
SQLAIchemy
Ⅰ : SQLAIchemy
https://zhuanlan.zhihu.com/p/353399436
1.简介
SQLALchemy是Python中的一款优秀的ORM框架,它可以作用于任何第三方Web框架,如flask,tornado等框架。
SQLALchemy相较于DjangoORM来说更加的贴近原生SQL语句,因此学习难度较低。
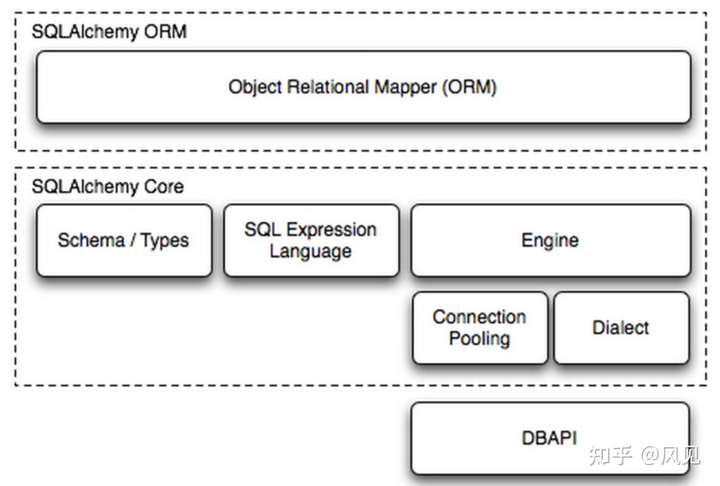
2.组成部分
| 组成部分 | 描述 |
|---|---|
| Engine | 框架引擎 |
| Connection Pooling | 数据库链接池 |
| Dialect | 数据库DB API种类 |
| Schema/Types | 架构&类型 |
| SQL Exprression Language | SQL表达式语言 |
3.下载SQLALchemy模块:
pip install sqlalchemy值得注意的是SQLALchemy必须依赖其他操纵数据的模块,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.htmlⅡ : 基本操作
1.表操作
SQLALchemy中不允许修改表结构,如果修改表结构则需要删除旧表,再创建新表:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import datetime
from sqlalchemy import Column, Integer, String, DateTime, UniqueConstraint, Index
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8",
# "mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8", # 有密码时
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
age = Column(Integer,nullable=False)
phone = Column(String(11))
addr = Column(String(64), nullable=True)
create_time = Column(DateTime, default=datetime.datetime.now) # 一定不要加括号
__table_args__ = (
UniqueConstraint("id", "name"), # 创建联合唯一 可指定name给个别名
Index("phone", "addr", unique=True), # 创建联合唯一索引 可指定name给个别名
)
def __str__(self):
return "object:<id:%s name:%s>" % (self.id, self.name)
def create_tb():
"""
创建表
:return:
"""
Base.metadata.create_all(engine)
def drop_tb():
"""
删除表
:return:
"""
Base.metadata.drop_all(engine)
if __name__ == '__main__':
drop_tb()
create_tb()2.链接库
表创建好之后,开始链接库
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)3.单表 - 新增记录
新增单条记录:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
user_obj = Users(name="user001", phone="15125352333",age=23, addr="China")
session.add(user_obj)
# 提交
session.commit()
# 关闭链接(可使用session.remove())
session.close()4.单表 - 修改记录
修改记录:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 修改名字
session.query(Users).filter_by(id=1).update({"name": "USER001"})
# 修改年龄,使用+号,默认为"fetch",代表只允许int类型使用+号
session.query(Users).filter_by(id=1).update({"age": Users.age + 1},synchronize_session="fetch")
# 修改地址,使用+号,由于是字符类型,所以要修改synchronize_session=False
session.query(Users).filter_by(id=1).update({"addr":Users.addr + "BeiJing"},synchronize_session=False)
# 提交
session.commit()
# 关闭链接
session.close()5.单表 - 删除记录
删除案例:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
session.query(Users).filter_by(id=2).delete()
# 提交
session.commit()
# 关闭链接
session.close()6.单表 - 批量增加
批量增加:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 批量增加
session.add_all([
Users(name="user002",age=21,phone="13269867233",addr="ShangHai"),
Users(name="user003",age=18,phone="13269867234",addr="GuangZhou"),
Users(name="user003",age=24,phone="13269867235",addr="ChongQing"),
])
# 提交
session.commit()
# 关闭链接
session.close()7.单表查询 - 基本查询
基本查询:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 查询
# -- 查所有 --
result_01 = session.query(Users).all()
# -- 过滤 --
result_02 = session.query(Users).filter(Users.name == "USER001").all() # Python表达式的形式过滤
result_03 = session.query(Users).filter_by(name="user002").all() # ORM形式过滤
result_04 = session.query(Users).filter_by(name="user003").first() # ORM形式过滤 取第一个
print(result_01) # [<models.Users>,<models.Users>,<models.Users>]
print(result_02)
print(result_03)
print(result_04) # object:<id:3 name:user003> 通过__str__拿到结果
# 提交
session.commit()
# 关闭链接
session.close()8.其他过滤
条件查询:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 只拿某字段
result_00 = session.query(Users.name,Users.age).first()
print(result_00)
# and(用逗号或者用and_)
result_01 = session.query(Users).filter( Users.id > 1,Users.age < 23).all()
print(result_01)
from sqlalchemy import and_
result_02 = session.query(Users).filter(and_( Users.id > 1,Users.age < 23)).all()
print(result_02)
# or
from sqlalchemy import or_
result_03 = session.query(Users).filter(or_(Users.id > 3,Users.age < 23)).all()
print(result_03)
# and与or的组合使用
result_04 = session.query(Users).filter(or_(
Users.id > 1,
and_(Users.id > 2, Users.age < 24)
)).all()
print(result_04)
# 范围
result_05 = session.query(Users).filter(Users.age.between(18,24)).all()
print(result_05)
# 包含
result_06 = session.query(Users).filter(Users.age.in_([18,21,24])).all()
print(result_06)
# 取反 ~
result_07 = session.query(Users).filter(~Users.age.in_([18,21,24])).all()
print(result_07)
# 通配符
result_08 = session.query(Users).filter(Users.name.like("us%")).all()
print(result_08)
# 分页
result_09 = session.query(Users).all()[0:1]
print(result_09)
# 排序
result_10 = session.query(Users).order_by(Users.id.desc()).all() # 倒序
print(result_10)
result_11 = session.query(Users).order_by(Users.id.asc()).all() # 正序
print(result_11)
# 分组
result_12 = session.query(Users).group_by(Users.id).all()
print(result_12)
# 聚合函数
from sqlalchemy.sql import func
result_13 = session.query(
func.max(Users.age),
func.sum(Users.age),
func.min(Users.age),
).group_by(Users.name).having(func.max(Users.age > 12)).all()
print(result_13)
# 提交
session.commit()
# 关闭链接
session.close()9.多表相关 - 一对多
首先是建立一对多的关系,使用relationship做逻辑一对多,不会在物理表中创建关系,但是可以通过该字段进行增删改查:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8",
# "mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8", # 有密码时
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
class Classes(Base):
__tablename__ = "classes"
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
class Students(Base):
__tablename__ = "students"
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 真实约束字段:避免脏数据写入,在物理表中会创建真实字段关系
# 可选级联操作:CASCADE,DELETE、RESTRICT
fk_class = Column(Integer, ForeignKey("classes.id",ondelete="CASCADE",onupdate="CASCADE"))
# 逻辑关系字段:不会在真实物理表中创建字段,但是可以通过该逻辑字段进行增删改查
# backref:反向查询的名字
re_class = relationship("Classes",backref="students")
def create_tb():
"""
创建表
:return:
"""
Base.metadata.create_all(engine)
def drop_tb():
"""
删除表
:return:
"""
Base.metadata.drop_all(engine)
if __name__ == '__main__':
drop_tb()
create_tb()通过逻辑字段进行增加:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
session.add_all(
[
Students(name="学生01", re_class=Classes(name="一年级一班")), # 自动填入fk_class
Students(name="学生02", re_class=Classes(name="一年级二班")),
]
)
# 提交
session.commit()
# 关闭链接
session.close()10.多对多
多对多也使用relationship做逻辑多对多,不会在物理表中创建关系,但是可以通过该字段进行增删改查。
使用relationship时,传入指定手动生成的第三张表,代表这是多对多关系:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8",
# "mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8", # 有密码时
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
class Classes(Base):
__tablename__ = "classes"
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
class Students(Base):
__tablename__ = "students"
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 可选级联操作:CASCADE,DELETE、RESTRICT
fk_class = Column(Integer, ForeignKey("classes.id", ondelete="CASCADE", onupdate="CASCADE"))
# 逻辑关系字段:不会在真实物理表中创建字段,但是可以通过该逻辑字段进行增删改查
# backref:反向查询的名字
re_class = relationship("Classes", backref="students")
class Teachers(Base):
__tablename__ = "teachers"
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
# 逻辑字段M2M:指定第三张表,secondary参数为__tablename__,反向查询为teachers
re_class = relationship("Classes", secondary="teachersm2mclasses", backref="teachers")
class TeachersM2mClasses(Base):
__tablename__ = "teachersm2mclasses"
id = Column(Integer, primary_key=True)
teacher_id = Column(Integer, ForeignKey("teachers.id"))
class_id = Column(Integer, ForeignKey("classes.id"))
__table_args__ = (
UniqueConstraint("teacher_id", "class_id"), # 创建联合唯一 可指定name给个别名
)
def create_tb():
"""
创建表
:return:
"""
Base.metadata.create_all(engine)
def drop_tb():
"""
删除表
:return:
"""
Base.metadata.drop_all(engine)
if __name__ == '__main__':
drop_tb()
create_tb()用一个列表,将班级的记录对象放进去,你可以用多种增加方式,使用逻辑字段添加或自己操纵第三张表:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
session.add_all(
[
Teachers(name="老师01",re_class=[
session.query(Classes).filter_by(id=1).first()
]),
Teachers(name="老师02",re_class=[
session.query(Classes).filter_by(id=1).first()
]),
Teachers(name="老师03",re_class=[
session.query(Classes).filter_by(id=2).first()
]),
]
)
# 提交
session.commit()
# 关闭链接
session.close()11.组合查询
组合查询将两张表用笛卡尔积的效果显现出来:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 必须用filter,获取全部也是,不可以使用all因为他会返回一个list,list不具备union_all
# 使用filter返回的对象是:<class 'sqlalchemy.orm.query.Query'>
# 并且query中必须单拿某一个字段,如果不指定字段就直接返回对象
s = session.query(Students.name).filter()
t = session.query(Teachers.name).filter()
c = session.query(Classes.name).filter()
ret = s.union_all(t).union_all(c).all() # 用列表显示
print(ret)
# [('学生01',), ('学生02',), ('老师01',), ('老师02',), ('老师03',), ('一年级一班',), ('一年级二班',)]
# 提交
session.commit()
# 关闭链接
session.close()12.连表查询
使用join进行连表查询:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 手动指定条件查询
result = session.query(Students.name, Classes.name).filter(Students.id == Classes.id).all()
for i in result:
print(i)
# 连接查询,同上,内部自动指定 Students.fk_class == Classes.id 的条件
result = session.query(Students.name, Classes.name).join(Classes).all()
# 相当于:result = session.query(Students.name,Classes.name).join(Classes, Students.fk_class == Classes.id).all()
for i in result:
print(i)
# 左链接查询,即使有同学没有班级也拿出来
result = session.query(Students.name, Classes.name).join(Classes, isouter=True).all()
for i in result:
print(i)
# 如果想查看有哪些班级没有同学,就换一个位置
result = session.query(Students.name, Classes.name).join(Students, isouter=True).all()
for i in result:
print(i)
# 三表查询,需要自己指定条件
result = session.query(Teachers.name, Classes.name, TeachersM2mClasses.id) \
.join(Teachers, TeachersM2mClasses.teacher_id == Teachers.id) \
.join(Classes, TeachersM2mClasses.class_id == Classes.id) \
.filter() # 查看原生语句
print(result)
for i in result:
print(i)
# 提交
session.commit()
# 关闭链接
session.close()13.正反向查询
上面是使用join进行的连表查询,其实也可以使用逻辑字段relationship查询
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
# 正向:查看第一个老师都在哪些班级(通过逻辑字段的名字)
result = session.query(Teachers).first()
# result.re_class是一个列表,存了有关该老师所在的班级 <class 'sqlalchemy.orm.collections.InstrumentedList'>
for class_obj in result.re_class: # 查看其所有的班级
print(class_obj.name)
# 反向:查看第一个班级下都有哪些老师,都有哪些学生(通过逻辑字段中的backref参数进行反向查询)
result = session.query(Classes).first()
# 看老师
for teacher_obj in result.teachers:
print(teacher_obj.name)
# 看学生
for student_obj in result.students:
print(student_obj.name)
# 提交
session.commit()
# 关闭链接
session.close()14.正反方法
使用逻辑字段relationship可拥有一些方法执行增删改
由于逻辑字段是一个类似列表的存在,所以列表的方法都能用。比如使用extend方法增加老师的班级:
# 给老师增加班级
result = session.query(Teachers).first()
# extend方法:
result.re_class.extend([
Classes(name="三年级一班",),
Classes(name="三年级二班",),
])使用remove方法删除老师的班级:
# 减少老师所在的班级
result = session.query(Teachers).first()
# 待删除的班级对象,集合查找比较快
delete_class_set = {
session.query(Classes).filter_by(id=7).first(),
session.query(Classes).filter_by(id=8).first(),
}
# 循换老师所在的班级
# remove方法:
for class_obj in result.re_class:
if class_obj in delete_class_set:
result.re_class.remove(class_obj)使用clear清空老师所对应的班级
# 拿出一个老师
result = session.query(Teachers).first()
result.re_class.clear()15.原生SQL - 查看SQL命令
如果一条查询语句是以filter结尾,则返回结果对象的__str__方法中都是SQL语句:
result = session.query(Teachers).filter()
print(result)
# SELECT teachers.id AS teachers_id, teachers.name AS teachers_name
# FROM teachers如果是all结尾,返回的就是一个列表,first结尾也是一个列表:
result = session.query(Teachers).all()
print(result)
# [<models.Teachers object at 0x00000178EB0B5550>, <models.Teachers object at 0x00000178EB0B5518>, <models.Teachers object at 0x00000178EB0B5048>]16.执行SQL语句
执行原生SQL:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
# 导入引擎,模型表等
from models import *
# 通过Session绑定引擎和数据库建立关系
Session = sessionmaker(bind=engine)
# 创建链接池,使用session即可为当前线程拿出一个链接对象。内部采用threading.local进行隔离
session = scoped_session(Session)
cursor = session.execute(r"select * from students where id <= (:num)",params={"num":2})
print(cursor.fetchall())
# 提交
session.commit()
# 关闭链接
session.close()
# flask-sqlalchemy的基本使用 from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() # 管理员信息表 class Admin(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(50), unique=True) password = db.Column(db.String(50)) def __init__(self, username, password): self.username = username self.password = password def __repr__(self): return "<Admin(id='%s',username='%s',password='%s')>" % (self.id, self.username, self.password) # 用户信息表 class User(db.Model): id = db.Column(db.Integer, primary_key=True) # name字段,字符类型,最大的长度是50个字符 username = db.Column(db.String(50), unique=True) password = db.Column(db.String(50)) def __init__(self, username, password): self.username = username self.password = password # 让打印出来的数据更好看,可选的 def __repr__(self): return "<User(id='%s',username='%s',password='%s')>" % (self.id, self.username, self.password) # 柱状图数据表 class DataBar(db.Model): id = db.Column(db.Integer, primary_key=True) label = db.Column(db.Integer) data = db.Column(db.Integer) def __init__(self, label, data): self.label = label self.data = data def __repr__(self): return "<DataBar(id='%s',label='%s',data='%s')>" % (self.id, self.label, self.data) # 线状图数据表 class DataLine(db.Model): id = db.Column(db.Integer, primary_key=True) label = db.Column(db.Integer) data = db.Column(db.Integer) def __init__(self, label, data): self.label = label self.data = data def __repr__(self): return "<DataLine(id='%s',label='%s',data='%s')>" % (self.id, self.label, self.data) # 单位名称映射表 class Unit(db.Model): id = db.Column(db.Integer, primary_key=True) unitname = db.Column(db.String(50)) contents = db.relationship('Content', back_populates='unit') def __init__(self, unitname): self.unitname = unitname def __repr__(self): return "<Unit(id='%s',unitname='%s')>" % (self.id, self.unitname) # 问题一级分类映射表 class Category1(db.Model): id = db.Column(db.Integer, primary_key=True) category = db.Column(db.String(50)) contents = db.relationship('Content', back_populates='category1') category2s = db.relationship('Category2', back_populates='category1') def __init__(self, category): self.category = category def __repr__(self): return "<Unit(id='%s',category='%s')>" % (self.id, self.category) # 问题二级分类映射表,细化分类 class Category2(db.Model): id = db.Column(db.Integer, primary_key=True) category = db.Column(db.String(50)) c1id = db.Column(db.Integer, db.ForeignKey('category1.id')) contents = db.relationship('Content', back_populates='category2') category1 = db.relationship('Category1', back_populates='category2s') def __init__(self, category, c1id): self.category = category self.c1id = c1id def __repr__(self): return "<Unit(id='%s',category='%s',c1id='%s)>" % (self.id, self.category, self.c1id) # 情况登记表,问题,问题类型编号,单位编号,发生时间 class Content(db.Model): id = db.Column(db.Integer, primary_key=True, autoincrement=True) problem = db.Column(db.Text) c1id = db.Column(db.Integer, db.ForeignKey('category1.id')) c2id = db.Column(db.Integer, db.ForeignKey('category2.id')) uid = db.Column(db.Integer, db.ForeignKey('unit.id')) date = db.Column(db.Date) modificationstate = db.Column(db.Boolean) modificationdate = db.Column(db.Date) category1 = db.relationship('Category1', back_populates='contents') category2 = db.relationship('Category2', back_populates='contents') unit = db.relationship('Unit', back_populates='contents') def __init__(self, problem, c1id, c2id, uid, date, modificationstate, modificationdate): self.problem = problem self.c1id = c1id self.c2id = c2id self.uid = uid self.date = date self.modificationstate = modificationstate self.modificationdate = modificationdate def __repr__(self): return "<Content(id='%s',problem='%s',c1id='%s',c2id='%s',uid='%s',date='%s'),modificationstate='%s',modificationdate='%s'>" \ % (self.id, self.problem, self.c1id, self.c2id, self.uid, self.date, self.modificationstate, self.modificationdate) # db.create_all() # admin = Admin('admin', '123456') # user = User('user', '123456') # unit = Unit('单位一') # db.session.add(admin) # db.session.add(user) # db.session.add(unit) # db.session.commit()
# sqlalchemy的基本使用 from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String, Text, Date, ForeignKey from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker, relationship from settings import DB_URI engine = create_engine(DB_URI) # 所有的类都要继承自`declarative_base`这个函数生成的基类 Base = declarative_base(engine) Session = sessionmaker(bind=engine) # 用户信息表 class User(Base): # 定义表名为users __tablename__ = 'users' # 将id设置为主键,并且默认是自增长的 id = Column(Integer, primary_key=True) # name字段,字符类型,最大的长度是50个字符 username = Column(String(50)) password = Column(String(50)) # 让打印出来的数据更好看,可选的 def __repr__(self): return "<User(id='%s',username='%s',password='%s')>" % (self.id, self.username, self.password) # 管理员信息表 class Admin(Base): __tablename__ = 'admin' id = Column(Integer, primary_key=True) username = Column(String(50)) password = Column(String(50)) def __repr__(self): return "<Admin(id='%s',username='%s',password='%s')>" % (self.id, self.username, self.password) # 柱状图数据表 class DataBar(Base): __tablename__ = 'databar' id = Column(Integer, primary_key=True) label = Column(Integer) data = Column(Integer) def __repr__(self): return "<DataBar(id='%s',label='%s',data='%s')>" % (self.id, self.label, self.data) # 线状图数据表 class DataLine(Base): __tablename__ = 'dataline' id = Column(Integer, primary_key=True) label = Column(Integer) data = Column(Integer) def __repr__(self): return "<DataLine(id='%s',label='%s',data='%s')>" % (self.id, self.label, self.data) # 单位名称映射表 class Unit(Base): __tablename__ = 'unit' id = Column(Integer, primary_key=True) unitname = Column(String(50)) contents = relationship('Content', back_populates='unit') def __repr__(self): return "<Unit(id='%s',unitname='%s')>" % (self.id, self.unitname) # 问题分类映射表 class Category(Base): __tablename__ = 'category' id = Column(Integer, primary_key=True) category = Column(String(50)) contents = relationship('Content', back_populates='category') def __repr__(self): return "<Unit(id='%s',unitname='%s')>" % (self.id, self.unitname) # 情况登记表,问题,问题类型编号,单位编号,发生时间 class Content(Base): __tablename__ = 'content' id = Column(Integer, primary_key=True) problem = Column(Text) cid = Column(Integer, ForeignKey('category.id')) uid = Column(Integer, ForeignKey('unit.id')) date = Column(Date) category = relationship('Category', back_populates='contents') unit = relationship('Unit', back_populates='contents') # Base.metadata.create_all() # session = Session() # tmp_user = User(username='user3', password='1234') # print(tmp_user) # session.add(tmp_user) # session.commit()
概要的说:
SQLAlchemy是python社区使用最广泛的ORM之一,SQL-Alchmy直译过来就是SQL炼金术。
Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器、管理数据库操作会话等各类工作,让Flask中的数据处理体验变得更加轻松。
虽然我们要使用的大部分类和函数都由SQLAlchmey提供,但在Flask-SQLAlchemy中,大多数情况下,我们不需要手动从SQLAlchemy导入类或函数。在sqlalchemy和sqlalchemy.orm模块中实现的类和函数
,以及其他几个常用的模块和对象都可以作为db对象的属性调用。当我们创建这样的调用时,Flask-SQLAlchemy会自动把这些调用转发到对应的类、函数或模块
具体区别:
区别1:定义模型:
flask_sqlalchemy需要使用db.Column,而sqlalchemy则不需要
flask_sqlalchemy写法:

1 class Role(db.Model):
2 __tablename__ = 'roles'
3 id = db.Column(db.Integer, primary_key=True)
4 name = db.Column(db.String(64))
5 user = db.relationship('User', backref='role')
6
7 def __repr__(self):
8 return '<Role %r>' % self.name
sqlalcehmy写法:
1 class EnvConfig(Base): 2 __tablename__="env_config" 3 id=Column(Integer,primary_key=True) 4 host = Column(String(50)) # 默认值 1 0:appapi.5i5j.com, 5 def __repr__(self): 6 return "<EnvConfig.%s>"%self.host
区别2:声明字段类型
flask_sqlalchemy使用定义字段类型时无须额外导入类型,一切类型都通过db对象直接调用
1 from flask import Flask 2 from flask_sqlalchemy import SQLAlchemy 3 4 app = Flask(__name__) 5 6 # 设置连接数据库的URL 7 # 不同的数据库采用不同的引擎连接语句: 8 # MySQL: mysql://username:password@hostname/database 9 10 app.config['SQLALCHEMY_DATABASE_URI'] ='mysql+mysqlconnector://root:admin123456@10.1.71.32:3306/test' 11 12 # 设置每次请求结束后会自动提交数据库的改动 13 app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True 14 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True 15 16 # 查询时显示原始SQL语句 17 app.config['SQLALCHEMY_ECHO'] = False 18 db = SQLAlchemy(app)
sqlalchemy需要单独导入字段声明类型:
1 from sqlalchemy.ext.declarative import declarative_base 2 from sqlalchemy import Column,Integer,Text,String,Enum 3 Base =declarative_base()
完整的代码片断:
# 导入依赖
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类
Base = declarative_base()
# 定义User对象
class User(Base):
# 表的名字
__tablename__ = 'user'
# 表的结构
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库链接
engine = create_engine('mysql+mysqlconnector://root:123456@localhost:3306/test')
# 创建DBSession类型
DBSession = sessionmaker(bind=engine)
# 添加
# 创建Session对象
session = DBSession()
# 创建User对象
new_user = User(id='5', name='Bob')
# 添加到session
session.add(new_user)
# 提交
session.commit()
# 关闭session
session.close()
# 查询
# 创建session
session = DBSession()
# 利用session创建查询,query(对象类).filter(条件).one()/all()
user = session.query(User).filter(User.id=='5').one()
print('type:{0}'.format(type(user)))
print('name:{0}'.format(user.name))
# 关闭session
session.close()
# 更新
session = DBSession()
user_result = session.query(User).filter_by(id='1').first()
user_result.name = "jack"
session.commit()
session.close()
# 删除
session = DBSession()
user_willdel = session.query(User).filter_by(id='5').first()
session.delete(user4._willdel)
session.commit()
session.close()
区别3:
查询方式不一样
sqlalchemy通过session.query(模型名)查询
而flask_sqlalchemy则是通过 模型名.query查询
#SQLAlchemy
result_id = session.query(ScriptRunResult).order_by(ScriptRunResult.id.desc()).all()[0].id
result_id =
#Flask-SQLAlchemy
ScriptRunResult.query.order_by(ScriptRunResult.id.desc()).all()[0].id

 浙公网安备 33010602011771号
浙公网安备 33010602011771号