进程编程
---恢复内容开始---
一、多道技术核心
1.空间上的复用
多个程序共用一套计算机硬件
2.时间上的复用
切换+保存状态
1.当一个程序遇到IO操作 操作系统会剥夺该程序(提高了cpu的利用率)
2.当一个程序长时间占用cpu 操作系统也会剥夺该程序的cpu执行权限
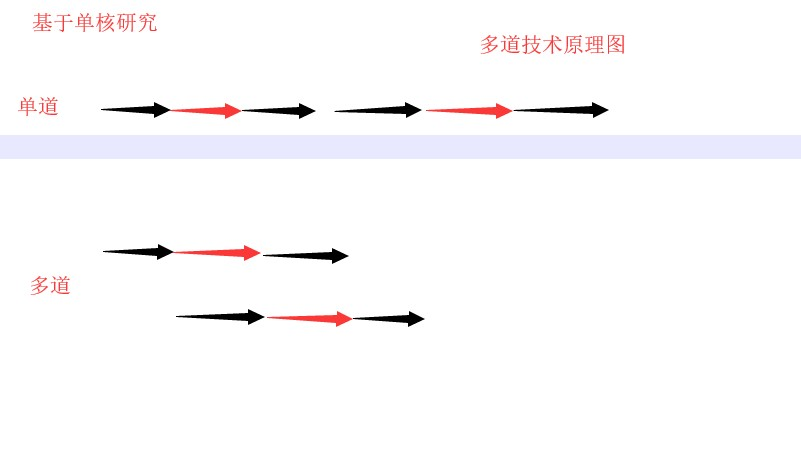
3.单道与多道状态图
二、进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
狭义定义:进程是正在运行的程序的实例
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。
这是官方定义,但是我们可以理解为:一个程序是由一串代码组成的,那么进程就是正在运行的程序。
程序:一坨代码
进程:正在运行的程序
进程的并行与并发
并发:看起来像同时在运行
并行:真正意义上的同时运行
单核计算机不能实现并行,但可以实现并发
同步异步阻塞非阻塞
同步异步:表示任务提交的方式
同步:任务提交之后 原地等待的任务的执行并拿到返回结果才走 期间不做任何事(程序层面的表现就是卡住了)
异步:任务提交之后 不再原地等待 而是继续执行下一行代码(结果是要的 但是是用过其他方式获取)
阻塞非阻塞:表示程序运行的状态
阻塞:阻塞态
非阻塞:就绪态 运行态
状态介绍
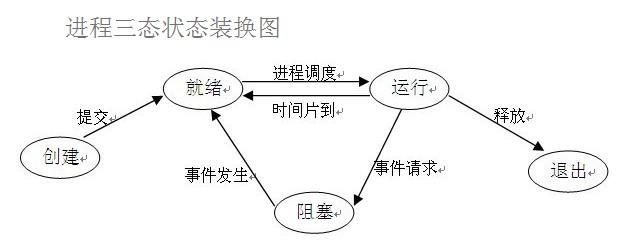
一个程序运行具有“就绪,运行,阻塞”三种状态,就比如启动支付宝软件,程序启动会先就绪,然后运行,之后就会进入支付宝这个界面,这个时候CPU就不运行了,程序就进入了阻塞的状态,
再次点击支付宝当中的某个功能的时候,程序又会重新进入就绪状态开始运行。
强调:同步异步与阻塞非阻塞是两个概念
windows创建进程会将代码以模块的方式 从上往下执行一遍
linux会直接将代码完完整整的拷贝一份
注意:
windows创建进程一定要在if name == 'main':代码块内创建 否则报错
创建进程就是在内存中重新开辟一块内存空间 将允许产生的代码丢进去 一个进程对应在内存就是一块独立的内存空间
进程与进程之间数据是隔离的 无法直接交互
from multiprocessing import Process import time def f(name): print('%s is running'%name) time.sleep(2) print('%s is over'%name) if __name__ == '__main__': p = Process(target=f,args=('nick',)) # 创建一个进程对象 p.start() # 告诉操作系统帮你创建一个过程 print('1号主进程')
class MyProcess(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s is running'%self.name) time.sleep(1) print('%s is over'%self.name) if __name__ == '__main__': p = MyProcess('egon') p.start() print('2号主进程')
四、join方法
之前创建进程的两种方式运行结果都是先运行主进程,然后再运行子进程
增加join方法之后,就会先运行子进程,子进程运行完毕后再运行主进程


class MyProcess(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s is running'%self.name) time.sleep(1) print('%s is over'%self.name) if __name__ == '__main__': p = MyProcess('egon') p.start() p.join() print('主进程')
五、进程间的数据时相互隔离的
利用代码进行演示
主进程会执行主进程之间的数据,子进程会执行子进程之间的数据
from multiprocessing import Process def work(): global n n=0 print('子进程内: ',n) if __name__ == '__main__': n = 100 p=Process(target=work) p.start() print('主进程内: ',n) #运行结果:主进程内: 100 子进程内: 0
六、进程对象及其他应用方法
1.获取“子进程”与“主进程”
# current_process # 获取当前进程号 from multiprocessing import Process,current_process import time def test(name): print('%s is running' % name, current_process().pid) time.sleep(30) print('%s is over' % name) if __name__ == '__main__': p = Process(target=test,args=('egon',)) p.start() print('主进程',current_process().pid)
运行结束的结果:

在终端运行这些进程号,查看这主进程与子进程分别代表哪些应用程序
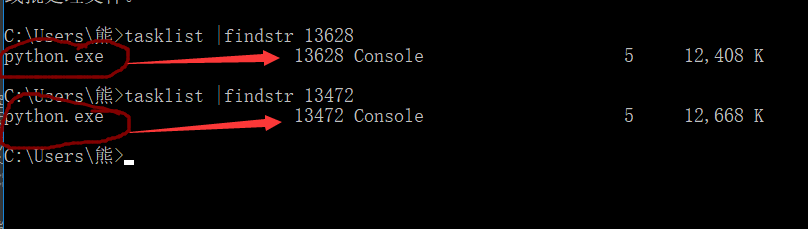
由终端运行结果可知,主进程与子进程都是代表python.exe,这是为什么呢?
原因:
因为py文件不能直接被cpu执行,必须是python解释器与cpu打交道,
用·python去创建多个进程,所以每一个进程里都会有一个python解释器
2.获取“子进程”的“父进程” 获取“主进程的主主进程”
from multiprocessing import Process import time import os def test(name): print('%s is running' % name, '子进程%s' % os.getpid(), '父进程%s' % os.getppid()) time.sleep(3) # 在30秒之后才结束子进程 print('%s is over' % name) if __name__ == '__main__': p = Process(target=test,args=('egon',)) p.start() print('主', os.getpid(),'主主进程:%s' % os.getppid())
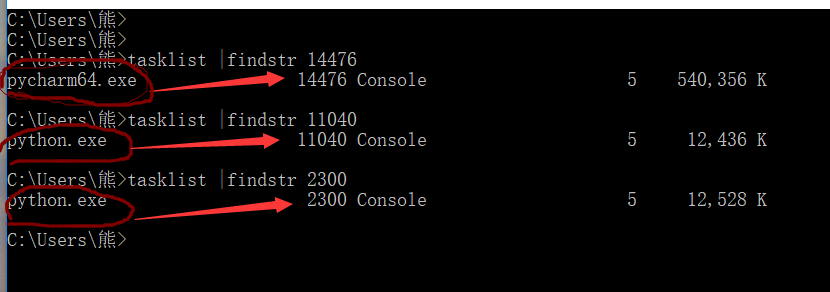
运行结束的结果:

在终端运行这些进程号,由此可知这些进程号都代表哪些应用程序:
3.其它方法补充
杀死进程与判断进程是否存在
from multiprocessing import Process,current_process import os import time def test(name): print('%s is running'%name,'子进程%s'%os.getpid(),'父进程%s'%os.getppid()) time.sleep(3) print('%s is over'%name) if __name__ == '__main__': p = Process(target=test,args=('egon',)) p.start() p.terminate() # 杀死当前进程 其实是告诉操作系统帮你杀死一个进程 time.sleep(0.1) # 因为代码运行速度比操作系统运行速度快,所以睡0.1秒即可 print(p.is_alive()) # 判断进程是否存活 print('主',os.getpid(),'主主进程:%s'%os.getppid())
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。**
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。**
父进程回收子进程资源的两种方式
1.join方法 2.父进程正常死亡 所有的进程都会步入僵尸进程
子进程没死 父进程意外死亡 针对linux会有儿童福利院(init) 如果父进程意外死亡他所创建的子进程都会被福利院收养
八、守护进程
守护进程(daemon)是一类在后台运行的特殊进程,用于执行特定的系统任务。很多守护进程在系统引导的时候启动,并且一直运行直到系统关闭。另一些只在需要的时候才启动,完成任务后就自动结束。
from multiprocessing import Process import time def test(name): print('%s总管正常活着'%name) time.sleep(3) print('%s总管正常死亡'%name) if __name__ == '__main__': p = Process(target=test,args=('egon',)) p.daemon = True # 将该进程设置为守护进程 这一句话必须放在start语句之前 否则报错 p.start() time.sleep(0.1) print('皇帝jason寿正终寝')
九、互斥锁
当多个进程操作同一份数据的时候 ,会造成数据的错乱 ,这个时候必须加锁处理
将并发变成串行, 虽然降低了效率但是提高了数据的安全
注意:
1.锁不要轻易使用 容易造成死锁现象
2.只在处理数据的部分加锁 。不要在全局加锁
锁必须在主进程中产生 交给子进程去使用
模拟抢票软件
from multiprocessing import Process,Lock import time import json # 查票 def search(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) print('用户%s查询余票为:%s'%(i,t_d.get('ticket'))) # 买票 def buy(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) time.sleep(1) if t_d.get('ticket') > 0: # 票数减一 t_d['ticket'] -= 1 # 更新票数 with open('data','w',encoding='utf-8') as f: json.dump(t_d,f) print('用户%s抢票成功'%i) else: print('没票了') def run(i,mutex): search(i) mutex.acquire() # 抢锁 只要有人抢到了锁 其他人必须等待该人释放锁 buy(i) mutex.release() # 释放锁 if __name__ == '__main__': mutex = Lock() # 生成了一把锁 for i in range(10): p = Process(target=run,args=(i,mutex)) p.start()
十、进程间通信
队列(multiprocess.Queue)概念
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
主要方法
Queue的实例q具有以下方法:
q.get_nowait()
取值,没有值不等待,直接报错。
q.put()
往队列中添加数据。
q.empty()
判断队列中的数据是否取完,如果调用此方法时 q为空,返回True。
q.full()
判断队列是否满了,如果q已满,返回为True。
from multiprocessing import Queue q = Queue(5) # 括号内可以传参数 表示的是这个队列的最大存储数 #1.往队列中添加数据 q.put(1) q.put(2) # print(q.full()) # 判断队列是否满了,因为在此处还没满,所以返回结果为:False q.put(3) q.put(4) q.put(5) # print(q.full()) # 在此处数据已满,返回结果为:True # q.put(6) # 当队列满了之后 再放入数据 不会报错 会原地等待 直到队列中有数据被取走(阻塞态) #2.取数据 print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get()) # print(q.empty()) # 判断对列数据是否取完(类似于full方法),在此处已取完5次,所以返回结果为:True print(q.get()) # 当队列中的数据被取完之后 再次获取 程序会阻塞 直到有人往队列中放入值 # print(q.get_nowait()) # 取值,没有值不等待,直接报错
1.如果只添加了5组数据,却取了六组数据,结果会是什么?
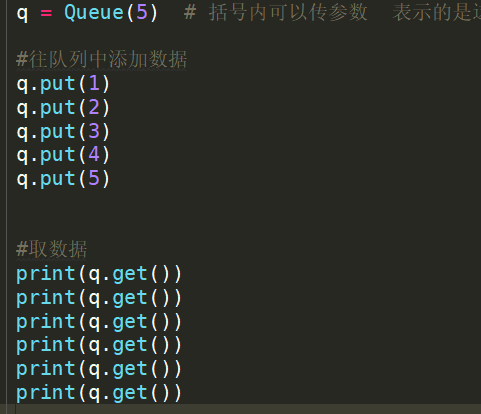
图一 添加5组取6组
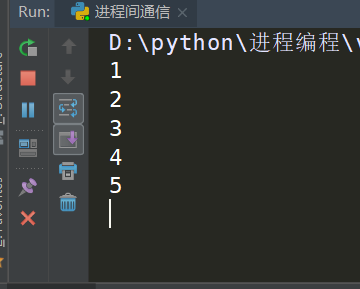
图二、运行结果
能够取出前面的5组数据,
没有的数据会在原地等待
2.如果有六组数据,但是却取5组数据,结果会是什么呢?
结果如下图所示
进程间通信IPC机制
队列能够实现两个独立的内存空间数据的通信
子进程放数据,主进程获取数据
两个进程之间相互放取数据
from multiprocessing import Queue,Process def producer(q): q.put('hello') # 子进程放数据 def consumer(q): print(q.get()) # 主进程获取数据 if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) # 子进程 c = Process(target=consumer,args=(q,)) # 主进程 p.start() c.start()
12、生产者消费模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
''' 生产者:生产/制造数据的 消费者:消费/处理数据的 例子:做包子的,买包子的 1.做包子远比买包子的多 2.做包子的远比包子的少 供需不平衡的问题 ''' from multiprocessing import Process,Queue,JoinableQueue # JoinableQueue是能够被等待的队列 import random import time def producer(name,food,q): for i in range(1,10): data = '%s生产了%s%s'%(name,food,i) time.sleep(random.random()) q.put(data) print(data) def consumer(name,q): while True: data = q.get() if data == None: break print('%s吃了%s'%(name,data)) time.sleep(random.random()) q.task_done() # 告诉队列你已经取出了一个数据,并且处理完毕了 if __name__ == '__main__': q = JoinableQueue() p = Process(target=producer,args=('大厨亮平','馒头',q)) p1 = Process(target=producer,args=('跟班冯琪','生蚝',q)) c = Process(target=consumer,args=('佩琪',q)) c1 = Process(target=consumer,args=('浩哥',q)) p.start() p1.start() c.daemon = True c1.daemon = True c.start() c1.start() p.join() p1.join() q.join()

