ZooKeeper快速入门
“一入Java深似海”,本文将重点介绍分布式相关理论以及Zookeeper的基础应用,深入内容之后会持续更新。
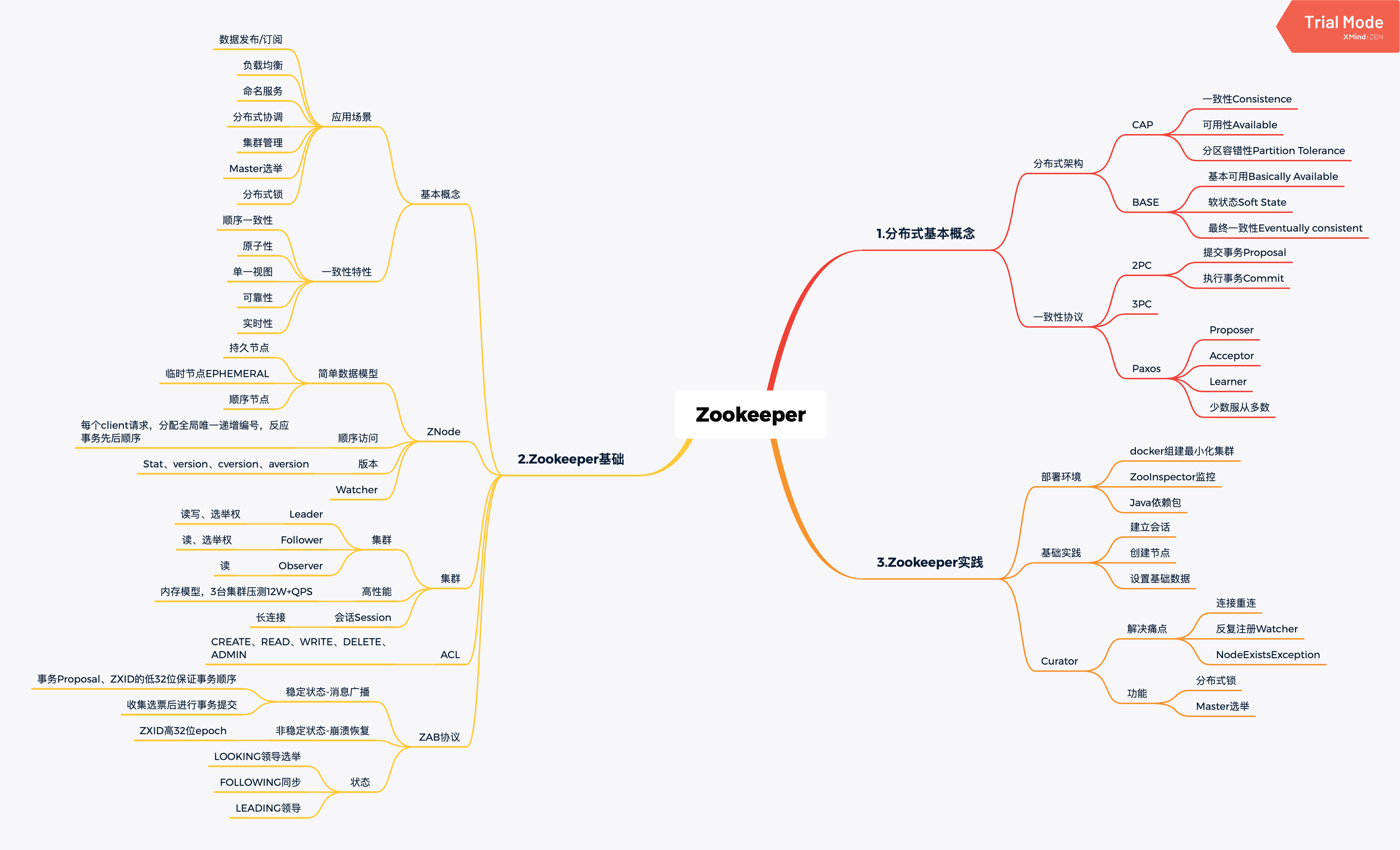
1.分布式基本概念
分布式架构
在集中式的系统环境中,可以简单通过事务(ACID)保证数据的一致性;而在分布式系统环境中,由于存在缺少全局时钟、故障无法避免等痛点,过去的方式不在适用,而适用新的CAP定理和BASE理论。
CAP
- Consistency一致性:指数据在多个副本间是否能保持一致的特性。针对一个数据项的更新,所有用户都可以读取到最新的值,则系统被认为是强一致的。
- Availablity可用性:指系统一直处于可用状态,对于每一个请求都能在单位时间内返回结果。
- Partition tolerance分区容错性:分布式系统在遇到任何网络故障时,仍然可以对外提供满足一致性和可用性的服务,除非整个网络都出现故障。
该原理指出,一个分布式系统无法同时满足这三个基本需求,因此需要作出合理的选择。由于P是分布式系统的基础,那么核心就是平衡A和C,最常见的就是BASE理论。
BASE
其核心思想是即使无法做到强一致性,但每个应用都可以根据自身业务特点,选择合适的手段达到最终一致性
- Basically Available基本可用:指分布式系统出现不可知故障时,允许损失部分可用性,比如响应时间上的损失、功能上的损失(服务降级)
- Soft state软状态:允许系统中数据存在中间状态,即允许不同节点的数据副本之间进行数据同步时存在延时
- Eventually consistent最终一致性:需要保证最终数据保持一致,而不需要实时保证系统的强一致性。在实践中,最终一致性存在5中变种,因果一致性,读自己之所写,会话一致性,单调读一致性和单调写一致性。比如关系型数据库,常通过同步或一部的方式实现主备数据复制,其实主备之间就存在数据不一致,但其通过多次重试或认为数据修订等方式保证了数据最终一致性,算是一个经典案例
一致性协议
提到一致性协议,最基础的就是2PC(Two-Phase Commit protocol)两阶段提交协议,绝大多数的关系型数据库都是采用的2PC来完成分布式事务处理的。
2PC
- 流程:提交事务阶段,包括事务询问、执行事务、各参与者向协调者反馈事务询问的响应等步骤;执行事务阶段,包含两种情况,成功时执行事务提交,包括发送提交请求、事务提交、反馈事务提交结果、完成事务等步骤,而失败时会中断事务,包括发送回滚请求、事务回滚、反馈事务回滚结果、中断事务等步骤。其优点是原理简单、实现方便,但存在同步阻塞、单点问题、脑裂等痛点。

3PC
其实就是2PC的改进版,将提交事务请求阶段分成了CanCommit,PreCommit阶段,最后的DoCommit没有变化。
Paxos
是Lamport与1990提出的基于消息传递且有高度容错特性的一致性算法,其成功的解决了“拜占庭将军”问题(这个问题在区块链中也涉及)。其包括三种参与角色,分别是Proposer、Acceptor和Learner,这儿不展开介绍其基于数据归纳法的证明(个人也没打算深入研究),但一个重点的观念就是,2PC是基于所有参与者都同意的情况,而Paxos是基于多数参与者同意的情况>50%,google的chubby就是基于该算法的实现。
2.Zookeeper基础
基本概念
Zookeeper由Hadoop的子项目发展而来,之前的文章介绍过Hadoop,不过到目前为止,该部分的实践依然几乎为0,不过相信理解了Zookeeper后,一定能更好的深入实践Hadoop。其为分布式应用提供了高效可靠的分布式协调服务,分布式应用程序可以基于它实现如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。其在一致性方面具有顺序一致性、原子性、单一视图(每个client看到的数据一致)、可靠性、实时性的特点。
设计目标与特点
ZNode
- 简单的数据模型:其通过一个共享的、树形结构的名字空间来相互协调,其数据模型由多个ZNode节点组成,类似文件系统,且存储在内存中。比如
/dubbo/com.bjork.PayService/providers就是一个数据节点ZNode,其分为持久节点和临时节点SEQUENTIAL两种,大部分框架都使用的临时节点。 - 顺序访问:对于每一个客户端请求,都分配一个全局唯一递增编号,这个编号反应了所有事务的先后顺序,用于同步原语。
- 版本:每个ZNode除了保存数据还维护一个Stat数据结构,其中version表示节点版本,cversion表示子节点版本,aversion表示ACL版本。
- Watcher:允许用户在指定节点上注册一些Watcher(Observer模式),当特定事件触发时,会将事件通知到订阅了的客户端。
集群
- 集群:集群中每台机器都会在内存中维护当前服务器状态并相互通信,只要集群中存在超过一半机器可用(基础3台)即可正常提供服务。集群没有沿用Master/Slave概念,而是引入Leader、Follower和Observer三种角色,Leader由所有机器选出并对外提供读写服务,而Follower和Observer都能提供读,区别在于Observer没有选举权。
- 高性能:由于数据模型存储在内存,因此非常适用于大量请求,3台集群压测可达12W+QPS。
- 会话Session:客户端连接是一个C端和S端的TCP长链接,除了保持心跳检测,还用于接收服务器的Watch事件,如果因为网络原因连接断开,只要在sessionTimeout时间内重连到任意服务器,会话仍然有效。
ACL
类似Unit的权限控制,包括CREATE, READ, WRITE, DELETE, ADMIN等权限。
ZAB协议(ZooKeeper Atomic Broadcast)
这部分原理比较复杂,简单来说,所有的参数者只会处于消息广播或崩溃恢复两种状态中的一种。前者为稳定状态,使用类似2PC的协议交互,Leader会生成事务Proposal及其ZXID,然后发送到其他服务器并收集选票后进行事务提交,后者为非稳定状态,即还未选出Leader或Leader出问题是,基于ZXID中的高32位epoch进行选举的阶段(低32位用于表示事务顺序),此外非Leader进入集群时首先会同步Leader的状态。 因此,ZAB中的每一个进程只会处于LOOKING领导选举阶段、FOLLOWING跟随者和领导者保持同步状态、LEADING领导者作为主领导者等3种状态中的一种。
3.Zookeeper实践
部署环境
使用Docker部署3台组成集群,涉及配置文件zoo.cfg和myid(安装运行后,通过bash命令在myid文件中设置1,2,3即可)
zoo.cfg配置文件如下所示,在默认的基础上需要添加最后3行
clientPort=2181
dataDir=/data
dataLogDir=/datalog
tickTime=2000
initLimit=5
syncLimit=2
//3088用于Zookeeper选举, 2088用于Leader和Follower或Observer交换数据
server.1=127.0.xx.1:2088:3088
server.2=127.0.xx.1:2089:3089
server.3=127.0.xx.1:2090:3090
docker安装并部署,在aliyun上需要开放9个端口号
docker pull zookeeper:3.4.10
docker run --name zookeeper01 -p 2181:2181 -p 2888:2888 -p 3888:3888 -v $PWD/zookeeper01/data:/data -v $PWD/zookeeper01/datalog:/datalog -d zookeeper:3.4.10
docker run --name zookeeper02 -p 2182:2181 -p 2889:2888 -p 3889:3888 -v $PWD/zookeeper02/data:/data -v $PWD/zookeeper02/datalog:/datalog -d zookeeper:3.4.10
docker run --name zookeeper03 -p 2183:2181 -p 2890:2888 -p 3890:3888 -v $PWD/zookeeper03/data:/data -v $PWD/zookeeper02/datalog:/datalog -d zookeeper:3.4.10
//通过bash命令
docker exec -ti zookeeper01 /bin/bash
docker exec -ti zookeeper02 /bin/bash
docker exec -ti zookeeper03 /bin/bash
为了便于管理zk,目前主要使用最基础的windows工具,ZooInspector实验够用了,此外还有TaoKeeper,Zkui等组件。
Java客户端maven(也包含之后要介绍的Curator及其扩展):
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.4.2</version>
</dependency>
基础示例:建立会话,创建节点,设置基础数据
public class SessionNew implements Watcher {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private static ZooKeeper zookeeper = null;
private static Stat stat = new Stat();
public static void main(String[] args) throws IOException {
try {
// 1.创建会话
zookeeper = new ZooKeeper("xx.xx.xx.xx:2181", 5000, new SessionNew());
System.out.println(zookeeper.getState());
connectedSemaphore.await();
// 2.创建节点
String path1 = zookeeper.create("/zk-test-ephemeral-", "123".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
System.out.println(path1);
String path2 = zookeeper.create("/zk-test-ephemeral-", "".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(path2);
/* String path1sub1 = zookeeper.create(path1+"/sub1", "".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
String path1sub2 = zookeeper.create(path1+"/sub2", "".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
List<String> childList = zookeeper.getChildren(path1, true);
System.out.println(childList);*/
System.out.println(new String(zookeeper.getData(path1, true, stat)));
zookeeper.setData(path1, "testData01".getBytes(), -1);
// zookeeper.getData(path, watch, stat);
} catch (Exception e) {
System.out.println("连接已经建立");
e.printStackTrace();
}
}
@Override
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event);
if (KeeperState.SyncConnected == event.getState()) {
if (EventType.None == event.getType() && null == event.getPath()) {
connectedSemaphore.countDown();
} else if (EventType.NodeDataChanged == event.getType()) {
try {
System.out.println(new String(zookeeper.getData(event.getPath(), true, stat)));
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
Curator
是Netflix公司开源的一套Zookeeoper客户端框架,解决了连接重连、反复注册Watcher和NodeExistsException等痛点。最重要的是,其提供了共享锁服务、Master选举和分布式计数器等常见模式的实现,棒棒哒。
public static void main(String[] args) throws Exception {
// 1.创建会话
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// CuratorFramework client = CuratorFrameworkFactory.newClient(url01,
// 5000, 3000, retryPolicy);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString(url01).sessionTimeoutMs(5000)
.namespace("firstDemo").retryPolicy(retryPolicy).build();
client.start();
// 2.创建节点并设置初始值
String path = "/zk-book/c1";
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path, "init".getBytes());
// 3.读取数据
Stat stat = new Stat();
byte[] data = client.getData().storingStatIn(stat).forPath(path);
System.out.println(String.format("第一次的版本: %s", stat.getVersion()));
System.out.println(new String(data, "UTF-8"));
// 4.更新数据
client.setData().withVersion(stat.getVersion()).forPath(path, "second".getBytes());
// data = client.getData().storingStatIn(stat).forPath(path);
data = client.getData().forPath(path);
System.out.println(String.format("第2次的版本: %s", stat.getVersion()));
System.out.println(new String(data, "UTF-8"));
try {
client.setData().withVersion(stat.getVersion()).forPath(path, "third".getBytes());
} catch (Exception ex) {
System.out.println("更新失败,乐观锁!");
}
// 5.删除数据
client.delete().deletingChildrenIfNeeded().withVersion(stat.getVersion()).forPath(path);
Thread.sleep(Integer.MAX_VALUE);
}

应用场景:包括事件监听、Master选举、分布式锁、分布式计数器&Barrier等,这些都可以借助Curator实现。
开源应用:Hadoop, HBase, Kafka, Alibaba(Metamorphosis,Dubbo, Canal, Otter, JStrom),之后持续更新。
Tip:
4层负载均衡和7层负载均衡的区别
这部分其实就是原来大学学习的网络原理,比如可以基于2层的MAC负载均衡、3层的IP负载均衡,也可以通过4层IP+端口(TCP/UDP)负载均衡,还可以通过应用层(第7层)来负载均衡。重点是7层的负载均衡可以更加的智能,比如Zookeeper其就是基于树型数据模型更加灵活的进行负载均衡,而不是像4层基于random或轮训方案进行负载均衡。前者适合微服务架构服务治理这类场景,而后者(nginx)适合通过反向代理均衡Web服务器负载的场景。
详情请见博文:四层和七层负载均衡的区别
参考文献
- 倪超. 从Paxos到Zookeeper[M]. 北京:电子工业出版社, 2015.
出 处:http://www.cnblogs.com/xiong2ge/
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号