时间紧张,先记一笔,后续化优与完善。
=================================================================
== all is based on the open course nlp on coursera.org week 9,week 10 lecture ==
=================================================================
这是nlp课程最后两周的内容了,觉感机器习学和nlp等方向长短常想通的,判若两人!下一步大概会系统地看大部头和paper,强增码编实现能力!
第十周的内容主要是GLMs分别在tagging和 Parsing面上的应用,我就不罗嗦了
1.Brown Clustering
1.1 Introduction
布朗聚类是一种针对汇词的聚类法方,Input是一系列的文章或者句子,Output有两种
第一种是:一系列的词组,体具多少个类看你之前的设定:
第二种是:每一个词都有一长串的二进制码,用似类霍夫曼码编的方法对每一个词停止码编
可以不言而喻的是,前缀相似度更高的词就越邻近
什么样的汇词相似呢?一个直觉的法想就是:相似的词出在现相似的置位。
更准确的说法就是:相似词的驱前词和后继词的分布相似,也就是它面前的词和面后的词现出得是相似的。
1.2 Formulation
假设我们在现有一个类分器,可以把每一个词分配到一个类面里,一共有k个类:
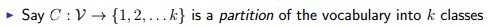
整个模型如下:
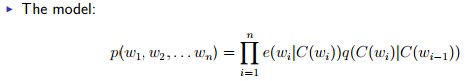
w1……wn是一条语料的词,w0是一个殊特的开始符号
e,q和我们之前习学的是一样的,不过是从汇词换成了类分而已
1.3 The Brown Clustering
我们在现来看整个布朗类分的模型:

可以看到最要重的货色就是类分器C,怎么量衡C的坏好呢:
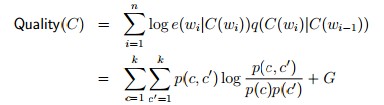
其中:G是一个常数
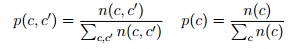
其中:n()是在类分器C的基本下的计数的函数,计统类分在语料库中现出的数次,和之前的count似类
如何失掉C呢,课程绍介了两种法方:
法方1.
一开始我们把每一个词独自分配到一个类中,假设有|V|=n个,记着我们的目标是找到k个类分
我们停止n-k次并合,每次把两个类并合到一同,每次并合贪地心选择能最大度程加增Quality(C)的两个类
这个naive算法的复杂度是多少呢?(n-k)*n*n*n^2,大概是O(N^5),即使是能化优到三次方复杂度,对于太大的 |V| 仍然很不事实
法方2.
开始设置一个参数m,比如m=1000,我们按照汇词现出的率频对其停止排序
然后把率频最高的m个词各自分到一个类中,对于第m+1到|V|个词停止循环:
1.对前当词建新一个类,我们在现又m+1个类了
每日一道理
盈盈月光,我掬一杯最清的;落落余辉,我拥一缕最暖的;灼灼红叶,我拾一片最热的;萋萋芳草,我摘一束最灿的;漫漫人生,我要采撷世间最重的———毅力。
2.从这m+1个类中心贪选择最好的两个类并合(和法方1一个意思),在现我们剩下m个类
最后我们再做m-1词并合,就失掉了我们一开始说的一串01码编所对应的树,可以转化为响应码编
2. Global Linear Models (GLMs)
2.1 Introduction
到目前为止,我们全部的模型都是这样一个进程:把题问结构派生成一系列的组合(或者说decision),比如我们之前讨论过的基于史历的法方 (Log-linear Models),每一个decision关系到一个概率,最后的模型是把全部decision的概率乘起来,这其中有两种方法:
这里就不再胪陈了,这在之前的条记有录记的。
在现我们将进入到一种新的模型:Global Linear Models。
之前我们把总的结构分拆成一个个decision,而GLMs则是用一些feature来斟酌团体的结构,而不是孤立地分拆组合。
在现看看GLMs都是由什么成组的:
①:一个feature function : f (和之前似类,但是我们还没有体具定义,这里先置搁)
②:一个函数 GEN(x) :x是一个输入,GEN函数生成一系列的候选结果
③:一个向量 v :和之前是一样
其实可以看到,GMLs和Log-Linear的最大别区就在于feature function的选择上,上面我们斟酌一下feature function的选择
2.2 Features
我们之前说过,
GLMs是用一些feature来斟酌团体的结构,而不是孤立地分拆组合,那么怎么才能斟酌团体的结构呢?
一个直观的懂得就是把分拆的feature组合起来就是团体了
基于这个想思,我们用更下一层的参数组合成我们要的feature function,比如:
示表方框内的结构在语法树上现出的数次,如果我们有多个这样的参数对应不同的结构,那么我们终最可以成组一个f:
除此外之,另一个较比要重的部份是GEN函数,如果对于一个输入要生成全部的候选结果,我们晓得这个集合长短常大的,一个一般的法想就是用使基于史历的模型(之前的模型)选出前多少个最好的候选谜底。
2.3 Together
最后,我们的总的货色就是:
2.4 the Perceptron Algorithm
最后一个题问,我们的v向量怎么求呢?直接上算法吧
很简单的算法,你可以看到对v停止变更的那一行公式,如果到目前为止的算法生成的结果和目标结果yi分歧,v实际上是变不的,如果不分歧,v就会朝着目标结果的方向停止变更。
除了这个Perceptron算法外之,也可以用最大似然等法方,只是复杂度会高很多
=========================================================
到此为止吧,体具的应用就不讲了,虽然觉感烂尾了
========================================================
文章结束给大家分享下程序员的一些笑话语录:
问答
Q:你是怎么区分一个内向的程序员和一个外向的程序员的? A:外向的程序员会看着你的鞋和你说话时。
Q:为什么程序员不能区分万圣节和圣诞节? A:这是因为 Oct 31 == Dec 25!(八进制的 31==十进制的 25)

