精读比特币论文
上一次读比特币论文还是几年前,在区块链大火的今天,决定仔细重读一下,并写下读后感。
本文试图以一种从宏观到微观,先静态后动态的叙述方式,描述比特币系统,文中绝大多数内容来自于中本聪的比特币论文,加上了一些自己的理解。
世界地图上看比特币
时至今日,比特币在物理上已是包含一万两千多个节点的,遍布全球的分布式系统。其中的每一个节点可能是普通的笔记本电脑、台式机、服务器、也可能是专用的“矿机”,归根结底,是一台具备计算和存储能力的计算机。这些节点通过Internet连接在一起,使用TCP/IP协议通信。
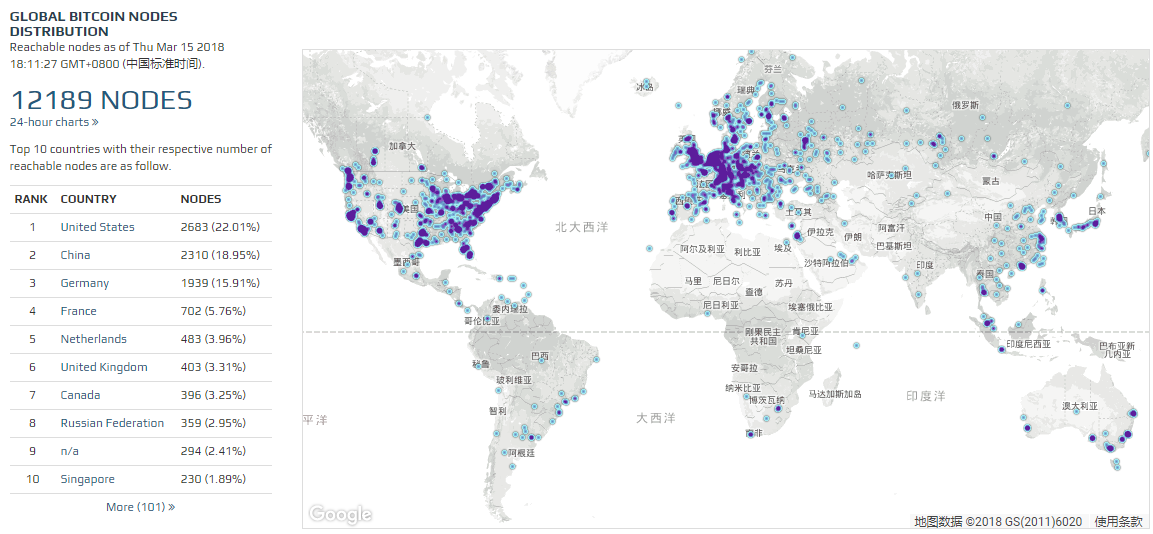
节点
每一个比特币节点上存储的数据是相同的,或者说是大致相同的。换句话说,比特币系统里面的每一个节点,都拥有所有的比特币数据。这些数据以一种叫做区块链的数据结构组织在一起,使得数据一旦存储到链上,就不容易被篡改。
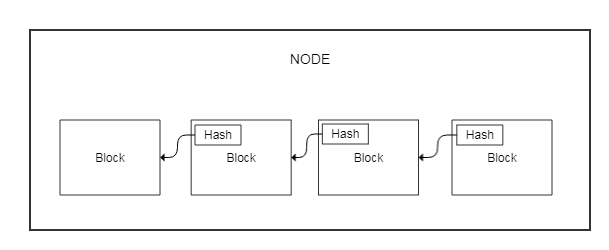
区块的大小是最大1MB,由一些不同类型的数据组成,其中一部分是它前一个区块Hash值,这样每一个区块都包含一个指向前一个区块的Hash,构成了一个非常普通的数据结构,链表,称之为区块链。区块链的巧妙之处在于难以篡改数据,如果要修改链上某个区块内的数据,它的Hash值就会变,这样其后的每一个区块都会变。
区块
区块由header和body两部分组成,整体大小的最大值为1MB,其中header占80个字节。header中包含了前一个区块的Hash值、本区块body内容的hash值、以及填充数据Nonce。其中填充数据Nonce用来调整控制当前区块的Hash值,其作用,在接下来描述区块如何生成时再介绍。
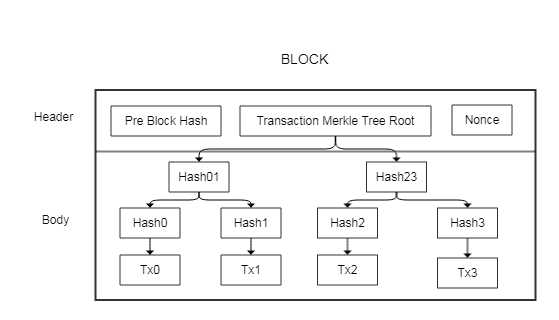
事实上,所谓区块的Hash值,指的是区块的80字节大小的header的Hash值。那区块链如何保证body的内容不被篡改呢?是使用了一种名为Merkle Tree的数据结构。
In cryptography and computer science, a hash tree or Merkle tree is a tree in which every leaf node is labelled with the hash of a data block and every non-leaf node is labelled with the cryptographic hash of the labels of its child nodes. Hash trees allow efficient and secure verification of the contents of large data structures. Hash trees are a generalization of hash lists and hash chains.
这样,通过在叶子节点存储实际数据,逐层计算Hash,最终将根节点Root Hash保存到区块header中,使得任何一个叶子数据发生变动,从根节点到该叶子节点路径上的Hash值,包含Root Hash在内都要发生变动。从而保证了数据不被篡改。
那么这样做带来了什么好处呢?这给区块链带来了删除数据的能力,即Merkle Tree叶子节点的数据不能被修改,但可以直接删除不再保存,而其Root Hash不变,区块的Hash也不会变。这一点保证了区块链在不断增加新区块的过程中,数据不会爆发性增长,使得区块全都存储在一个单计算机节点上,成为可能。
在比特币系统里面,组成区块body的Merkle Tree的叶子节点存储的,是一个交易。
交易
比特币里面交易用来将比特币从一个人传递给另一个人,跟现实世界一个人付钱给另一个一样。不同的是,现实世界需要钱这个实体,需要钱背后的政府背书,而比特币世界里面,交易既表达交易本身,又代表了比特币的持有权。
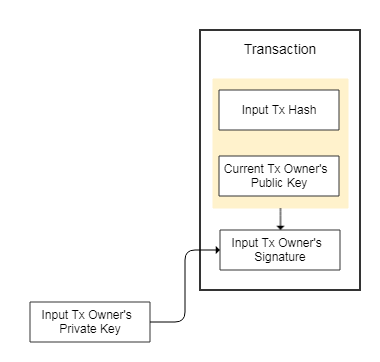
所以每一笔交易都包含了之前一笔交易的Hash值,用来做输入;同时包含交易对象的公钥,用来做输出。这样比特币的所有权就从之前一笔交易包含的公钥所对应的私钥的持有人,转移到了当前这笔交易包含的公钥对应的私钥的持有人。
当然,因为私钥代表了对一笔交易的所有权,每一笔交易都必须要使用作为其输入的交易包含的公钥对应的私钥进行签名,才生效。
持有私钥就可以交易,那么怎么避免持有人将一个比特币,支付给多人,也就是说怎样解决双花问题?答案是,所有交易数据都是公开的,存储到区块链上,不能篡改的,这样在验证一个新交易时,通过遍历已有交易,可以判断出是否存在双花现象。
交易链
论文中将比特币定义为一个交易链,其所有权在交易中流转,持有最后一笔交易中公钥所对应私钥的人,拥有该交易链所代表的比特币的所有权。
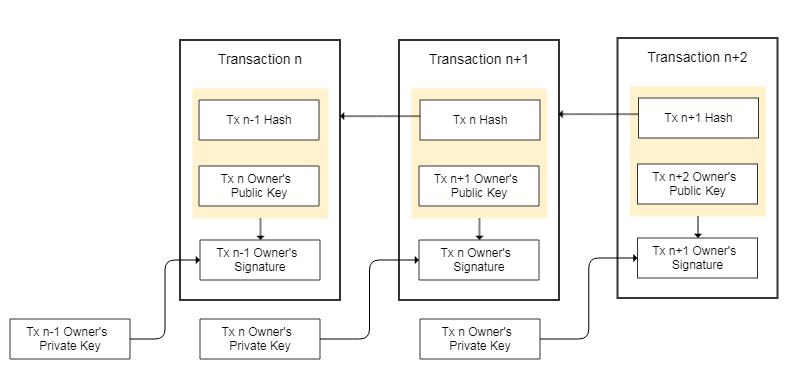
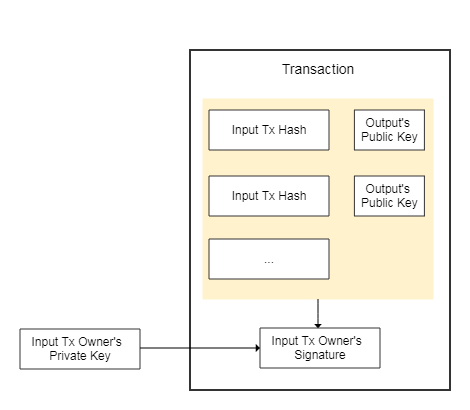
现实中的交易,可能有一次消费多个币,可能有找零,等需求。考虑到这一点,论文中将交易扩展为支持多个输入交易和多个输出公钥,至此,一次可以消费多个币,一个币也可以掰开来花。
比特币的诞生
代表比特币的交易链中每一笔交易都至少要有一笔交易作为输入,那第一笔交易哪来的呢,也就是说,比特币何时诞生呢?
区块的body由交易组成的Merkle Tree组成,而每一个区块内的第一笔交易,是一笔特殊交易,特殊之处在于没有输入,用来奖励该区块的生成者。这样随着交易增多,区块就增多,而随着区块增多,比特币/交易链也增多,相当于货币不断增发。
谁来生成区块
第一个区块是中本聪生成的,称之为创世区块,也是唯一一个不含其它块的Hash的区块。其余的区块都是由比特币节点生成,节点收集网络上尚未被确认的交易,进行确认后组成区块,同时将区块添加到区块链上。
一万两千多个节点,由哪一个节点来生成呢?比特币使用一种较为POW的机制来达成共识,比特币规定了每个区块的Hash值末尾的几位必须为0,这样节点在计算区块header的Hash值时,就必须不断调整填充字段Nonce的内容,以满足Hash值要求。由于Sha256这种Cryptographic hash的特性,计算特定的Hash值十分困难,需要大量的计算资源。而当一个节点找到符合条件的Nonce时,其它节点验证起来又特别的容易。
节点都在不断的计算新的区块的Hash值的过程,就称作挖矿,新区块的奖励交易,也就是挖矿的收益了。因为网络上的节点都在挖矿每个节点都有挖到的可能,并且网络也存在分区的可能(比如海底光缆被挖断、遭到了网络攻击等),网络上可能存在多条合法的区块链,当出现这种情况时,论文规定,长链胜出,短的被抛弃,其上与长链不一致的交易,也会被取消。
如果节点在某一时刻,收到了两条长度相当的区块链,那么它会同时保存两条链。同时,在收到的第一条上进行挖矿,直到随着交易进行,两条链有一条胜出,则抛弃失败的那条。
货币发行政策
作为一种货币,比特币也有其货币政策,前面也提到随着区块生成,货币不断增发。有一个问题是,随着比特币网络不断壮大,节点越来越多,生成新区快的速度也会不断增加,这会导致比特币数量不断增多。为了解决这个问题,论文中描述了一种Hash值计算难度自动调节的机制,通过根据区块生成速度,自动调整Hash值末尾0的个数,使得货币发行速度不受全网算力的影响。
按照论文的设计,当发行到一定数量后,计算出新区块不再受到比特币奖励,即不再有货币发行。比特币数量维持稳定,生成区块的节点,只收到交易手续费用的奖励。交易手续费,指一笔交易中,输入大于输出,则多余的被当做交易手续费,相当于打赏比特币节点的小费。小费高的交易,更容易吸引节点,因此更容易被确认,交易速度更快。
隐私保护
跟传统银行交易只提供给本人查询不同,比特币的交易是对所有人公开的。但比特币的所有权是靠RSA密钥来证明的,即比特币系统不保证交易的隐私性,但保证了比特币持有人的匿名性。
安全验证
只要掌控一定数量的算力,就可以攻破比特币共识协议,使得已确认的交易能够被撤销。论文中,对安全问题进行了论证,主要是讨论了,在不同的算力比例下,需等待多少个区块领先后,交易就可以被认为是安全的。此处不再赘述了,有兴趣去论文详读。
相比算力攻击,网络攻击似乎更容易些。只要刻意制造一个小的网络分区,就很容易使得分区内的交易被撤销。但论文中也提到,即便黑客控制了更多算力等,也只能撤销交易,进行欺诈。受益于交易链公私钥的所有权证明,黑客并不能花别人的钱。
比特币为什么值钱
因为大家相信它值钱。法币的背后是国家政府信用,比特币更多靠信仰吧,跟黄金一样。
总结
论文描述了比特币系统的整体设计,一个非常精致的分布式计算系统。当然有一些工程和安全上的问题没有讨论到,但已经足够精致了,很聪明,读起来过瘾。
熟悉分布式存储系统,分布式共识算法的人应当对文中的很多概念特别熟悉,我觉着也会有一些疑惑,觉着有一些问题,比如对网络的假设太简单,只考虑replication没考虑sharding等等。后面我会找机会去读下代码和衍生系统,期待更多的惊喜。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号