

python学习笔记5:基础(函数)
自定义函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
1 while True: 2 if cpu利用率 > 90%: 3 #发送邮件提醒 4 连接邮箱服务器 5 发送邮件 6 关闭连接 7 8 if 硬盘使用空间 > 90%: 9 #发送邮件提醒 10 连接邮箱服务器 11 发送邮件 12 关闭连接 13 14 if 内存占用 > 80%: 15 #发送邮件提醒 16 连接邮箱服务器 17 发送邮件 18 关闭连接
也可改写为:
1 def 发送邮件(内容) 2 #发送邮件提醒 3 连接邮箱服务器 4 发送邮件 5 关闭连接 6 7 while True: 8 9 if cpu利用率 > 90%: 10 发送邮件('CPU报警') 11 12 if 硬盘使用空间 > 90%: 13 发送邮件('硬盘报警') 14 15 if 内存占用 > 80%:
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
我们首先要搞明白计算机(Computer)和计算(Compute)的概念。
在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。
而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。
对应到编程语言,就是越低级的语言,越贴近计算机,抽象程度低,执行效率高,比如C语言;越高级的语言,越贴近计算,抽象程度高,执行效率低,比如Lisp语言。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
函数式编程最重要的是增强代码的重用性和可读性
二、 函数的定义和使用
1 def 函数名(参数): 2 3 ... 4 函数体 5 ...
def:表示函数的关键字函数的定义主要有如下要点:
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
以上要点中,比较重要有参数和返回值:
(1)、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。
Python的函数的返回值使用return语句,可以将函数作为一个值赋值给指定变量:
该功能到底执行成功与否,需要通过返回值来告知调用者。
def 发送短信(): 发送短信的代码... if 发送成功: return True else: return False while True: # 每次执行发送短信函数,都会将返回值自动赋值给result # 之后,可以根据result来写日志,或重发等操作 result = 发送短信() if result == False: 记录日志,短信发送失败...
(2)、参数
为什么要有参数?


1 def CPU报警邮件() 2 #发送邮件提醒 3 连接邮箱服务器 4 发送邮件 5 关闭连接 6 7 def 硬盘报警邮件() 8 #发送邮件提醒 9 连接邮箱服务器 10 发送邮件 11 关闭连接 12 13 def 内存报警邮件() 14 #发送邮件提醒 15 连接邮箱服务器 16 发送邮件 17 关闭连接 18 19 while True: 20 21 if cpu利用率 > 90%: 22 CPU报警邮件() 23 24 if 硬盘使用空间 > 90%: 25 硬盘报警邮件() 26 27 if 内存占用 > 80%: 28 内存报警邮件()
1 def 发送邮件(邮件内容) 2 3 #发送邮件提醒 4 连接邮箱服务器 5 发送邮件 6 关闭连接 7 8 9 while True: 10 11 if cpu利用率 > 90%: 12 发送邮件("CPU报警了。") 13 14 if 硬盘使用空间 > 90%: 15 发送邮件("硬盘报警了。") 16 17 if 内存占用 > 80%: 18 发送邮件("内存报警了。")
函数的有三中不同的参数:
- 普通参数
- 默认参数
- 动态参数 1个* 接收 序列;2个*接收 字典
1 # ######### 定义函数 ######### 2 3 # name 叫做函数func的形式参数,简称:形参 4 def func(name): 5 print name 6 7 # ######### 执行函数 ######### 8 # 'wupeiqi' 叫做函数func的实际参数,简称:实参 9 func('wupeiqi')
1 def func(name, age = 18): 2 3 print "%s:%s" %(name,age) 4 5 # 指定参数 6 func('wupeiqi', 19) 7 # 使用默认参数 8 func('alex') 9 10 注:默认参数需要放在参数列表最后
1 #### 2 # * 只能在最后一个参数 3 4 def func(*args): 5 6 print args 7 8 9 # 执行方式一 10 func(11,33,4,4454,5) 11 12 # 执行方式二 13 li = [11,2,2,3,3,4,54] 14 func(*li)
1 ##** 2个星默认为字典 2 3 def func(**kwargs): 4 5 print args 6 7 8 # 执行方式一 9 func(name='wupeiqi',age=18) 10 11 # 执行方式二 12 li = {'name':'wupeiqi', age:18, 'gender':'male'} 13 func(**li)
1 ## 2 def func(*args, **kwargs): 3 4 print args 5 print kwargs 6 7 func(11,22,33,k1='12',k2='13')
扩展:发送邮件实例
1 def smg(): 2 import smtplib 3 from email.mime.text import MIMEText 4 from email.utils import formataddr 5 6 mail_msg = """ 7 <p>Python 邮件发送测试...</p> 8 <p><a href="http://www.runoob.com">这是一个链接</a></p> 9 <p><img src="cid:image1"></p> 10 """ 11 12 msg = MIMEText(mail_msg, 'html', 'utf-8') 13 msg['From'] = formataddr(["熊力", 'xiongli1@sina.com']) 14 msg['To'] = formataddr(["飞飞", '283378285@qq.com']) 15 msg['Subject'] = "熊熊的邮件测试" 16 17 server = smtplib.SMTP("smtp.sina.com", 25) 18 server.login("xiongli1@sina.com", "邮件密码") 19 server.sendmail('xiongli1@sina.com', ['261016594@qq.com', ], msg.as_string()) 20 server.quit() 21 22 23 smg()
(3)、内置函数(Built-in Functions)
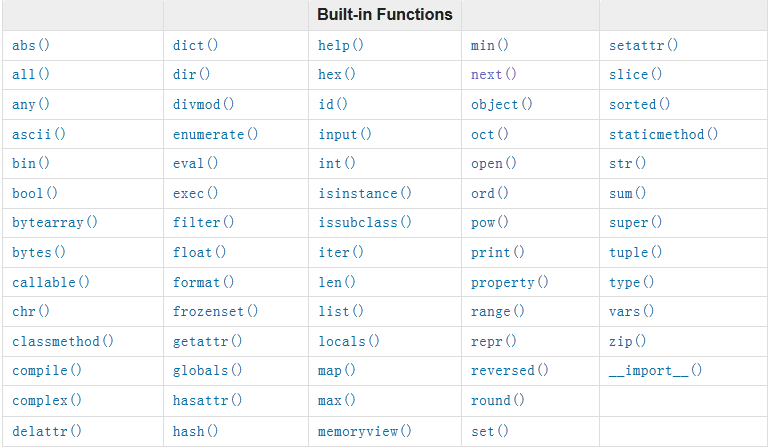
The Python interpreter has a number of functions and types built into it thatare always available. They are listed here in alphabetical order.
官方文档:点击
1.abs()【绝对值】
|
1
2
3
4
5
6
7
|
>>> abs(-10)10>>> abs(10)10>>> a=-10>>> a.__abs__()10 |
2.all()集合中的元素都为真的时候为真,若为空串返回为True
|
1
2
3
4
5
6
|
>>> li = ['yao','liu']>>> li_1=[]>>> print(all(li))True>>> print(all(li_1))True |
3.any()集合中的元素有一个为真的时候为真若为空串返回为False
|
1
2
3
4
5
6
7
8
9
|
>>> li['yao', 'liu']>>> li_1[]>>> print(any(li))True>>> print(any(li_1))False>>> |
4.chr()返回整数对应的ASCII字符
|
1
2
|
>>> print(chr(65))A |
5.ord()返回字符对应的ASC码数字编号
|
1
2
3
|
>>> print(ord('A'))65>>> |
6.bin(x)将整数x转换为二进制字符串
|
1
2
3
|
>>> print(bin(10))0b1010>>> |
7.bool(x)返回x的布尔值
|
1
2
3
4
5
|
>>> print(bool(0))False>>> print(bool(1))True>>> |
8.dir()不带参数时,返回当前范围内的变量、方法和定义的类型列表,带参数时,返回参数的属性、方法列表。
|
1
2
3
4
|
>>> dir()['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'li', 'li1', 'li2', 'li_1']>>> dir(list)['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] |
9.divmod()分别取商和余数.
|
1
2
|
>>> divmod(20,6)(3, 2) |
10.enumerate()返回一个可枚举的对象,该对象的next()方法将返回一个tuple
|
1
2
3
4
5
6
7
|
>>> info = ['liu','yao','sb']>>> for k,v in enumerate(info):... print(k,v)... 0 liu1 yao2 sb |
11.eval()将字符串str当成有效的表达式来求值并返回计算结果。
|
1
2
3
4
|
>>> name = '[[1,2], [3,4], [5,6], [7,8], [9,0]]'>>> a = eval(name)>>> print(a)[[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]] |
12.filter(function, iterable)函数可以对序列做过滤处理
|
1
2
3
4
5
6
7
|
>>> def guolvhanshu(num):... if num>5 and num<10:... return num>>> seq=(12,50,8,17,65,14,9,6,14,5)>>> result=filter(guolvhanshu,seq)>>> print(list(result))[8, 9, 6] |
13.hex(x)将整数x转换为16进制字符串。
|
1
2
|
>>> hex(21)'0x15' |
14.id()返回对象的内存地址
|
1
2
|
>>> id(22)10106496 |
15.len()返回对象的长度
|
1
2
3
|
>>> name = 'liuyao'>>> len(name)6
|
16.map遍历序列,对序列中每个元素进行操作,最终获取新的序列。
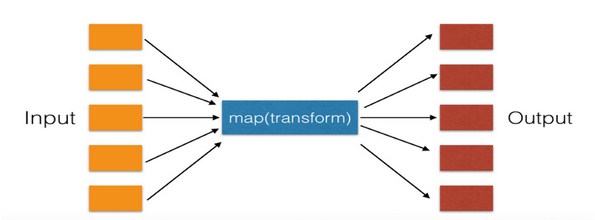
例:
|
1
2
|
li = [11, 22, 33]li_1 = map(lambda a: a + 100, li) |
|
1
2
3
|
li = [11, 22, 33]sl = [1, 2, 3]lit = map(lambda a, b: a + b, li, sl) |
17.oct()八进制转换
|
1
2
3
|
>>> oct(10)'0o12'>>> |
18.range()产生一个序列,默认从0开始
|
1
2
3
|
>>> range(14)range(0, 14)>>> |
19.reversed()反转
|
1
2
3
4
5
6
7
8
|
>>> re = list(range(10))>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> re_1 = reversed(re)>>> re_1<list_reverseiterator object at 0x7f50d1788be0>>>> print(list(re_1))[9, 8, 7, 6, 5, 4, 3, 2, 1, 0] |
20.round()四舍五入
|
1
2
3
4
|
>>> round(4,6)4>>> round(5,6)5 |
21.sorted()队集合排序
|
1
2
3
4
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> sorted(re)[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
22.sum()对集合求和
|
1
2
3
4
5
6
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> type(re)<class 'list'>>>> sum(re)45 |
23.type()返回该object的类型
|
1
2
3
4
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> type(re)<class 'list'> |
24.vars()返回对象的变量,若无参数与dict()方法类似。
|
1
2
|
>>> vars(){'v': 'sb', 'a': [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]], 'k': 2, '__builtins__': <module 'builtins' (built-in)>, 're': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'info': ['liu', 'yao', 'sb'], '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__doc__': None, 'li2': ['name', []], 're_1': <list_reverseiterator object at 0x7f50d1788be0>, 'guolvhanshu': <function guolvhanshu at 0x7f50d1874bf8>, 'li1': [], 'name': 'liuyao', 'seq': (12, 50, 8, 17, 65, 14, 9, 6, 14, 5), '__spec__': None, 'li_1': [], 'li': ['yao', 'liu'], '__name__': '__main__', 'result': <filter object at 0x7f50d1788ba8>, '__package__': None} |
25.zip()zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表。
26.reduce对于序列内所有元素进行累计操作
(4)、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def calc(n): print(n) if int(n/2) ==0: return n return calc(int(n/2))calc(10)输出:10521 |
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
(5). 匿名函数 -->lambda
匿名函数就是不需要显式的指定函数
|
1
2
3
4
5
6
7
8
|
#这段代码def calc(n): return n**nprint(calc(10))#换成匿名函数calc = lambda n:n**nprint(calc(10)) |
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
|
1
2
3
|
res = map(lambda x:x**2,[1,5,7,4,8])for i in res: print(i) |
输出
1
25
49
16
64
|
1
2
3
4
5
6
7
8
|
# 普通条件语句if1==1: name ='wupeiqi'else: name ='alex' # 三元运算name ='wupeiqi'if1==1else'alex'
|
