人生苦短,我用python-- Day3
集合
集合的特点:去重、关系、无序
创建2个集合#



1 >>> dog_breed = set(['拉布拉多', '德国牧羊犬', '萨马耶', '哈士奇', '藏獒']) 2 >>> dog_breed2 = set(['边境牧羊犬','吉娃娃','德国牧羊犬','秋田犬','蝴蝶犬','博美犬','罗威纳犬']) 3 >>> dog_breed2 4 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'} 5 >>> dog_breed 6 {'哈士奇', '拉布拉多', '萨马耶', '德国牧羊犬', '藏獒'}
测试两个集合的交集#
1 #方法一 2 >>> dog_breed2 3 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'} 4 >>> dog_breed 5 {'哈士奇', '拉布拉多', '萨马耶', '德国牧羊犬', '藏獒'} 6 >>> print(dog_breed & dog_breed2) 7 {'德国牧羊犬'} 8 #方法二 9 >>> print(dog_breed.intersection(dog_breed2)) 10 {'德国牧羊犬'} 11 12 #上述两种方法效果相似度100%
测试两个集合的并集#
1 >>> dog_breed2 2 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'} 3 >>> dog_breed 4 {'哈士奇', '拉布拉多', '萨马耶', '德国牧羊犬', '藏獒'} 5 #方法一 6 >>> print(dog_breed.union(dog_breed2)) 7 {'蝴蝶犬', '秋田犬', '哈士奇', '藏獒', '边境牧羊犬', '博美犬', '萨马耶', '罗威纳犬', '拉布拉多', '德国牧羊犬', '吉娃娃'} 8 #方法二 9 >>> print(dog_breed | dog_breed2) 10 {'蝴蝶犬', '秋田犬', '哈士奇', '藏獒', '边境牧羊犬', '博美犬', '萨马耶', '罗威纳犬', '拉布拉多', '德国牧羊犬', '吉娃娃'} 11 12 #二者相似度100%
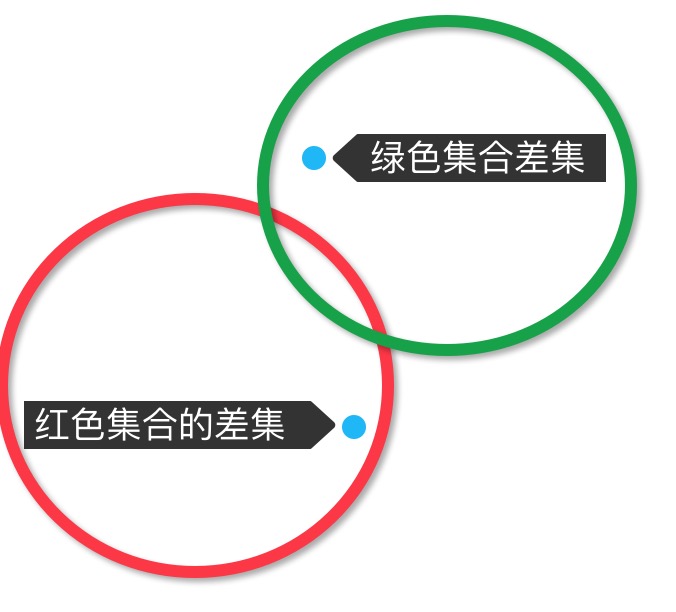
测试两个集合的差集#
1 #方法一 2 >>> print(dog_breed - dog_breed2) 3 {'哈士奇', '拉布拉多', '萨马耶', '藏獒'} 4 >>> print(dog_breed2 - dog_breed) 5 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '吉娃娃'} 6 7 #方法二 8 >>> print(dog_breed.difference(dog_breed2)) 9 {'哈士奇', '拉布拉多', '萨马耶', '藏獒'} 10 >>> print(dog_breed2.difference(dog_breed)) 11 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '吉娃娃'} 12 13 #二者相似度100%
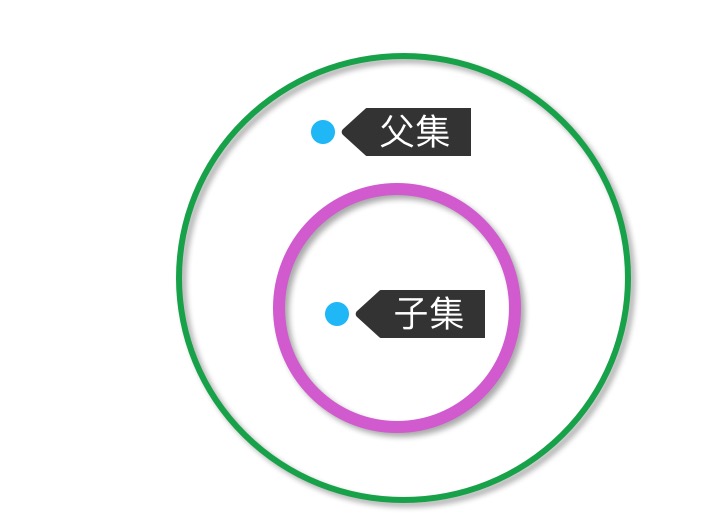
测试两个集合的子集#
1 #测试前面的集合是否为后面的子集,也就是说后面的集合是否全部包括前面的集合,返回为True or False 2 >>> print(dog_breed.issubset(dog_breed2)) 3 False 4 >>> dog_breed3 = set(['边境牧羊犬', '博美犬', '罗威纳犬', '吉娃娃']) 5 >>> dog_breed3.issubset(dog_breed2) 6 True 7 >>> dog_breed3 8 {'边境牧羊犬', '博美犬', '吉娃娃', '罗威纳犬'} 9 >>> dog_breed2 10 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'}
测试两个集合的父集#
1 #测试两个集合是否存在父集关系,也就是说前者的集合是否完全包括后者的集合 2 >>> dog_breed2 3 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'} 4 >>> dog_breed3 5 {'边境牧羊犬', '博美犬', '吉娃娃', '罗威纳犬'} 6 >>> dog_breed2.issuperset(dog_breed3) 7 True 8 >>> dog_breed3.issuperset(dog_breed2) 9 False
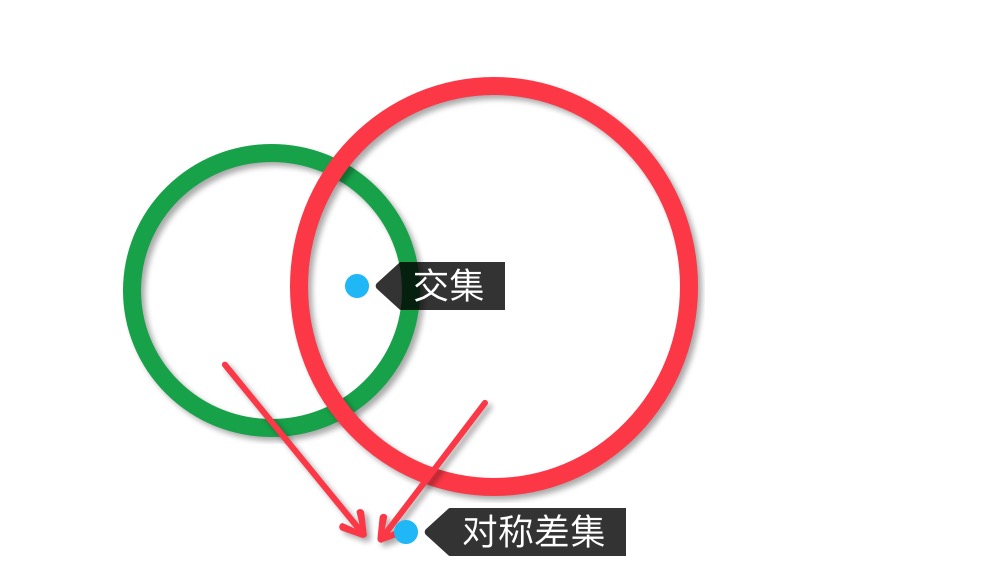
测试两个集合的对称差集#
1 #所谓对称差集就是取两个集合的并集中去掉交集的部分。 2 >>> dog_breed 3 {'哈士奇', '拉布拉多', '萨马耶', '德国牧羊犬', '藏獒'} 4 >>> dog_breed2 5 {'蝴蝶犬', '秋田犬', '边境牧羊犬', '博美犬', '罗威纳犬', '德国牧羊犬', '吉娃娃'} 6 >>> dog_breed.symmetric_difference(dog_breed2) 7 {'蝴蝶犬', '拉布拉多', '萨马耶', '秋田犬', '罗威纳犬', '哈士奇', '藏獒', '边境牧羊犬', '博美犬', '吉娃娃'}
1 >>> dog_breed ^ dog_breed2 2 {'蝴蝶犬', '拉布拉多', '萨马耶', '秋田犬', '罗威纳犬', '哈士奇', '藏獒', '边境牧羊犬', '博美犬', '吉娃娃'}

集合的去重功能#
1 #去重功能 2 >>> list1 = [1,3,4,5,6,7,84,3,2,1,2,3,4] 3 >>> list1 4 [1, 3, 4, 5, 6, 7, 84, 3, 2, 1, 2, 3, 4] 5 >>> list1 = set(list1) 6 >>> list1 7 {1, 2, 3, 4, 5, 6, 7, 84} 8 >>>
一些关于集合的其它姿势#
isdisjoint 如果两个集合存在交集返回True,反之返回False
1 >>> list1.isdisjoint(list2) 2 True 3 >>> list2 4 {0, 9, 11, 12} 5 >>> list1 6 {1, 2, 3, 4, 5, 6, 7, 84}
集合的删除功能
1 #删除字典中的随机一个元素 2 >>> list1.pop() 3 1 4 >>> list1 5 {2, 3, 4, 5, 6, 7, 84} 6 #删除字典中的指定元素,不管元素是否存在,都不会抛异常,只会返回None 7 >>> list1.discard(876) 8 >>> a = list1.discard(9876) 9 >>> print(a) 10 None 11 #删除字典中的指定元素,如果元素不存在,抛出keyError错误 12 >>> list1.remove(987) 13 Traceback (most recent call last): 14 File "<stdin>", line 1, in <module> 15 KeyError: 987
集合的内容增加功能
1 >>> list1 2 {3, 4, 5, 7, 84} 3 >>> list1.add(110) 4 >>> list1 5 {3, 4, 5, 7, 110, 84}
集合的更新
1 >>> list1.update([1,2,3,4,5,6,7,8,9,10]) 2 >>> list1 3 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 110, 84}
集合的长度
1 >>> list1 2 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 110, 84} 3 >>> len(list1) 4 12
判断一个元素是否在集合中
1 >>> list1 2 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 110, 84} 3 >>> 2 in list1 4 True 5 >>> 22 in list1
判断一个元素不在集合中
1 >>> 22 not in list1 2 True 3 >>> 2 not in list1 4 False
文件读写
打开文件 #
打开一个文件,我们看看是怎么实现的
smt_file = open('smt','r') #打开一个文件为smt,文件句炳叫smt_file,使用只读的模式打开 print(smt_file.read()) # 一次性读区所有的文件内容
文件指针#
我们来说一下文件读取指针的东西
smt_file = open('smt','r') print(smt_file.read()) #第一次读取文件内容 print('----------分割线------------') print(smt_file.read()) #第二次读取文件内容 print('----------分割线end------------')
#看一下打印结果,我也是一个有追求的人!
等着我吧──我会回来的。 只是要你苦苦地等待, 等到那愁煞人的阴雨 勾起你的忧伤满怀, 等到那大雪纷飞, 等到那酷暑难捱 等到别人不再把亲人盼望, 往昔的一切,一古脑儿抛开。 等到那遥远的他乡 不再有家书传来, 等到一起等待的人 心灰意懒──都已倦怠。 等着我吧──我会回来的, 不要祝福那些人平安: 他们口口声声地说── 算了吧,等下去也是枉然! 纵然爱子和慈母认为── 我已不在人间 纵然朋友们等得厌倦, 在炉火旁围坐, 啜饮苦酒, 把亡魂追荐…… 你可要等下去啊! 千万不要同他们一起, 忙着举起酒盏。 等着我吧──我会回来的: 死神一次次被我挫败! 就让那不曾等待我的人 说我侥幸──感到意外! 那没有等下去的人不会理解── 亏了你的苦苦等待, 在炮火连天的战场上, 从死神手中, 是你把我拯救出来。 我是怎样在死里逃生的, 只有你和我两个人明白── 只因为你同别人不一样, 你善于苦苦地等待。 ----------分割线------------ ----------分割线end------------ Process finished with exit code 0
我们发现,第二次读区文件并没有内容,我们来查看一下当前的读区文件指针的值
# Author:Sean sir smt_file = open('smt','r') print(smt_file.read()) print('----------分割线------------') print(smt_file.read()) print('----------分割线end------------') print(smt_file.tell()) print(smt_file.seek(0)) print('----------第三次读取分割线------------') print(smt_file.read()) print('----------第三次读取分割线end------------') #打印结果 等着我吧──我会回来的。 只是要你苦苦地等待, 等到那愁煞人的阴雨 勾起你的忧伤满怀, 等到那大雪纷飞, 等到那酷暑难捱 等到别人不再把亲人盼望, 往昔的一切,一古脑儿抛开。 等到那遥远的他乡 不再有家书传来, 等到一起等待的人 心灰意懒──都已倦怠。 等着我吧──我会回来的, 不要祝福那些人平安: 他们口口声声地说── 算了吧,等下去也是枉然! 纵然爱子和慈母认为── 我已不在人间 纵然朋友们等得厌倦, 在炉火旁围坐, 啜饮苦酒, 把亡魂追荐…… 你可要等下去啊! 千万不要同他们一起, 忙着举起酒盏。 等着我吧──我会回来的: 死神一次次被我挫败! 就让那不曾等待我的人 说我侥幸──感到意外! 那没有等下去的人不会理解── 亏了你的苦苦等待, 在炮火连天的战场上, 从死神手中, 是你把我拯救出来。 我是怎样在死里逃生的, 只有你和我两个人明白── 只因为你同别人不一样, 你善于苦苦地等待。 ----------分割线------------ ----------分割线end------------ 1129 0 ----------第三次读取分割线------------ 等着我吧──我会回来的。 只是要你苦苦地等待, 等到那愁煞人的阴雨 勾起你的忧伤满怀, 等到那大雪纷飞, 等到那酷暑难捱 等到别人不再把亲人盼望, 往昔的一切,一古脑儿抛开。 等到那遥远的他乡 不再有家书传来, 等到一起等待的人 心灰意懒──都已倦怠。 等着我吧──我会回来的, 不要祝福那些人平安: 他们口口声声地说── 算了吧,等下去也是枉然! 纵然爱子和慈母认为── 我已不在人间 纵然朋友们等得厌倦, 在炉火旁围坐, 啜饮苦酒, 把亡魂追荐…… 你可要等下去啊! 千万不要同他们一起, 忙着举起酒盏。 等着我吧──我会回来的: 死神一次次被我挫败! 就让那不曾等待我的人 说我侥幸──感到意外! 那没有等下去的人不会理解── 亏了你的苦苦等待, 在炮火连天的战场上, 从死神手中, 是你把我拯救出来。 我是怎样在死里逃生的, 只有你和我两个人明白── 只因为你同别人不一样, 你善于苦苦地等待。 ----------第三次读取分割线end------------
这里我们讲述一下两个方法,分别为tell和seek,第一个方法为查看当前读取的文件位置;第二个为把文件指针专向相应的地方,我在上文中是把指针指向了文件的开始,所以第三次读取便读到了数据。
f.write()
f.write('想要写入的内容') #这里要说的是,写入的内容必须是一个字符串,如果要写入一个列表、字典等是不被允许的; #上面我们讲过f.seek()这个方法,假如我们seek到了一个指定的地方,这个时候往里面写东西,那么这个地址后面的相应的内容就会被冲掉了,这里一定要注意!
f.encoding 显示一个文件的编码格式
#打开一个文件,打印文件编码格式 smt_file = open('smt','r') print(smt_file.encoding) #输出 UTF-8
f.seekable 打印一个文件是否为光标可移动文件,有些二进制文件事无法进行光标移动的。
#打开一个文件,打印文件是否为光标可移文件
smt_file = open('smt','r') print(smt_file.seekable()) #输出 True
f.read() 如果不输入任何参数,那么将会吧整个文件读出来,这里也可以输入参数,指定读取文件子节数
#打开一个文件,并把打印read的结果的长度
smt_file = open('smt','r') a = smt_file.read(56) print(len(a))
#out
56
f.readable() 判断一个文件是否可读
#以一个r的方式打开一个文件,然后测试这个文件是否为可读
smt_file = open('smt','r') print(smt_file.readable())
#out
True
我们来用追加的模式进行测试
#以一个a的方式打开一个文件,然后测试这个文件是否为可读
smt_file = open('smt','a') print(smt_file.readable())
#out
False
f.writeble()和上面的一样,是用来测试文件的打开方式是否可读,这里不在演示
f.flush()强制刷新文件
f.fileno()返回文件句炳在系统中的编号我觉得理解为打开文件的顺序。
file = open('smt', 'r') print(file.fileno()) smt_file = open('smt', 'r') print(smt_file.fileno()) smt= open('smt', 'r') print(smt.fileno())
循环文件内容#
循环文件内容有两种,我们分别做一下解释:
#方法一:
#打开一个文件,用只读的模式
smt_file = open('smt', 'r') for line in smt_file.readlines(): print(line.strip())
#f.readlines()是把整个文件的每一行当做一个元素,存放在一个列表中,然后循环这个列表就可以了。
注:此种方式存在隐患,假如一个文件过大,会把整个内存撑爆
#方法二:
#打开一个文件,用只读的模式
smt_file = open('smt', 'r')
for line in smt_file:
print(line.strip())
#据大王所说,后面直接跟文件句炳,此时这个文件句炳是一个迭代器的东西,但是我现在不知道是啥,就理解为一个很牛逼的东西吧,这样读取是一行一行的读取,内存只会存放一行内容,故而不会涉及内存的问题。
#两者的优缺点,第一种方法因为是列表,可以直接使用下标,对文件读取那行进行方便控制;第二种方法没有下标,只能自己写计数器,进行判断。
可以同时打开两个文件#
with open('test', 'r', encoding='utf-8') as file, \ open('test_bak', 'w', encoding='utf-8') as file_new:
关闭文件#
#当打开文件的时候,如果不关闭会导致系统产生过多的垃圾,最后导致系统卡机,出现瓶颈。
#有得人说了,我们之前运行的程序,也都没有关闭文件,不是照样运行的好好的吗?
#其实python的底层垃圾回收的机制,当我们程序运行完后,默认会给你关闭文件,哪有人会说了,python自动帮我关闭了,那我还关闭个屁啊,那我们想如果我们运行1000个#文件,1000个程序都没退出,那这样岂不是内存中有1000个文件句炳在打开着。所以我们要记住只要不用这个文件了,就要关闭这个文件
F = open('filename','r') XXXXXXXXX F.close()
with语法打开文件#
#即便上面我们说了这么一大堆要记住关闭文件,但是我还是会忘记;那么我们就来用这种方法来打开一个文件,创建一个文件句炳,这样的话即便我们不关闭文件,python也会帮我们关闭的 with open('filename','r') as F: for line in F: print line
文件的修改#
# Author:Sean sir # 引用os模块,把新创建的文件重命名 import os with open('test', 'r', encoding='utf-8') as file, \ open('test_bak', 'w', encoding='utf-8') as file_new: for line in file: if 'A' in line: line = 'a\n' file_new.write(line) os.rename('test_bak', 'test') # 如上就做到了文件的修改,确实有点low,但是没办法,python就是这样
字符编码
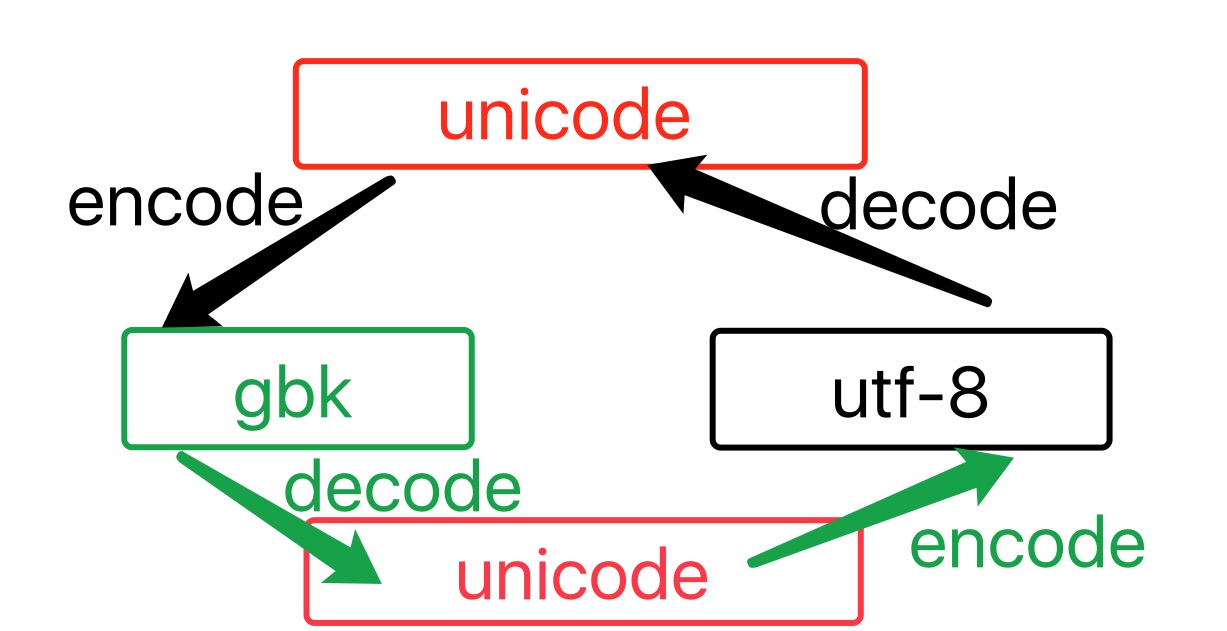
字符编码在python2.0和python3.0里面是不一样的,我们分别阐述一下这两种的区别:
python2.0 #
在python2.0里面,如果在编写程序前没有指定使用哪种编码进行编写,那么会使用系统默认的编码,也就是ascii编码 -----这是大前提
下面用一张图来解释2.0里面转吗的过程
我们把utf-8转为gbk的编码的测试
#声名我的程序使用utf-8的编码进行编码 #_*_ coding:utf-8 _*_ #引用sys模块 import sys #使用sys模块中的getdefaultencoding方法查询系统的编码 print(sys.getdefaultencoding()) #使用utf-8的编码定义变量s s = '你好' #把s转为unicode编码,因为unicode是万国码当然可以显示中文 s_unicode = s.decode('utf-8') #这里显示的并不是乱码,而是打印一个元组的时候,unicode默认是不显示中文的 print(s_unicode,type(s_unicode)) print(s_unicode) #把unicode编码转为gbk的编码,因为crt是utf-8的编码,所以是看不到的 unicode_gbk = s_unicode.encode('gbk') print(unicode_gbk) #输出 (u'\u4f60\u597d', <type 'unicode'>) 你好
下面我们把crt的编码改为gbk的,我们再看一下输出的结果
root@java:~# python utf8_gbk.py ascii (u'\u4f60\u597d', <type 'unicode'>) 浣犲ソ 你好 root@java:~#
再写一个gbk到utf8的转换
#_*_ coding:utf-8 _*_ import sys print(sys.getdefaultencoding()) s = '你好' s_unicode = s.decode('utf-8') print(s_unicode,type(s_unicode)) print(s_unicode) unicode_gbk = s_unicode.encode('gbk') print(unicode_gbk) print('------------------------') #首先decode成uncoide,然后再encode成utf8的编码,最后打印出来了 gbk_utf8 = unicode_gbk.decode('gbk').encode('utf-8') print(gbk_utf8) #输出 root@java:~# python utf8_gbk.py ascii (u'\u4f60\u597d', <type 'unicode'>) 你好 ------------------------ 你好
python3.0#
在py3中所有的编码默认是unicode的编码,所以当我门进行编码转换的时候,不需要进行decode解码了,直接进行encode编码成目标编码即可。在py3.0里面
只要一encode那么就会变成byts类型了。要想打印中文就的解码成unicode类型
import sys print('系统编码:',sys.getdefaultencoding()) str = '猜猜看' utf8_gbk = str.encode('gbk') print('utf8_gbk:', utf8_gbk) print('utf8_gbk的类型:',type(utf8_gbk)) print(str.encode('utf-8')) gbk_utf8 = utf8_gbk.decode('gbk').encode('utf-8') print('gbk_utf8:',gbk_utf8) print('gbk_utf8的类型:',type(gbk_utf8)) utf8_unicode = gbk_utf8.decode('utf-8') print('utf8_unicode:',utf8_unicode) print('utf8_unicode的类型:',type(utf8_unicode)) # 输出 系统编码: utf-8 utf8_gbk: b'\xb2\xc2\xb2\xc2\xbf\xb4' utf8_gbk的类型: <class 'bytes'> b'\xe7\x8c\x9c\xe7\x8c\x9c\xe7\x9c\x8b' gbk_utf8: b'\xe7\x8c\x9c\xe7\x8c\x9c\xe7\x9c\x8b' gbk_utf8的类型: <class 'bytes'> utf8_unicode: 猜猜看 utf8_unicode的类型: <class 'str'>
函数&过程
定义一个过程和定义一个函数的区别#
函数有返回值,过程没有返回值;
函数是调用这个函数体进行逻辑的运算,最后并返回一个值,这叫函数;
过程是调用这个过程,没有返回值,交给一个过程些数据进行逻辑运算,没有返回值,这叫过程;
但是在python中过程默认的返回值是None(也可以说python隐事的为我们返回了None),所以说在python中函数和过程没有明显的界定。
过程的定义规范#
# 定义一个过程,名称是test,无参数 def test2(): # 这里是描述一个过程的介绍 ''' 函数的描述,方便查询 ''' # 这是函数体 print('这是一个test过程') # 调用test过程 test2()
函数的定义#
函数是逻辑结构化和过程化的一种编程方法。
函数的定义规范#
# Author:Sean sir # 定义一个函数,名称是test,无参数 def test(): # 这里是描述一个函数的介绍 ''' 函数的描述,方便查询 :return: ''' # 这是函数体 print('这是一个test函数方法') # 这事函数的返回值 return 0 # 调用test函数 test()
为什么要使用函数#
如果我有三个程序,都要往同一个文件中写一行文字,如果不使用函数的话,我们只能挨个复制
def test1(): print('test1 starting action...') with open('a.txt', 'a') as file: file.write('start end \n') def test2(): print('test2 starting action...') with open('a.txt', 'a') as file: file.write('start end \n') def test3(): print('test3 starting action...') with open('a.txt', 'a') as file: file.write('start end \n')
如果用了函数我们只需要来写一个过程,就能省掉很大麻烦,优化后的代码如下:
def write_file(): with open('a.txt','a') as file: file.write('start end \n') def test1(): print('test1 starting action...') write_file( ) def test2(): print('test2 starting action...') write_file( ) def test3(): print('test3 starting action...') write_file( )
现在领导给了新需求,要在每一句下面加一个时间信息
下面的代码简单的更改了需求,不需要每个程序都需要更改
import time def write_file(): time_format = '%Y-%m-%d %X' time_current = time.strftime(time_format) with open('a.txt', 'a') as f: f.write('time %s end action\n' %time_current) def test1(): print('test1 starting action...') write_file( ) def test2(): print('test2 starting action...') write_file( ) def test3(): print('test3 starting action...') write_file( )
我们可以总结出,使用方法的优点有如下:代码一致性、代码可扩展性、代码重用性
函数的return#
在函数中只要遇到return方法那么代码体就不会继续往下运行,所以声明函数的时候要切记此问题
def test(): print('1111111') return 0 print('2222222') test() # 输出 1111111
python的函数可以返回任何数据,但是如果返回多个数据的话,python会把这些数据存放到一个元组中当做一个返回值返回
def test01(): pass def test02(): return 0 def test03(): return 0, 10, 'hello', ['sean', 'xiaoxin'], {'WuDaLang': 'lb'} t1 = test01( ) t2 = test02( ) t3 = test03( ) print('from test01 return is [%s]: ' % type( t1 ), t1) print('from test02 return is [%s]: ' % type( t2 ), t2) print('from test03 return is [%s]: ' % type( t3 ), t3) # 输出 from test01 return is [<class 'NoneType'>]: None from test02 return is [<class 'int'>]: 0 from test03 return is [<class 'tuple'>]: (0, 10, 'hello', ['sean', 'xiaoxin'], {'WuDaLang': 'lb'})
为什么要用返回值呢?返回值可以帮我们来确定这个函数的执行结果是不是正确的或者不正确的,后面的程序可以根据返回值的状态来做不同的动作!
函数的参数区别#
默认参数#
默认参数是在声明函数的时候定义的默认的参数,当调用的时候如果给了此参数的值那么就用调用时候的值,如果没有指定那么就用默认的参数值。
def test(x,y,z = 3): print(x) print(y) print(z) test(1,2,4) print('----------') test(2,1) # 输出 1 2 4 ---------- 2 1 3
位置参数#
位置参数中形参和实参是一一对应的关系,位置是对应的。
def test(x,y): print(x) print(y) test(1,2) print('----------') test(2,1) # 输出 1 2 ---------- 2 1
关键参数#
关键参数可以自由赋值,也可以和位置参数混用,需要注意的是关键参数不能在位置参数前面
参数组#
关键字参数组#
函数的局部变量与全局变量区别 #
#
作者:屌丝逆袭记
出处:https://www.cnblogs.com/xinzhiyu/p/5753673.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律