


3、python基础语法知识
3.1变量
1.什么是变量?
可以变化的量
2.为什么要有变量?
程序去执行一种状态,并且是可以变化的
1.变量的使用
原则:先定义,后使用
name='hello' #定义 print(name) #使用
2.变量的内存管理
申请的变量不用就要释放
内存管理:垃圾回收机制
垃圾:没有变量名的值
引用计数:同一个值可以关联不同的变量名
引用计数增加:
x=10 #10的引用计数为1 y=x #10的引用计数为2 z=x #10的引用计数为3
引用计数减少:
x=10 #10的引用计数为1 y=x #10的引用计数为1 z=x #10的引用计数为1 del x #解除变量名x与值10的绑定关系,10的引用计数为2 del y #解除变量名y与值10的绑定关系,10的引用计数为1 z=12346 #z会解除与10的关联 print(z)
3.变量名的命名
原则:见名知意
命名规范:
变量名只能是字母,数字或者下划线的任意组合
变量名的第一个字符不能是字符
关键字不能声明为变量名
变量名的命名风格:
1.驼峰命名法
AgeOfAlex=30
2.纯小写加下划线的方法(python推荐使用这种方式)
age_of_alex=30
4.变量值
变量值的三个重要的特征
id:反映的是变量值的内存地址,内存地址不同,id不同
print(id(name))
type:数据类型
print(type(name))
value:值本身,等号右边的值
is与==
is:比较左右两个值身份id是否相等
==:比较左右两个值他们的值是否相等
注意:
值一样的情况下,id的值也不一样
id相同的情况下,值一定相同
注意:
小整数池:[-5,256]从Python解释器启动的那一刻开始,就会在内存中事先申请好一系列的内存空间来存放常用的整数
>>> m=10 >>> n=10 >>> m is n True >>> id(m),id(n) (2423951786512, 2423951786512) >>> x='aaa' >>> y='bbb' >>> id(x),id(y) (2423953409264, 2423953414576)
# 垃圾回收机制 # 1.引用计数 # 1.1 直接引用 # x= 10 # print(id(x)) # 1.2 间接引用 # l=['a', x] # print(id(l[1])) # id 地址都是相同的 # 列表在内存中开辟一个区域来存索引与内存地址,一个内存地址指向真正所存的 # x= 10 # l=['a','b', x] # l=['a的内存地址','b的内存地址','x的内存地址'] # x = 123 # x的值是变的,但是x的内存地址是不会变的 # 2.标记清除 # 循环引用 # 在循环引用的使用下,把l1,l2的直接引用去掉,没有直接访问的可能性,彼此只剩间接使用,引用计数不为0,此时他们成为了永远不能回收的垃圾,此时就叫内存泄露 l1 = [111] l2 = [222]l1.append(l2) # l1=['111的内存地址','l2的内存地址'] l2.append(l1) # l2=['222的内存地址','l1的内存地址']print(id(l1))print(id(l2[0])) # 3.分代回收 # 分代回收就是根据存活时间为变量划分不同的等级,然后对引用计数进行计算来回收
3.2常量
常量:不变的量
注意:在Python中没有常量的概念,但是在程序开发的过程中会涉及到常量的概念比如:π 一个人的年龄在某种情况下是常量
常量的表示:小写的字母全部为大写,代表常量
AGE_OF_A = 12 # 可以修改,但是最好不要修改
3.3数据类型
一、数字类型
1.整形int作用:记录年龄,身份证号码,个数等定义:age=18
2.浮点型float作用:记录薪资,身高,体重
3.数字类型的其他使用
做数学运算level = 1x = level + 1整数是可以和浮点型进行相加的
# 1.int类型 # 定义 # age = 10 # age = int(10) # 纯数字转化为int # int可以将由纯整数构成的字符串直接转换成整型,若包含其他任意非整数符号,则会报错 # res = int('1212') # 了解: # 十进制=》二进制 # print(bin(20)) # 0b表示是二进制 # 二进制=》十进制 # print(int('0b1001',2)) # 十进制=》八进制 # print(oct(11)) # 0o表示八进制 # 八进制转十进制 # print(int('0o12',8)) # 十进制=》十六进制 # print(hex(12)) # 0x开头表示十六进制 # 十六进制=》十进制 # print(int('0xb',16)) # 2.浮点型float的定义 # salary=3000.3 # 本质salary=float(3000.3) # 注意:名字+括号的意思就是调用某个功能,比如 # print(...)调用打印功能 # int(...)调用创建整型数据的功能 # float(...)调用创建浮点型数据的功能 # float同样可以用来做数据类型的转换 # s = '12.3' # res=float(s) # (12.3, <class 'float'>)
二、字符串类型
作用:描述类型性质的状态,比如名字,一段话
定义:用引号("",'',''' ''',""" """)包含的一串字符 延迟满足
name = 'upup'
x= 18 x是整形
x = '18' x是字符串
# 作用:定义描述性质的状态 # 定义: # msg = 'hello' # 类型转换:str可以把任意类型都转成字符串 # res=str({'k1':12}) # print(res,type(res)) # {'k1': 12} <class 'str'> #单引号、双引号、多引号有什么区别呢?单双引号木有任何区别,只有下面这种情况 需要考虑单双的配合 msg = "My name is gigi , I'm 18 years old!" #多引号什么作用呢?作用就是多行字符串必须用多引号 msg = ''' 今天 天气 真好 ''' print(msg) #数字可以进行加减乘除等运算,字符串呢?也能,但只能进行"相加"和"相乘"运算。 # name='hahaha' # age='18' # hahaha+age #相加其实就是简单拼接 # 'hahaha18' # name*5 'hahaha18hahaha18hahaha18hahaha18hahaha18' #注意1:字符串相加的效率不高 字符串1+字符串3,并不会在字符串1的基础上加字符串2,而是申请一个全新的内存空间存入字符串1和字符串3,相当字符串1与字符串3的空间被复制了一次, #注意2:只能字符串加字符串,不能字符串加其他类型 # 内置方法 # 1.优先掌握 # 1.1 按索引取值(正向取+反向取),只能取 # 正向取 msg ='hello baby' # 空格也算字符 print(msg[3]) print(msg[6]) # 反向取 msg ='hello baby' # 空格也算字符 print(msg[-3]) print(msg[-6]) # 只能取,不能修改索引的值 msg ='hello baby' # 空格也算字符 msg[0]='H' print(msg[0]) # 会报错 # 1.2 切片:索引的扩展应用,从一个大字符串中拷贝一个小字符串 msg ='hello baby' res = msg[0:5] # 顾头不顾尾,从索引开始计算 print(res) # 1.3步长 # 不写步长,默认步长为1 msg ='hello baby' res=msg[0:5:2] # 0,2,4 print(res) # hlo # 反向步长 msg = 'hello baby' res = msg[5:0:-1] print(res) msg = 'hello baby' res = msg[0:11] res = msg[:] # 与上面的效果是一样的 print(res) # 倒着取 把字符串倒着取过来 res = msg[::-1] # 1.4长度len msg = 'hello baby' print(len(msg)) # 1.5成员运算 in 或者not in # 判断一个子字符串是否存在于一个大字符串中 res='hello' in 'hello baby' print(res) # 1.6移除字符串左右两侧的符号strip lstrip rstrip msg = ' hello ' res=msg.strip() # 不传参数,默认去掉空格 print(res) # 产生了新的值 msg = '***hello***' print(msg.strip('*')) # 默认去掉*号 # 了解:strip只去两边,不去中间 msg = 'h***h**' print(msg.strip('*')) msg = '**/*=-**hello*-=()**' print(msg.strip('*/-=()')) # 两边的符号可以完全去掉 #strip name='*hahaha**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) # 应用 uname=input('name:').strip() upwd=input('pwd:').strip() if uname=='hello' and upwd=='123': print('okok') else: print('error') # 1.7切分split rsplit # 把某一个字符串按照某种分隔符进行切分,得到一个列表 info = "hello 18 baby" res=info.split() # 不传参数默认按照空格进行分割 print(res) # 得到一个列表 # 指定分隔符 info = "hello:18baby" res=info.split(':') print(res) # 指定分割次数 了解 info = "hello:18:baby" res=info.split(':',1) print(res) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分 # 1.8循环 # 空格也会依次循环打印出来 info = "hello:18:baby" for k in info: print(k) # 2.需要掌握 # 2.1 strip lstrip(去左边的符号) rstrip(去右边的符号) name='*hahaha**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) # 2.2 lower upper msg='asdfg' print(msg.upper()) # 2.3 startswitch endswitch 判断以什么开头与结尾的 返回的是布尔值 msg = 'hello baby' res =msg.startswith('hello') print(res) # 2.4format 的三种方式 # 3.str.format 字符串格式化 兼容性好 # 按照位置传值 res = "我的名字是 {},我的年龄是 {}" .format('hello','19') print(res) res = "我的名字是 {0}{0}{0},我的年龄是 {1}" .format('hello','19') print(res) # 打破位置限制,按照key=value传值 res = "我的名字是{name},我的年纪是{age}".format(age=18,name="hello") print(res) # 4.f:python3.5以后才支持这种格式 x=input('name') y=input('age') res = f"我的名字是{x},我的年龄是{y}" print(res) # 2.5split(从左往右开始切) rsplit(从右往左开始切) info = "hello:18:baby" res=info.split(':',1) res = info.rsplit(':',1) print(res) # 2.6 join 把列表拼接成字符串 可迭代对象必须都是字符串 l= ['name','12','hhhh'] res=':'.join(l) # 按照某个分隔符,把纯字符串的列表拼接成一个大字符串 注意:必须全部都是字符串 print(res) # 2.7 replace 替换 msg = 'hello baby' res=msg.replace('hello','hi',1) # 后面的数字表示替换几次 print(res) # 2.8isdigit # 判断字符串是否是由数字组成 res='123'.isdigit() print(res) # 3 了解 # 3.1 find rfind index rindex count # rfind()函数用于返回字符串最后一次出现的位置(从右向左查询),如果没有匹配项则返回“-1”。 # rindex()方法返回所在的子str被找到的最后一个索引,可选择限制搜索的字符串string[beg:end] 如果没有这样的索引存在,抛出一个异常。 msg='hello baby hhh' res=msg.find('e') # 返回要查找的字符串在大字符串中返回的起始索引,找不到返回-1 res=msg.index('e') # 返回要找的起始索引,找不到就会抛出异常 res=msg.count('h') # 统计要返回的次数 print(res) # 3.2 center ljust rjust zfill msg='hello' res = msg.center(10,'*') # 返回10个字符串,不够就用*号来补在左右两边 res = msg.rjust(10,'*') # 在右边进行填充 res = msg.ljust(10,'*') # 在左边进行填充 res=msg.zfill(10) # 用0填充,默认右填充 print(res) # 3.3expandtabs # expandtabs()将tab转换成空格,默认1个tab转成8个空格,\t制表符代表一个tab,我们也可以自定义转换成几个空格 msg='hello\tbaby' res=msg.expandtabs(4) # 设置制表符代表的空格数为4 print(res) # 3.4 capitalize swapcase title msg = 'hello baby' res=msg.capitalize() # 首字母大写 res = msg.swapcase() # 大小写反转 res = msg.title() # 每个单词的首字母大写 print(res) # 3.5 is数字系列 # 3.5.1 is其他 # print('abc'.islower()) # print('abc'.isupper()) # print('hello baby'.istitle()) # 每个单词的首字母大写 # print('123m'.isalnum()) # 是否是字母或数字组成 # print('123'.isalpha()) # 是否由字母组成 # print(' '.isspace()) # 字符串由空格组成结果为True # print('def'.isidentifier()) # 是否是由Python的内置方法 num1=b'4' # bytes num2=u'4' # Unicode 在Python3中无需加Unicode num3='四' # 中文数字 num4='IV' # 罗马数字 # isdigit只能识别num1,num2 #isnumberic能识别num2,num3,num4 #isdecimal 能识别num2 几乎不用 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric
三、列表类型
索引对应值,索引从0开始,0代表第一个值
作用:按位置记录多个值,并且可以安装索引取出的值
注意:列表中存放的数据大部分都是同一个性质
定义:在[]内用逗号分隔开多个任意类型的值,一个值称之为一个元素
l = [10, 2, 'aaa', ['bbb', 'ccc'], 'ddd'] print(l) print(l[3]) print(l[3][1]) # 列表的嵌套取值 print(l[-2][1]) # 其他的用途 student_info =[ ['Andy', 18, ['play']], ['Helen', 20, ['swim', 'sleep']]] # 取出第二个学生的第一个爱好 print(student_info[1][2][0])
# 作用:按位置用来存多个值 # 定义: l=[1,2,3] print(type[l]) # 类型转换:能够被for循环遍历的类型都可以被当成参数传给list转成列表 res=list('hello') print(res) # 相似的还有字典 # 内置方法 # 1.优先掌握的方法 # 1.1 正向取,反向取 l=[111,'hello','haha'] print(l[0]) print(l[-1]) # 可以取也可以改 l[0]=222 # 索引存在则修改所对应的值 # 索引不存在就不能对他赋值,否则就会报错 # 往列表里面加值 print(l) l=[111,'hello','haha'] # 追加值 l.append(333) # 这个会往列表的末尾加 # extend()一次性在列表尾部添加多个元素 l1 = ['a','b','c'] l1.extend(['a','b','c']) ['a', 'b', 'c', 'a', 'b', 'c'] # 插入值 在指定位置插入元素 l.insert(1,'wawa') # 这个是插入值 1表示按索引位置插值 print(l) # 往列表中添加列表 l=[1,2,3] new_l=['12','34'] l.extend(new_l) print(l) # 1.2切片(顾头不顾尾,步长) l = [111,'hello','waha'] print(l[0:3]) print(l[0:5:2]) # 0 2 4 # 切完整的l列表 print(l[0:len(l)]) print(l[:]) print(l[::-1]) # 把列表给倒过来 # 切片就是copy行为,相当于浅拷贝 # new_l = l[:] # 1.3 长度 # print(len([1,2,3])) # 1.3成员运算in 和not in print('aaa' in ['asd',222]) # 1.5删除 # 方式一 公用的删除,没有返回值 不支持赋值语法 l = [111,'hello','waha'] del # 删除整体 del l[1] # 删除索引为1的值 print(l) # 方式二 列表相关的删除 # l.pop pop()默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素 # l = [111,'hello','waha'] # l.pop()# 不指定索引默认删除最后一个 # l.pop(1) # 选择删除索引为1的元素 # 方式三 # l.remove 根据元素删除 返回值是None # l = [111,'hello','waha'] # l.remove('hello') # 1.6循环 # for x in ['ac',222,'cv']: # print(x) # reverse()颠倒列表内元素顺序 l = [11,22,33,44] l.reverse() print(l) # [44,33,22,11] # 1.7sort()给列表内所有元素排序 # 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错 l = [11,22,3,42,7,55] l.sort() print(l) # [3, 7, 11, 22, 42, 55] # 默认从小到大排序 l = [11,22,3,42,7,55] l.sort(reverse=True) # reverse用来指定是否跌倒排序,默认为False print(l) # [55, 42, 22, 11, 7, 3] # 1.8 了解知识: # 我们常用的数字类型直接比较大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素,比如 l1=[1,2,3] l2=[2,] print(l2 > l1) # True # 字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大 s1='abc' s2='az' print(s2 > s1) # s1与s2的第一个字符没有分出胜负,但第二个字符'z'>'b',所以s2>s1成立 # True # 所以我们也可以对下面这个列表排序 l = ['A','z','adjk','hello','hea'] l.sort() print(l) # ['A', 'adjk', 'hea', 'hello','z']
四、字典类型dict
字典是key对应值,其中key通常为字符串类型,所以key对值有描述性
索引反应的是位置,对值没有描述的作用
作用:用来存多个值,每个值都有唯一一个key与其对应
定义:用花括号{}来表示,在括号内分开多个key:value value可以是任意类型(int float str list dict) 但是key必须是不可变类型 d = {'a':1,'b':2}
也可以这么定义字典
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
# 类型转换 # 转换1: info=dict([['name','tony'],('age',18)]) print(info) # {'age': 18, 'name': 'tony'} # 转换2:fromkeys会从元组中取出每个值当做key,然后与None组成key:value放到字典中 res = {}.fromkeys(('name','age','sex'),None) print(res) # {'age': None, 'sex': None, 'name': None} # d = {'a':1, 'b':2}# print(d) # print(type(d)) # 字典的其他用法: 嵌套取值 students_info = [ {'name1':'a', 'age1':18, 'gender':'male'}, {'name2':'b', 'age2':19, 'gender':'male'}, {'name3':'c', 'age3':30, 'gender':'male'} ] print(students_info[1]['age2']) # 1、按key存取值:可存可取 # 取值 dic = { 'name': 'xxx', 'age': 18, 'hobbies': ['play game', 'basketball'] } print(dic['name']) # 'xxx' print(dic['hobbies'][1]) # 'basketball' # 对于赋值操作,如果key原先不存在于字典,则会新增key:value dic['gender'] = 'male' print(dic) # {'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'} # 对于赋值操作,如果key原先存在于字典,则会修改对应value的值 dic['name'] = 'tony' print(dic) # {'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']} # 2、长度len print( len(dic) ) # 3 # 3、成员运算in和not in print('name' in dic) # 判断某个值是否是字典的key True # 4、删除 dic.pop('name') # 通过指定字典的key来删除字典的键值对 print(dic) # {'age': 18, 'hobbies': ['play game', 'basketball']} # 5、键keys(),值values(),键值对items() dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'} # 获取字典所有的key print(dic.keys() ) dict_keys(['name', 'age', 'hobbies']) # 获取字典所有的value print(dic.values()) dict_values(['xxx', 18, ['play game', 'basketball']]) # 获取字典所有的键值对 print(dic.items()) dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])]) # 6、循环 # 6.1 默认遍历的是字典的key for key in dic: print(key) """ age hobbies name """ # 6.2 只遍历key for key in dic.keys(): print(key) """ age hobbies name """ # 6.3 只遍历value for key in dic.values(): print(key) """ 18 ['play game', 'basketball'] xxx """ # 6.4 遍历key与value for key in dic.items(): print(key) """ ('age', 18) ('hobbies', ['play game', 'basketball']) ('name', 'xxx') """ 需要掌握的操作 1.get() dic= {'k1':'jason','k2':'Tony','k3':'JY'} print(dic.get('k1')) # 'jason' # key存在,则获取key对应的value值 res=dic.get('xxx') # key不存在,不会报错而是默认返回None print(res) # None res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值 print(res) # 666 # ps:字典取值建议使用get方法 2.pop() dic= {'k1':'jason','k2':'Tony','k3':'JY'} v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值 print(dic) # {'k1': 'jason', 'k3': 'JY'} print( v) # 'Tony' 3.popitem() dic= {'k1':'jason','k2':'Tony','k3':'JY'} item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组内返回 print(dic) # {'k3': 'JY', 'k2': 'Tony'} print(item) # ('k1', 'jason') 4.update() # 用新字典更新旧字典,有则修改,无则添加 dic= {'k1':'jason','k2':'Tony','k3':'JY'} dic.update({'k1':'JN','k4':'xxx'}) print(dic) # {'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'} 5.fromkeys() dic = dict.fromkeys(['k1','k2','k3'],[]) print(dic) # {'k1': [], 'k2': [], 'k3': []} 6.setdefault() # key不存在则新增键值对,并将新增的value返回 dic={'k1':111,'k2':222} res=dic.setdefault('k3',333) print(res) # 333 print(dic) # 字典中新增了键值对 {'k1': 111, 'k3': 333, 'k2': 222} # key存在则不做任何修改,并返回已存在key对应的value值 dic={'k1':111,'k2':222} res=dic.setdefault('k1',666) print(res) # 111 print(dic) # 字典不变 {'k1': 111, 'k2': 222}
五、布尔类型bool
作用:用来记录真假这两种状态的
# 定义: # is_ok=True # is_ok = False # print(type(is_ok)) x = 1 y = 0 # 1和0也可以表示状态 print(type(y))
六、集合类型
# 1.作用 # 1.1 关系运算:取交集与并集 # f1={12,23,57,89,100} # f2={23,12,78,100} # l=[] # for x in f1: # if x in f2: # l.append(x) # print(l) # 1.2 去重 ''' 2.定义:在花括号{}内用逗号分隔开各个元素,元素满足一下三个条件: 1,元素为不可变类型 2.集合内元素为无序 3.集合内元素没有重复 集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算 # 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。 # 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者? d = {} # 默认是空字典 s = set() # 这才是定义空集合 ''' # 3.类型转换 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型 s = set([1,2,3,4]) s1 = set((1,2,3,4)) s2 = set({'name':'jason',}) s3 = set('egon') print(s,s1,s2,s3) # {1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'} print(set({'k1':12,'k2':29,'k3':100})) # {'k1', 'k3', 'k2'} # 4.内置方法 # f1={12,23,57,89,100} # f2={23,12,78,100} # 4.1 取交集 两者共同有的 # res=f1 & f2 # print(res) # res = f1.intersection(f2) # print(res) # 4.2 取并集/合集 两者都有的 重复只留一个 # res = f1 | f2 # print(res) # print(f1.union(f2)) # 4.3 取差集 取第一个所独有的 # res=f1-f2 # print(res) # print(f1.difference(f2)) # print(f2.difference(f1)) # 4.4 取对称差集 取两者独有的,即去掉共同有的 # 方式一: # res=(f1-f2) | (f2-f1) # print(res) # 方式二: # res=f1^f2 # print(res) # print(f1.symmetric_difference(f2)) # 4.5 父子集:包含的关系 # f3={1,2,3} # f4={1,2} # print(f3>f4) # 当f1>f2时,f1为父,f2为子 # 如果 f1 = f2 的时候,f1与f2互为父子 # print(f3.issuperset(f4)) # print(f4.issubset(f3)) # f4 < f3 # 5.去重 # 5.1 只能针对不可变类型去重 # 5.2 无法保证原来的类型 # 对不需要去重,对顺序有要求的可以使用循环,既保证了顺序又去重了 l=['a','b',1,'a','a'] s=set(l) # 将列表转成了集合 print(s) # {'b', 'a', 1} l_new=list(s) # 再将集合转回列表 print(l_new) # ['b', 'a', 1] # 去除了重复,但是打乱了顺序 # 6.其他操作 # 6.1 长度 # s={'a.txt','b','c'} # print(len(s)) # 6.2 成员运算 # res = 'a.txt' in s # print(res) # 6.3 循环 # for x in s: # print(x) # 7 其他内置方法 # 7.1 discard 删除元素 # remove 也是删除一个元素,如果删除的元素不存在则会报错 # s={1,2,3,4,5} # res = s.discard(1) # res=s.discard(6) # res = s.remove(4) # 会报错 # print(s) # 更新 update s={9,1,2,3,4,5} # res=s.update({9,0}) # res=s.pop() # 去除掉第一个元素 # res=s.add(8) # res=s.isdisjoint({3}) # 两个集合完全独立,没有共同部分,返回True # print(res)
七、元组
作用:元组与列表类似,也是可以存多个任意类型的元素,不同之处在于元组的元素不能修改,即元组相当于不可变的列表,用于记录多个固定不允许修改的值,单纯用于取 定义:在()内用逗号分隔开多个任意类型的值 本质:countries = ("中国","美国","英国") # 本质:countries = tuple("中国","美国","英国") 强调:如果元组内只有一个值,则必须加一个逗号,否则()就只是包含的意思而非定义元组 countries = ("中国",) # 本质:countries = tuple("中国") 1、数据类型转换 # 但凡能被for循环的遍历的数据类型都可以传给tuple()转换成元组类型 tuple('wdad') # 结果:('w', 'd', 'a', 'd') tuple([1,2,3]) # 结果:(1, 2, 3) tuple({"name":"jason","age":18}) # 结果:('name', 'age') tuple((1,2,3)) # 结果:(1, 2, 3) tuple({1,2,3,4}) # 结果:(1, 2, 3, 4) # tuple()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到元组中 2、使用 tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33) # 1、按索引取值(正向取+反向取):只能取,不能改否则报错! print(tuple1[0]) # 1 print(tuple1[-2]) # 22 print(tuple1[0] = 'hehe' ) # 报错:TypeError: # 2、切片(顾头不顾尾,步长) print(tuple1[0:6:2] ) # (1, 15000.0, 22) # 3、长度 print(len(tuple1) ) # 6 # 4、成员运算 in 和 not in print('hhaha' in tuple1 ) True print('hhaha' not in tuple1 ) False # 5、循环 for line in tuple1: print(line) 1 hhaha 15000.0 11 22 33
3.4与用户交互
# 接受用户的输入 # 在Python3中:input会将用户输入的所有的内存都存成字符串 username = input("请输入您的账号:") print(username,type(username)) age = input("请输入您的年龄:") print(age,type(age)) # age = int(age) # int只能将纯数字的字符串转为整形# print(age,type(age)) # 在Python2中:有一个raw_input()与Python3的input一模一样 # 在Python2中的input必须要输入一个明确的数据类型 # 格式化输出 # 1.值按照位置与%s一一对应,多一个不行,少一个不行 # 缺点是要记位置,不方便 # res = "my name is %s,my age is %s"%('hello',"18") # res = "my name is %s" % 'hello'# print(res) # 2.以字典的形式传值,打破位置的限制 res = "我的名字是 %(name)s,我的年龄是 %(age)s" % {'age':'12','name':'hello'} print(res) # 注意:%s可以接受任意类型 %d只能接受int # 3.str.format 字符串格式化 兼容性好 # 按照位置传值 res = "我的名字是 {},我的年龄是 {}" .format('hello','19') print(res)# res = "我的名字是 {0}{0}{0},我的年龄是 {1}" .format('hello','19') print(res) # 打破位置限制,按照key=value传值 res = "我的名字是{name},我的年纪是{age}".format(age=18,name="hello") print(res) # 4.f:python3.5以后才支持这种格式 x=input('name') y=input('age') res = f"我的名字是{x},我的年龄是{y}" print(res)
3.5运算符
1.算术运算符
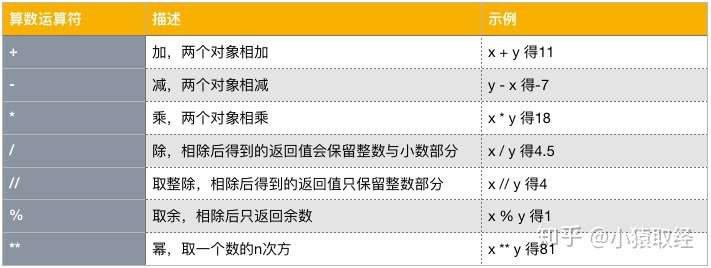
print(1+1) print(10 / 3) # 结果带小数 print(10 // 3) # 只保留整数部分 print(10 % 3) # 取模
2.比较运算符
返回的值是布尔值

print(10 > 3) print(10 == 3) print(10 <= 3) name = input('name') print(name=='hello')
3.赋值运算符

# 3.1增量赋值 # 年龄加1 age=18 age+=1 print(age) # 3.2 链式赋值 x=10 y=x z=y x = y = z = 10 # 把上面的代码改写成这一行 # 3.3 交叉赋值 # m和n交换变量,先给一个临时变量 m=10 n=20 # temp = m # m = n # n = temp # print(m) # print(n) m,n = n,m # 交叉赋值也可以用一行代码搞定 print(m) print(n) # 3.4解压赋值 # sal= [11,22,33,44,55] # m0=sal[0] # m1=sal[1] # m2=sal[2] # m3=sal[3] # m4=sal[4] # print(m0) # print(m1) # print(m2) # print(m3) # 更简单的做法,一行搞定 对应的变量名少一个不行,多一个不行 sal= [11,22,33,44,55] m0,m1,m2,m3,m4,=sal print(m0) print(m1) print(m2) print(m3) # 可以使用 *_ 来匹配所需要的值 下划线作为一个占位符 sal= [11,22,33,44,55] x,y,z,*_=sal # 取前三个值 print(x,y,z) *_,x,y,z=sal # 取后三个值 print(x,y,z) x,y,*_,z # 取第一个值和第二个值,与最后一个值 print(x,y,z) # 解压字典,默认解压出来的是字典的key x,y,z=dict = {'a':1,'b':2,'c':3} print(x,y,z) 字符串、字典、元组、集合类型都支持解压赋值
4.逻辑运算符
会返回布尔值True或False

# 逻辑运算:用来判断 # not :就是把紧跟其后的那个条件结果取反 print(not 10 > 6) print(not '') # and 逻辑与 用来连接左右两个条件 全真为真,有一个条件为假,则结果为False # print(True and 10 > 3) # 偷懒原则:看到一个条件为假就不用继续算下去了,直接结果为假 # or 逻辑或 用来连接左右两个条件 全假为假,如果有一个条件为真,则结果为真 print(10 > 3 or 0) # 也有偷懒原则:看到一个条件为真,直接结果为真 # 优先级 not > and > or # 如果单独是一串and或者or 连接,就按照从左向右的顺序依次运算即可 # 如果是混用,就需要考虑优先级了 # 3 > 4 and not 4 > 3 or 1 ==3 and 'x'=='x' or 3 > 3 res= (3>4 and (not 4 > 3)) or (1==3 and 'x'=='x') or 3 > 3 print(bool(res)) 短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回 短路运算面试题: 1 or 3 1 1 and 3 3 0 and 2 and 1 0 0 and 2 or 1 1 0 and 2 or 1 or 4 1 0 or False and 1 False
5.成员运算符

# 5.成员运算符 # 5.1 in 判断一个子字符串是否存在于一定大字符串 第一种更好 print('happy' in 'happy new year') print(111 in [111,222,333]) # 列表也算 print('k1' in {'k1':111,'k2':222}) # 字典是要用key值 # 5.2 not in 判断一个子字符串是否存在于一定大字符串 逻辑同 in 但语义不明确 print('happy' not in 'happy new year') 虽然两种判断可以达到相同的效果,但我们推荐使用第二种格式,因为not in语义更加明确 # 6.身份运算符 # is 判断的是id是否相等 # 注意:==双等号比较的是value是否相等,而is比较的是id是否相等 #1. id相同,内存地址必定相同,意味着type和value必定相同 #2. value相同type肯定相同,但id可能不同,如下
3.6可变与不可变
# 可变与不可变类型 # 可变类型:值改变的情况下,id不变 证明改的是原值,原值是可以被改变的 # 不可变类型:值改变,id也改变了,证明是产生新的值,压根没有改变原值,原值是不可以被改变的 # int是不可变的类型 # float是不可变类型 # 字符串类型是不可变类型 # int float str 都被设计成了不可分割的整体,不能够被改变 # 列表 是可变类型 改变列表的值,整体是不会改变的,元素值的id会改变的 # l=['1','2','3'] # print(id(l)) # l[0]=['5'] # print(id(l)) # 字典 是可变类型 改变key的值,整体是不会改变的,元素值的id会改变的 dict = {'k1':1,'k2':2} print(id(dict)) dict['k1']=[4] print(id(dict)) # bool 不可变 # 什么可以当做条件? # 1.显示布尔值 # 1.1条件可以是比较运算符 # age = 18 # print(age>18) # 1.2条件可以是布尔值 # is_beautiful=True # 2.隐式布尔值 所有的值都可以当做条件去使用 # 1,'aaa' # 其中 空 0 None 为假 其余类型都为真 # abc= 1 # print(bool(abc))
3.7浅拷贝与深拷贝
# list1=['111','222','333'] # 二者分割不开,list1与list2指向的都是同一个地址 # lis2=list1 # 这个不是拷贝 # 需求: # 1、拷贝一个原列表产生一个新的列表 # 2、想让两个列表完全独立开 # 如何copy列表 # 1.浅拷贝 # 浅拷贝:把原列表第一层内存地址完全copy一份给新列表 # list1 = [ # 'hello', # 'bjt', # [1,2,3] # ] # # list2 = list1.copy() # print(id(list1)) # print(id(list2)) # print(list2) # print(list1) # 2.深copy # 想要copy得到的新列表和原列表的改操作完全独立开,必须要有一种可以区分可变类型与不可变类型的copy机制,这就是深copy # 可变类型,重新开辟一个内存地址,但是内存地址里面所指的值并没有改变,全都指向原来的。不可变类型,还是用原来的地址。 import copy list1 = [ 'hello', 'bjt', [1,2,3] ] list2 = copy.deepcopy(list1) # print(id(list1)) # print(id(list2)) print(id(list1[2])) print(id(list2[2])) # 拷贝:如果l2是l1的拷贝对象,l1内部的任何数据类型的元素变化,那么l2内部的元素也会跟着改变,因为可变类型值变id不变。 l1 = ['a', 'b', 'c', ['d', 'e', 'f']] l2 = l1 l1.append('g') print(l1) # ['a', 'b', 'c', ['d', 'e', 'f'], 'g'] print(l2) # ['a', 'b', 'c', ['d', 'e', 'f'], 'g'] # 浅拷贝:如果l2是l1的浅拷贝对象,l1内的不可变元素发生了改变,l2不变;但是l1内的可变元素发生了改变,l2也会跟着改变。 import copy l1 = ['a', 'b', 'c', ['d', 'e', 'f']] l2 = copy.copy(l1) l1.append('g') print(l1) # ['a', 'b', 'c', ['d', 'e', 'f'], 'g'] print(l2) # ['a', 'b', 'c', ['d', 'e', 'f']] l1[3].append('h') print(l1) # ['a', 'b', 'c', ['d', 'e', 'f', 'h'], 'g'] print(l2) # ['a', 'b', 'c', ['d', 'e', 'f', 'h']] # 深拷贝:如果l2是l1的深拷贝对象,那么l1内的不可变元素发生了改变,l2不变;如果l1内的可变元素发生了改变,l2也不会变,即l2永远不会因为l1变化而变化。 import copy l1 = ['a', 'b', 'c', ['d', 'e', 'f']] l2 = copy.deepcopy(l1) l1.append('g') print(l1) # ['a', 'b', 'c', ['d', 'e', 'f'], 'g'] print(l2) # ['a', 'b', 'c', ['d', 'e', 'f']] l1[3].append('h') print(l1) # ['a', 'b', 'c', ['d', 'e', 'f', 'h'], 'g'] print(l2) # ['a', 'b', 'c', ['d', 'e', 'f']]
流程控制即控制流程,具体指控制程序的执行流程,而程序的执行流程分为三种结构:顺序结构(之前我们写的代码都是顺序结构)、分支结构(用到if判断)、循环结构(用到while与for)
3.8if判断语句
''' 完整语法: if 条件1: # 如果条件1的结果为True,就依次执行:代码1、代码2,...... 代码1 代码2 ...... elif 条件2: # 如果条件2的结果为True,就依次执行:代码3、代码4,...... 代码3 代码4 ...... elif 条件3: # 如果条件3的结果为True,就依次执行:代码5、代码6,...... 代码5 代码6 ...... else: # 其它情况,就依次执行:代码7、代码8,...... 代码7 代码8 ''' ''' 写代码的时候要缩进四个空格 语法1: if 条件: 代码1 代码3 代码3 ''' age = 12 name = 'abab' if age==12 and name == 'abab' : print('hjjjj')age = 12 print('我是其他代码') ''' 语法2: if 条件: 代码1 代码2 代码3 else: 代码1 代码2 代码3 ''' age = 12 name = 'abab' if age==11 and name == 'abab' : print('我们是一样的') else: print('我们不一样') ''' 语法3: if 条件: 代码1 代码2 代码3 elif 条件2: 代码1 代码2 代码3 elif 条件3: 代码1 代码2 代码3 ````` ''' score = input('请输入您的成绩:') score=int(score) if score >= 90: print('优秀') elif score >= 80: print('良好') elif score >= 70: print('普通') elif score >= 60: print('及格') elif score >= 0: print('不及格') score = input('请输入您的成绩:') score=int(score) if score >= 90: print('优秀') elif score >= 80: print('良好') elif score >= 70: print('普通') elif score >= 60: print('及格') else: print('不及格') # if 嵌套 age = 12 name = 'abab' if age==12 and name == 'abab' : print('我们是一样的') is_sus=True if is_sus: print('happy!') else: print('我们不一样') # 注意: # 1、python用相同缩进(4个空格表示一个缩进)来标识一组代码块,同一组代码会自上而下依次运行 # 2、条件可以是任意表达式,但执行结果必须为布尔类型 # 在if判断中所有的数据类型也都会自动转换成布尔类型 # 2.1、None,0,空(空字符串,空列表,空字典等)三种情况下转换成的布尔值为False # 2.2、其余均为True
3.9while循环语句
while循环的语法及基本使用
''' while 条件 代码1 代码2 代码3 运行步骤: 步骤1:如果条件为真,那么依次执行:代码1、代码2、代码3、...... 步骤2:执行完毕后再次判断条件,如果条件为True则再次执行:代码1、代码2、代码3、......,如果条件为False,则循环终止 ''' count = 0 while count < 5: print(count) count+=1 print('hhh') print('最后一行代码')
死循环与效率问题
# 输入输出会有一定的缓存时间,不会导致致命的效率问题 # count = 0 # while count < 5: # print(count) # # while True: # 1 与True都一样,但是1的效率会比True快一些 # name=input('name:') # print(name) # 这个死循环会带来致命的效率问题。纯计算无io的死循环会导致致命的效率问题 # while True: # 1+1
退出循环的两种方式
# 退出循环的两种方式 # 方式一:将条件改为false,等到下次循环判断条件时才会生效 # username = 'bjt' # yourpwd = '123' # tag = True # while tag: # name = input('请输入您的账号:') # pwd = input('请输入您的密码:') # if name == username and pwd == yourpwd: # print('welcom') # tag = False # else: # print('Error') # print('hhhh') # 方式二: 可以加一个break 终止循环 只要运行到break,就会立刻终止本层循环 username = 'bjt' yourpwd = '123' while True: name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name == username and pwd == yourpwd: print('welcom') break else: print('Error')
while循环应用
# 循环的应用 # username = 'bjt' # yourpwd = '123' # name = input('请输入您的账号:') # pwd = input('请输入您的密码:') # if name == username and pwd == yourpwd: # print('welcom') # else: # print('Error') # 优化代码,重复代码不可粘贴赋值来循环使用 username = 'bjt' yourpwd = '123' while True: name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name == username and pwd == yourpwd: print('welcom') else: print('Error')
while循环嵌套
# while循环嵌套 ''' 每一层都必须配一个break while True: while True: while True: break break break ''' username = 'bjt' yourpwd = '123' while True: name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name == username and pwd == yourpwd: print('welcom') while True: cmd = input('输入命名编号:') if cmd == 'q': break print('{x}正在运行中'.format(x='cmd')) break # 后面的代码都不会执行,立刻终止本层循环 else: print('Error') # 改变条件的方式 username = 'bjt' yourpwd = '123' tag = True while tag: name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name == username and pwd == yourpwd: print('welcom') while tag: cmd = input('输入命名编号:') if cmd == 'q': tag = False else: print('{x}正在运行中'.format(x=cmd)) else: print('Error')
while与continue的使用
# while 与 continue的使用 结束本次循环,直接进入下一次循环 # 强调:在continue之后加同一行代码无意义,永远无法执行 count = 0 while count < 6: if count == 4: count+=1 continue print(count) count+=1
while+else的使用
# while + else # else 包含的代码会在while循环结束后,没有被break打断的情况下,正常结束后才会运行 # count = 0 # while count<6: # if count == 4: # count+=1 # continue # print(count) # count+=1 # else: # print('会在while循环结束后,没有被break打断的情况下,正常结束后才会运行') # else不会运行 # count = 0 # while count<6: # if count == 4: # break # print(count) # count+=1 # else: # print('会在while循环结束后,没有被break打断的情况下,正常结束后才会运行') # else 是专门针对break的 # 案例 输错三次退出程序 username = 'bjt' yourpwd = '123' tag = True count = 0 while tag: # count < 3也可以 if count == 3: print('输入次数超过三次') break name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name == username and pwd == yourpwd: print('输入正确') else: print('账号密码错误') count += 1
3.10 for循环
for循环是Python提供第二种循环机制
理论上for循环能做的事情上,while循环也可以做
for循环取值比while循环更简洁
如何使用for循环
# 如何使用for循环 ''' 基本语法 for 变量名 in 可迭代对象: 代码1 代码2 代码3 ··· 可迭代对象可以是列表,字典,字符串,元组,集合 ''' **案例:** ```Python # 案例 列表循环取值 # l=['aa','22','333'] # for x in l: # print(x) # l=['aa','22','333'] # i=0 # while i < 3: # print(l[i]) # i+=1 # 字典循环取值 # dict = {'k1':11,'k2':22,'k3':33} # for x in dict: # print(x,dict[x]) # 字符串取值 空格也算 msg = 'have a good time' for x in msg: print(x)
总结for循环与while循环
# 总结 for 循环 与 while 循环 # 相同之处:都是循环,for循环能做的事,while循环也能做 # 不同之处:while循环称之为条件循环,循环次数取决于条件什么时候变为假 # for循环称之为取值循环,循环次数取决于in后面包含的值的个数
for循环:range()控制循环次数
# for循环控制循环次数:range() # 有局限性 # for x in '1 2': # print('循环我')# 会循环3次,空格也算 # range()功能介绍 ''' 顾头不顾尾 range(10) [0,1,2,3,4,5,6,7,8,9] range(1,9) [1,2,3,4,5,6,7,8] range(1,9,1) [1,2,3,4,5,6,7,8] range(1,9,2) [1,3,5,7] ''' # for i in range(3): # print('循环3次') # for i in range(10): # print('循环3次') username = 'bjt' yourpwd = '123' for i in range(3): name = input('请输入您的账号:') pwd = input('请输入您的密码:') if name==username and pwd == yourpwd: print('输入正确') break else: print('密码错误') continue print('错误次数超过三次') # range()补充知识 # 1.可以按照索引取值 for循环可以按照range()索引取值,但是有点麻烦,不推荐 l = ['a','b','c','d'] for k in range(len(l)): print(k,l[k]) # 2.range()在Python3里面得到的是一只会下鸡蛋的老母鸡 for i in range(10): print(i)
for + continue
# for + continue for i in range(6): if i == 4: continue print(i)
for 循环嵌套
# for循环嵌套 外层循环执行一次,内层循环要全部执行玩 for i in range(3): print('外层循环=====') for j in range(5): print('内层循环') # 跳出for循环,只有break。结束本次,进入下一次只有continue
补充print()
# 补充:print() # print()可以传多个值,逗号会表现为空格号 print()打印会自带一个换行符 print('hello\n',end='') print('hi') print('hello',end='') print('hi')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY