
从0到1,Python异步编程的演进之路
转自 https://zhuanlan.zhihu.com/p/25228075
本文将通过一些例子来讲述作为Python开发者有哪些常用的方式来实现异步编程,以及分享个人对异步编程的理解,如有错误,欢迎指正。
先从一个例子说起。
小梁是一个忠实的电影好爱者,有一天,小梁看到豆瓣这个网站,发现了很多自己喜欢的内容,恰好小梁是个程序猿,于是心血来潮的他决定写个程序,把豆瓣Top250的电影列表给爬下来。小梁平时是个Python发烧友,做起这些事情来自然是得心应手,于是他欣喜地撸起袖子就是干!果不其然,不到十分钟,小梁就写好了第一个程序。
#-*- coding:utf-8 -*-
import urllib.request
import ssl
from lxml import etree
url = 'https://movie.douban.com/top250'
context = ssl.SSLContext(ssl.PROTOCOL_TLSv1_1)
def fetch_page(url):
response = urllib.request.urlopen(url, context=context)
return response
def parse(url):
response = fetch_page(url)
page = response.read()
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
for url in fetch_list:
response = fetch_page(url)
page = response.read()
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
print(i, title)
def main():
parse(url)
if __name__ == '__main__':
main()
程序也不出意外地正常运行。

但是,这个程序让人感觉比较慢,有多慢呢?小梁在主函数中加了下面一段代码。
def main():
from time import time
start = time()
for i in range(5):
parse(url)
end = time()
print ('Cost {} seconds'.format((end - start) / 5))
发现总共耗时7.6秒!!
python movie.py
Cost 7.619797945022583 seconds
小梁不禁陷入了沉思...
 小梁突然想起了两天前小张同学给他安利的一个库,叫requests,比那urllib,urllib2,urllib3,urllibn...不知高到哪里去了!小梁兴致勃勃地修改程序,用requests代替了标准库urllib。
小梁突然想起了两天前小张同学给他安利的一个库,叫requests,比那urllib,urllib2,urllib3,urllibn...不知高到哪里去了!小梁兴致勃勃地修改程序,用requests代替了标准库urllib。
import requests
from lxml import etree
from time import time
url = 'https://movie.douban.com/top250'
def fetch_page(url):
response = requests.get(url)
return response
def parse(url):
response = fetch_page(url)
page = response.content
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
for url in fetch_list:
response = fetch_page(url)
page = response.content
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
# print(i, title)
结果一测,6.5秒!虽然比用urllib快了1秒多,但是总体来说,他们基本还是处于同一水平线的,程序并没有快很多,这一点的差距或许是requests对请求做了优化导致的。
python movie_requests.py
Cost 6.540304231643677 seconds
小梁不禁暗想:是我的程序写的太挫了吗?会不会是lxml这个库解析的速度太慢了,用正则表达式会不会好一些?
于是小梁把lxml库换成了标准的re库。
#-*- coding:utf-8 -*-
import requests
from time import time
import re
url = 'https://movie.douban.com/top250'
def fetch_page(url):
response = requests.get(url)
return response
def parse(url):
response = fetch_page(url)
page = response.content
fetch_list = set()
result = []
for title in re.findall(rb'<a href=.*\s.*<span class="title">(.*)</span>', page):
result.append(title)
for postfix in re.findall(rb'<a href="(\?start=.*?)"', page):
fetch_list.add(url + postfix.decode())
for url in fetch_list:
response = fetch_page(url)
page = response.content
for title in re.findall(rb'<a href=.*\s.*<span class="title">(.*)</span>', page):
result.append(title)
for i, title in enumerate(result, 1):
title = title.decode()
# print(i, title)
再一跑,咦,又足足提升了将近一秒!
python movie_regex.py
Cost 5.578997182846069 seconds
小梁心里暗爽,程序变得更短了,运行得也更快了,感觉离成功越来越近了,但小梁眉头一皱,很快地意识到了一个问题,这样写出来的程序虽然看起来更短了,但所做的都是在盲目地求快,但完全没有扩展性可言!虽然这样做可以满足普通的需求场景,但当程序逻辑变复杂时,依赖原生正则表达式的程序会更加难以维护!借助一些专门做这些事情的解析库,才能使程序变得清晰。其次,这种网络应用通常瓶颈都在IO层面,解决等待读写的问题比提高文本解析速度来的更有性价比!小梁想起了昨天上操作系统课时老师讲的多进程和多线程概念,正好用他们来解决实际问题。

#-*- coding:utf-8 -*-
import requests
from lxml import etree
from time import time
from threading import Thread
url = 'https://movie.douban.com/top250'
def fetch_page(url):
response = requests.get(url)
return response
def parse(url):
response = fetch_page(url)
page = response.content
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
def fetch_content(url):
response = fetch_page(url)
page = response.content
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
threads = []
for url in fetch_list:
t = Thread(target=fetch_content, args=[url])
t.start()
threads.append(t)
for t in threads:
t.join()
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
# print(i, title)
效果果然立竿见影!多线程有效的解决了阻塞等待的问题,这个程序足足比之前的程序快了80%!只需要1.4秒就可完成电影列表的抓取。
python movie_multithread.py
Cost 1.451986598968506 seconds
但小梁还是觉得不够过瘾,既然Python的多线程也受制于GIL,为什么我不用多进程呢?于是话不多说又撸出了一个基于多进程的版本。用4个进程的进程池来并行处理网络数据。
#-*- coding:utf-8 -*-
import requests
from lxml import etree
from time import time
from concurrent.futures import ProcessPoolExecutor
url = 'https://movie.douban.com/top250'
def fetch_page(url):
response = requests.get(url)
return response
def fetch_content(url):
response = fetch_page(url)
page = response.content
return page
def parse(url):
page = fetch_content(url)
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
with ProcessPoolExecutor(max_workers=4) as executor:
for page in executor.map(fetch_content, fetch_list):
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
# print(i, title)
结果是2秒,甚至还不如多线程的版本。
python movie_multiprocess.py
Cost 2.029435634613037 seconds
小梁立马就傻眼了,这跟他的预期完全不符合啊。

多进程带来的优点(cpu处理)并没有得到体现,反而创建和调度进程带来的开销要远超出它的正面效应,拖了一把后腿。即便如此,多进程带来的效益相比于之前单进程单线程的模型要好得多。

正当小梁在苦苦思索还有什么方法可以提高性能时,他无意中看到一篇文章,里面提到了协程相比于多进程和多线程的优点(多进程和多线程除了创建的开销大之外还有一个难以根治的缺陷,就是处理进程之间或线程之间的协作问题,因为是依赖多进程和多线程的程序在不加锁的情况下通常是不可控的,而协程则可以完美地解决协作问题,由用户来决定协程之间的调度。),小梁折腾起来也是不甘人后啊,他搜索了一些资料,思考如何用协程来加强自己的程序。
很快,小梁就发现了一个基于协程的网络库,叫做gevent,而且更爽的是,听说用了gevent的猴子补丁后,整个程序就会变成异步的了!

真的有那么神奇吗?小梁迫不及待地要看看这到底是什么黑科技!马上写出了基于gevent的栗子:
#-*- coding:utf-8 -*-
import requests
from lxml import etree
from time import time
import gevent
from gevent import monkey
monkey.patch_all()
url = 'https://movie.douban.com/top250'
def fetch_page(url):
response = requests.get(url)
return response
def fetch_content(url):
response = fetch_page(url)
page = response.content
return page
def parse(url):
page = fetch_content(url)
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
jobs = [gevent.spawn(fetch_content, url) for url in fetch_list]
gevent.joinall(jobs)
[job.value for job in jobs]
for page in [job.value for job in jobs]:
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
# print(i, title)
python movie_gevent.py
Cost 1.2647549629211425 seconds
虽然程序变得很快了,但小梁整个人都是懵逼的啊,gevent的魔术给他带来了一定的困惑,而且他觉得gevent这玩意实在不好学,跟他心目中Pythonic的清晰优雅还是有距离的。Python社区也意识到Python需要一个独立的标准库来支持协程,于是就有了后来的asyncio。
小梁把同步的requests库改成了支持asyncio的aiohttp库,使用3.5的async/await语法(3.5之前用@asyncio.coroutine和yield from代替)写出了协程版本的例子。
#-*- coding:utf-8 -*-
from lxml import etree
from time import time
import asyncio
import aiohttp
url = 'https://movie.douban.com/top250'
async def fetch_content(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def parse(url):
page = await fetch_content(url)
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
pages = html.xpath(xpath_pages)
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get('href'))
tasks = [fetch_content(url) for url in fetch_list]
pages = await asyncio.gather(*tasks)
for page in pages:
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
# print(i, title)
def main():
loop = asyncio.get_event_loop()
start = time()
for i in range(5):
loop.run_until_complete(parse(url))
end = time()
print ('Cost {} seconds'.format((end - start) / 5))
loop.close()
1.7秒,也不错。而且用上了async/await语法使得程序的可读性提高了不少。
python movie_asyncio.py
Cost 1.713043785095215 seconds
经过一番洗礼后,小梁对异步有了更加深刻的认识。异步方式有很多,这里列出了比较常见的几种,在实际使用中,应该根据使用场景来挑选最合适的应用方案,影响程序效率的因素有很多,以上不同的异步方式在不同的场景下也会有不一样的表现,不要抱死在一个大树上,该用同步的地方用同步,该用异步的地方异步,这样才能构建出更加灵活的网络应用。
说到这里你估计也明白了,清晰优雅的协程可以说实现异步的最优方案之一。
协程的机制使得我们可以用同步的方式写出异步运行的代码。
总所周知,Python因为有GIL(全局解释锁)这玩意,不可能有真正的多线程的存在,因此很多情况下都会用multiprocessing实现并发,而且在Python中应用多线程还要注意关键地方的同步,不太方便,用协程代替多线程和多进程是一个很好的选择,因为它吸引人的特性:主动调用/退出,状态保存,避免cpu上下文切换等…
什么是协程?
协程,又称作Coroutine。从字面上来理解,即协同运行的例程,它是比是线程(thread)更细量级的用户态线程,特点是允许用户的主动调用和主动退出,挂起当前的例程然后返回值或去执行其他任务,接着返回原来停下的点继续执行。等下,这是否有点奇怪?我们都知道一般函数都是线性执行的,不可能说执行到一半返回,等会儿又跑到原来的地方继续执行。但一些熟悉python(or其他动态语言)的童鞋都知道这可以做到,答案是用yield语句。其实这里我们要感谢操作系统(OS)为我们做的工作,因为它具有getcontext和swapcontext这些特性,通过系统调用,我们可以把上下文和状态保存起来,切换到其他的上下文,这些特性为coroutine的实现提供了底层的基础。操作系统的Interrupts和Traps机制则为这种实现提供了可能性,因此它看起来可能是下面这样的:

理解生成器(generator)
学过生成器和迭代器的同学应该都知道python有yield这个关键字,yield能把一个函数变成一个generator,与return不同,yield在函数中返回值时会保存函数的状态,使下一次调用函数时会从上一次的状态继续执行,即从yield的下一条语句开始执行,这样做有许多好处,比如我们想要生成一个数列,若该数列的存储空间太大,而我们仅仅需要访问前面几个元素,那么yield就派上用场了,它实现了这种一边循环一边计算的机制,节省了存储空间,提高了运行效率。
这里以斐波那契数列为例:
def fib(max):
n, a, b = 0, 0, 1
while n max:
print b
a, b = b, a + b
n = n + 1
如果使用上述的算法,那么我每一次调用函数时,都要耗费大量时间循环做重复的事情。而如果使用yield的话,它则会生成一个generator,当我需要时,调用它的next方法获得下一个值,改动的方法很简单,直接把print改为yield就OK。
生产者-消费者的协程
#-*- coding:utf-8
def consumer():
status = True
while True:
n = yield status
print("我拿到了{}!".format(n))
if n == 3:
status = False
def producer(consumer):
n = 5
while n > 0:
# yield给主程序返回消费者的状态
yield consumer.send(n)
n -= 1
if __name__ == '__main__':
c = consumer()
c.send(None)
p = producer(c)
for status in p:
if status == False:
print("我只要3,4,5就行啦")
break
print("程序结束")上面这个例子是典型的生产者-消费者问题,我们用协程的方式来实现它。首先从主程序中开始看,第一句c = consumer(),因为consumer函数中存在yield语句,python会把它当成一个generator(生成器,注意:生成器和协程的概念区别很大,千万别混淆了两者),因此在运行这条语句后,python并不会像执行函数一样,而是返回了一个generator object。
再看第二条语句c.send(None),这条语句的作用是将consumer(即变量c,它是一个generator)中的语句推进到第一个yield语句出现的位置,那么在例子中,consumer中的status = True和while True:都已经被执行了,程序停留在n = yield status的位置(注意:此时这条语句还没有被执行),上面说的send(None)语句十分重要,如果漏写这一句,那么程序直接报错,这个send()方法看上去似乎挺神奇,等下再讲它的作用。
下面第三句p = producer(c),这里则像上面一样定义了producer的生成器,注意的是这里我们传入了消费者的生成器,来让producer跟consumer通信。
第四句for status in p:,这条语句会循环地运行producer和获取它yield回来的状态。
好了,进入正题,现在我们要让生产者发送1,2,3,4,5给消费者,消费者接受数字,返回状态给生产者,而我们的消费者只需要3,4,5就行了,当数字等于3时,会返回一个错误的状态。最终我们需要由主程序来监控生产者-消费者的过程状态,调度结束程序。
现在程序流进入了producer里面,我们直接看yield consumer.send(n),生产者调用了消费者的send()方法,把n发送给consumer(即c),在consumer中的n = yield status,n拿到的是消费者发送的数字,同时,consumer用yield的方式把状态(status)返回给消费者,注意:这时producer(即消费者)的consumer.send()调用返回的就是consumer中yield的status!消费者马上将status返回给调度它的主程序,主程序获取状态,判断是否错误,若错误,则终止循环,结束程序。上面看起来有点绕,其实这里面generator.send(n)的作用是:把n发送generator(生成器)中yield的赋值语句中,同时返回generator中yield的变量(结果)。
于是程序便一直运作,直至consumer中获取的n的值变为3!此时consumer把status变为False,最后返回到主程序,主程序中断循环,程序结束。
输出结果:
我拿到了5!
我拿到了4!
我拿到了3!
我只要3,4,5就行啦
程序结束
Coroutine与Generator
有些人会把生成器(generator)和协程(coroutine)的概念混淆,我以前也会这样,不过其实发现,两者的区别还是很大的。
直接上最重要的区别:
-
generator总是生成值,一般是迭代的序列
-
coroutine关注的是消耗值,是数据(data)的消费者
-
coroutine不会与迭代操作关联,而generator会
-
coroutine强调协同控制程序流,generator强调保存状态和产生数据
相似的是,它们都是不用return来实现重复调用的函数/对象,都用到了yield(中断/恢复)的方式来实现。
asyncio
asyncio是python 3.4中新增的模块,它提供了一种机制,使得你可以用协程(coroutines)、IO复用(multiplexing I/O)在单线程环境中编写并发模型。
根据官方说明,asyncio模块主要包括了:
-
具有特定系统实现的事件循环(event loop);
-
数据通讯和协议抽象(类似Twisted中的部分);
-
TCP,UDP,SSL,子进程管道,延迟调用和其他;
-
Future类;
-
yield from的支持;
-
同步的支持;
-
提供向线程池转移作业的接口;
下面来看下asyncio的一个例子:
import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
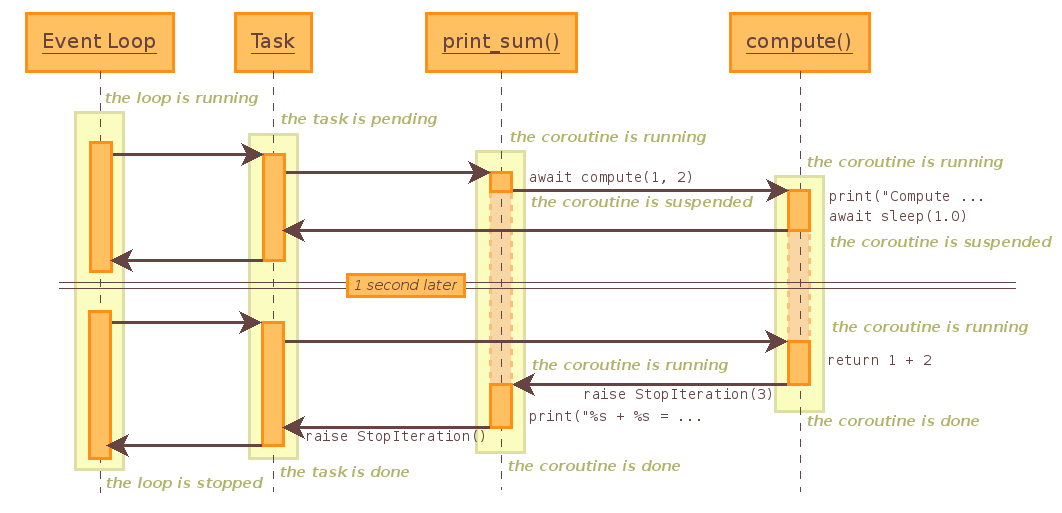
当事件循环开始运行时,它会在Task中寻找coroutine来执行调度,因为事件循环注册了print_sum(),因此print_sum()被调用,执行result = await compute(x, y)这条语句(等同于result = yield from compute(x, y)),因为compute()自身就是一个coroutine,因此print_sum()这个协程就会暂时被挂起,compute()被加入到事件循环中,程序流执行compute()中的print语句,打印”Compute %s + %s …”,然后执行了await asyncio.sleep(1.0),因为asyncio.sleep()也是一个coroutine,接着compute()就会被挂起,等待计时器读秒,在这1秒的过程中,事件循环会在队列中查询可以被调度的coroutine,而因为此前print_sum()与compute()都被挂起了,因此事件循环会停下来等待协程的调度,当计时器读秒结束后,程序流便会返回到compute()中执行return语句,结果会返回到print_sum()中的result中,最后打印result,事件队列中没有可以调度的任务了,此时loop.close()把事件队列关闭,程序结束。
会JS的同学是不是感觉倍感亲切?没错,事件驱动模型就是异步编程的重中之重。
最后再通过一个例子,演示事件驱动模型的运作原理。
首先,我们用同步的方式,抓取baidu的一百个网页。
def sync_way():
for i in range(100):
sock = socket.socket()
sock.connect(('www.baidu.com', 80))
print('connected')
request = 'GET {} HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n'.format('/s?wd={}'.format(i))
sock.send(request.encode('ascii'))
response = b''
chunk = sock.recv(4096)
while chunk:
response += chunk
chunk = sock.recv(4096)
print('done!!')
from time import time
start = time()
sync_way() #Cost 47.757508993148804 seconds
end = time()
print ('Cost {} seconds'.format(end - start))
总共耗时47秒,这对于一个要求性能的爬虫来说是不可接受的,看看我们有没有办法将这个爬虫的性能提高十倍以上,把时间缩短到5秒之内。
首先考虑上面这个程序的瓶颈出在哪个地方,经过思考,很容易看出上面的程序有几个不足之处:
-
socket连接的建立需要等待,一旦握手建立的时间漫长,就会影响下面的流程正常运行。
-
socket接收数据的过程是阻塞式的,等待buffer的过程也是需要一段时间的。
-
socket的建立连接-接收过程都是一个一个来的,在没完成一个连接时不能进行其他连接的处理。
好了,先解决第一个问题:socket的等待。痛点很明显,我们不能一直等待socket的状态发生改变,而是当socket的状态发生改变时,让它告诉我们。要解决这个问题,可以利用io复用,先看看io复用的定义:
IO复用:预先告知内核,使内核一旦发现进程指定的一个或多个IO条件就绪(输入准备被读取,或描述符能承接更多的输出),它就通知进程。
阻塞IO模型看起来是这样的:
recvfrom->无数据报准备好->等待数据->数据报准备好->数据从内核复制到用户空间->复制完成->返回成功指示
而IO复用模型看起来是这样的:
select->无数据报准备好->据报准备好->返回可读条件->recvfrom->数据从内核复制到用户空间->复制完成->返回成功指示
于是我们可以对上面的代码这样修改。
from selectors import DefaultSelector, EVENT_WRITE
selector = DefaultSelector()
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('www.baidu.com', 80))
except BlockingIOError:
pass
def connected():
selector.unregister(sock.fileno())
print('connected!')
selector.register(sock.fileno(), EVENT_WRITE, connected)
把socket设置为非阻塞,把socket的句柄注册到事件轮询中,当socket发生可写事件时,表示socket连接就绪了,这时候再把socket从事件轮询中删除,在socket返回可写事件之前,系统都不是阻塞状态的。同理,对于socket从网络中接收数据,也可以用同样的方法,只需要把要监听的事件改为可读事件就行了。
当然,仅仅这样还是不够的,试想一下,如果有多个socket进行连接,采用上面的非阻塞方式,当一个socket开始等待事件返回时,理论上系统此时应该做的是处理另一个socket的流程,但这里还缺乏了一个必要的机制,当从一个处理socket流程切到另一个处理socket流程时,原来的流程的上下文状态该怎么保存下来以便恢复呢,显然易见这里需要用到上面说到的协程机制,在python中通过yield语法可以把一个函数或方法包装成一个生成器,当生成器执行yield语句时,生成器内部的上下文状态就会被保存,如果想要在未来的操作中把这个生成器恢复,只需要调用生成器的send方法即可从原流程中继续往下走。
有了上面这个概念,我们可以创建一个Future类,它代表了协程中等待的“未来发生的结果”,举例来说,在发起网络请求时,socket会在buffer中返回一些数据,这个获取的动作在异步流程中发生的时间是不确定的,Future就是用来封装这个未来结果的类,但当socket在某个时间段监测到可读事件,读取到数据了,那么他就会把数据写入Future里,并告知Future要执行某些回调动作。
class Future:
def __init__(self):
self.result = None
self._callbacks = []
def add_done_callback(self, fn):
self._callbacks.append(fn)
def set_result(self, result):
self.result = result
for callback in self._callbacks:
callback(self)
有了Future,我们可以包装一个AsyncRequest类,用以发起异步请求的操作。
class AsyncRequest:
def __init__(self, host, url, port, timeout=5):
self.sock = socket.socket()
self.sock.settimeout(timeout)
self.sock.setblocking(False)
self.host = host
self.url = url
self.port = port
self.method = None
def get(self):
self.method = 'GET'
self.request = '{} {} HTTP/1.0\r\nHost: {}\r\n\r\n'.format(self.method, self.url, self.host)
return self
def process(self):
if self.method is None:
self.get()
try:
self.sock.connect((self.host, self.port))
except BlockingIOError:
pass
self.f = Future()
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.on_connected)
yield self.f
selector.unregister(self.sock.fileno())
self.sock.send(self.request.encode('ascii'))
chunk = yield from read_all(self.sock)
return chunk
def on_connected(self, key, mask):
self.f.set_result(None)
在AsyncRequest的process方法里,实例在发起异步连接请求后通过yield一个future阻断了程序流,表示他需要等待未来发生的动作发生(在这里是等待socket可写),这时候系统会去执行其他事件,当未来socket变成可写时,future被写入数据,同时执行回调,从原来停下的地方开始执行,执行读取socket数据的处理。
这里关键的地方就是future在yield之后会在未来某个时候再次被send然后继续往下走,这时候就需要一个用来驱动Future的类。这里称为Task,它需要接受一个协程作为参数,并驱动协程的程序流执行。
class Task(Future):
def __init__(self, coro):
super().__init__()
self.coro = coro
f = Future()
f.set_result(None)
self.step(f)
def step(self, future):
try:
next_future = self.coro.send(future.result)
if next_future is None:
return
except StopIteration as exc:
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
最终,整个程序还需要一个EventLoop类,用来监听到来的事件为socket执行回调以及把协程包装成Task来实现异步驱动。
class EventLoop:
stopped = False
select_timeout = 5
def run_until_complete(self, coros):
tasks = [Task(coro) for coro in coros]
try:
self.run_forever()
except StopError:
pass
def run_forever(self):
while not self.stopped:
events = selector.select(self.select_timeout)
if not events:
raise SelectTimeout('轮询超时')
for event_key, event_mask in events:
callback = event_key.data
callback(event_key, event_mask)
def close(self):
self.stopped = True
OK,那么现在用新的方法再测试一遍,通过python3的yield from语法我们把协程操作代理到AsyncRequest类的process方法中,最终把协程放到EventLoop中执行。
def fetch(url):
request = AsyncRequest('www.baidu.com', url, 80)
data = yield from request.process()
return data
def get_page(url):
page = yield from fetch(url)
return page
def async_way():
ev_loop = get_event_loop()
ev_loop.run_until_complete([
get_page('/s?wd={}'.format(i)) for i in range(100)
])
from time import time
start = time()
async_way() # Cost 3.534296989440918 seconds
end = time()
print ('Cost {} seconds'.format(end - start))
可以看到总共耗时3.5秒,通过把同步改写成基于事件驱动的异步,整个程序的效率提高的十倍以上。
有了上面的基础,可以更进一步改写出一个的任务队列的异步处理形式,把EventLoop的实现隐藏,提供更简单的接口。
from collections import deque
class Queue:
def __init__(self):
self._q = deque()
self.size = 0
def put(self, item):
self.size += 1
self._q.append(item)
def get(self):
item = self._q.popleft()
return item
def task_done(self):
self.size -= 1
if self.size == 0:
self.empty_callback()
class AsyncWorker(Queue):
def __init__(self, coroutine, workers=10, loop_timeout=5):
super().__init__()
self.func = coroutine
self.stopped = False
self.ev_loop = get_event_loop()
self.ev_loop.select_timeout = loop_timeout
self.workers = workers
self.result_callbacks = []
def work(self):
def _work():
while not self.stopped:
item = None
try:
item = self.get()
except IndexError:
yield None
result = yield from self.func(item)
self.task_done()
for callback in self.result_callbacks:
callback(result)
self.tasks = []
for _ in range(self.workers):
self.tasks.append(_work())
self.ev_loop.run_until_complete(self.tasks)
def add_result_callback(self, func):
self.result_callbacks.append(func)
def empty_callback(self):
self.ev_loop.close()
def print_content_length(data):
print(len(data))
async_worker = AsyncWorker(get_page, workers=20)
async_worker.add_result_callback(print_content_length)
for i in range(15):
async_worker.put('/s?wd={}'.format(i))
async_worker.work()
参考文献:
A Web Crawler With asyncio Coroutines
------------
End
我的其他文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号