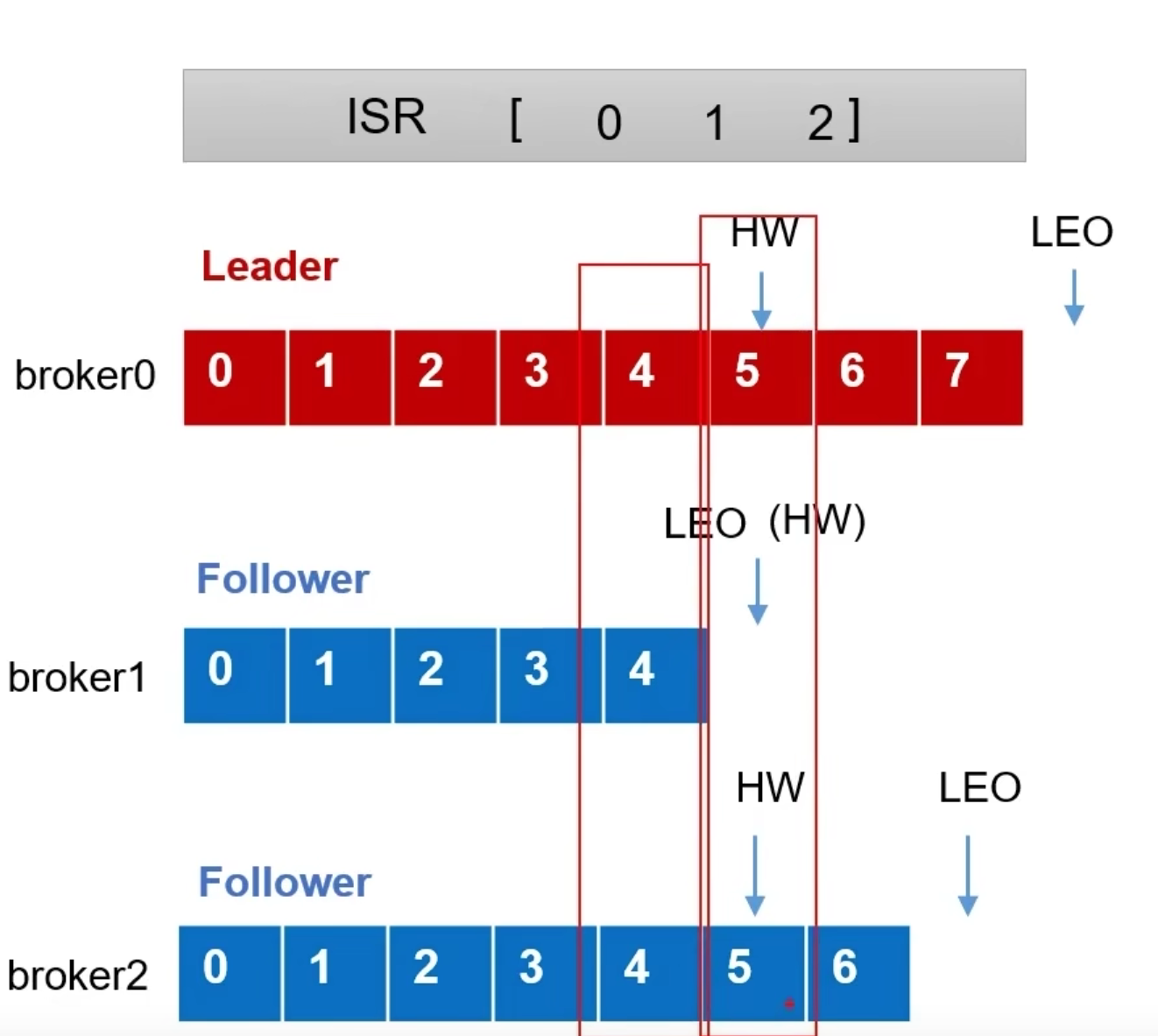
故障处理
LEO每个副本最后的offset,即为最新offset+1
HW所有副本最小的LEO
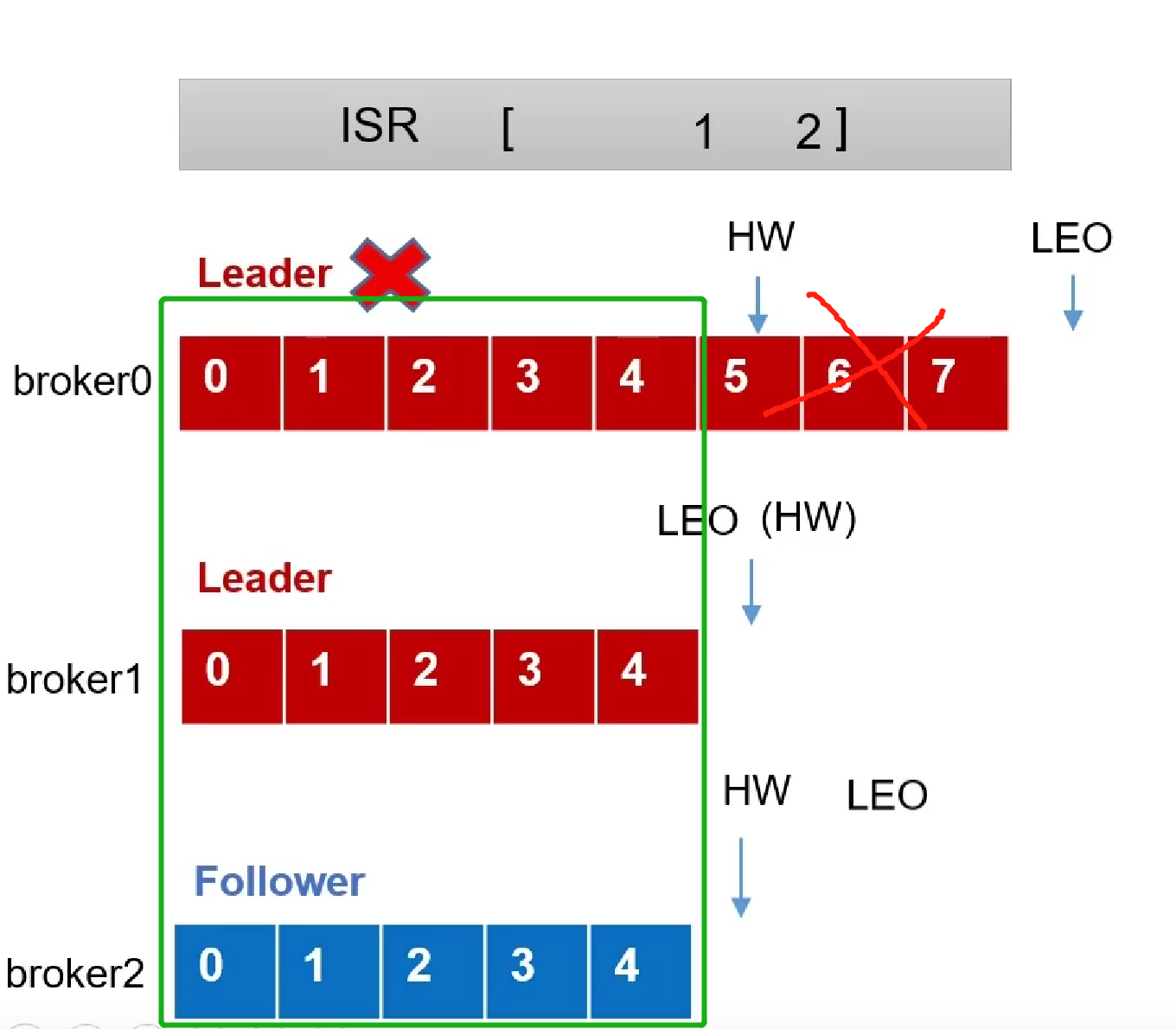
-
follower故障
1.踢出ISR队列
2.记录HW位置
3.恢复后去除HW后的信息,从HW开始位置同步leader的数据 -
leader故障
1.leader故障后回重新从ISR队列选举新的Leader节点
2.其他follower同步新的leader数据,截取高于HW后的数据(可能数据丢失)
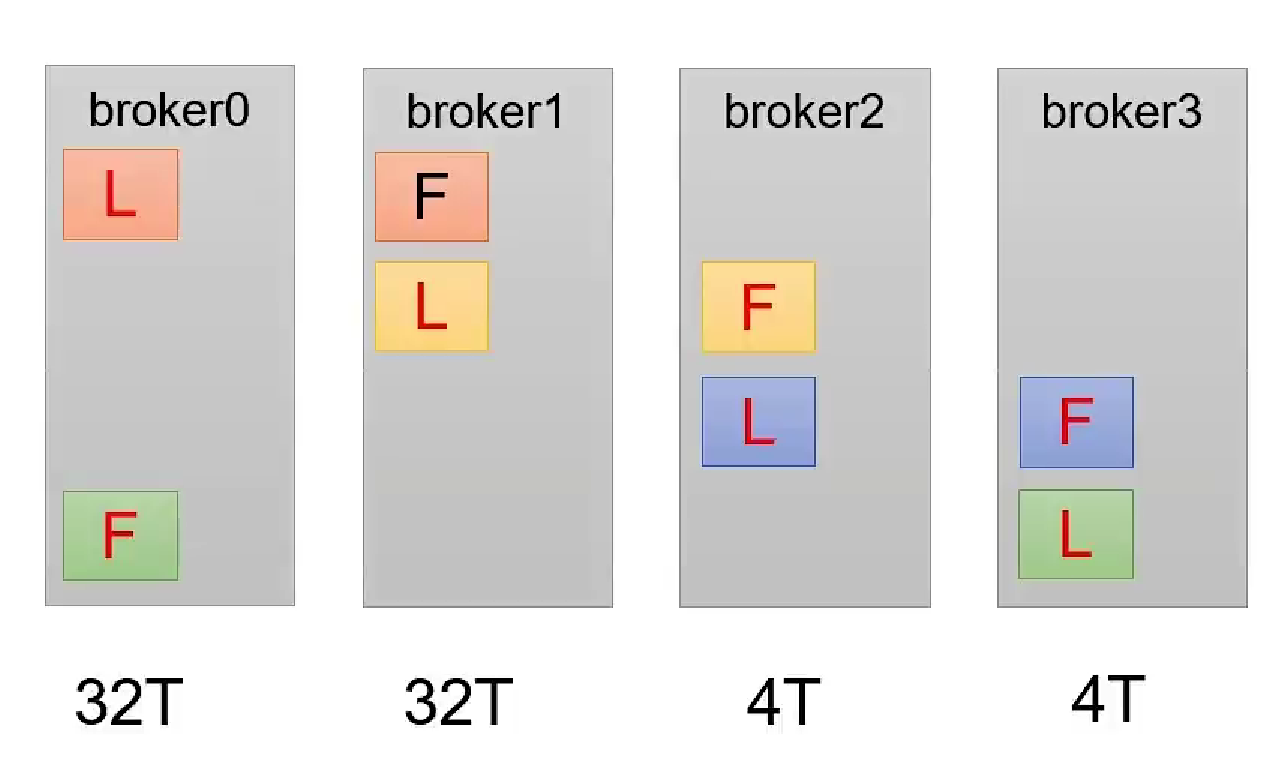
副本分配
-
默认均匀分配,保证每个节点压力均衡
-
手动调整副本分配

文件存储机制
- index文件采用
稀疏索引,每往log文件写入4kb数据时插入一条索引,且索引记录的是offset的相对位置
文件清除策略
Kafka 中 默认的日志保存时间为 7 天 ,可以通过调整如下参数修改保存时间。配置文件在kafka的config/server.properties文件中:
log.retention.hours,最低优先级小时,默认 7 天。
log.retention.minutes ,分钟。
log.retention.ms ,最高优先级毫秒。
log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
清除策略:
1.delete:清除(默认)
2.compact:压缩
-
清除
log.cleanup.policy = delete所有数据启用删除策略
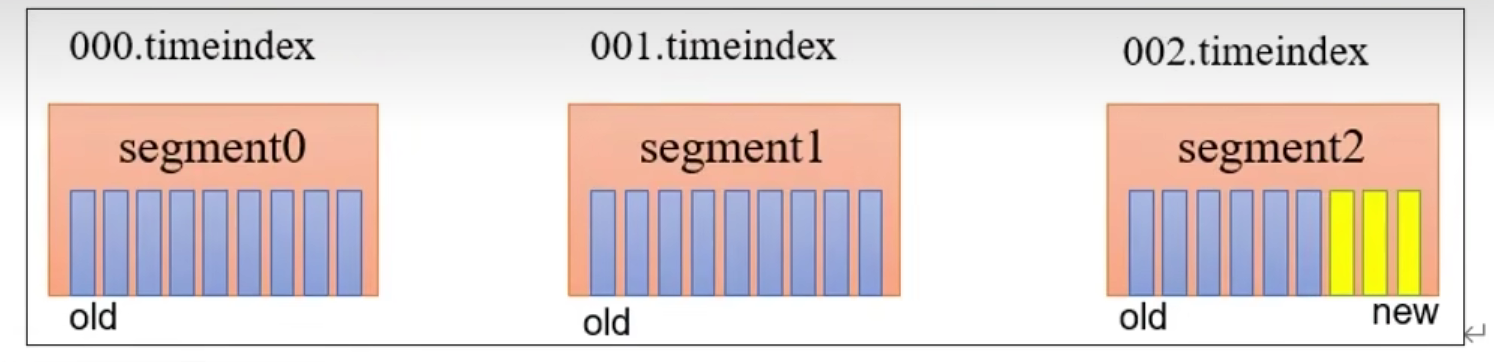
基于时间:默认打开 。 以 segment 中所有记录中的最大时间戳作为该文件时间戳。
基于大小:默认关闭 。超过设置的所有日志总大小,删除最早的 segment 。
log.retention.bytes ,默认等于 -1 ,表示无穷大
-
压缩
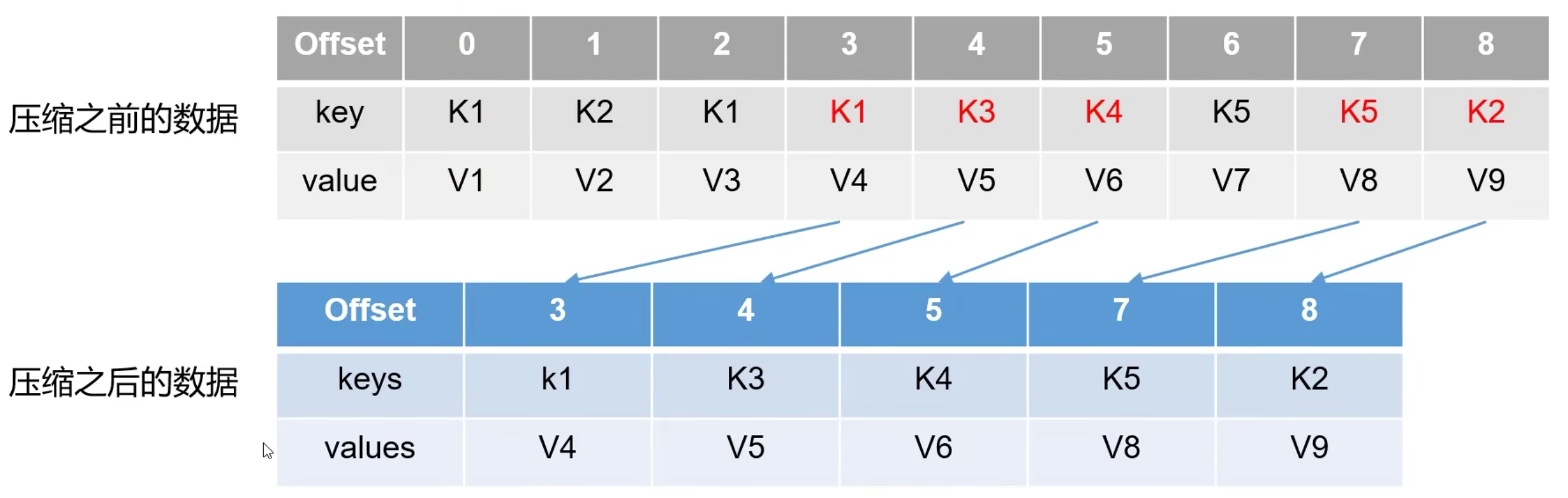
log.cleanup.policy = compact所有数据启用压缩策略
压缩后的 offset 可能是不连续的,当从这些 offset 消费消息时,将会拿到比这个 offset 大的 offset 对应的消息
消费者
- pull(拉):Kafka采用拉模型,主动拉取数据,缺点是容易返回空数据
- push(推):向所有消费者推送数据,kafka不采用这种模式因为不好匹配所有消费者速率
工作流程
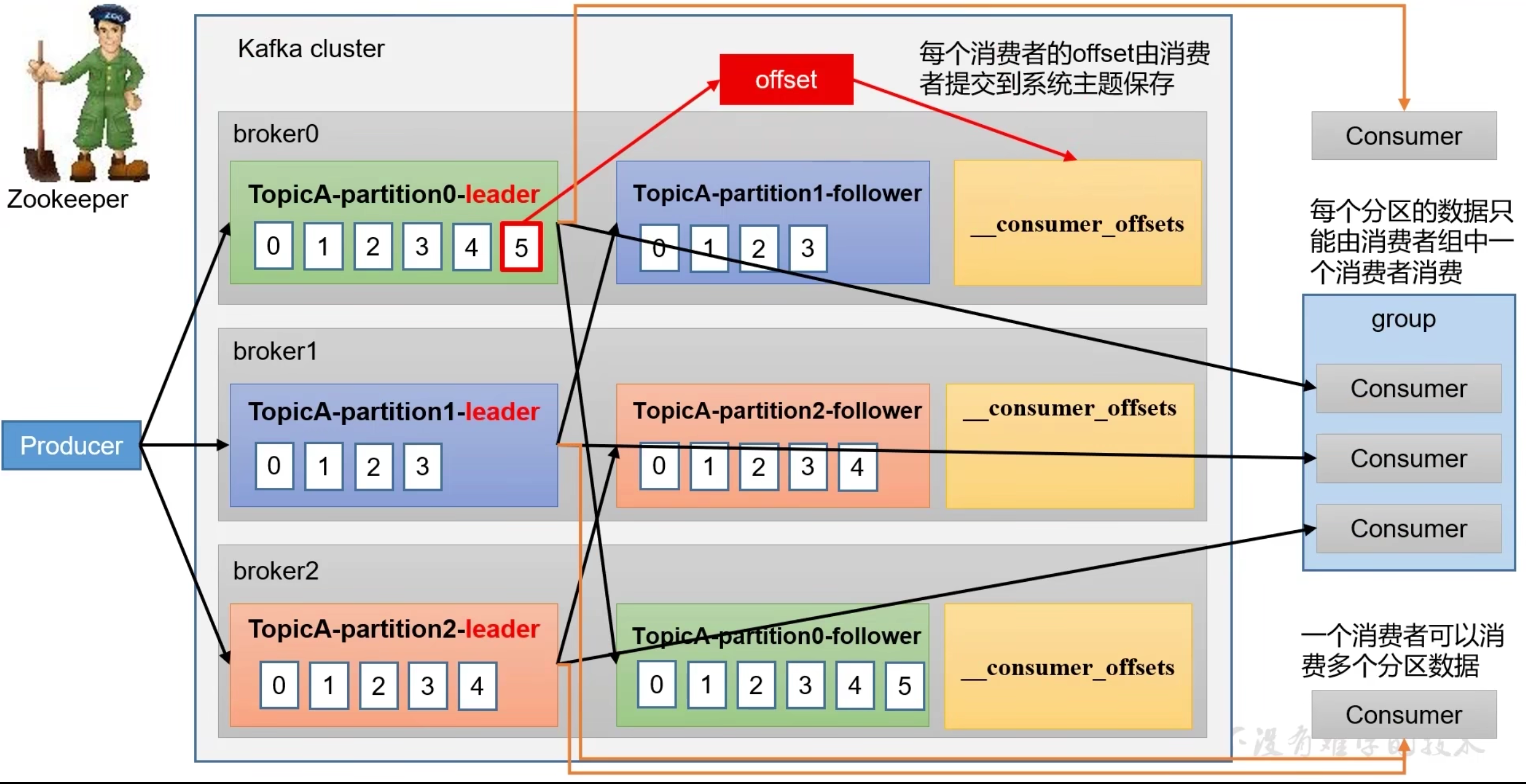
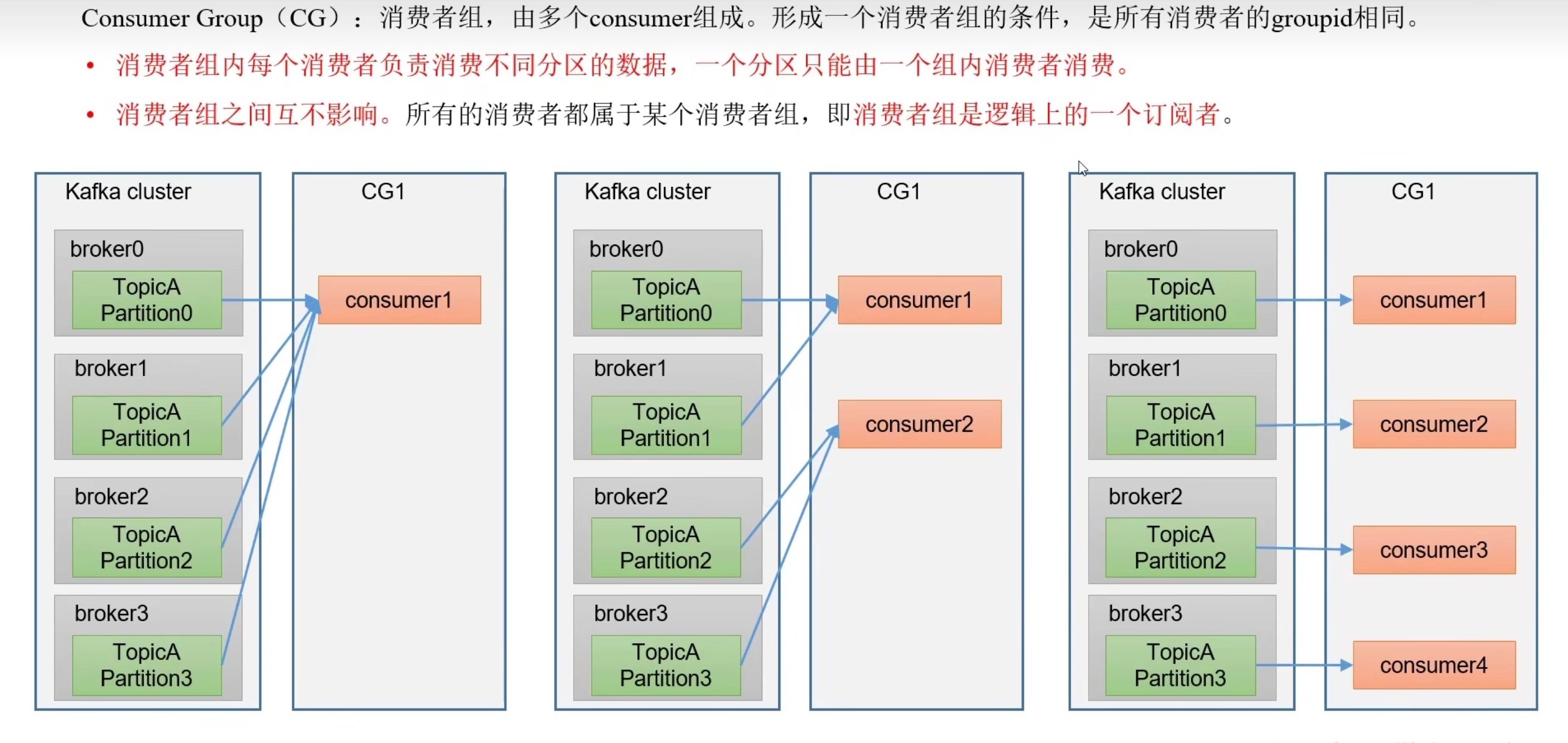
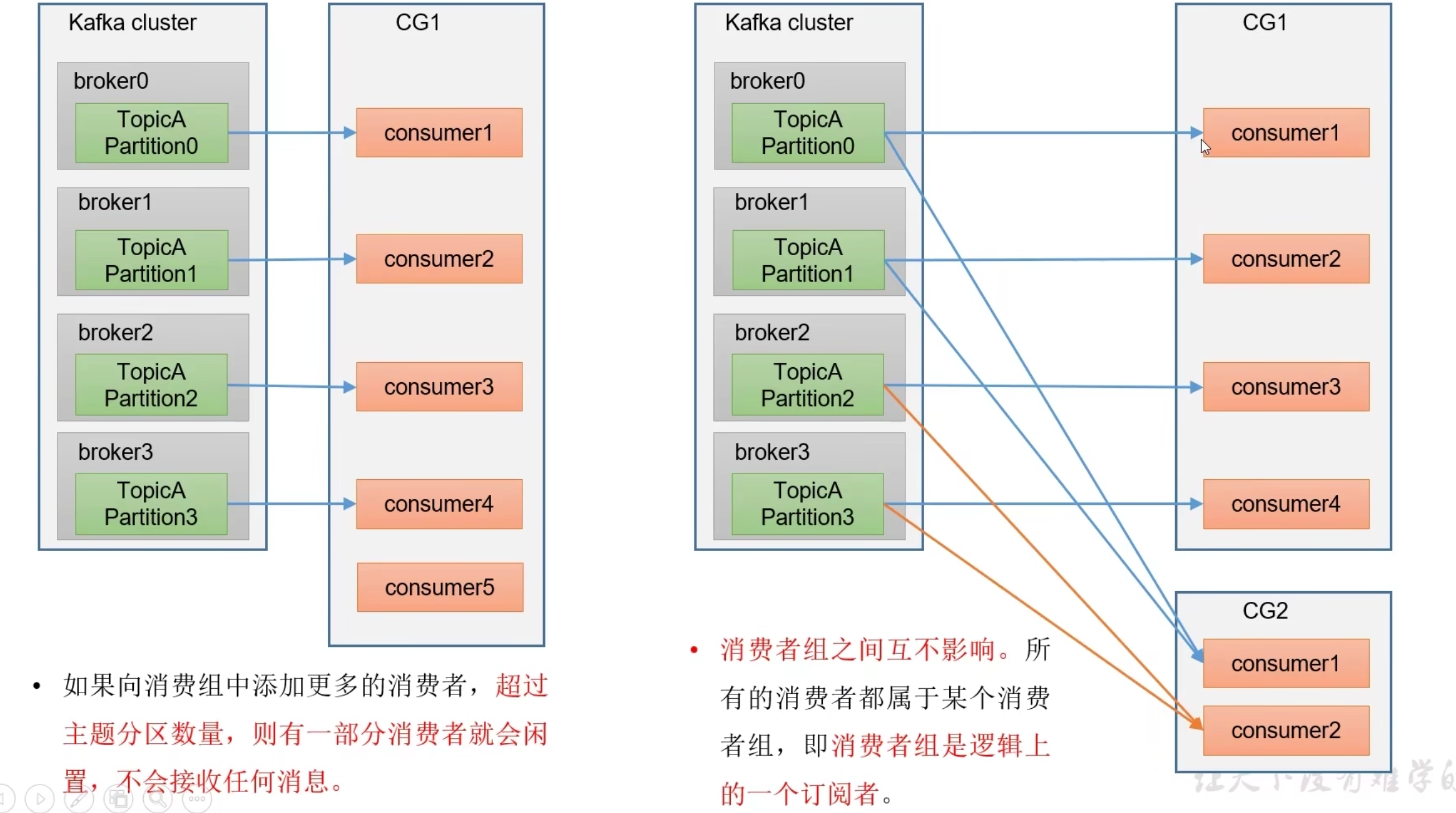
- 每个broker分区只能由一个消费者组(group)中的一个消费者消费
- 每个消费者offset由每个消费者提交到系统主题保存
消费者组
- 初始化消费者组
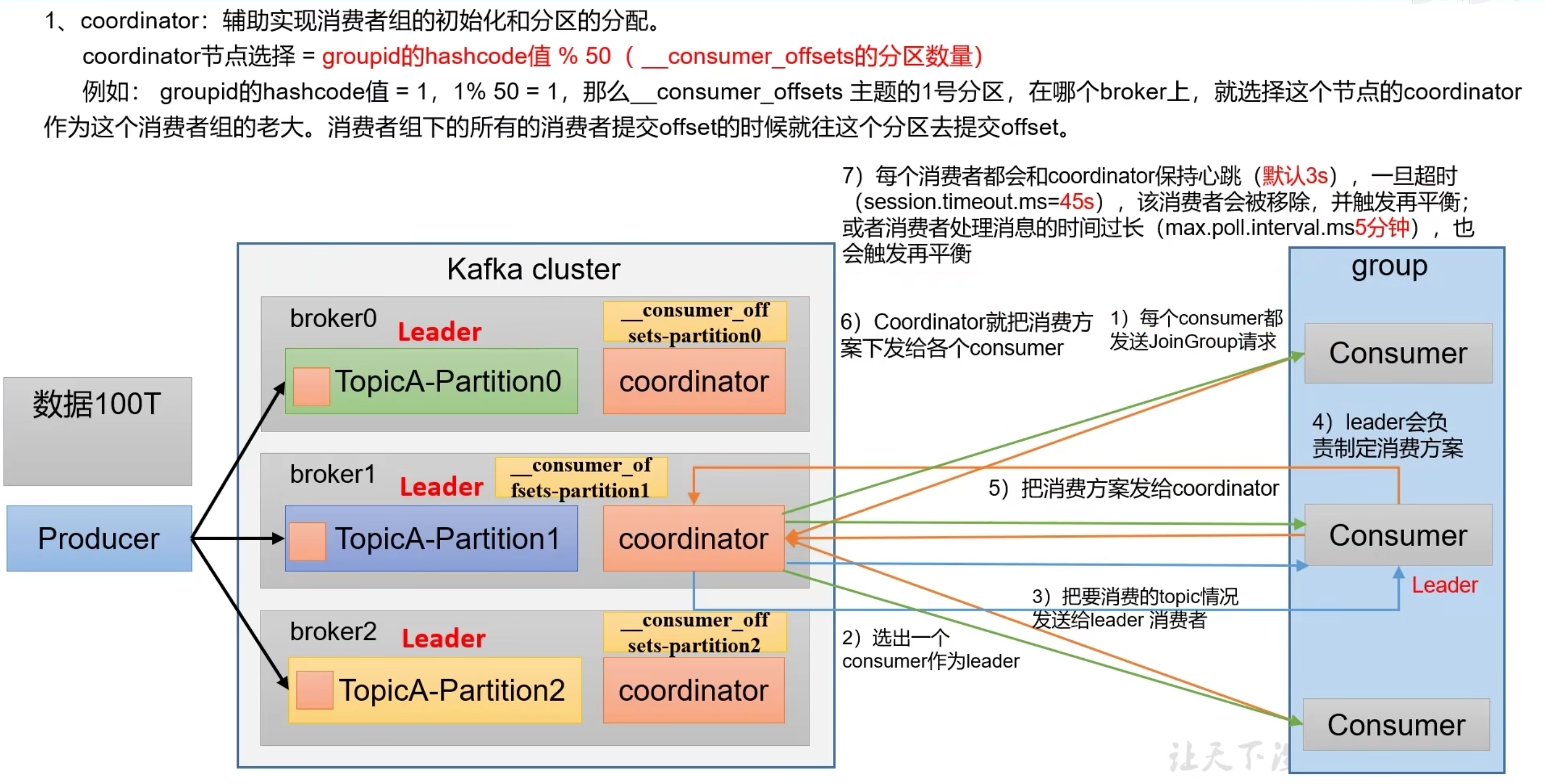
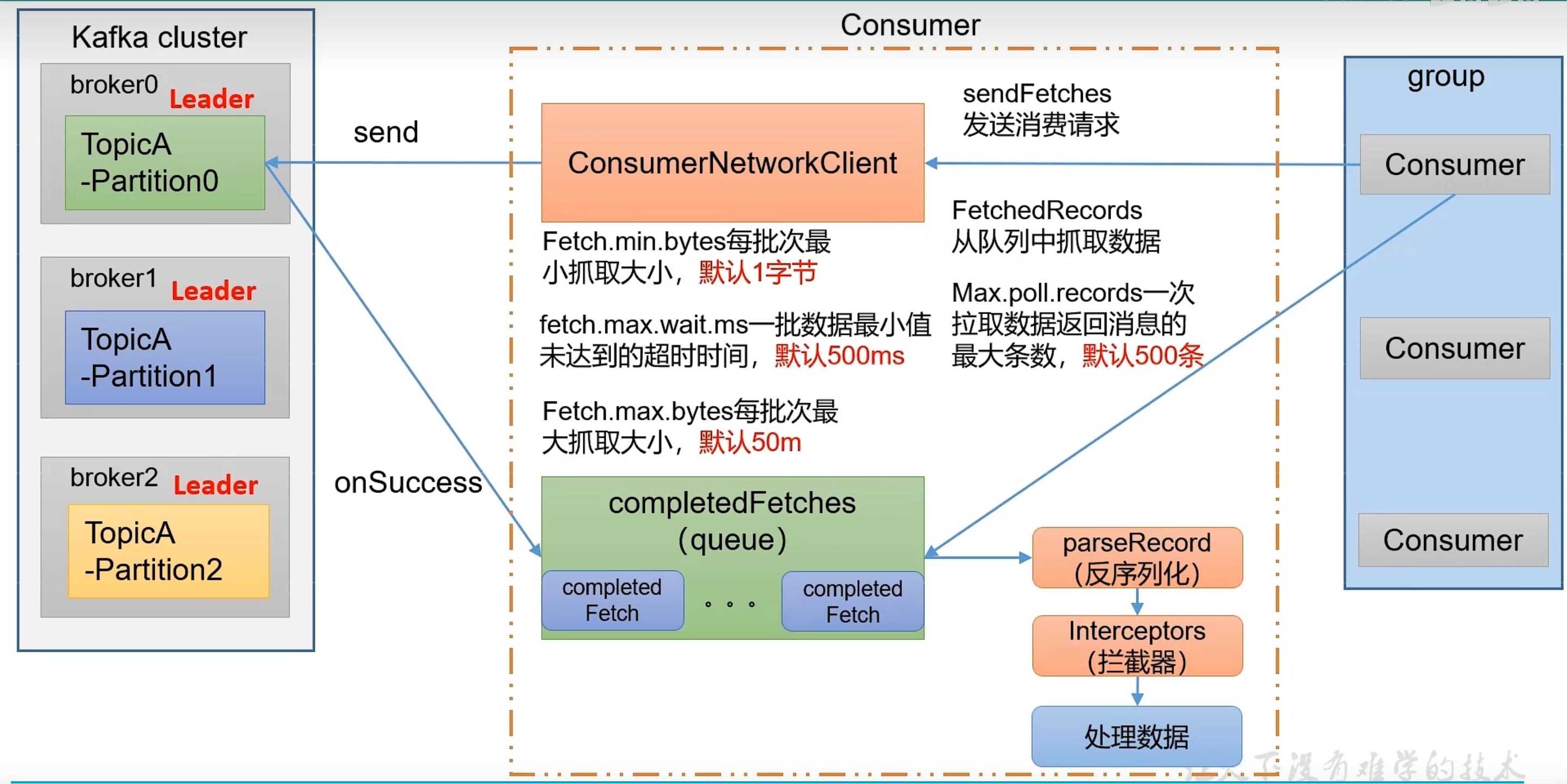
消费流程
分区分配策略
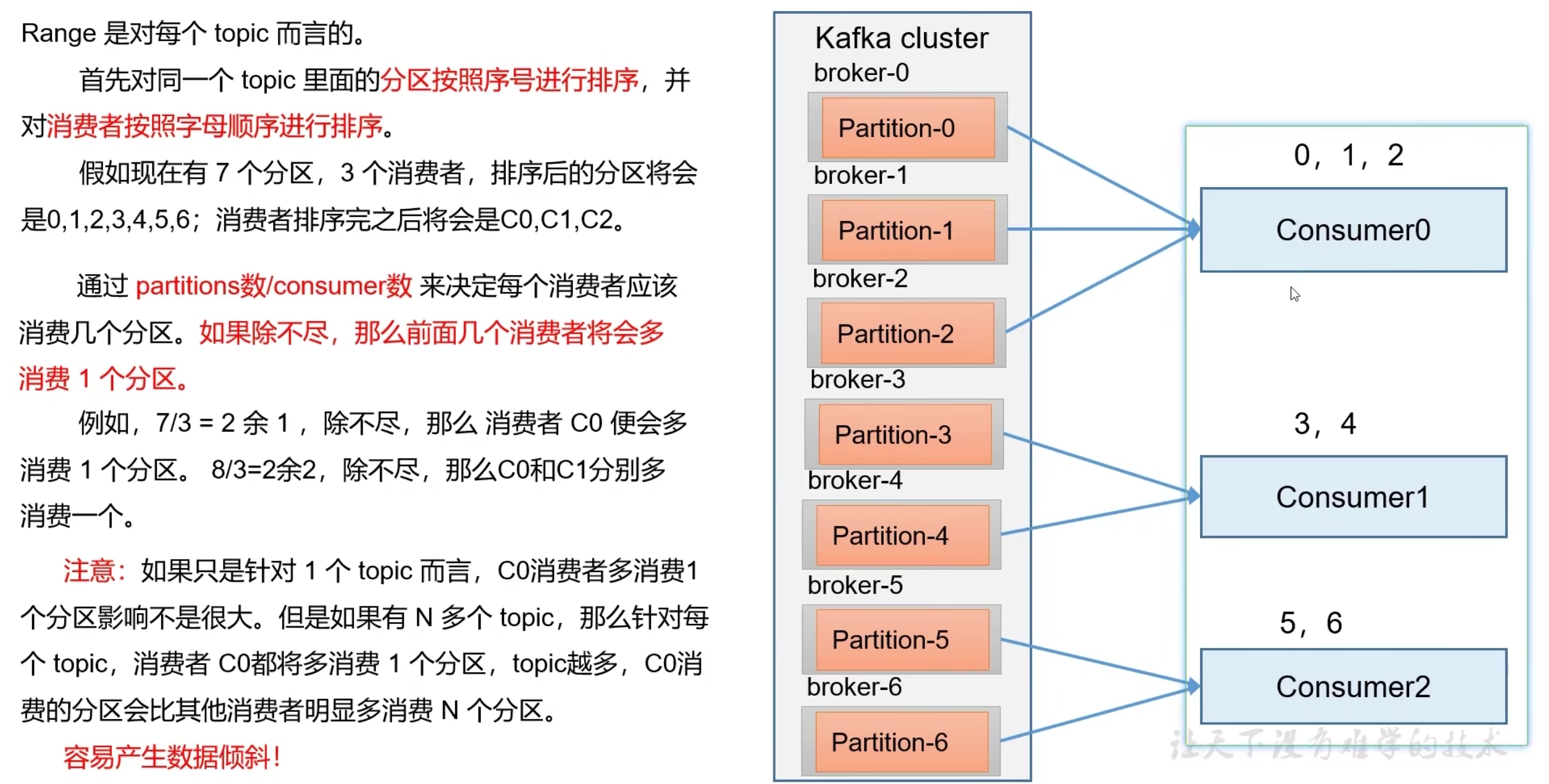
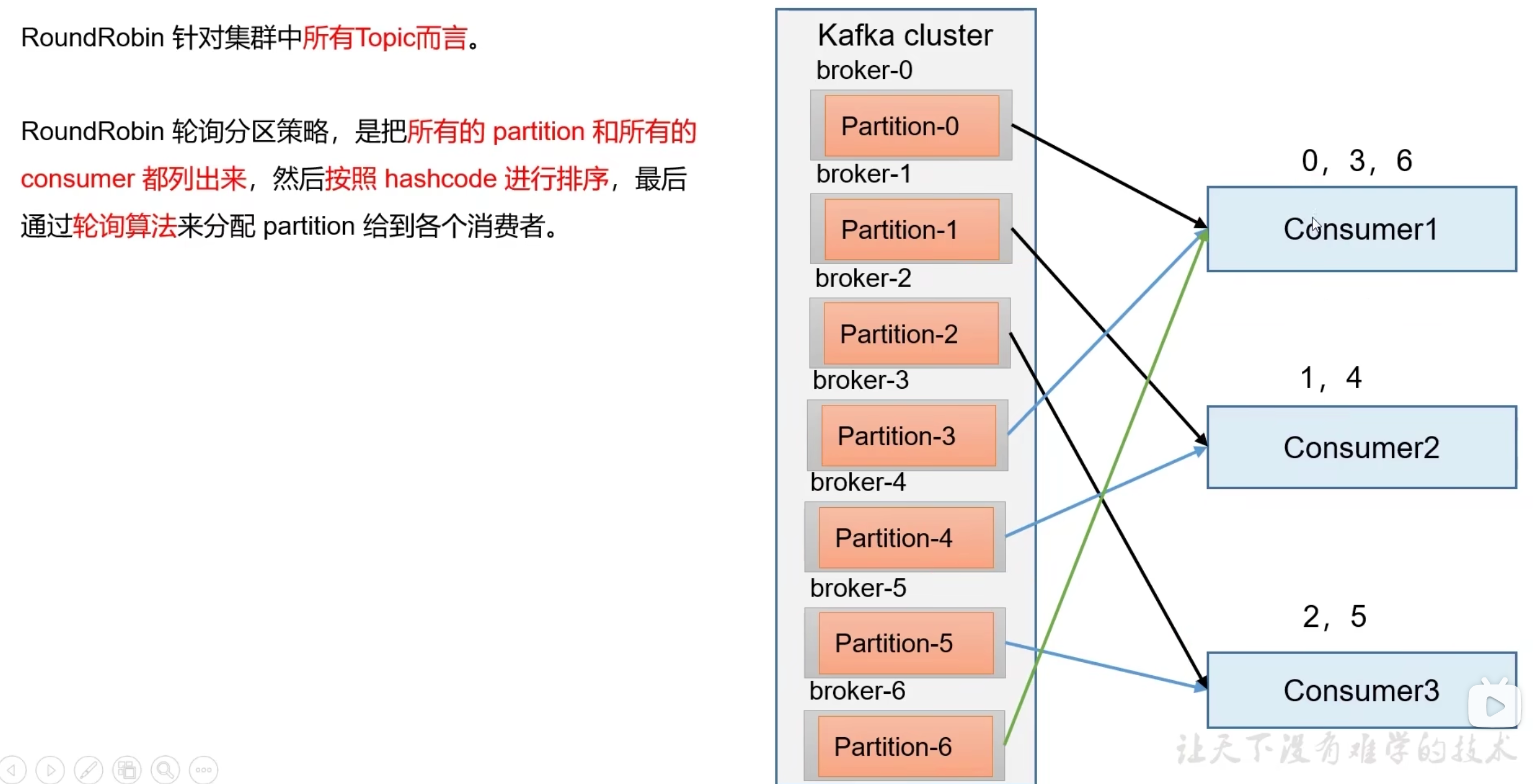
Kafka提供了3种消费者分区分配策略:RangeAssigor、RoundRobinAssignor、StickyAssignor
partition.assignsent.strategy配置分配策略,默认:Range + cooperativeSticky
- range
- RoundRobin
- Sticky
目的是在执行一次新的分配时,能在上一次分配的结果的基础上,尽量少的调整分区分配的变动,节省因分区分配变化带来的开销。Sticky是“粘性的”,可以理解为分配结果是带“粘性的”——每一次分配变更相对上一次分配做最少的变动。其目标有两点:
- 分区的分配尽量的均衡。
- 每一次重分配的结果尽量与上一次分配结果保持一致。
- CooperativeSticky
重分配的协议发生变化了,不再需要所有的consumer放弃当前持有分区
offset位移
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费
-
存储位置
Kafka 0.9版本之前,consumer 默认将 offset 保存在 zookeeper 中;从 0.9 版本开始,默认将 offset 保存在 kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。Key 是 group.id+topic+分区号,value 就是当前 offset 的值。 每隔一段时间,kafka 内部会对这个 topic 进行 compact,也就是每个 group.id+topic+分区号 就保留最新数据 -
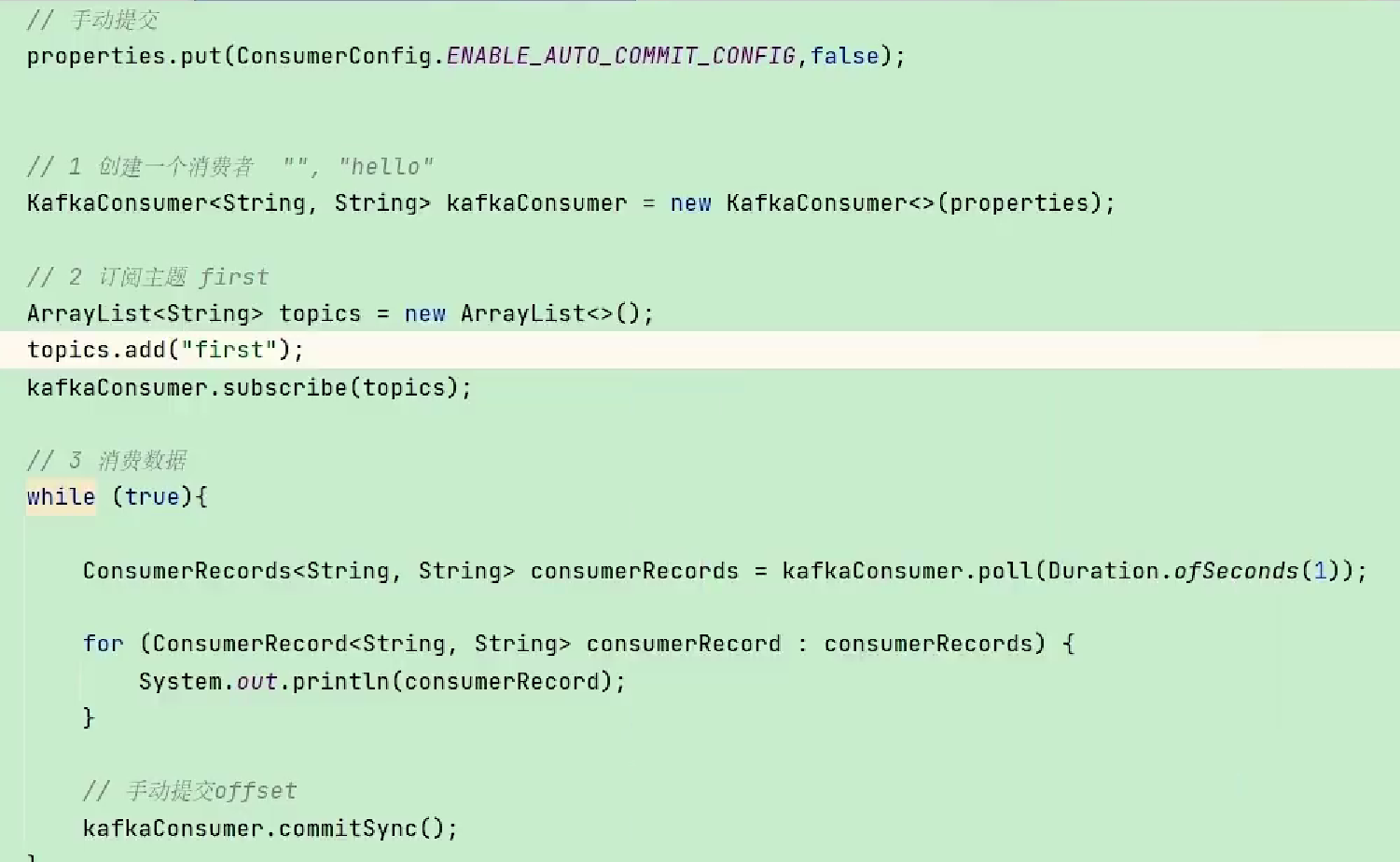
手动提交
enable.auto.commit是否开启自动提交,默认 true
auto.commit.inteval.ms自动提交的时间间隔,默认5s
- 同步提交:必须等待offset提交完毕再去消费下一批数据
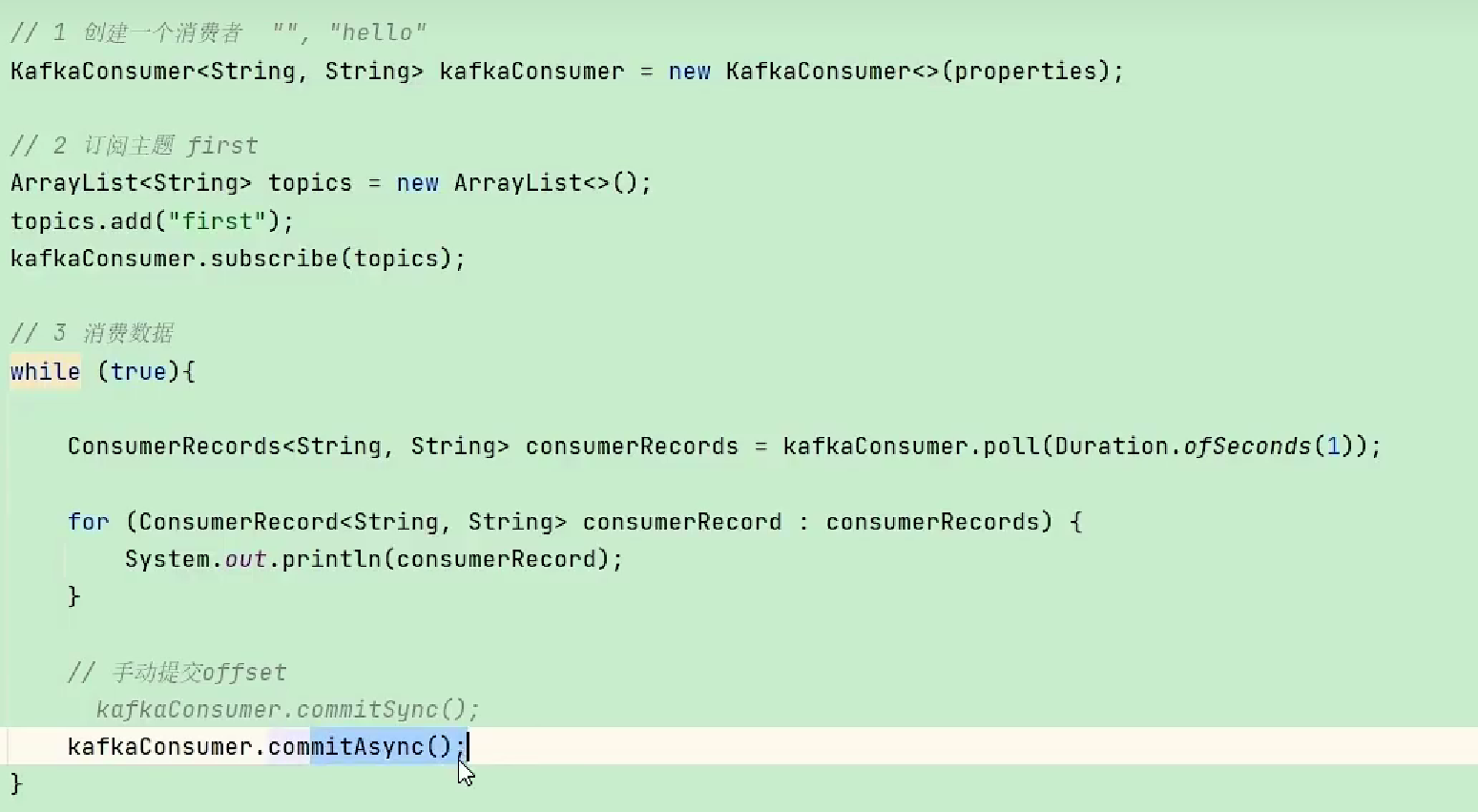
- 异步提交:发送完offset提交后,就可以去消费下一批数据
-
手动同步提交:commitSync
-
手动异步提交:commitAsync
-
指定offset消费
auto.offset.reset = earliest|latest|none(默认latest)
- earliest:自动将偏移量重置为最早的偏移量
- latest(默认值):自动将偏移量重置为最新偏移量
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
任意指定 offset 位移开始消费
- 重复消费&漏消费
自动提交导致的重复消费,和手动提交导致的漏消费,需用消费者事务方式解决
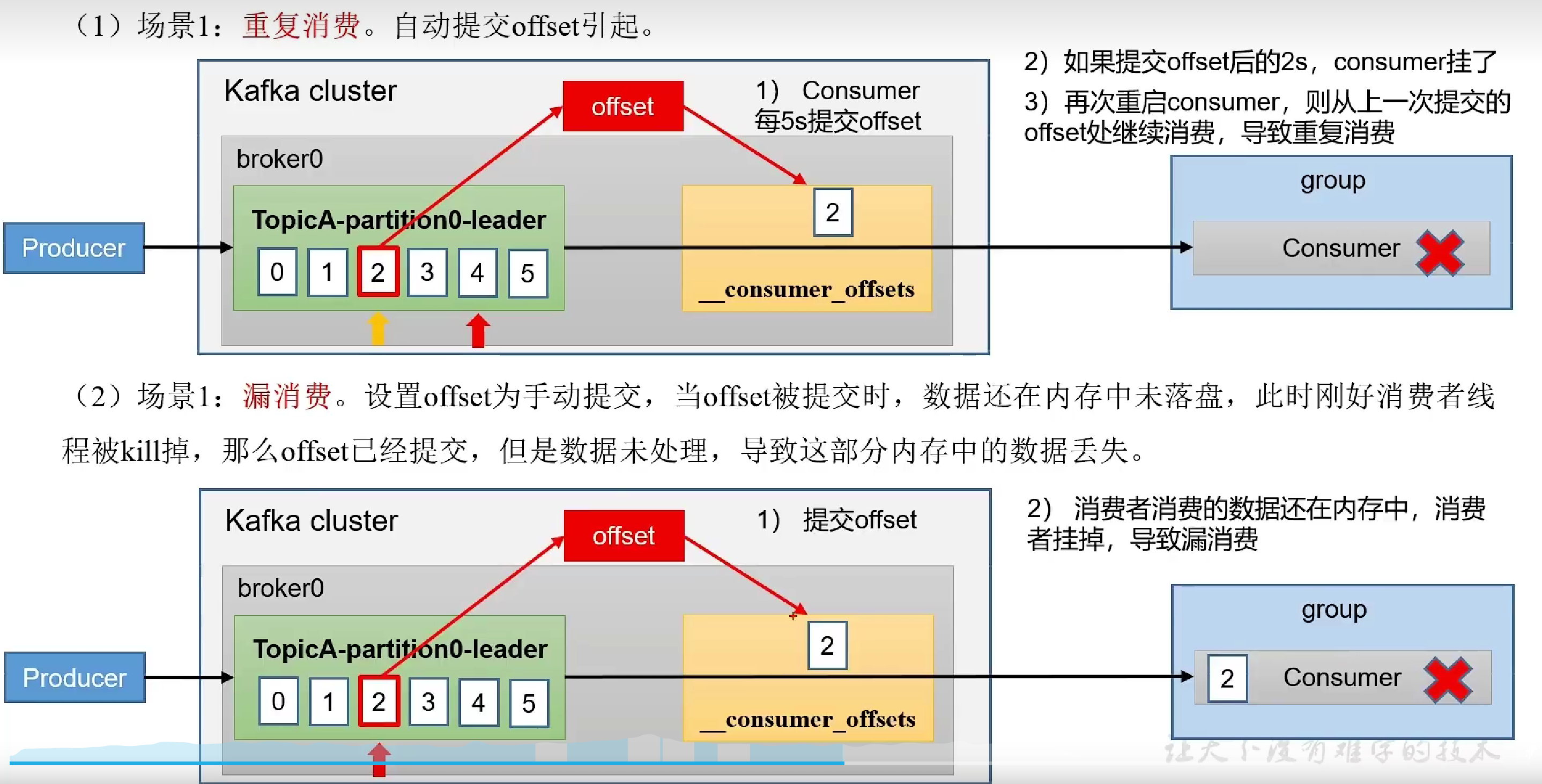
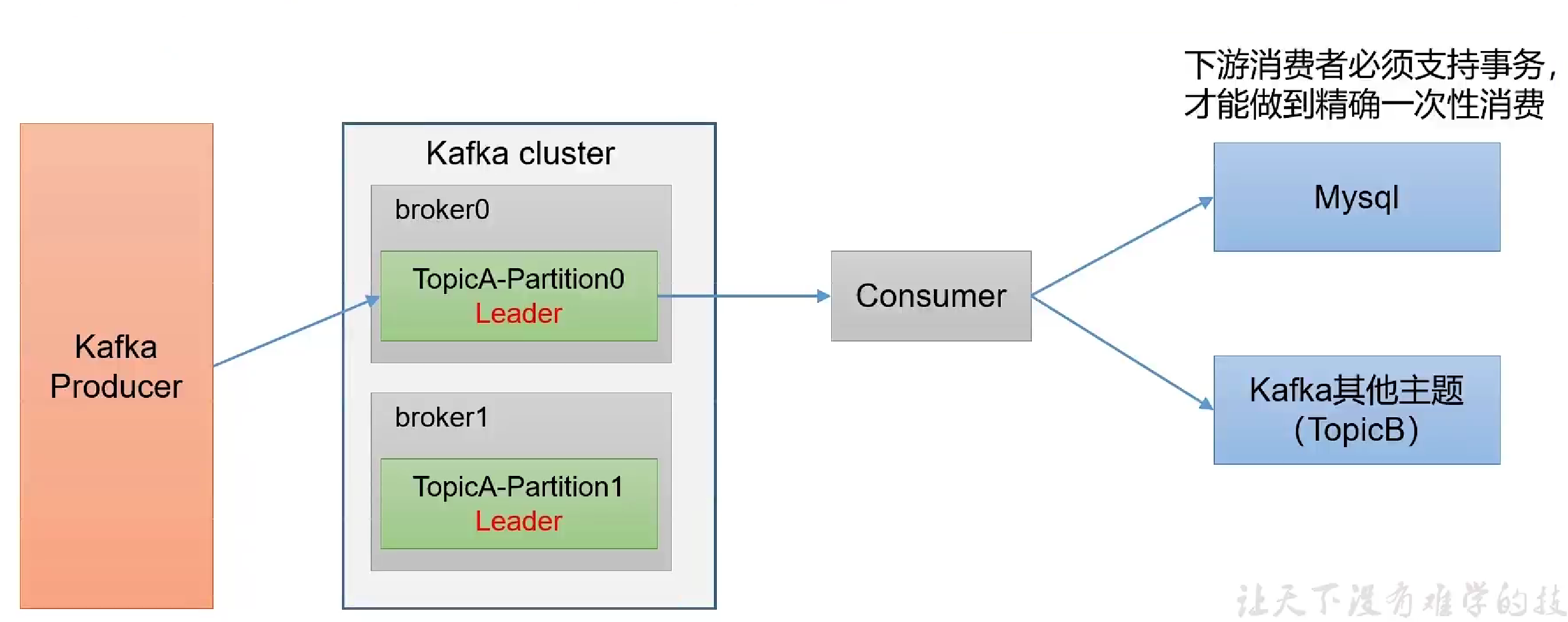
- 消费者事务
- 需要将整个消费过程和提交offset过程做原子绑定,此时需要将offset存储在支持事务的中介(如Mysql)
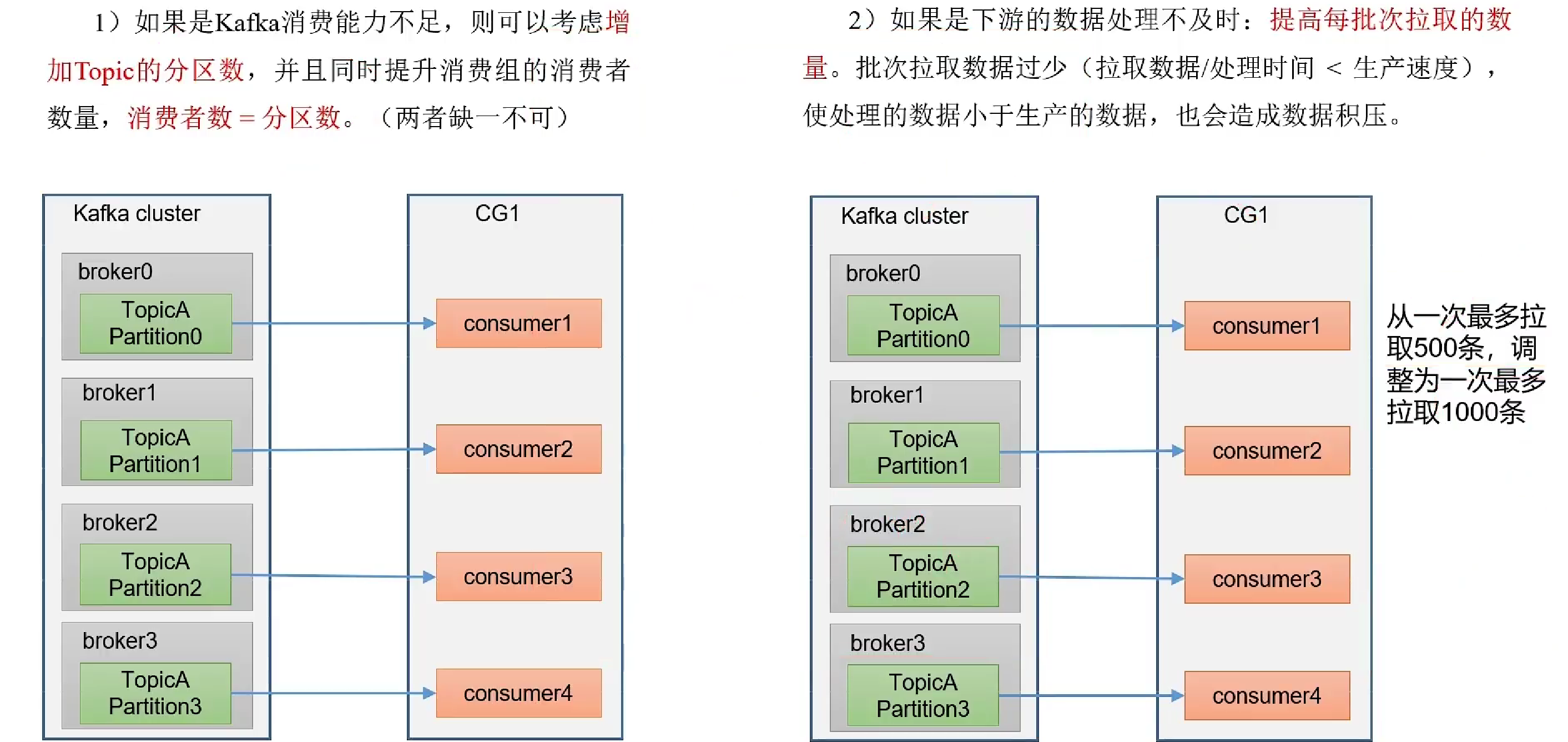
提高消费者吞吐量
- 增加Toppic分区数和消费者数量,消费者数=分区数
- 提交每次拉取数据量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现