zabbix自动截图留档_python版
1 背景
每个DB Server都有zabbix监控,除了异常情况的报警信息外,也会在日检、周检、月检等工作中用到zabbix的监控数据,对zabbix监控数据会做两种处理:1 数据分析(环比分析、最大值、最小值及平均值分析);2 主要检测项目折线图留档(为啥需要留档呢,因为zabbix监控过多服务器,监控数据仅保留半年到1年间)。
关于 数据分析类的,已嵌入 日检邮件报告跟 月度报告 中,而 zabbix 监控图留档 一直没实现自动化,每个月都是人工取截图。刚好最近遇到 国庆db报告跟9月数据库报告,需要各种截图留档,然后触发了写个小脚本来自动下载 zabbix的监控图。
2 写个小脚本
2.1 获取图片url
首先打开日常的zabbix监控图页面,点击 F12,然后点击 ,这个时候选中页面中的折线图,就可以看到 对应的HTML代码,最后点击对应的html代码右键 copy下图片的链接地址,即可知道 zabbix的监控图 的url。
,这个时候选中页面中的折线图,就可以看到 对应的HTML代码,最后点击对应的html代码右键 copy下图片的链接地址,即可知道 zabbix的监控图 的url。

根据获取的url如下:
http://company.moniter.com/chart.php?period=2592000&stime=20170901000000&itemids%5B0%5D=32571&type=0&updateProfile=1&profileIdx=web.item.graph&profileIdx2=32571&width=1778&sid=341eb79599119b85&screenid=&curtime=1508809467171
这里边有几个参数说明下
- stime 是监控的开始时间按照 '%Y%m%d%H%M%S' 的时间格式
- period 是监控图的时长,从 stime开始要展示 多少秒 的监控数据
- itemid[0] 是 监控项目在zabbix 数据库的 itemid 号
- 这个如何查呢?首先根据 host表格,找到监控服务器的hostid,然后根据 items表格找到对应的监控id
- select i.hostid,itemid,i.name,key_,i.description from items i join hosts h on i.hostid=h.hostid where h.name = 'hostname';
- curtime这里可以不填写,但是注意 stime 加上 period秒数后,不要超过当前查询时间即可
- width 为图片的长度
根据需要,仅保留4个参数,这里注意 stime 加上 period秒数后,不要超过当前查询时间 ,简化后的url如下(把zabbix部署的域名或者网址IP替换掉 company.moniter.com):
http://company.moniter.com/chart.php?period=2592000&stime=20170901000000&itemids[0]=32571&width=1778
2.2 脚步及测试
小脚本实现的功能是:根据批量的itemid,自动下载图片到本地目录,并且重命名图片名称。
代码实现如下:
1 # -*- coding: utf-8 -*- 2 __author__ = 'xinysu' 3 __date__ = '2017/10/12 14:38' 4 import sys 5 import datetime 6 import http.cookiejar, urllib.request, urllib 7 from lxml import etree 8 import requests 9 class ZabbixChart(object): 10 def __init__(self, name, password): 11 url="http://company.monitor.com/index.php"; 12 self.url = url 13 self.name = name 14 self.password = password 15 cookiejar = http.cookiejar.CookieJar() 16 urlOpener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookiejar)) 17 values = {"name": self.name, 'password': self.password, 'autologin': 1, "enter": 'Sign in'} 18 data = urllib.parse.urlencode(values).encode(encoding='UTF8') 19 request = urllib.request.Request(url, data) 20 try: 21 urlOpener.open(request, timeout=10) 22 self.urlOpener = urlOpener 23 except urllib.request.HTTPError as e: 24 print(e) 25 def download_chart(self, image_dir,itemids,stime,etime): 26 # 此url是获取图片是的,请注意饼图的URL 和此URL不一样,请仔细观察! 27 url="http://company.monitor.com/chart.php"; 28 # 折线图的大小 30 url_par={} 31 url_par={"width":1778, "height":300,"itemids":itemids} 32 # 开始日期、结束日期从str转换为datetime 33 stime = datetime.datetime.strptime(stime, "%Y-%m-%d") 34 etime=datetime.datetime.strptime(etime, "%Y-%m-%d") 35 # 计算period 36 diff_sec = etime - stime 37 period = diff_sec.days*24*3600 + diff_sec.seconds 38 url_par["period"] = period 39 # stime转换str 40 stime = stime.strftime('%Y%m%d%H%M%S') 41 url_par["stime"] = stime 42 key = url_par.keys() 43 data = urllib.parse.urlencode(url_par).encode(encoding='UTF8') 44 request = urllib.request.Request(url, data) 45 url = self.urlOpener.open(request) 46 image = url.read() 47 html = requests.get('http://company.monitor.com/history.php?action=showgraph&itemids[]={}'.format(itemids)).text 48 page = etree.HTML(html) 49 hostname_itemname = page.xpath('//div[@class="header-title"]/h1/text()')[0].split(':') 50 hostname = hostname_itemname[0] 51 hostname_itemname.pop(0) 52 itemname = '_'.join(hostname_itemname).replace('/','_') 53 imagename = "{}\{}_{}_{}_({}).png".format(image_dir,hostname,stime,etime.strftime('%Y%m%d%H%M%S'),itemname) 54 f = open(imagename, 'wb') 55 f.write(image) 56
根据写好的类,输入zabbix的登录帐号、监控图的起始跟结束时间、本地存放图片目录、itemid的list,运行后如下:
1 # 登陆URL 2 username = "xinysu" 3 password = "passwd" 4 5 # 图片的参数,该字典至少传入graphid 6 stime = "2017-09-01" 7 etime = "2017-10-01" 8 9 # 用于图片存放的目录 10 image_dir = "E:\\03 WORK\\03 work_sql\\201709" 11 12 #运行 13 b = ZabbixChart(username, password) 14 item_list =(35295,35328,38080,37992,38102,38014,35059,35022,42765,35024,35028,35035,35036,35044,35045,35046,35047,38248,36369,36370,36371,36372) 15 for i in item_list: 17 itemids = i 18 b.download_chart(image_dir,itemids,stime,etime)
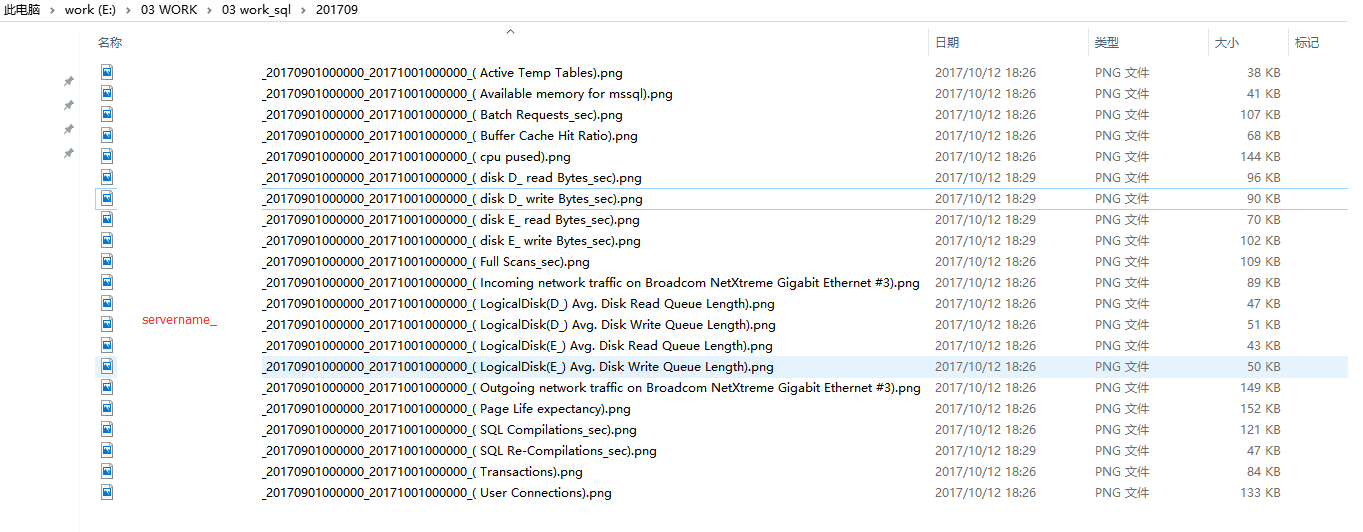
随便输入的itemid 测试下载,实际需要根据监控需要过滤itemid,下载后在文件夹中显示如下:

如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有。望各位支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号