Java 8的新并行API - 魅力与炫目背后
这是一篇译文,原文链接见这里。
本文同时发表在ImportNew上,转载请注明出处。

我很擅长同时处理多项任务。就算是在写这篇博客的此刻,我仍然在为昨天在聚会上发表了一个让大家都感到诧异的评论而觉得尴尬。好吧,好消息是我并不孤单——Java 8在多任务处理方面同样很优秀。让我们来看看它是怎么做的。
在Java 8引入的新功能中,有很重要的一项是并行数组处理。这项新功能使得我们能够使用可以利用多核体系结构的Lambda表达式来对对数组的元素进行排序,过滤和分组。这里的重点是,Java程序员只需要非常少的工作就可以立刻使程序的性能获得提升。非常酷。
问题来了。这项新功能有多快?我应该什么时候使用它?好吧,答案有点让人沮丧——这依赖于具体的情况。要知道依赖什么情况吗?请继续阅读。
新的API
Java8的新并行操作API十分灵活。让我们一起看几个我们要用来做测试的例子。
1. 使用多核对数组进行排序:
Arrays.parallelSort(numbers);
2. 根据特定的条件(比如:素数和非素数)对数组进行分组:
Map<Boolean, List<Integer>> groupByPrimary = numbers
.parallelStream().collect(Collectors.groupingBy(s -> Utility.isPrime(s)));
3. 对数组进行过滤:
Integer[] prims = numbers.parallelStream().filter(s -> Utility.isPrime(s))
.toArray();
跟自己写多线程程序来实现相同的功能比较,生产力提高太多了!在这个新的体系中,我个人最喜欢的是一个叫Spliterator的新概念,将一个集合分成多个块,并行处理这多个块并将处理结果汇合到一起。就像它的哥哥iterator,它也被用来遍历一个集合的元素,只不过它更加灵活,允许你编写检查和分离集合的自定义行为,并在遍历时直接插入。
它的性能如何?
为了测试这些并行操作API的性能, 我在两种情况(低竞争和高竞争)下进行了实验。原因是单独运行一个多核算法,往往会有好的性能,但在真实的服务器环境中运行,情况就完全不同了。真实环境中往往有大量的线程在竞争宝贵的CPU时间片以处理消息或用户请求,由于竞争的存在,程序的性能就降低了。所以我进行了接下来的测试。我首先随机生成了长度为100K的整数数组,这些整数的取值在0到1百万之间。然后我分别使用传统的顺序方法和新的Java 8的并行API对这个数组进行了排序,分组和过滤。结果并不使人惊讶。
- 快速排序快了4.7倍
- 分组快了5倍
- 过滤快了5.5倍
这可以说明java 8的并行API具有非常好的性能吗?很不幸,不能。
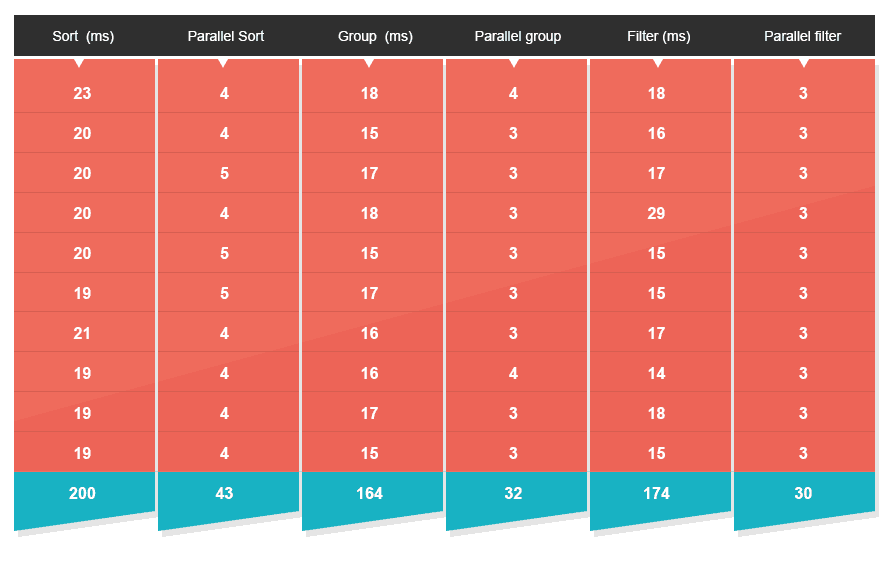
*测试结果与运行了100次的附加测试结果一致。
*测试机器为MBP,i7四核。
在有负载的情况下会发生什么呢?
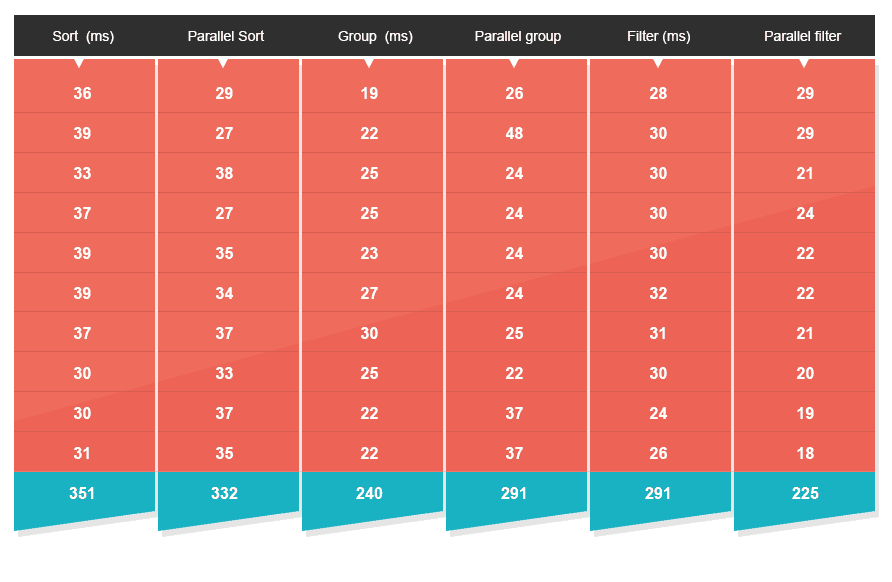
目前为止新API的性能表现非常出色,原因是线程之间对CPU的时间片的竞争非常少。这是理想的环境,但不行的是,理想环境往往不会出现在现实环境中。为了模拟真实的环境,我建立了第二个测试。这次测试使用跟第一次相同的算法,但测试任务在十个并发线程上执行,以模拟处在压力环境中的服务器同时处理十个请求的情况。这十个请求使用传统的顺利处理方法或Java 8的新API处理。
测试结果
- 排序现在只快了20%
- 过滤现在只快了20%
- 分组现在慢了15%
更高的规模和竞争水平很可能使这些数字进一步下降。原因是在一个多线程的环境中添加线程并不一定能帮助你提高计算效率,是计算机的CPU个数决定了计算效率,而不是线程个数。
结论
虽然这些都是非常强大和易于使用的API,但它们不是银弹。我们仍然需要花费精力去判断何时应该使用它们。如果你事先知道你会做多个处理并行操作,那么考虑使用排队架构,并使并发操作数和你的处理器数量相匹配可能是一>个好主意。这里的难点在于运行时性能将依赖于实际的硬件体系结构和服务器所处的压力情况。你可能只有在压力测试或者生产环境中才能看到代码的运行时性能,使之成为一个“易编码,难调试”的经典案例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号