kaffa简单入门
kafka入门
1.基本概述
- 定义
是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域.
spark数据90%来源于kafka
-
优点
- 异步,解耦
- 削峰
-
概览
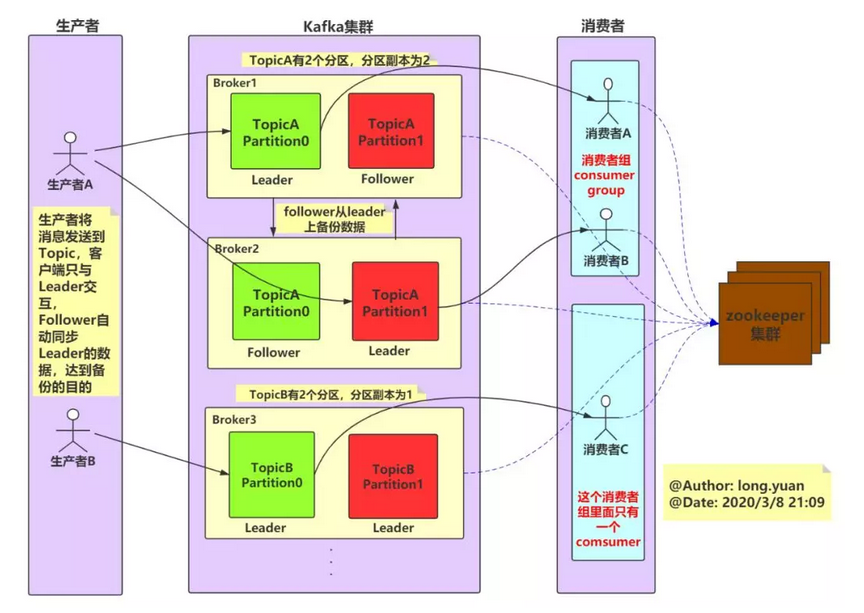
- Broker 就是 安装了kafka服务的机器
- Topic 主题
- Partion 分区
- 分布式,可以存储在不同的机器上,提高Topic的负载,提高并发度
-
zookeeper来调度整个集群,同时生产者与消费者也会存储一些信息在里面
- 数据存在磁盘中,默认存储7天
- kafka里的文件存储位置 名称叫 log(容易跟日志混淆)
2.安装kafka
-
安装虚拟机 VM
虚拟机 VMware Workstation 16激活码:
*****-*****-*****-*****-***** (亲测可以用)
*****-*****-*****-*****-*****
*****-*****-*****-*****-*****
leishen /123456
-
安装CentOS8
-
解决centos没有jps
yum install java-1.8.0-openjdk-devel.x86_64
-daemon 后台进程允许
3.常用命令
#启动zookeeper
cd /home/leishen/soft/kafka_2.13-2.7.0/bin
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
#启动kafka
./kafka-server-start.sh -daemon ../config/server.properties
#创建topic
#--create list delete describe(查看详情)
#replication-factor 副本数量
#partitions 分区数量
#topic topic 名称
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
#查看topic
./kafka-topics.sh --list --zookeeper localhost:2181
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
#启动生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
#启动消费者
--from-beginning 从开头的地方获取数据
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
4.springboot整合kafka
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=192.168.52.128:9092
#spring.kafka.bootstrap-servers=node06.jstdata.com:9092
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
# spring.kafka.consumer.max-poll-records=50
//简单消费者
package com.jst.demo.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumer {
// 消费监听
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
//简单生产者
package com.jst.demo.product;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ProductController {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/helloword")
public String helloWorld(){
return "hello world!";
}
// 发送消息
@GetMapping("/kafka/normal/{message}")
public void sendMessage1(@PathVariable("message") String normalMessage) {
kafkaTemplate.send("test", normalMessage);
System.out.println("send msg:"+normalMessage);
}
}
5.参考资料
高并发:单机可支持数千个客户端同时读写;
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
6.报错
修改server.properties的两行默认配置,即可通过外网连接服务器Kafka,问题解决:
# 允许外部端口连接
listeners=PLAINTEXT://0.0.0.0:9092
# 外部代理地址
advertised.listeners=PLAINTEXT://121.201.64.12:9092


 浙公网安备 33010602011771号
浙公网安备 33010602011771号